详解十大经典排序算法(C++ 实现)
预备知识
概念说明
稳定和非稳定
- 稳定:对于数组中任意两个元素,某次排序前 a > b a>b a>b,排序后仍有 a > b a>b a>b,也就是说每次排序都朝着更加有序的方向发展,最坏的时候也会不会比上一次排序无序。
- 非稳定:对于数组中任意两个元素,某次排序前 a > b a>b a>b,排序后可能会出现有 a < b aa<b,则称为排序算法不稳定,也就是说排序算法虽然最终会使得数组变为有序,但是中间过程有时候会使得数组比上一步排序后更无序。
原地和非原地
- 原地:只需要常数空间的额外辅助空间,如堆排序。
- 非原地:需要非常数的额外辅助空间。
比较和非比较
- 比较:排序中需要对元素的大小做对比(算法1-7)。
- 非比较:排序中不需要对元素的大小做对比(算法8-10,即桶排序系列)。
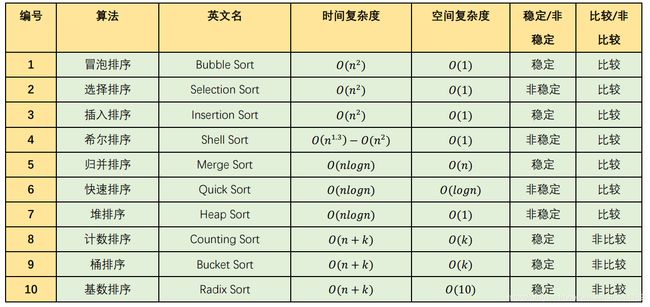
排序算法分类
关于
- 本文为了方便各位将程序复制过去就能直接调试和运行,所以都单独写成在了main()函数里,没有写成类方法的形式。
- 本文的所有算法都经过测试,copy过去就可以直接运行。
- 本文还有很多不足,后续会持续改进。
1、冒泡排序
经典排序算法,算法启蒙。
1.1 核心思想
冒泡排序(Bubble Sort),从数组的第 0 个元素开始,每次遍历,依据大小关系选择是否将第 i 个数和第 i+i 个数交换。每次循环,最大的数被放到数组的尾部,小的数渐渐漂浮到数组的前列。就像泡泡逐渐从池底浮到水面一样,因此称之为冒泡排序。
1.2 代码实现
冒泡排序的代码如下
//sort1:冒泡排序
#include上面的代码实际每次循环都会把大的元素后移,小的元素前移。冒泡排序虽然是最基础的排序算法,但是它是一种稳定的排序算法,每次循环都能保证数组的有序性提升或者至少不变。
1.3 算法性能
时间复杂度:
- O ( n 2 ) O(n^2) O(n2)
空间复杂度:
- O ( 1 ) O(1) O(1)
2、选择排序
2.1 核心思想
选择排序(Selection Sort),从数组的第 0 个元素开始,每次循环,找到当前剩余未排序的数中最小的值,将其与已排序最后一个的数的后一个数交换。
2.2 代码实现
//sort2:选择排序
#include2.3 算法性能
时间复杂度:
- O ( n 2 ) O(n^2) O(n2)
空间复杂度:
- O ( 1 ) O(1) O(1) ,只需要常数额外空间。
冒泡排序和选择排序的效率很低,究其原因是因为其对于某些常见情况如数组已经比较有序的情况没有优化。
3、插入排序
3.1 核心思想
插入排序(Insertion Sort),从数组的第 0 个元素开始,认为其已经排过序,将其作为参照,每次循环,找到数组的第 i (i>=1)个元素在前面已经排过序的数中位置,将其插入到已经排序过的数中,排过序的数依次后移相应的位数。和选择排序一样,我们将排过序的数放在数组的头部。当然也可以选择将最大的数放到尾部,从尾部向前遍历,看君喜好。
3.2 代码实现
//sort3:基本插入排序
#include3.3 算法性能
时间复杂度:
- O ( n 2 ) O(n^2) O(n2)
空间复杂度:
- O ( 1 ) O(1) O(1) ,只需要常数额外空间。
插入排序的算法对于比较有序的数组效率很高,很多时候其效率要高于冒泡排序和选择排序。但是到目前为止,排序算法的时间复杂度都没有突破 O ( n 2 ) O(n^2) O(n2) ,接下来介绍时间复杂度优于(或者大多数情况下优于 O ( n 2 ) O(n^2) O(n2) 的排序算法。
4、希尔排序(详解)
4.1 核心思想
希尔排序(Shell Sort),由D.L.Shell于1959年提出。希尔排序是插入算法的改进算法,也是第一批时间复杂度突破 O ( n 2 ) O(n^2) O(n2) 的算法之一。插入排序对于大型乱序的数组排序很慢,因为它是通过交换相邻的元素实现已排序部分后移从而实现插入的。希尔排序为了加快速度改进了插入排序,对不相邻的子数组进行排序,并最终用插入排序将局部有序的数组排序。希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
