目标检测之SPP--spatial pyramid pooling layer


crop就是从一个大图扣出网络输入大小的patch,比如227×227
warp就是把一个边界框bounding box的内容resize成227×227
但warp/crop这种预处理,导致的问题要么被拉伸变形、要么物体不全,限制了识别精确度。没太明白?说句人话就是,一张16:9比例的图片你硬是要Resize成1:1的图片,你说图片失真不?

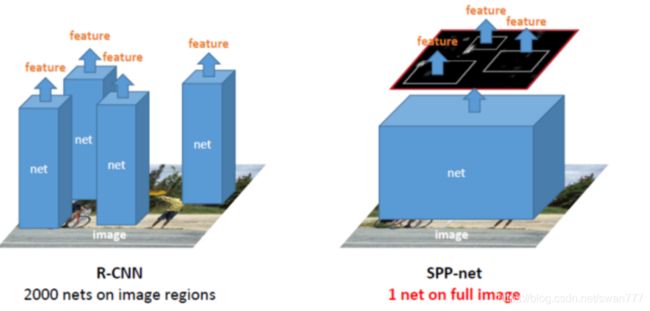
SPP Net训练和测试的方法基本一样
一张任意尺寸的图片,在最后的卷积层conv5可以得到特征图。根据Region proposal步骤可以得到很多候选区域,这个候选区域可以在特征图上找到相同位置对应的窗口,然后使用SPP,每个窗口都可以得到一个固定长度的输出。将这个输出输入到全连接层里面。这样,图片只需要经过一次CNN,候选区域特征直接从整张图片特征图上提取。在训练这个特征提取网络的时候,使用分类任务得到的网络,固定前面的卷积层,只微调后面的全连接层。
在检测的后面模块,仍然和R-CNN一样,使用SVM和边框回归。SVM的特征输入是FC层,边框回归特征使用SPP层。


SPP层的输入
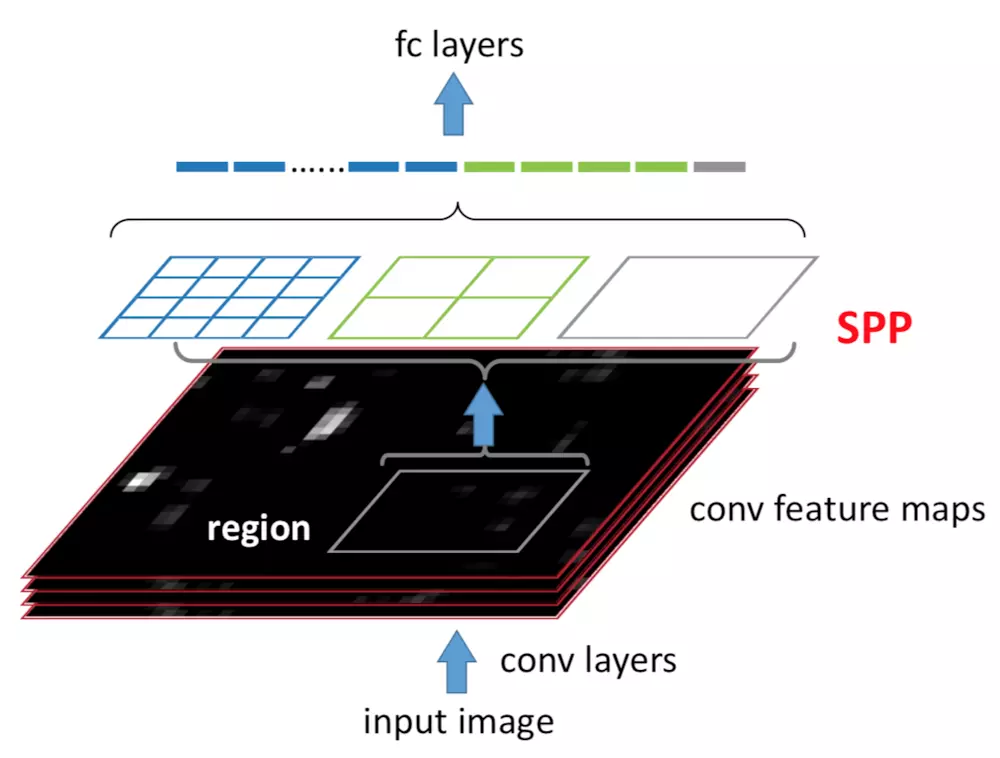
在conv5层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为4*4、2*2、1*1,然后每个网格做max pooling,这样256层特征图就形成了16*256,4*256,1*256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。
SPP层的输出:
SPP layer分成1x1,2x2,4x4三个pooling结构(这部分结构如下图所示),对每个输入(这里每个输入大小是不一样的)都作max pooling(论文使用的),出来的特征再连接到一起,就是(16+4+1)x256的特征向量。

