- 利用纯Go语言编写的开源的支持分布式的高并发、重量级爬虫软件Pholcus(幽灵蛛)爬取慕课网课程、章节等并入库MongoDB。
写在前面
个人非常热爱慕课网,在慕课网学习两年多了,收获很大,编写此爬虫目的纯粹为了学习Pholcus, 爬虫也并未爬取慕课网视频地址(其实慕课的视频地址不是那么容易就能爬到的,好像是分割成了1M左右的小视频),没有其他任何商业用途。同时也希望网友能爱护慕课网,如果要爬,请轻爬!
爬取说明
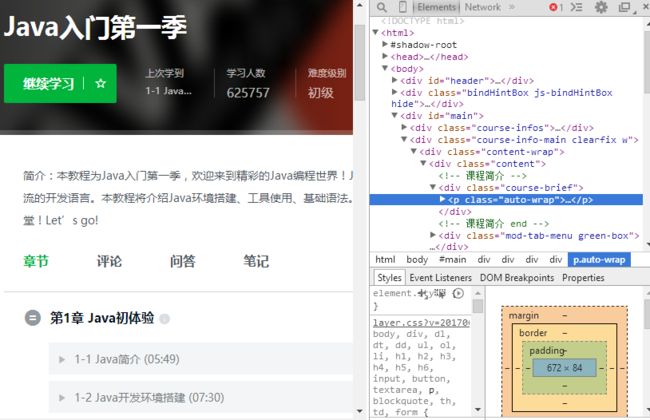
- 在图1页面爬取课程名称、课程简介等,然后点击进入在图2页面爬取学习人数、课程章节等内容。最后如图3写入数据库。
- 爬取过程中,图1中爬取的内容并不直接如果,而是通过
struct request中的temp字段以及SetTemp()、GetTemp()讲图1中内容与图2中的内容整合后写入数据库。- 因为慕课网课程内容层级结构类似于JSON,所以数据库考虑使用MongoDB,实现图3效果。
 Paste_Image.png
Paste_Image.png
Paste_Image.png
 Paste_Image.png
Paste_Image.png
Paste_Image.png

Paste_Image.png
Spider源码
package imooc
import (
"strconv"
"strings"
"encoding/json"
//"io/ioutil"
"log"
"net/http"
"regexp"
"fmt"
"github.com/henrylee2cn/pholcus/app/downloader/request"
. "github.com/henrylee2cn/pholcus/app/spider"
"github.com/henrylee2cn/pholcus/common/goquery"
)
func init() {
Imooc.Register()
}
func cleanHTML(s string) string {
s = strings.Replace(s, " ", "", -1)
s = strings.Replace(s, "\n", "", -1)
s = strings.Replace(s, "\t", "", -1)
return s
}
type Data struct {
id string `json:"id"`
Numbers string `json:"numbers"`
}
type AjaxCourseMembers struct {
result int `json:"result"`
Data []Data `json:"data"`
msg string `json:"msg"`
}
var chapterin = make(map[string]string)
var Score = make(map[string]string)
var chapterout = make(map[string]interface{})
var chapterall = make(map[string]interface{})
var Imooc = &Spider{
Name: "Imooc",
Description: "慕课网课程,[Auto Page][imooc.com]",
EnableCookie: false,
RuleTree: &RuleTree{
Root: func(ctx *Context) {
ctx.AddQueue(&request.Request{Url: "http://www.imooc.com/course/list", Rule: "首页请求"})
},
Trunk: map[string]*Rule{
"首页请求": {
ParseFunc: func(ctx *Context) {
tmpMp, _ := ctx.GetDom().Find("div.page").Find("a").Eq(8).Attr("href")
maxPage, _ := strconv.Atoi(strings.TrimLeft(tmpMp, "/course/list?page="))
ctx.Aid(map[string]interface{}{"loop": [2]int{1, maxPage}, "Rule": "所有课程"}, "所有课程")
},
},
"所有课程": {
AidFunc: func(ctx *Context, aid map[string]interface{}) interface{} {
for loop := aid["loop"].([2]int); loop[0] < loop[1]; loop[0]++ {
ctx.AddQueue(&request.Request{
Url: "http://www.imooc.com/course/list?page=" + strconv.Itoa(loop[0]),
Rule: aid["Rule"].(string),
})
}
return nil
},
ParseFunc: func(ctx *Context) {
query := ctx.GetDom().Find(".index-card-container")
query.Each(func(i int, goq *goquery.Selection) {
CourseTitle := goq.Find(".course-card-name").Text()
TechStack := goq.Find(".course-card-top span").Text()
Introduction := goq.Find("p").Text()
Attr, ok := goq.Find(".course-card").Attr("href")
CourseUrlNumber := strings.Join(regexp.MustCompile("[0-9]").FindAllString(Attr, -1), "")
url := "http://www.imooc.com/course/AjaxCourseMembers?ids=" + CourseUrlNumber
resp, err := http.Get(url)
/***
if err != nil {
log.Println("ERROR:", err)
return
}
doc1, _ := ioutil.ReadAll(resp.Body)
ajaxCourseMembers := &AjaxCourseMembers{}
if err:= json.Unmarshal([]byte(string(doc1)), &ajaxCourseMembers);err!=nil{
log.Println("ERROR:", err)
return
}
***/
//myjson, _ := ioutil.ReadAll(resp.Body)
//fmt.Println(string(myjson)) //resp的body内容OK
if err != nil {
log.Println("ERROR:", err)
}