对于新手,希尔排序比较难以理解,而且很多文章的解释含糊不清,根本没说到点子上。实际上希尔排序的思想非常简单,那就是:在对整个数组进行插入排序前,先大致将其排几次序,大致排序的方法是先将整个数组中距离比较远的个个数进行两两交换排序,把小数放到前面。比如对于一个长度为16的数组,可以先对相距为13的数两两排序,然后缩小距离,对相距为4的数两两排序,最后对相邻的两个数(相距为1)进行排序。大家必须明确,希尔排序无论排了几次序,最后必须来一次相邻距离为1的排序(也就是3中使用的基本插入排序),至于在这之前的相距为13和相距为4的排序完全是为最后一次的插入排序服务,也可以说相距为13的排序是使得相距为4的排序更加容易,相距为4的排序使得相距为1的排序更加容易。 在进行基本插入排序之前,先在比较大的距离上对数组进行几次排序,这就是希尔排序的核心所在,希尔排序能提高排序效率的根本原因也就无非是在基本插入排序之前进行了几次长间隔的大致排序。而这么做可以提高插入排序效率的基本依据就是:插入排序对于比较有序的数组有更高的排序效率。
希尔排序的方法是给定一个有序序列 H H H , H H H的值在1到数组长度之间,比如对于长度为16的数组,可以选择:
H = [ 1 , 4 , 13 ] H=[1,4,13] H=[1,4,13]
也可以选择
H = [ 1 , 3 , 7 , 15 ] H=[1,3,7,15] H=[1,3,7,15]
注意其中 H H H 必须以 1 结尾,因为1代表最后一次的插入排序。如果 H = [ 1 ] H=[1] H=[1],则希尔排序就退化为基本的插入排序。原则上 H H H 的取值是不固定的,但是一般情况下,为了程序的统一起见, H H H 往往是一个按一定规律产生的递增间隔的有序序列,并且一般情况下 H H H 并不会再程序开始之前算好,而是在循环的过程中计算其元素值 h h h 作为排序间隔(有的书也叫做增量或者排序增量)。下面给出希尔排序程序。
4.2 代码实现
在上面解释希尔排序的时候,我们在长间隔排序的时候采用的方法是两两交换,先给出这种希尔排序的程序:
//sort4_1:希尔排序
//长间隔两两交换方式
#include上面代码中的 inc_fac是一个排序间隔因子,可以调节排序间隔:
当 inc_fac=3 的时候,排序间隔为:
[ 1 , 4 , 13 ] [1,4,13] [1,4,13]
排序完成时所需的元素交换次数time为 22.
当inc_fac=2 的时候,排序间隔为:
[ 1 , 3 , 7 , 15 ] [1,3,7,15] [1,3,7,15]
排序完成时所需的元素交换次数time为 30.
当inc_fac=4的时候,排序间隔为:
[ 1 , 6 ] [1,6] [1,6]
排序完成所需的元素交换次数time为 42.
因此, h h h 的选取会影响算法的效率,尤其对于长数组,一般来说,其可能有多个 h h h 的选取方式可以使得算法的效率达到相似的水平。当 h h h 很大的时候,我们就能将元素移动到很远的地方,为实现更小的 h h h 有序创造方便。
实际上,上面的交换方式只是一种希尔排序的实现方式,其示意如下:
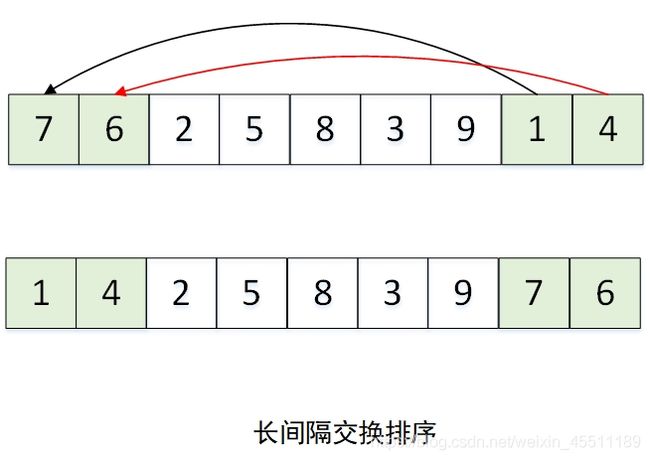
其通过间隔为 h h h 的元素事件交换排序达到将小数移动到前面的目的,随着 h h h 的不断减小,小的数逐渐移动到了数组前列。
希尔排序还可以将相邻比较远的数分组,然后分别采用插入排序,如下图所示:
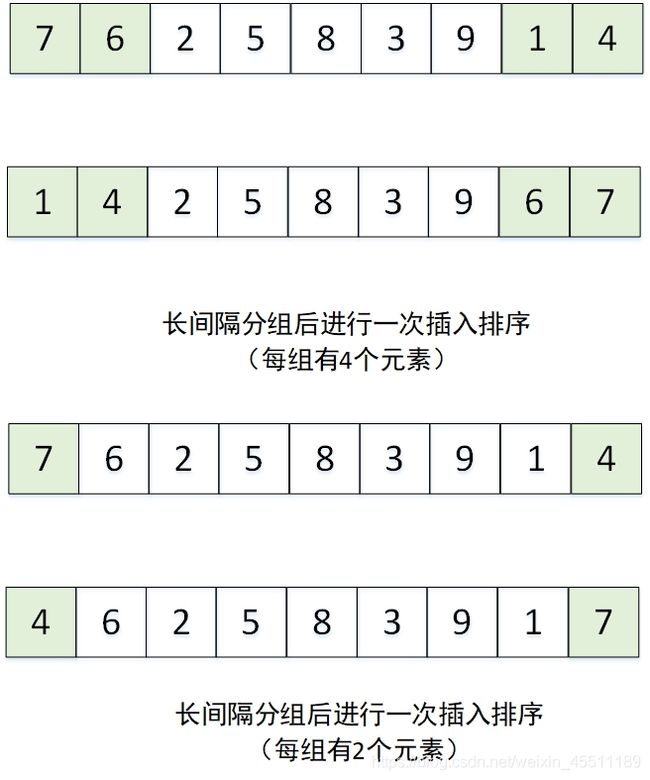
可以看到,在 h > 1 h>1 h>1时,对比交换排序的方式,插入排序是将分组后的长间隔数组整体排序,而交换排序只是随相距为 h h h 的两个数进行了交换排序,因此在 h = 1 h=1 h=1 之前,采用插入排序得到的中间数组是更有序的,但是,采用插入排序的方法对长间隔分组数组进行排序的时候,需要考虑如何分组的问题,即数组的头部取几个元素,数组的尾部取几个元素,因此采用插入排序进行长间隔分组数组排序的时候,分组常采用偶数分组,从而使得前面取 h / 2 h/2 h/2 个元素,后面也取 h / 2 h/2 h/2 个元素。如可以令分组间隔为2的指数形式:
[ 1 , 2 , 2 2 , 2 3 , 2 4 , . . . ] [1,2,2^2,2^3,2^4,...] [1,2,22,23,24,...]
