Hadoop HDFS API 操作图文详解及参数解读
HDFS是Hadoop的分布式文件系统,负责海量数据的存取
HDFS系列文章请参考:
- 一、HDFS 概述 | 优缺点 | 组成架构 | 文件块大小
- 二、HDFS 常用Shell命令 | 图文详解
- 三、HDFS 搭建客户端 API 环境 | 图文详解 | 提供依赖下载连接
- 四、HDFS API 操作图文详解及参数解读
- 五、HDFS 读写流程 | 图文详解
- 六、HDFS | NameNode和SecondaryNameNode的工作机制
- 七、HDFS | DataNode工作机制 | 数据完整性 | 掉线时限参数设置

文章目录
- 零、使用API的套路
- 一、获取FileSystem对象
- 二、释放FileSystem资源
- 三、使用FileSystem对象
-
- 1、创建文件夹 mkdirs()
- 2、上传文件 copyFromLocalFile()
- 3、下载文件 copyToLocalFile()
- 4、文件的更名和移动 rename()
- 5、删除文件或目录 delete()
- 6、查看文件详情 表格整理!
- 7、判断文件还是文件夹 isFile() | isDirectory()
可以点击这些文字去学习如何Hadoop搭建客户端API环境
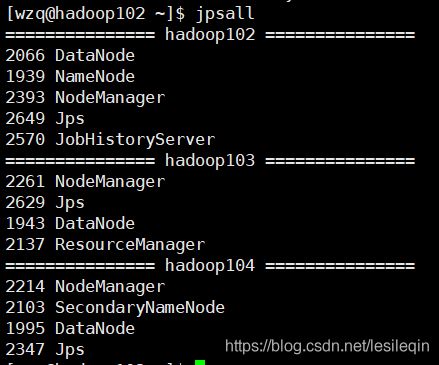
在进行下列操作之前,要确保Hadoop集群出于开启状态:
零、使用API的套路
使用API操作HDFS的套路有三步:
- 获取
FileSystem,即执行操作的对象 - 使用
FileSystem执行相关的操作 - 释放
FileSystem资源
下面就按照这个套路使用API操作:
一、获取FileSystem对象
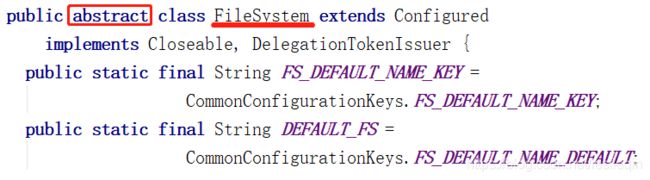
首先获取FileSystem对象,因为FileSystem是一个抽象类(看下图的源码)所以只能get,不能new:
获取FileSystem需要使用FileSystem.get(),
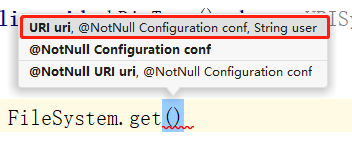
如上图所示,他需要三个参数,分别是:
-
URI uri:要连接的HDFS地址,HDFS在Hadoop的内部通讯端口是:8020,使用的是HDFS传输协议,所以这个参数可以写做hdfs://hadoop102:8020 -
Configuration configuration:这是获取FileSystem所需要的配置信息,现在可以先不写配置,直接new出来获取的时候,添加进去就好了如果这里要写配置,比如设置副本数量:
configuration.set("dfs.replication",2); -
String user:这个是hadoop用户的id,这个可以不写,但是不写的后果是:没有权限做操作,建议还是写上
接下来就可以写Java代码了,为了方便后续调用,可以直接抽取为一个方法(当然一些固定的字符串,以后在做大项目的时候,都可以使用Spring的DI机制抽取为配置类,这里就先不做了)
private FileSystem fs;
/**
* 获取文件系统
* @throws URISyntaxException
* @throws IOException
* @throws InterruptedException
*/
@Before
public void Init() throws URISyntaxException, IOException, InterruptedException {
//连接到Hadoop102的URI
URI uri = new URI("hdfs://hadoop102:8020");
//获取创建FileSystem所需要的配置信息
Configuration configuration = new Configuration();
//连接到HDFS的用户名
String user = "wzq";
//因为FileSystem是一个抽象类
fs = FileSystem.get(uri, configuration, user);
}
注:方法上面标注了
@Before注解,这是Junit‘的注解,它的意思是:在执行测试类时先执行该方法
二、释放FileSystem资源
这里先把释放FileSystem资源的代码写了,方便在下面的环节使用FileSystem测试方便
和连接数据库之类的都一样,使用完FileSystem需要把资源释放掉,只要调用FileSystem的close方法就好了,同样,直接把关闭释放资源的代码抽取为一个方法:
/**
* 释放资源
* @throws IOException
*/
@After
public void close() throws IOException {
fs.close();
}
住:方法上的
@After注解也是Junit自带的,它的意思是在执行完测试方法后再执行该方法
三、使用FileSystem对象
1、创建文件夹 mkdirs()
创建文件夹只需要调用FileSystem的一个方法mkdirs,这个方法只写一个参数,就是创建文件夹的路径Path,这个比较简单直接上代码:
/**
* 创建文件夹
*/
@Test
public void mkDirTest() throws URISyntaxException, IOException, InterruptedException{
fs.mkdirs(new Path("/xiyou/huaguoshan"));
}
注:因为已经将获取与释放
FIleSystem抽取为方法,并且使用Junit注解规定分别在方法执行前与方法执行后执行,所以测试方法只需要写使用FileSystem的代码就好了
点击运行,然后到http://hadoop102:9870上查看:
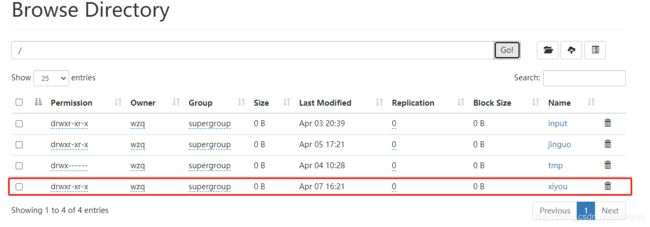
可以看到我们的文件夹已经被上传了
2、上传文件 copyFromLocalFile()
上传文件使用FileSystem对象的copyFromLocalFile()方法,他需要传递很多的参数,如下图所示:
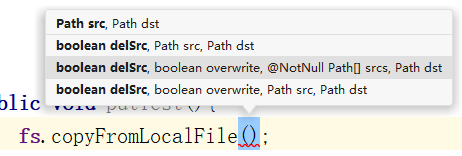
直接选取一个需要最多的参数说一下:
boolean delSrc:该参数填一个布尔值,即true还是false,如果为true则代表删除本地的数据,反之不删除。可有可无boolean overwrite:也为一个布尔值,表示如果文件重名且路径一致是否允许覆盖HDFS现存的文件。可有可无Path[] srcs或Path src:可以填一个Path[]数组也可以只填一个Path,这里是本地文件的绝对路径。必须有其中一个Path dst:该参数为目的地路径。必须有
现在创建一个sunwukong.txt在里面写sunwukong:
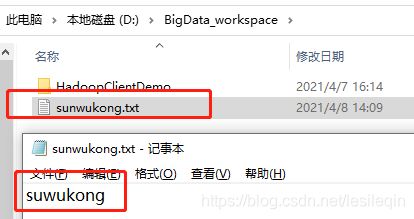
需求是:上传到/xiyou/huaguoshan/路径下,上传完成之后删除该文件
/**
* 上传文件
* @throws IOException
*/
@Test
public void putTest() throws IOException {
fs.copyFromLocalFile(true, false,
new Path("D:\\BigData_workspace\\sunwukong.txt"),
new Path("/xiyou/huaguoshan"));
}
HDFS已有该文件:

本地已经没有该文件了:
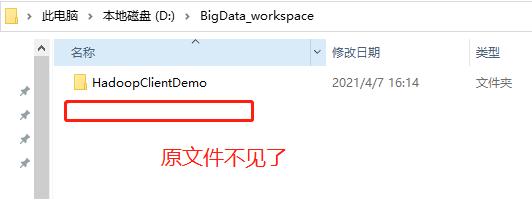
3、下载文件 copyToLocalFile()
下载文件使用FileSystem的copyToLocalFile()方法,他也有很多的参数:
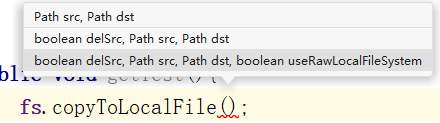
参数解读:
boolean delSrc:填布尔值,表示是否将原文件删除。可有可无Path src:要下载的文件路径。必须有Path dst:要将文件下载到客户端的哪个路径。必须有boolean useRawLocalFileSystem:因为网络传输有他的不稳定性,在传输文件时候一般都会有一些校验的方法,比如奇偶校验、CRC循环冗余校验,Hadoop采用的是CRC循环冗余校验,该参数表示是否启用文件的校验。可有可无
现在的需求是:下载/xiyou/huaguoshan/sunwukong.txt到本地D:\BigData_workspace,开启文件校验,不删除原文件:
/**
* 下载文件
* @throws IOException
*/
@Test
public void getTest() throws IOException {
fs.copyToLocalFile(false,
new Path("/xiyou/huaguoshan/sunwukong.txt"),
new Path("D:\\BigData_workspace\\sunwukong.txt"),
true);
}
注:如果上面代码不能运行,可能缺少微软运行库,请点击这些字安装微软运行库
效果:

4、文件的更名和移动 rename()
文件的更名和移动使用FileSystem的rename()方法实现,他有两个参数:
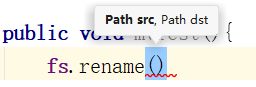
参数解读:
Path src:原文件地址Path dst:要移动或者重命名到的地址
需求:把/xiyou/huaguoshan/sunwukong.txt文件移动到根目录,并更名为meihouwang.txt:
/**
* 文件的更名或移动
* @throws IOException
*/
@Test
public void mvTest() throws IOException {
fs.rename(new Path("/xiyou/huaguoshan/sunwukong.txt"),
new Path("/meihouwang.txt"));
}
测试:

5、删除文件或目录 delete()
删除文件和目录使用FileSystem对象的delete()方法实现。他有两个参数:
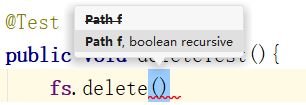
参数解读:
Path f:要删除的文件或目录的路径boolean recursive:是否递归删除,如果是个文件夹,则需要标记为true
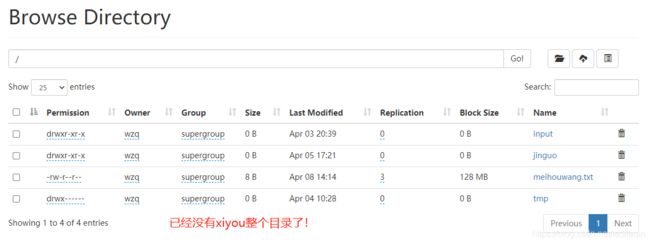
需求:删除/xiyou整个文件夹:
/**
* 删除文件或文件夹
* @throws IOException
*/
@Test
public void deleteTest() throws IOException {
fs.delete(new Path("/xiyou"),true);
}
测试:
6、查看文件详情 表格整理!
使用API操作可以查看HDFS上所有的文件信息,下面对这些方法进行表格整理
| 方法 | 作用 |
|---|---|
listFiles(Path f,boolean recursive) |
要获取哪个文件夹的文件,是否递归获取 |
getPermission() |
文件权限 |
getOwner() |
文件的拥有者 |
getGroup() |
文件所属分组 |
getLen() |
文件大小 |
getModificationTime() |
文件最后修改时间 |
getReplication() |
文件存储副本数 |
getBlockSize() |
文件块大小 |
getPath() |
文件路径 |
getPath().getName() |
文件名称 |
getBlockLocations() |
文件块存储在哪个位置 |
需求:获取根目录下所有文件的详细信息:
/**
* 获取文件相信信息
* @throws IOException
*/
@Test
public void detailTest() throws IOException {
//获取根目录下所有文件
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//遍历所有文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========="+fileStatus.getPath()+"=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
//获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
测试:

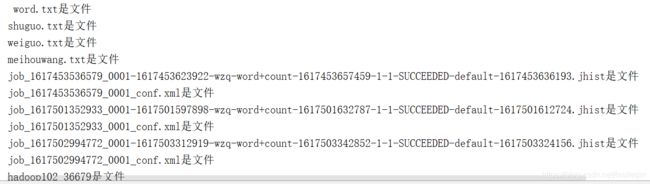
7、判断文件还是文件夹 isFile() | isDirectory()
使用isFile()来判断是不是文件,用isDirectory()判断是不是目录
/**
* 判断文件是目录还是文件
* @throws IOException
*/
@Test
public void judgeFileTest() throws IOException {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
if(fileStatus.isFile()){
System.out.println(fileStatus.getPath().getName() + "是文件");
}
if(fileStatus.isDirectory()){
System.out.println(fileStatus.getPath().getName() + "是目录");
}
}
}
测试: