流
什么是流?
Graylog“流”是一种处理信息的机制,它能够将信息实时路由到所定义的类别中。你可以定义规则,来指示什么样的信息能够进入到何种“流”中。假设将下面的3条信息发送到Graylog:
message: INSERT failed (out of disk space)
level: 3 (error)
source: database-host-1
message: Added user 'foo'.
level: 6 (informational)
source: database-host-2
message: smtp ERR: remote closed the connection
level: 3 (error)
source: application-x
你可以创建一个Database-errors的“流”,来获取你的数据库主机的每条错误信息。
使用你所定义的规则来创建一个新的“流”,选择匹配所有规则的“选项”:
- 字段level的值必须大于4
- 字段source必须匹配正则表达式:^database-host-\d+
这会将每一条达到报警级别且与数据库主机的正则表达式相匹配的信息路由到指定的“流”中。
如果一条信息满足了所有“流”中的规则,那么它就是所有“流”的一部分。
我们上面所定义的“流”会出现在“流列表”里,点击它就会显示出所有的数据库错误。
“流”的功能是在某些特定情况发生时,会发出告警。
与保存搜索的区别?
最大的区别就是能够对“流”进行实时处理。这样不仅保证了实时告警,而且可以及时转发至其它系统。想象一下,将数据库错误信息转发至另一个系统,或者定期从信息存储中读取数据而将其写入文件。在这些方面,“流”的实时处理会做的更好。
另一个区别是一条信息被处理时,我们会用“流“的ID对其进行标记,这使得我们在搜索许多复杂的”流“规则时,会相对便捷。无论你配置了多少“流”规则,内部的搜索总是如下所示,
streams:[STREAM_ID]
使用所有规则构建查询,将会导致信息存储的负载明显升高。
如何创建“流”?
- 从顶部的导航栏中,导航到“流”部分。
- 点击“创建流”。
- 输入名称和描述后,保存“流”。例如,名称—所有错误信息,描述—从每个来源中获取的所有错误信息。“流”现在已保存,但尚未激活。
- 点击刚刚创建的流的“编辑规则”。这将打开一个页面,您可以在其中管理和测试流规则。
- 选择如何评估流规则来决定哪些消息进入流:
- 信息必须符合以下所有规则(逻辑与):只有满足流中的所有规则,信息才会路由到流中。这是默认行为
- 信息必须至少匹配以下规则之一(逻辑或):如果流中的一个或多个规则得到满足,信息将被路由到流中
- 添加“流”规则,指示要检查的字段以及应满足的条件。匹配规则的一些信息,需要通过从输入加载或手动提供信息ID来获得。一旦你对结果感到满意,点击“我完成了”。
- “流”仍然处于暂停状态,单击“开始流”按钮,来激活流。
索引集
对于初学者,您应该阅读Index model,以了解Graylog中索引集功能的全面描述。
每个流都会被分配一个索引集,这个索引集控制着什么样的信息会被路由到存储在Elasticsearch中的“流”中。下图Web界面中的流概述显示为每个流分配到的索引集。

索引集可以在创建流时分配给流,并在编辑流设置时更改。
重要:
如果将另一个索引集分配给流,则Graylog不会自动将信息复制到新的Elasticsearch索引中。
除非使用pipeline规则从流中删除信息(请参阅处理管道),或者将信息路由到标有从‘所有信息’流中删除匹配项的流里。否则,默认情况下,Graylog会将每条信息路由到所有信息流中。
如果信息应该存储在与默认索引集中的设置不同的流中,后者将非常有用,例如,Web服务器访问日志应仅存储4周,而所有其他消息应存储1年。
存储要求
Graylog将每个索引集的信息写入Elasticsearch一次。这意味着如果所有流都使用默认索引集,则每个信息将被精确写入Elasticsearch一次,而不管信息已发送多少流。这可以被认为是一种重复数据删除。
如果某些流使用其他索引集,并且未启用从‘所有信息’流中删除匹配项的设置,信息将至少写入Elasticsearch两次,一次为默认索引集,一次为已分配的索引集。这意味着相同的信息将存储在具有不同索引设置的Elasticsearch中的两个或多个索引中。
除非您明确要在不同的Elasticsearch索引中多次存储信息,否则将默认索引集分配给相应的流,或者为相应的“流”启用从‘所有信息’流中删除匹配项的设置。
输出
“流”输出系统允许您将路由到“流”中的每条信息转发到其他目的地。
输出是全局管理(如信息输入),而不是单个流。您可以创建新的输出,并根据需要激活它们。这样,您可以配置转发目的地一次,并选择多个流来使用它。
Graylog带有默认输出,可以使用Plugins扩展。
使用案例
以下是“流”的使用案例:
- 转发一部分消息到其他数据分析或BI系统以降低其许可证成本
- 监视整个环境中的异常或错误率,并分解每个子系统
- 获取所有SSH登录失败的名单列表,并使用“快速值”分析受影响的用户名
- 获取所有HTTP POST请求"/login",并将其发送到称为“成功用户登录”的流中。现在可以获得用户登录时的图表,并使用“快速值”获取在搜索时间范围内执行最多登录操作的用户列表。
内部流如何处理?