注意最大的分组间隔不要超过数组的个数。实际中,由于子数组是相互独立的,因此多采用的两两交换的排序方式,即将 h − h- h−子数组中的每个元素交换到比它大的元素之前去。下面给出采用这种指数间隔的插入排序实现希尔排序的代码:
//sort4_2:希尔排序
//指数间隔插入实现
#include 【总结】希尔排序可以提高效率的原因在于它权衡了子数组的规模和有序性,通过在基本插入排序之前将数组进行长间隔的多次提前排序,使得在进行最后一步间隔为1的基础插入排序之前,得到是一个比较有序的数组,从而使得最后一步的插入排序获得了很高的效率。很有意思的是,到目前为止,人们依然没有彻底弄清楚希尔排序的性能以及最优递增序列的选择。
4.3 算法性能
时间复杂度:
- O ( n 1.3 ) − O ( n 2 ) O\left( n^{1.3} \right) - O\left( n^{2} \right) O(n1.3)−O(n2)
空间复杂度:
- O ( 1 ) O(1) O(1)
5、归并排序(详解)
5.1 核心思想
归并排序(Merge Sort),其最初的想法很简单,那就是:如果要对一个大的有序数组进行排序,则可以将其分成小的数组然后分别对其排序,最后通过归并的方法将排序后的小数组归并为大数组。这里的归并指的是:将两个排序后的小数组按照元素的大小次序依次排序。
归并排序最吸引人的性质是,在任何情况下,对于长度为N的数组,其排序所需的时间复杂度都不会超过 N l o g N NlogN NlogN。归并排序的缺点是其空间复杂度(排序所需的额外空间)和 N N N 成正比。
归并排是分治思想的典型应用(分治思想是高效排序算法中的常用思想)。在归并算法提出初期,人们尝试了很多的方法希望找到一种原地的归并排序方法,即只需要常数辅助空间的归并方法,但是这些方法大都非常复杂。因此,实际中很少使用。实际可用的归并算法需要额外的非常数额外空间,归并算法可以分为两种,分别是:
- 自顶向下的归并排序
- 自底向上的归并排序
下面分别介绍这两种排序方法的代码实现。
5.2 代码实现
① 自顶向下的归并排序
自顶向下的归并是通过递归实现的,即将大数组分成两个小数组,两个小数组又可以分为两个小数组,其递归顺序为:
左数组排序 —— 右数组排序 —— 归并
这里所谓的递归顺序指的是先递归到最小不可分割的左数组,遇到递归终止条件返回,对最小左数组其排序后,然后对最小右数组排序,然后将两者合并,递归这一过程,直到排序完成,其排序过程有些类似于二叉树的后续遍历。
自顶向下的归并排序算法如下:
//sort5_1:自顶向下的归并排序(递归)
#include将自定向下的排序方法,由于递归的构建方式,是从左到右排序的,即先将数组的左半边递归完成,然后又开始递归排序右半边的数组。
② 自底向上的归并排序
自底向上的归并排序不是通过递归实现的,而是先将数组分为不可分割的最小数组,然后两两归并、再四四归并、最后再八八归并,一直下去,最后一次归并的第二个数组可能比第一个数组要小(但是这对merge方法不是问题),直到排序完成。
自底向上的归并排序算法如下:
//sort5_2:自底向下的归并排序(非递归)
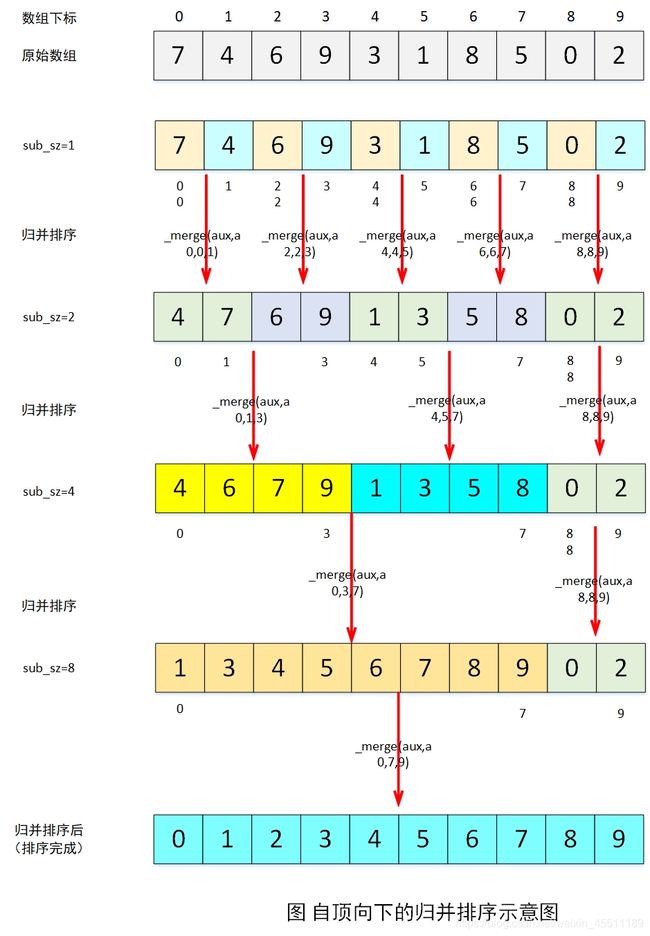
#include自底向下的归并排序是一种非递归的排序,其中子数组长度控制每次归并的数组长度,即:
- sub_sz=1时,从左到右,01归并、23归并、45归并、67归并…;
- sub_sz=2时,从左到右,01、23归并、45、67归并…
- sub_sz=4时,从左到右,0123、4567归并…
- …
如下图所示:
5.3 算法性能
归并排序算法最重要的一点就是可以证明他在最坏的情况下时间复杂度不会超过 O ( n l o g n ) O(nlogn) O(nlogn),对于归并排序算法:
