文本检索问题----第六届泰迪杯C题赛后总结
一,开篇
本人参加了第六届泰迪杯,并且选择了C题。是一道文本检索的问题。要求是:可以根据官方给出的训练集跟测试集,最后在最后测试集中运行算法进行答案回答,完全相关为1,完全不相关为0.数据模式如图:

二.预处理
首先提取相关文件。文档文件为json格式文件,用python进行这次比赛。对于json文件,可用import json进行提取。其中的json.load()函数提取出来。需要注意的是文件中,以一个问题一个对象进行保存,训练集总共5000个问题。每个问题中又包括问题id(item_id),数个问题,问题有包括了内容跟passage_id。而对于答案的提问则在每个问题的最后。以下是提取部分的代码:
with open (filepath,'r',encoding='utf-8') as f:
with open (filepath1, 'w', encoding='utf-8') as a:
with open (filepath2, 'w', encoding='utf-8') as b:
lines = json.load(f)
for line in lines:
a.write(line['question']+'\n')
x.append(line['item_id'])
for kk in line['passages']:
b.write(kk['content']+'\n')
y.append(kk['passage_id'])提取出来后,查阅了相关各类资料,文献。相关资料在最后附上。
对于文本检索问题,首先需要进行对于句子或是文章的分解,将其分解为一个个词语。这时候可以下载jieba包,之后可以直接import jieba对文本进行分词操作。分词后,可以发现词语中有很多无关词语,这些我们将此称为停用词。我们应当将其全部去掉,否则会影响最后的正确率。而停用词网上也有已经完好的停用词库,大家可以自己下载使用。附上代码:
def stopwordslist(filepath):
stopwords = [line.strip () for line in open (filepath, 'r').readlines ()]
return stopwords
# 对句子进行分词
def seg_sentence(sentence):
sence =jieba.cut (sentence, cut_all=False)
sentence_seged =sence.split(" ")
stopwords = stopwordslist ("C:\\Users\\lenovo\\Desktop\\bear\\stop.txt") # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
outstr +='\n'
return outstr 在以上步骤完成后,初步数据的清洗操作完成。
三.模型建立
对于文本检索来说,广泛使用了神经网络。我推荐大家看一下《面向高考阅读理解观点类问题的答案抽取方法》这篇论文。我们最后打算根据文献,使用word2vec+SVM+LDA。博主写得是word2vec方面,最后三个算法在合起来加权。
word2vec就是对word进行embedding
首先,我们知道,在机器学习和深度学习中,对word的最简单的表示就是使用one-hot([0,0,1,0,0…..]来表示一个word). 但是用one-hot表示一个word的话,会有一些弊端:从向量中无法看出word之间的关系((wworda)Twwordb=0
(wworda)Twwordb=0),而且向量也太稀疏. 所以一些人就想着能否用更小的向量来表示一个word,希望这些向量能够承载一些语法和语义上的信息, 这就产生了word2vec
而已经有人对于word2vec进行了打包处理,各位可以直接下载使用,它在genism里面。
使用时候直接可以from gensim.models import word2vec
当你导入后,训练模型只需要一句话model=word2vec.Word2Vec(sentence,min_count=10,size=50)
保存的时候使用model.save('/model/word2vec_model')就行
导入的时候也是一句话model = word2vec.Word2Vec.load("\word2vec_model.model")
python中的word2vec自带了许多功能函数。接来下讲几个基础的
model.similarity(u"高速", u"火车")#计算两个词之间的余弦距离
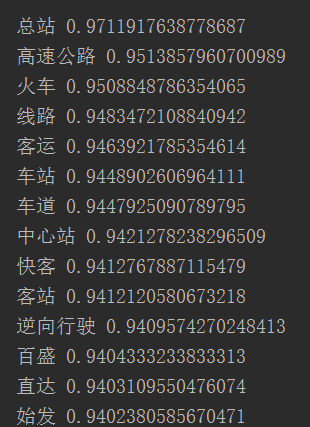
model.most_similar(u"高速")#计算余弦距离最接近“滋润”的10个词
但你可以发现这些都是单个词汇的相似性问题,处理句子的算法如下:
def pipei(s1="",s2=""):
results=[]
k = 0
for i in s1:
result=0
for j in s2:
try:
result = max(model.similarity(i,j),result)
except KeyError:
if i==j:
result = 1
results.append(result)
for kk in results:
k = k+kk
return k/len(s1)
def pp(s1,s2):
return (pipei(s1,s2)+pipei(s2,s1))/2自此,你可以求出两个句子之间的相似性,你可以用它去测量问题跟答案之间的相似度。
由于问题的id跟答案的id前五位是相同的,我们以此为匹配条件,进行匹配,进行循环。测量出的结果大概是83%左右。
之后再跟同学的算法进行加权,这里就不进行细说了。
PS:word2vec本质上是一层神经网络,正确率问题应该不高,但是这次由于理解错官方意思,在其他方面忙活了很久。耽误了时间。
第一次参赛,希望大佬不要吐槽。
score