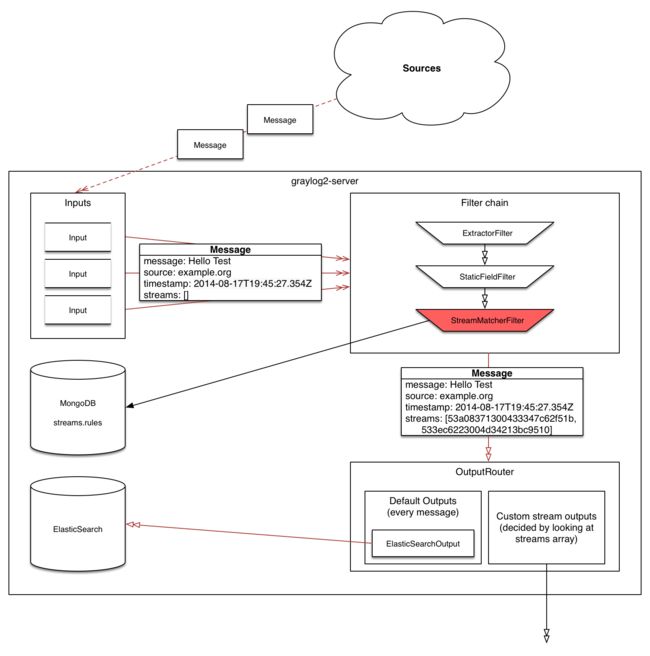
进入流中的每个消息都与该流的规则相匹配。对于满足所有或至少一个流规则(如流中配置)的消息,该流的内部ID存储在这个被处理的消息的“streams”阵列中。
与“流”绑定在一起的所有分析方法和搜索现在可以通过“streams:[STREAM_ID]”的限定搜索轻松地缩小其操作范围。这是由Graylog自动完成的,不需要由用户提供。
流处理运行时间的限制
消息处理过程中的一个重要步骤就是流分类。每条消息都与用户配置的流规则相匹配。如果消息与流的全部或任意一个规则匹配,则根据用户选择的内容,该消息将添加到流中。仅在消息索引期间完成应用流规则,那么消息分类所用的时间量对于系统可以处理的整体性能和消息吞吐量来说至关重要。
流规则需要非常长的时间才能匹配某些情况。当这种情况发生在多个消息时,消息处理会停止,等待处理的消息在存储器中累积,并且整个系统可能变得不响应。消息丢失,手动干预是必要的。这是最糟糕的情况。为了防止这种情况发生,匹配流规则的运行时间是有限制的。当它比配置的运行时间更长时,匹配此消息与特定流规则的过程将中止。一般情况下,信息处理和此特定的信息会继续进行下去。当运行时间需要配置很长时(通常,比常规流规则匹配需要更久的时间),其中任何的超时都将视为故障,并记录在流中。
如果单个流所记录的故障数量高于配置的阈值,则认为该流的流规则集是故障的,禁用该流。这样做是为了保护消息处理的整体稳定性和性能。显然,这是一个权衡,基于这一假设,一个或多个消息的总损失比这些流分类的丢失更糟糕。
有些情况可能不适用甚至有害。如果消息负载波动很大,包括消息负载远远高于系统可以处理的情况,总体流匹配所花费的时间可能比配置的超时时间长。
如果重复发生,所有流都将被禁用。这是一个清晰的指标,表明您的系统被滥用,无法处理峰值信息负载。
如果默认值不匹配,如何配置超时值
在服务器的配置文件中有两个配置变量,这些变量会影响此功能的行为。
stream_processing_timeout 定义流的规则可以花费的最长时间。当超过此值时,该流的流规则匹配中止,并记录故障。此设置以毫秒为单位定义,默认值为2000(2秒)。
stream_processing_max_faults 是单个流可以超过此运行时间限制的最大次数。当它更频繁地发生时,流被禁用,直到它被手动重新启用。此设置的默认值为3。
导致它发生的原因是什么?