时间复杂度:
- n l o g n nlogn nlogn
空间复杂度:
- O ( n ) O(n) O(n)
6、快速排序
快速排序(Quick Sort) 是应用最为广泛的排序算法,它由图灵奖获得者C. A. R. Hoare于1960年提出,被列为20实际十大算法之一。快速排序简单易懂,在大多数情况下排序效率优良,可以说是迄今为止最成功的排序算法。无论是在C++ STL亦或是Java SDK的底层实现中均可以看到它的身影。
6.1 核心思想
快速排序的核心思想是:将待排序数组经过一趟排序后分为两个部分,其中左半部分小于数组中的一个值 p p p,而有半部分大于值 p p p,我们将值 p p p 所在的位置称为切分( p a r t i t i o n partition partition)位置,然后再对左右两个小数组分别排序(可以是递归的,也可以是非递归的)。
6.2 代码实现
首先介绍如何将数组排序为比 p p p 大和比 p p p 的两部分,其实现其实很简单,那就是:遇到比 p p p大的数就将其插入到 p p p 的右边,遇到比 p p p 小的数就将其插入到 p p p 的左边。
对于快速排序,如何将比 p p p 大的元素放到 p p p 的左边、将比 p p p 小的元素放到 p p p 的右边、以及 p p p 的选择是快速排序的关键所在。其中 p p p 的选择是一个至今仍在研究的问题,实际中,一般就都是将数组的第一个元素作为切分元素。所以快速排序的关键问题就是如何将数组以 p p p 为界限分为左右两个部分,下面先给出代码实现,然后讲解其实现过程:
//sort6:快速排序
#include我们在上面的代码中,递归实现了快速排序,不过核心不是递归,而是partition()函数,其作用是将传入的数组切分排序并返回切值个sort()函数中的j,而 j-1 和 j+1 作为更小数组的high和low又被递归调用。下面说明partition()函数的工作过程:
- 从传入数组的头部(low)和尾部(high)开始,令 i = l o w , j = h i g h i=low,j=high i=low,j=high,然后将传如子数组的第一个元素(low位置)作为切分值,即 p = a r r a y [ l o w ] ; p=array[low]; p=array[low];
- 先执行: w h i l e ( a r r a y [ + + i ] < p ) i f ( i = = h i g h ) b r e a k ; while (array[++i] < p) if (i == high) break; while(array[++i]<p)if(i==high)break; 其作用是从 i + 1 i+1 i+1开始从后向前寻找比 p p p大的元素,其位置为 i i i;
后执行: w h i l e ( p < a r r a y [ − − j ] ) i f ( j = = l o w ) b r e a k ; while (p < array[--j]) if (j == low) break; while(p<array[−−j])if(j==low)break;其作用是从 j j j开始从前向后寻找比 p p p 小的元素,其位置为 j j j; - 将array[i]和array[j]交换,如果 i > = j i>=j i>=j 说明除了还在low位置的切分元素 p p p外,其余元素均以按要求分布。
- 最后,将位于low位置的切分元素array[0]和从左到右比 p p p 小的最后一个元素( j j j 位置处)交换。
其图示说明如下:

另外需要说明的是,快速排序其实也是一种分治的排序算法。它将一个数组分为两个数组,将两部分独立地排序。快速排序和归并排序是互补的:归并排序将数组分为两个子数组分别排序,并将有序的子数组归并并以将整个数组排序;而快速排序将数组排序的方式则是当两个都有序时整个数组自然也就有序了。在第一种情况中,递归调用发生在处理整个数组之前;在第二种情况中,递归调用发生在处理整个数组之后。在归并排序中,一个数组被分为两半;在快速排序中,切分( p a r t i t i o n partition partition)的位置取决于数组的内容。
6.3 算法性能
从统计角度,快速排序在多少情况下性能优良,可以肯定的是对于大小为 n n n 的数组,上面给出的快排算法的运行时间在 1.39 n l o g n 1.39nlogn 1.39nlogn 的某个常数因子的范围之内,归并排序其实也可以做到这一点,但是快速排序一般会更快。但是快速排序是不稳定的,且在切分不平衡上面给出的程序可能会极为低效。所以,后续对快排的改进大多都是对于切分方式的改进。总的来说,可以认为快速排序的性能如下:
时间复杂度:
- n l o g n nlogn nlogn
空间复杂度:
- O ( l o g n ) O(logn) O(logn)
7、堆排序(详解)
堆的定义:堆是一棵完全二叉树,每个结点的值都大于等于其左右孩子的结点的堆称为大顶堆;每个结点的值都小于等于其左右孩子结点值的堆称为小顶堆。从堆的定义可以知道,根节点一定是堆中所有结点最大(小)者。
注意:堆是完全二叉树,既然是树,那么想当然的我们就可以用指针实现其结构,即每个结点都需要三个指针来指到它的上下结点(父结点和两个子节点各需要一个)。但是,千万不要忘了完全二叉树由于其特殊的结构,其仅用一个数组就能实现(因为其结点是层序连续的),所以我们用数组就可以实现大顶堆,实际上,堆排序就是用原数组不断原地构建堆有序的完全二叉树实现的,其不需要任何额外空间就可以达到对数世间复杂度,是一种相当相当经典的原地排序算法。建议读者在学习堆排序之前对二叉树(尤其是完全二叉树)进行充分的学习和理解。
下面给出一些完全二叉树的定义和一些重要性质:
1、定义
对于一课具有 n n n 个结点的二叉树按程序编号,如果编号 i ( 1 ≤ i ≤ n ) i(1\le i\le n) i(1≤i≤n)的结点与同样深度的慢二叉树中编号为 i i i 的结点在二叉树中位置完全相同,则这棵树称为完全二叉树。
2、性质
① 具有 n n n 个结点的完全二叉树的深度为 [ l o g 2 n ] + 1 [log_2^{n}]+1 [log2n]+1 ([ ]表示向下取整)。
② 如果对一棵有 n n n 个结点的完全二叉树的结点按层序排序(从第1层到 [ l o g 2 n ] + 1 [log_2^{n}]+1 [log2n]+1 层,每层从左到右),对任一结点 i i i有:
- 如果 i = 1 i=1 i=1 ,则结点 i i i 是二叉树的根;如果 i > 1 i>1 i>1,则其双亲是结点 [ i 2 ] [\frac {i}{2}] [2i] 。
- 如果 2 i > n 2i>n 2i>n,则结点 i i i 无左孩子(对于完全二叉树,当然也没有右结点,因此其是一个叶子);否则其左孩子是结点的 2 i 2i 2i。
- 如果 2 i + 1 > n 2i+1>n 2i+1>n,则结点 i i i 无右孩子;否则其右孩子是结点 2 i + 1 2i+1 2i+1。
由于堆是有序二叉堆,所以简单点来说就是:对于堆,位置 i i i 的结点的父结点的位置为 [ i 2 ] [\frac {i}{2}] [2i] ,两个子节点的位置分别是 2 i 2i 2i 和 2 i + 1 2i+1 2i+1。对于堆排序,既可以用大顶堆实现,也可以用小顶堆实现,其只是在代码上有微小的差别,基本思想是一致的,下面采用大顶堆实现堆排序。
