Nutch&Lucene
Nutch
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然 不利于广大Internet用户.
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码 搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的 费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有 动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
组成
爬虫crawler和查询searcher。
Crawler主要用于从网络上抓取网页并为这些网页建立索引。Searcher主要利用这些索引检索用户的查找关键词来产生查找结果。两者之间的接口是索引,所以除去索引部分,两者之间的耦合度很低。
Crawler和Searcher两部分尽量分开的目的主要是为了使两部分可以分布式配置在硬件平台上,例如将Crawler和Searcher分别放在两个主机上,这样可以提升性能。
Lucene
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。也是目前最为流行的基于 Java 开源全文检索工具包。
目前已经有很多应用程序的搜索功能是基于 Lucene 的,比如 Eclipse 的帮助系统的搜索功能。Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化成文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。不指定要索引的文档的格式也使 Lucene 能够几乎适用于所有的搜索应用程序。
下图表示了搜索应用程序和 Lucene 之间的关系,也反映了利用 Lucene 构建搜索应用程序的流程:
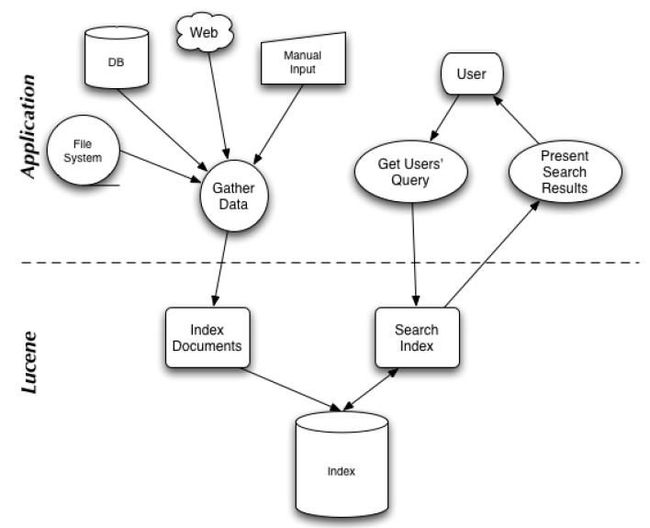
区别
Lucene其实是一个提供全文文本搜索的函数库,它不是一个应用软件。它提供很多API函数让你可以运用到各种实际应用程序中。现在,它已经成为Apache的一个项目并被广泛应用着。这里列出一些已经使用Lucene的系统。
Nutch是一个建立在Lucene核心之上的Web搜索的实现,它是一个真正的应用程序。也就是说,你可以直接下载下来拿过来用。它在 Lucene的基础上加了网络爬虫和一些和Web相关的东东。其目的就是想从一个简单的站内索引和搜索推广到全球网络的搜索上,就像Google和 Yahoo一样。当然,和那些巨人竞争,你得动一些脑筋,想一些办法。
总的来说,我认为LUCENE会应用在本地服务器的网站内部搜索,而Nutch则扩展到整个网络、Internet的检索。当然LUCENE加上爬虫程序等就会成为Nutch,这样理解应该没错吧。
题外话
apache lucene是apache下一个著名的开源搜索引擎内核,基于Java技术,处理索引,拼写检查,点击高亮和其他分析,分词等技术。
nutch和solr原来都是lucene下的子项目。但后来nutch独立成为独立项目。nutch是2004年由俄勒冈州立大学开源实验室模仿google搜索引擎创立的开源搜索引擎,后归于apache旗下。nutch主要完成抓取,提取内容等工作。
solr则是基于lucene的搜索界面。提供XML/HTTP 和 JSON/Python/Ruby API,提供搜索入口,点击高亮,缓存,备份和管理界面。
hadoop原来是nutch下的分布式任务子项目,现在也成为apache下的顶级项目。nutch可以利用hadoop进行分布式多任务抓取和分析存储工作。
所以,lucene,nutch,solr,hadoop一起工作,是能完成一个中型的搜索引擎工作的。