如果单个流已被禁用,并且所有其他流都很好,则在某些情况下,一个或多个流规则执行不良的机会很高。在大多数情况下,这与使用正则表达式的流规则相关。对于大多数其他流规则类型,常规运行时间是常量,而正则表达式变化非常大,受正则表达式本身和与之匹配的输入的影响。在某些特殊情况下,正则表达式的匹配和不匹配之间的差异可能在100甚至1000的数量级之间。这是由称为catastrophic backtracking的现象引起的。网上有相关的介绍,这将有助于您了解它。
总结:我该如何解决?
- 检查被禁用的可能需要很长时间的流规则(特别是正则表达式)。
- 修改或删除这些流规则。
- 重新启用流。
通过REST API进行编程访问
许多组织已经运行监控设施,能够在检测到事件时提醒操作人员。
这些系统通常能够定期轮询信息或推出新的警报 - 本文介绍如何使用Graylog Stream Alert API轮询当前活动的警报,以便在第三方产品中进一步处理它们
检查当前激活的警报/触发条件
当一个或多个相关联的警报条件评估为true时,目前可以将Graylog流警报配置为发送电子邮件。发送电子邮件解决了许多与警报相关的直接问题,可以有助于获得对当前活动警报的编程访问。
具有警报配置的流还具有激活警报的列表,如果到目前为止没有警报,其可以为空。使用流的ID,并通过经身份验证的API调用来检查目前与流相关联的警报条件的状态:
GET /streams//alerts/check
它返回的内容是对配置的条件的描述以及触发警报的数量。该数据可用于在监控系统的其他部分发送SNMP陷阱。
示例JSON返回值
{
"total_triggered": 0,
"results": [
{
"condition": {
"id": "984d04d5-1791-4500-a17e-cd9621cc2ea7",
"in_grace": false,
"created_at": "2014-06-11T12:42:50.312Z",
"parameters": {
"field": "one_minute_rate",
"grace": 1,
"time": 1,
"backlog": 0,
"threshold_type": "lower",
"type": "mean",
"threshold": 1
},
"creator_user_id": "admin",
"type": "field_value"
},
"triggered": false
}
],
"calculated_at": "2014-06-12T13:44:20.704Z"
}
请注意,结果缓存了30秒。
已经触发的流警报列表
在其他监视系统中,检查当前流的警报状态对于触发警报是非常有用的,但是如果要向操作发送更详细的消息,则有助于获取有关流的当前状态的更多信息,例如自一定时间戳以来所有触发警报的列表。
该信息可以在每个流中使用,通过使用下面的表达:
GET /streams//alerts?since=1402460923
since参数是一个unix时间戳值。其返回值可以是
{
"total": 1,
"alerts": [
{
"id": "539878473004e72240a5c829",
"condition_id": "984d04d5-1791-4500-a17e-cd9621cc2ea7",
"condition_parameters": {
"field": "one_minute_rate",
"grace": 1,
"time": 1,
"backlog": 0,
"threshold_type": "lower",
"type": "mean",
"threshold": 1
},
"description": "Field one_minute_rate had a mean of 0.0 in the last 1 minutes with trigger condition lower than 1.0. (Current grace time: 1 minutes)",
"triggered_at": "2014-06-11T15:39:51.780Z",
"stream_id": "53984d8630042acb39c79f84"
}
]
}
使用此信息可以产生更详细的消息,因为此响应包含着更详细的警报信息,以及自提供时间戳以来所触发的警报数。
请注意,目前最多将返回300个警报。
常见
使用正则表达式进行流匹配
流规则支持使用正则表达式匹配字段值。Graylog使用Java Pattern来执行正则表达式。
对于正则表达式语法的各个元素,请参阅Oracle的文档,但是语法大体上遵循当今广泛使用的正则表达式语言,大多数人都会熟悉这些语法。
然而,经常提出的一个关键问题是匹配一个不区分大小写的字符串。默认情况下,Java正则表达式区分大小写。某些标志,例如忽略大小写敏感的标志,可以在代码中设置,也可以作为正则表达式中的内联标志。
例如,在以下用户代理字符串中路由匹配浏览器名称的每条消息:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36
正则表达式 .applewebkit. 将不匹配,因为它是区分大小写的。为了使用任何大写和小写字符组合匹配表达式,请使用(?i)标志:
(?i).*applewebkit.*
Java支持的大多数其他标志很少在匹配流规则或提取器的上下文中使用,但是如果您需要它们,则它们的使用文档在Oracle的Javadoc页面上。
处理和存储流后,可以添加消息吗?
不,目前没有办法将消息重新处理或重新匹配到流中。
只有新消息被路由到当前流集合中。
可以编写自己的输出,警报条件或者通知吗?
是。请参阅Plugins文档页面。http://docs.graylog.org/en/2.3/pages/plugins.html