7.1 核心思想
堆排序(Heap Sort) 的核心思想是先将待排序的序列构成一个有序堆,则堆顶的根节点就是整个序列的最大值(或者最小值),然后将最大值(最小值)(当前根节点、堆首位)移走(这里的移走实际上是将最大值与末位交换),然后将剩余的 n − 1 n-1 n−1 个序列重新调整为一个有序堆,然后将其根节点移走(第二大值)并插入到最大值(最小值)的前面,重复这一过程,直至排序完成。
因此,堆排序的核心就是有序堆的构建,前面说过,由于堆是完全二叉树,是层序连续的,所以且结构由数组就可以实现,下面以大顶堆为例,说明如何将一个数组构建成一个大顶堆。
7.2 代码实现
假设我们要排序的原始数组为:
2 , 6 , 3 , 1 , 7 , 4 , 9 , 5 , 8 {2,6,3,1,7,4,9,5,8} 2,6,3,1,7,4,9,5,8
则其对应的完全二叉树如下所示:
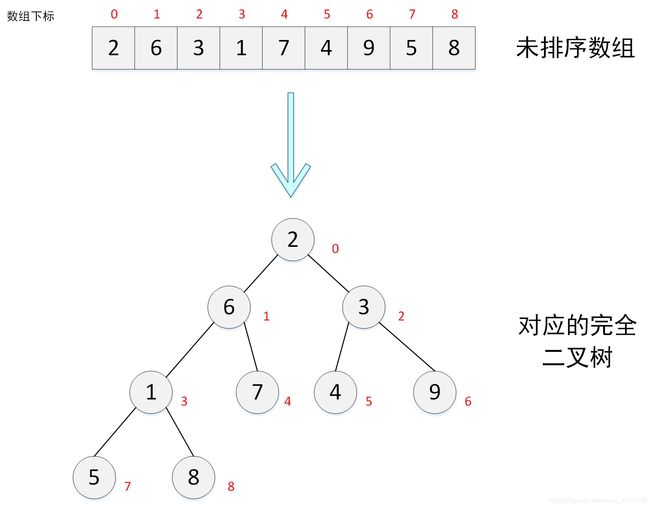
堆排序算法分为两个步骤:
- 一是将原始无序数组初始化为一个有序堆(本文以大顶堆为例)
- 二是循环进行堆排序
为什么这两个步骤要分开呢?原因是将原始无序数组初始化为一个大顶堆是一个耗时的过程,而初始大顶堆建好后,则排序就变的容易的多,我们每次循环和交换都可以将一个大元素放到数组的后面,文字是不容易理解的,也很难清楚的描述这个过程,但是当大家充分理解后面的程序代码后,就会很容易理解这个两个步骤为什么要分开,也会理解对排序的精髓所在。下面先介绍如何将无序数组初始化为一个大顶堆:
一般来说,有两种方法可以将数组初始化为大顶堆,一种是被称为上浮(swim)的方法,另一种则是被称为下沉(sink)的方法,这里我们选择下沉的方法将无序数组初始化为一个大顶堆 【注】 :
【注】 堆排序由著名计算机科学家、图灵奖得主弗洛伊德在1964年发明,是和快速排序(Quick Sort)齐名的高效排序算法。堆排序用原地实现了对数时间复杂度的排序,它是我们已知的唯一能够同时最优的利用空间和时间的方法。堆排序可以用大顶堆实现,也可以用小顶堆实现;可以用上浮(swim)实现堆的有序化,也可以用下沉(sink)实现,甚至可以两者同时使用,并且上浮/下沉算法可以用双循环实现,也可以用递归方法实现,本文不可能用有限的篇幅将这些方法及其组合 一 一 实现,本文采用的是最经典的大顶堆元素下沉的方法实现无序数组的初始化以及堆排序,不过只要理解了本文的程序,则其他程序解法也会很容易理解,所以各位朋友不必纠结于此。另外,如果有时间,本菜鸡可以考虑单独将堆排序写一篇文章,对其进行详细分析,大家可以关注一下。
由无序数组构建大顶堆的核心方法是从下到上,从右到左循环,将每个非叶子结点(比如上面的图中就是 3—2—1— 0 结点)下沉到不能再下沉的位置,则最终得到的就是一个大顶堆。其中,假设数组一共有 N N N 个元素,第 k ( k = 1 , 2... [ l o g 2 N ] + 1 ) k(k=1,2...[log_2{N}]+1) k(k=1,2...[log2N]+1) 层的结点(非叶子结点)最多可能会下沉 [ l o g 2 N ] + 1 [log_2{N}]+1 [log2N]+1 层,比如:
- 第0个结点(根节点2)会被比较3次
- 第1、2个结点(6和3)会被比较2次
- 第3个结点(结点1)会被比较1次
下沉时的原则是:如果父结点比某个孩子结点小,则将其与孩子结点的较大者交换,这是为了保证父节点的值比左右孩子结点的值都大。由原始数组构建大顶堆的过程如下所示:
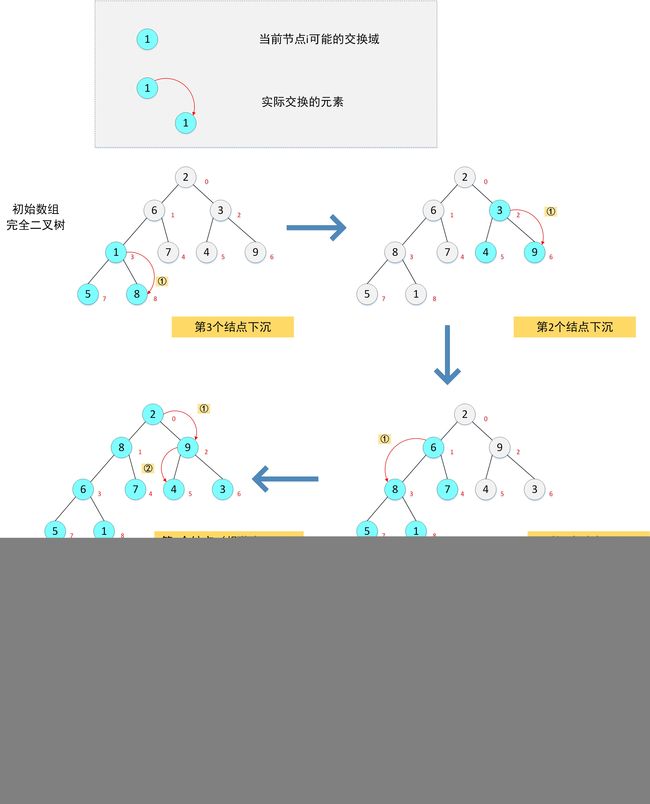