defer resp.Body.Close()
ajaxCourseMembers := &AjaxCourseMembers{}
if err := json.NewDecoder(resp.Body).Decode(&ajaxCourseMembers); err != nil {
log.Println("ERROR:", err)
}
//LearnerNumber:=ajaxCourseMembers.data[0].Numbers //此处,这么写更加方便。
LearnerNumber := ajaxCourseMembers.getnumbers()
if ok == true {
ctx.AddQueue(&request.Request{
Url: "http://www.imooc.com" + Attr,
Rule: "课程详细信息",
Temp: map[string]interface{}{
"CourseTitle": CourseTitle,
"TechStack": TechStack,
"Introduction": Introduction,
"LearnerNumber": LearnerNumber,
},
})
}
})
},
},
"课程详细信息": {
ItemFields: []string{
"课程名称",
"课程分类",
"课程简介",
"学习人数",
"课程介绍",
"课程路径",
"难度级别",
"课程时长",
"评分",
"章节",
},
ParseFunc: func(ctx *Context) {
dom := ctx.GetDom()
query := dom.Find(".mod-chapters > div")
Summary := cleanHTML(dom.Find("div.course-brief").Text())
CoursePath := cleanHTML(dom.Find(".course-infos").Find(".path").Text())
Difficulty := dom.Find(".course-infos").Find("div.static-item").Eq(1).Find(".meta-value").Text()
Duration := dom.Find(".course-infos").Find("div.static-item").Eq(2).Find(".meta-value").Text()
scoretmp := dom.Find(".course-infos").Find(".score-btn")
vScore0 := scoretmp.Find("span").Eq(0).Text()
vScore1 := scoretmp.Find("span").Eq(1).Text()
vScore2 := scoretmp.Find("span").Eq(2).Text()
vScore3 := scoretmp.Find("span").Eq(3).Text()
vScore4 := scoretmp.Find("span").Eq(4).Text()
vScore5 := scoretmp.Find("span").Eq(5).Text()
vScore6 := scoretmp.Find("span").Eq(6).Text()
vScore7 := scoretmp.Find("span").Eq(7).Text()
vScore8 := scoretmp.Find("span").Eq(8).Text()
Score[vScore0] = vScore1
Score["评价数"] = vScore2
Score[vScore4] = vScore3
Score[vScore6] = vScore5
Score[vScore8] = vScore7
query.Each(func(i int, goq *goquery.Selection) {
ChapterH1 := cleanHTML(goq.Find("strong").After("i").Text())
ctx.SetTemp("ChapterH1", ChapterH1)
Chapter2_html := goq.Find("ul.video>li")
Chapter2_html.Each(func(_ int, goq1 *goquery.Selection) {
Chapter2_url, _ := goq1.Find("a").Attr("href")
Chapter2 := cleanHTML(goq1.Find("a").After("button").Text())
chapterin[Chapter2] = "www.imooc.com" + cleanHTML(Chapter2_url)
ctx.SetTemp("JsonChapterH1", chapterin)
})
chapterout[ctx.GetTemp("ChapterH1", "").(string)] = ctx.GetTemp("JsonChapterH1", "")
chapterall[ctx.GetTemp("CourseTitle", "").(string)] = chapterout
chapterin = make(map[string]string)
})
chapterout = make(map[string]interface{})
ctx.Output(map[int]interface{}{
0: ctx.GetTemp("CourseTitle", "").(string),
1: ctx.GetTemp("TechStack", "").(string),
2: ctx.GetTemp("Introduction", "").(string),
3: ctx.GetTemp("LearnerNumber", "").(string),
4: Summary,
5: CoursePath,
6: Difficulty,
7: Duration,
8: Score,
9: chapterall[ctx.GetTemp("CourseTitle", "").(string)],
})
chapterall = make(map[string]interface{})
Score = make(map[string]string)
},
},
},
},
}
func (s *AjaxCourseMembers) getnumbers() string {
return s.Data[0].Numbers
}
源码说明
- 如上面爬取说明->2中说明,代码第115行的
temp字段临时存放页面1爬取到的字段,并传递到下一个Rule(这是跨Rule字段传递);代172、174等行中的SetTemp()、GetTemp()在同一请求下存取以及获取临时字段(这是同Rule字段传递)。- 如图4,页面2中的人数字段是通过Ajax动态加载的,所以需要通过相关接口单独获取JSON格式的人数字段。如图5,在代码第82、83行通过
http.Get()返回Response。- 在代码100~107行用
json.NewDecoder(resp.Body).Decode解析JSON。