总览
浏览器的主要组件有
- 用户界面 - 不解释
- 浏览器引擎 - 在用户界面和渲染引擎之间传送指令
- 渲染引擎 - 负责显示请求的内容。例如,如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器 - 用于解析和执行 JavaScript 代码。
- 数据存储 - 这是持久层。浏览器可能需要在本地保存各种数据,例如 Cookie。HTML5 中,浏览器也支持新的存储机制,如localStorage、IndexedDB、WebSQL和文件系统。

需要注意的是,和大多数浏览器不同,Chrome 浏览器的每个标签页都分别对应一个渲染引擎实例。每个标签页都是一个独立的进程。可以在任务管理器中看到有多个 Chrome 进程。
这篇文章主要介绍渲染引擎。
渲染引擎
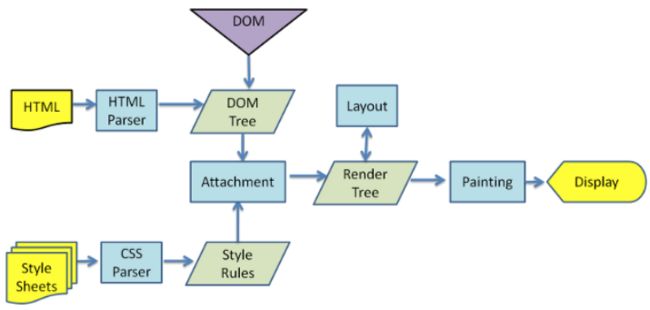
渲染引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在 8kB 以内。然后进行如下所示的基本渲染流程:

(1) 渲染引擎开始解析 HTML 文档,并将各 HTML 标记逐个转化成“内容树”上的DOM 节点。
(2) 同时也会解析外部 CSS 文件以及元素中的样式数据。HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构:“呈现树” (RenderTree)。呈现树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。
(3) 呈现树构建完毕之后,进入“布局”(Layout) 处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。
(4) 下一个阶段是"绘制"(Painting) - 渲染引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来。
需要着重指出的是,这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档都解析完毕,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,渲染引擎会先将部分内容解析并显示出来。
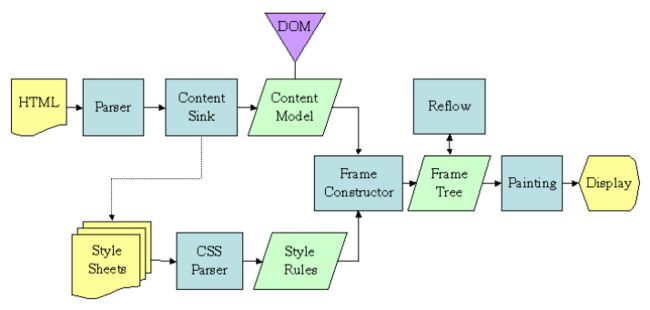
从上两图可看出,两种内核的浏览器的流程大致是一致的。
Gecko 将视觉格式化元素组成的树称为“框架树FrameTree”。每个元素都是一个框架。Webkit 使用的术语是“呈现树RenderTree”,它由“呈现对象”组成。
对于元素的放置,Webkit 使用的术语是“布局Layout”,而 Gecko 称之为“重排Reflow”。
对于连接 DOM 节点和可视化信息从而创建呈现树的过程,Webkit 使用的术语是“附加Attachment”,Gecko 称之为“框架构造FrameConstructor”。
有一个细微的非语义差别,就是 Gecko 在 HTML 与 DOM 树之间还有一个称为“内容槽ContentSink”的层,用于生成 DOM 元素。
下面详细介绍每一流程:
1. HTML Parser
1.1 解析
解析文档是指将文档转化成为有意义的结构,也就是可让代码理解和使用的结构。解析得到的结果通常是代表了文档结构的节点树,它称作解析树或者语法树。
例如 解析 2 + 3 - 1 这个表达式,会返回下面的树(中序遍历):
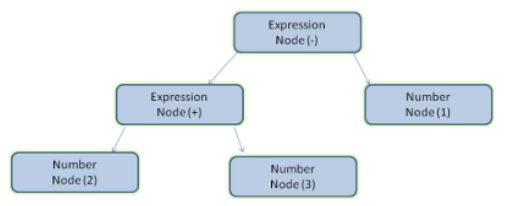
解析是以文档所遵循的语法规则为基础的。所有可以解析的格式都必须对应确定的语法(由词汇和语法规则构成)。这称为上下文无关的语法。人类语言并不属于这样的语言,因此无法用常规的解析技术进行解析。
解析的过程可以分成两个子过程:词法分析和语法分析。
词法分析是将输入内容分割成大量标记的过程
标记是语言中的词汇,即构成内容的单位。在人类语言中,它相当于语言字典中的所有单词。
语法分析是应用语言的语法规则的过程。
解析器通常将解析工作分给以下两个组件来处理:词法分析器(有时也称为标记生成器),负责将输入内容分解成一个个有效标记;而解析器负责根据语言的语法规则分析文档的结构,从而构建解析树。词法分析器知道如何将无关的字符(比如空格和换行符)分离出来。
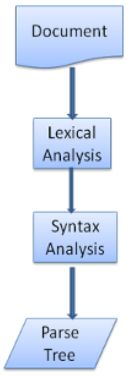
解析是一个迭代的过程。通常,解析器会向词法分析器请求一个新标记,并尝试将其与某条语法规则进行匹配。如果发现了匹配规则,解析器会将一个对应于该标记的节点添加到解析树中,然后继续请求下一个标记。
如果没有规则可以匹配,解析器就会将标记存储到内部,并继续请求标记,直至找到可与所有内部存储的标记匹配的规则。如果找不到任何匹配规则,解析器就会引发一个异常。这意味着文档无效,包含语法错误。
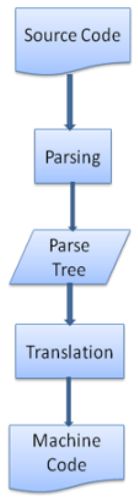
1.2 翻译
很多时候,解析树还不是最终产品。解析通常是在翻译过程中使用的,而翻译是指将输入文档转换成另一种格式。编译就是这样一个例子。编译器可将源代码编译成机器代码,具体过程是首先将源代码解析成解析树,然后将解析树翻译成机器代码文档。
1.3 解析示例
前面通过数学表达式建立了解析树。现在,让我们试着定义一个简单的数学语言,用来演示解析的过程。
词汇:整数、加号和减号。
语法:
- 构成语言的语法单位是表达式、项和运算符。
- 我们用的语言可以包含任意数量的表达式。
- 表达式的定义是:一个“项”接一个“运算符”,然后再接一个“项”。
- 运算符是加号或减号。
- 项是一个整数或一个表达式。
让我们分析一下 2 + 3 - 1
匹配语法规则的第一个子串是 2 ,而根据第 5 条语法规则,这是一个项。匹配语法规则的第二个子串是 2 + 3 ,而根据第 3 条规则(一个项接一个运算符,然后再接一个项),这是一个表达式。下一个匹配项已经到了输入的结束。 2 + 3 - 1 是一个表达式,因为我们已经知道 2 + 3 是一个项,这样就符合“一个项接一个运算符,然后再接一个项”的规则。 2 + + 不与任何规则匹配,因此是无效的输入。
1.4 解析器类型
自上而下解析器
从语法的高层结构出发,尝试从中找到匹配的结构
从上面那个例子来看
首先将 2 + 3 标识为一个表达式,然后将 2 + 3 - 1 标识为一个表达式(标识表达式的过程涉及到匹配其他规则,但是起点是最高级别的规则)
自下而上解析器
自下而上的解析器将扫描输入内容,找到匹配的规则后,将匹配的输入内容替换成规则。如此继续替换,直到输入内容的结尾。部分匹配的表达式保存在解析器的堆栈中。
| 堆栈 | 输入 |
|---|---|
2 + 3 - 1 |
|
| 项 | + 3 - 1 |
| 项 运算 | 3 - 1 |
| 表达式 | - 1 |
| 表达式运算符 | 1 |
| 表达式 | |
这种自下而上的解析器称为移位归约解析器,因为输入在向右移位(设想有一个指针从输入内容的开头移动到结尾),并且逐渐归约到语法规则上
1.5 HTML解析器
HTML 解析器的任务是将 HTML 标记解析成解析树。HTML 并不能很容易地用解析器所需的与上下文无关的语法来定义。
有一种可以定义 HTML 的正规格式:DTD(Document Type Definition,文档类型定义),但它不是与上下文无关的语法。
概括地说,HTML 无法很容易地通过常规解析器解析(因为它的语法不是与上下文无关的语法),也无法通过 XML 解析器来解析,因为 HTML 的处理比XML更为“宽容”,它允许省略某些隐式添加的标记,有时还能省略一些起始或者结束标记等等。
具体如何解析稍后会讲。
1.6 DOM
解析器的输出“解析树”是由 DOM 元素和属性节点构成的树结构。DOM 是文档对象模型 (Document Object Model) 的缩写。它是 HTML 文档的对象表示,同时也是外部内容(例如 JavaScript)与 HTML 元素之间的接口。
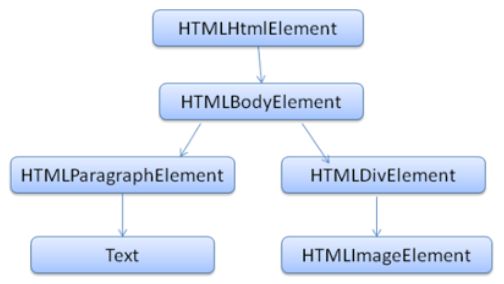
DOM 与标记之间几乎是一一对应的关系。比如下面这段标记:
Hello World

可解析成如下的 DOM 树:
1.7 解析算法
我们在之前章节已经说过,HTML 无法用常规的自上而下或自下而上的解析器进行解析。原因在于:
- 语言的宽容本质
- 浏览器历来对一些常见的无效 HTML 用法采取包容态度
- 解析过程需要不断地反复。源内容在解析过程中通常不会改变,但是在 HTML 中,脚本标记如果包含 document.write,就会添加额外的标记,这样解析过程实际上就更改了输入内容
HTML5规范详细描述了解析算法。此算法由两个阶段组成:标记化和树构建。
标记化是词法分析过程,将输入内容解析成多个标记。
HTML 标记包括起始标记、结束标记、属性名称和属性值。
标记生成器识别标记,传递给树构造器,然后接受下一个字符以识别下一个标记;如此反复直到输入的结束。

1.7.1 标记化算法
该算法的输出结果是 HTML 标记。
该算法使用状态机来表示。每一个状态接收来自输入信息流的一个或多个字符,并根据这些字符更新下一个状态。当前的标记化状态和树结构状态会影响进入下一状态的决定。
这意味着,即使接收的字符相同,对于下一个正确的状态也会产生不同的结果,具体取决于当前的状态。该算法相当复杂,无法在此详述,所以我们通过一个简单的示例来帮助大家理解其原理。
Hello world
初始状态是数据状态。
遇到字符 < 时,状态更改为“标记打开状态”。接收一个 a-z 字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收 > 字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。
遇到 > 标记时,会发送当前的标记,状态改回“数据状态”。 标记也会进行同样的处
理。目前 html 和 body 标记均已发出。现在我们回到“数据状态”。接收到 Hello world 中的 H 字符时,将创建并发送字符标记,直到接收 中的 < 。我们将为 Hello world 中的每个
字符都发送一个字符标记。
现在我们回到“标记打开状态”。接收下一个输入字符 / 时,会创建 end tag token 并改为“标记名称状态”。我们会再次保持这个状态,直到接收> 。然后将发送新的标记,并回到“数据状态”。