得到初始大顶堆后,排序就变的很简单,后续过程是将堆顶元素(最大值9)和最后一个叶子结点(对应数组最后一个元素)交换,然后将剩余的8个元素(数组的0-7)重新调整为大顶堆,调整的过程不再需要像由原始数组构建大顶堆一样,需要对整个二叉树进行重新构建,而只需要交换后的堆顶元素1下沉到不能在下沉即可(即只需要一次下沉),然后重复以上交换和下沉过程,直至数组完全有序。其过程如下图所示:
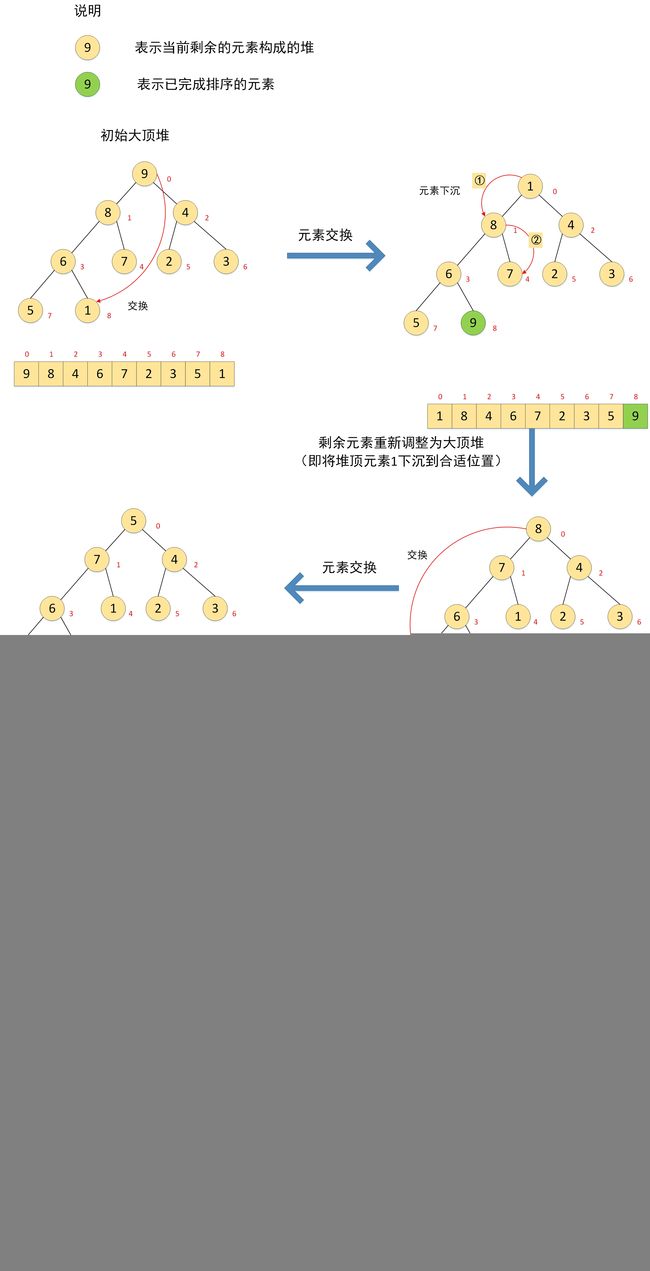
其中,首次由无序数组初始化为大顶堆需要从右到左,从下到上循环下沉所有的非叶结点,而大顶堆建好后,每次只要交换堆顶元素(当前对最大值)到新堆尾部,然后将交换后的较小的堆顶元素下沉到合适位置,即可完成堆的修复,然后重复 交换——重构大顶堆——交换 的过程,直至排序完成。完整的代码如下:
//sort7:堆排序
//通过下沉方式实现
#include至此,已经对基于非叶节点下沉方法的堆排序做了说明,堆排序比较难以理解但是非常经典,也是唯一一个能达到对数时间复杂度的原地排序算法。虽然由于堆排序无法很好的利用缓存导致现代系统中很少使用它,但是其深邃的思想仍然值得我们去解读和钻研。
7.3 算法性能
堆排序是一种最坏情况下时间复杂度不会超过 2 n l o g n 2nlogn 2nlogn 的原地排序算法,对于堆排序算法:
时间复杂度:
- O ( n l o g n ) O(nlogn) O(nlogn)
空间复杂度:
- O ( 1 ) O(1) O(1)
上面介绍的排序方法都是比较排序,下面介绍的3中排序方法则属于非比较排序,之所以不需要比较是因为有辅助的记号帮助其比较元素大小。
8、计数排序
计数排序(Counting Sort) 是一种比较土豪所以效率很高的排序算法,它用大量的额外内存换取了很低的排序时间复杂度。计数排序一般仅仅用于整数排序,其思想和LeetCode 739 每日温度的官方解法的思想比较类似。
8.1 核心思想
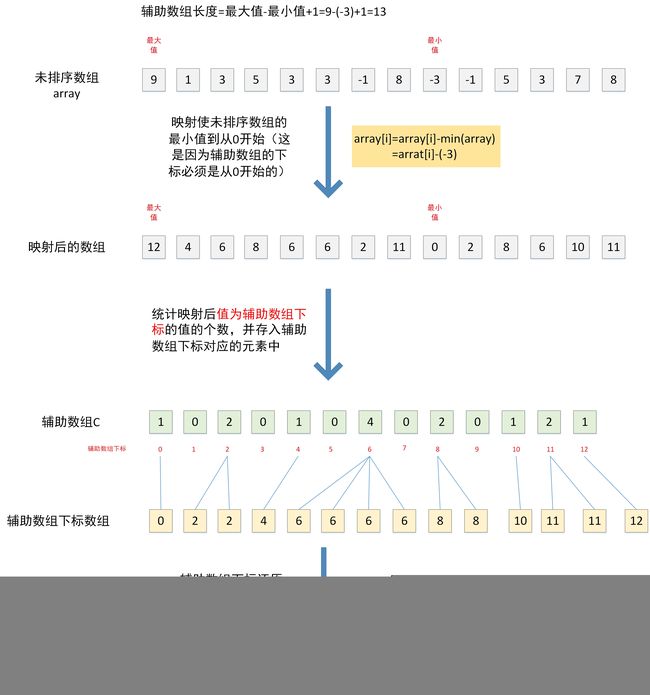
计数排序需要一个辅助数组,辅助数组的第 i ( i = 0 , 1 , 2... [ m a x ( a r r a y ) − m i n ( a r r a y ) ] ) i(i=0,1,2...[max(array)-min(array)]) i(i=0,1,2...[max(array)−min(array)]) 个元素的值是待排序数组中值为 i + m i n ( a r r a y ) i+min(array) i+min(array) 的元素的个数。也就是说,辅助数组的下标和待排序数组中元素的值是对应的,这样,有序数组下标是有序的,因此只需统计辅助数组某个下标对应的值,就可以知道待排序数组中值为 下 标 + m i n ( a r r a y ) 下标+min(array) 下标+min(array) 的元素的个数,然后根据这个个数将待排序数组的 下 标 + m i n ( a r r a y ) 下标+min(array) 下标+min(array) 依次排列,就完成了数组的排序。计数排序的过程如下:
8.2 代码实现
有上面的图示可以知道计数排序的步骤为:
- 求出待排序数组array的最大值max和最小值min.
- 声明一个大小为 m a x − m i n + 1 max-min+1 max−min+1 的辅助数组.
- 将待排序数组从 [ m i n , m a x ] [min,max] [min,max] 映射到区间 [ 0 , m a x − m i n ] [0,max-min] [0,max−min].
- 统计映射后的待排序数组值为 i i i 的元素的个数,并将其个数作为辅助数组下标为 i i i 的元素值.
- 利用辅助数组得到排序后的数组.