如果base net使用VGG,现在假使前面卷积层提取的feature map尺寸为(N,W,H,512),其中N为一个batch的图片数,W,H为任意值,那么怎样获得统一尺度的特征向量呢?
具体的池化规则相当于为:stride = ⌊a/n⌋⌊a/n⌋ window size = ⌈a/n⌉⌈a/n⌉ 其中n为每层最终输出的feature map边长, a为经过最后一层卷积层后的feature map的边长。 这样对于每一层的输出都是固定的,将各层的输出拼接起来作为FC层的输入,(在单尺度情况下,我们知道了输入图片的大小,那么就可以提前计算出“池化金字塔”每层需要几乘几的格子,并来池化,同时SPP也起到了多尺度训练的作用。)
网络结构如下:
Feature Map (N,W,H,512)
上图蓝色层: (N,W,H,512),每个蓝色子方框:(N,W/4,H/4,512)
上图绿色层: (N,W,H,512),每个绿色子方框:(N,W/2,H/2,512)
上图灰色层: (N,W,H,512),每个灰色子方框:(N,W,H,512) -------其实就相当于原feature map
然后我们对以上3个图层中的子方框分别进行global maxpooling
蓝色层一共有16个子方框,绿色层一共有4个,灰色层有1个,最终再将所有经过global maxpooling的特征向量融合,得到(N,512*21),最后在输入全连接层。
无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像中候选区域尺寸如何,SPP层的输出永远是(16+4+1)x256特征向量。
如下图所示

2*2得到4个值,同理4*4的到16个值,1*1得到1个值,总共21个值
候选区域在原图与feature map之间的映射关系
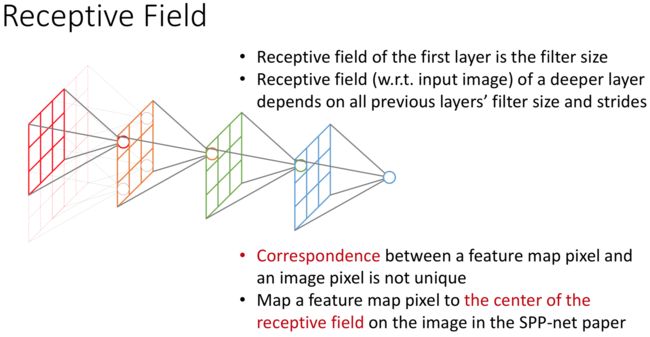
这部分的计算其实就是感受野大小的计算。
在CNN中感受野(receptive fields)是指某一层输出结果中一个元素所对应的上一层的区域大小,如下图所示。
先定义几个参数,参数的定义参考吴恩达在cousera讲解中对符号的定义,然后再讲解怎么计算

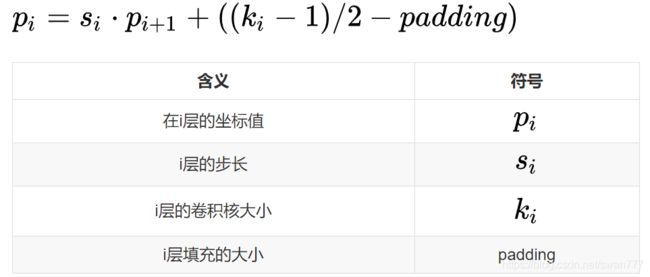
输入的尺寸大小与输出的尺寸大小有如下关系:

上面是区域尺寸大小的对应关系,下面看一下坐标点之间的对应关系:
SPP-net对上面的坐标对应关系作了一定的简化,简化过程如下:

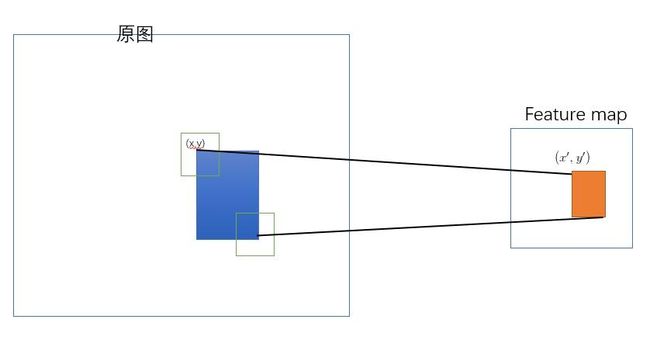
那么对于下图的做法,就是SPP-net的映射方法,SPP-net 是把原始ROI的左上角和右下角 映射到 feature map上的两个对应点。 有了feature map上的两队角点就确定了 对应的 feature map 区域(下图中橙色)。

多尺度训练与测试
理论上SPP-Net可以用于任何尺寸的图片输入,但在训练时候不能随意输入任意大小的图片,因为“池化金字塔”的n x n “bins“需要提前设定,不同的尺寸的图片用同一Spatital Pyramid Pooling可能会输出不同规格的feature map。
训练过程中,其实使用的是共享参数的多个固定尺寸的网络实现了不同输入尺寸的SPP-Net。其中从一个尺寸编导另一个尺寸使用的缩放而不是裁剪,这样不同尺度的区域仅仅是分辨率上的不同,内容与布局没有变化。
为了降低从一个网络(比如224)向另一个网络(比如180)切换的开销,在每个网络上训练一个完整的epoch,然后在下一个完成的epoch再切换到另一个网络(权重保留)。依此往复。实验中发现多尺寸训练的收敛速度和单尺寸差不多。多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸.
注意,上面的多尺寸解析度只用于训练。在测试阶段,是直接对各种尺寸的图像应用SPP-net的。
如何将原图的proposal映射到到feature map上
为了简单起见,对每一层卷积层进行padding,大小为⌊p/2⌋⌊p/2⌋,其中pp为卷积核的边长,这样卷积过程中feature map规格不会变,这样原图上的某点(x,y)(x,y) 与在 feature map上相应点(x′,y′)(x′,y′)的关系为: 左(上)边界x′=⌊x/S⌋+1,x′=⌊x/S⌋+1, 右(下)边界 x′=⌈x/S⌉−1x′=⌈x/S⌉−1, 同时,如果padding不是⌊p/2⌋⌊p/2⌋,需要对x进行一些补偿。
PS: paper中直接给出结论, 具体证明还没有去做,之后补上

- 虽然解决了R-CNN许多大量冗余计算的问题,但是还是沿用了R-CNN的训练结构,也训练了SVM分类器, 单独进行BBox regression。
- SPP-Net 很难通过fine-tuning对SPP-layer之前的网络进行参数微调,效率会很低,原因具体是(Fast-RCNN中的解释): SPP做fine-tuning时输入是多个不同的图片,这样对于每一个图片都要重新产出新的feature map,效率很低,而Fast-RCNN对其进行了改进。
参考:
https://blog.csdn.net/nanhnu/article/details/78872815
https://www.cnblogs.com/kk17/p/9748378.html#spatital-pyramid-pooling