其代码实现如下:
//sort8:计数排序
#include上面的算法还可以做一点小小的改进,那就是将映射和排序放在一起:
//sort8_1:计数排序小改进
#include由于我们使用的是数组这种数据结构辅助排序,使得计数排序在特殊情况如数组中元素跨度很大如:
10000000 , 0 , 101 , 101 , 100 , 100 , 100 , 99 {10000000,0,101,101,100,100,100,99} 10000000,0,101,101,100,100,100,99
这种情况下,按照计数排序的原理,需要的辅助数组长度为10000001,需要浪费大量的额外空间。但是对于密集的、跨度范围小的数组,计数排序效率极高。
8.3 算法性能
对于计数排序,假设数组长度为 n n n ,辅助数组长度 k = m a x − m i n + 1 k=max-min+1 k=max−min+1,则:
时间复杂度:
- O ( n + k ) O(n+k) O(n+k)
空间复杂度:
- O ( k ) O(k) O(k)
9、桶排序
9.1 核心思想
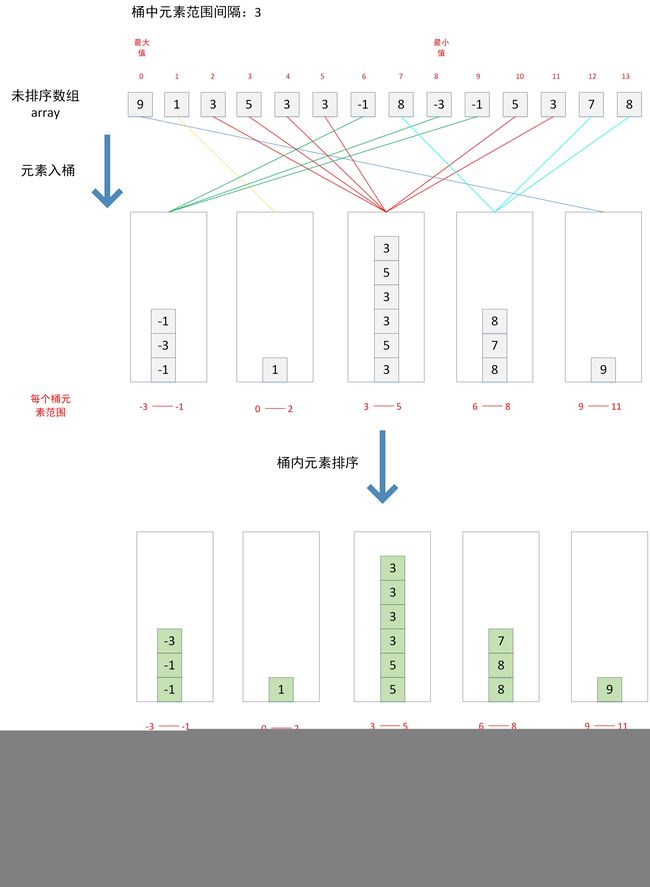
桶排序(Bucket Sort) 的核心思想是将待排序数组划分为数个范围(数个桶),然后分别对每个非空桶进行排序,最后将所有的桶连接起来。桶排序其实也算一种分治思想,桶的范围远大,所需的额外辅助空间就越小,但是每个桶排序所用的时间就越长,对每个桶进行排序的时候,可以选择仍一一种排序算法(一般是用插入排序对各个桶进行排序),也可以递归使用桶排序(递归到1的时候返回)。
桶排序适用于元素基本均匀分布于数组的最大最小值区内的情况。
9.2 代码实现
我们使用链表来保存桶内的元素,这样如果桶内没有元素,则不需要占用空间,如下图所示:
对应的代码如下:
//sort9:桶排序
#include
#include> bucket(bucketCount,vector(bucketSize)); //初始化桶
vector<list<int>> bucket(bucketCount); //初始化桶
//元素入桶
for(int i=0;i<array.size();i++)
{
int pos=(array[i]-min_val)/bucketSize; //判断元素在哪个桶中
bucket[pos].push_back(array[i]); //入桶
}
//给各个桶中的元素排序,并将非空桶链接起来
int flag=0;
list<int> ans;
for(int i=0;i<bucket.size();i++)
{
if(bucket[i].size()>0)
{
++flag;
bucket[i].sort(); //给桶中的元素排序,这个算法也可以自己写
}
if(flag==1)
{
ans=bucket[i];
}
else
{
ans.merge(bucket[i]);
}
}
//打印排序后的元素
for(list<int>::iterator it=ans.begin();it!=ans.end();it++)
{
cout<<*it<<" ";
}
return 0;
}
说明:对于桶内的排序,为简单起见,使用了list的sort()方法,这里也可以换成其他排序方法,包括桶内可以不用链表保存数据,而可以采用固定长度的数组来统计数据,从而使得桶内又可以使用桶排序。
9.3 算法性能
对于桶排序,设 n n n 为待排序数组元素的个数, k k k 为桶的个数,则
最好情况下时间复杂度:
- O ( n ) O(n) O(n)
空间复杂度:
- O ( k ) O(k) O(k)
10、基数排序
10.1 核心思想
基数排序(Radix Sort) 首先对每一个数按照最低位进行排序,然后按照下一个高位进行排序,直至排序完成。基数排序利用了桶的思想,基数排序聪明的地方在于他只用10个桶,因为任何十进制数的每一位数都在0-9之间。
10.2 代码实现
基数排序有两种方法,分别是:
- 从高位到低位的排序
- 从低位到高位的排序
下面给出从低位到高位的排序算法:
//sort10:基数排序
#include
#include10.3 算法性能
设 n n n 为待排序数组的元素个数, k k k 为最大值的位数,则对于基数排序:
时间复杂度
- O ( n + k ) O(n+k) O(n+k)
空间复杂度:
- O ( m ) O(m) O(m)
其中, m = 10 m=10 m=10 是10进制数的位的范围。