python3+selenium+pytest实现web自动化框架——基础知识整理
前言
什么时候,什么项目/功能需要做web自动化
- web自动化不像接口那么追求用例覆盖率;
- 一般用在跑正向主流程(冒烟)、回归测试上;
- 需求稳定,不频繁变更的功能;
- 周期较长的,比如节日活动这些基本不会复用的功能就不做自动化;
- 复用性高,可以跨系统跨平台使用的功能;
- 流程设计规范(文档齐全)的功能;
- 需要注意web自动化相对接口自动化,更繁琐、成本高,效率低,但web自动化还是有必要的。
流程(和手工测试的流程其实是一致的)
- 1.打开浏览器,webdriver.Chrome()
- 2.输入网址 get
- 3.找到要操作的元素 find_element()
- 4.点点点 click()
- 5.断言 Assert()
- 6.关闭浏览器 quit()
- 7.测试报告
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(2)
el = driver.find_element_by_id("kw")
el.send_keys("selenium实现web自动化")
expected = ""
actual = ""
assert expected == actual
driver.quit()
web自动化的工作原理
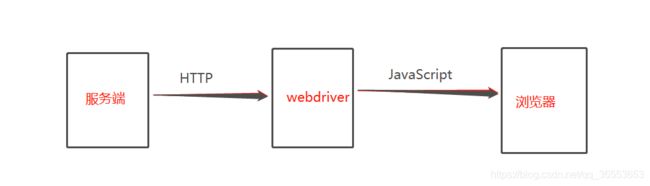
1.Python无法直接操作浏览器,因为浏览器中不存在Python环境;
2.浏览器内置了JavaScript的解释器,开发人员开发的前端页面也是使用JavaScript进行编写,每个浏览器中都存在js运行环境;
3.所以Python要想操作浏览器,就需要借助一个浏览器驱动webdriver去操作,由python向webdriver发送http请求(通过requests库发送)
4.webdriver运行时提供很多接口,当Python去访问webdriver的某个接口,如openbrowser,就会打开浏览器;
5.驱动接收到url地址请求后,就表示要打开一个浏览器,驱动就会告诉js,去打开浏览器。
所以本质上能发http请求的语言都能用来做web自动化。而selenium就是封装了上述这样一个过程,有了上面的概念,下面画个简图总结下selenium的工作原理:
环境准备
① python3 ,直接官网下载安装并配置环境变量
https://www.python.org/downloads/
② selenium,一个用于Web应用程序测试的工具,可以通过pip安装:pip install selenium
③ 浏览器,常用的谷歌、火狐等,本文基于Chrome讲解
④浏览器驱动,可以在淘宝镜像下下载
https://npm.taobao.org/mirrors/chromedriver
⑤ pytest,基于python的第三方单元测试框架,相比于unittest,功能更强大,支持很多插件,更自由的定义fixture装载测试用例。## TODO:pytest的paramatrize和fixture和unittest不兼容,其它功能兼容.
通过pip安装:pip install pytest
一、元素定位
都说搞好元素定位,web自动化就成功了一半,下面我们一起看下元素定位都有哪些坑坑绕绕吧
- 元素定位的概念:找到要操作的元素,找到操作页面组件的源代码;
- 元素定位的依据:根据元素特征进行定位;
- 查找元素得到的是一个WebElement对象。
传说中的8大元素定位
1)8大元素定位都有哪些?
① find_element_by_tag_name()
② find_element_by_id()
- 在一个页面中,有id是唯一的,有id尽量用id查找
③ find_element_by_name()
④ find_element_by_class_name()
- 查找的class_name不能是复核class,即class_name不能有空格
- 如果class_name有空格,可以考虑取一个来定位,或者用xpath
⑤ find_element_by_link_text()
- 链接的文本,只能用来定位链接(a)标签
⑥ find_element_by_partial_link_text()
- 部分链接的文本
⑦ find_element_by_xpath()
⑧ find_element_by_css_selector()
2)都有哪些坑或需要注意的地方?
① 前六种都是根据单一属性定位有局限性,xpath和css可以组合属性来定位
- xpath适合复杂元素定位
- css适合简单元素定位
② find_element和find_elements的区别
- 鱼钩和渔网的区别
- find_element只会找一个,如果匹配多个,只会返回第一个
- find_elements查找多个,返回一个列表
③ 查看定位元素是否唯一的小技巧
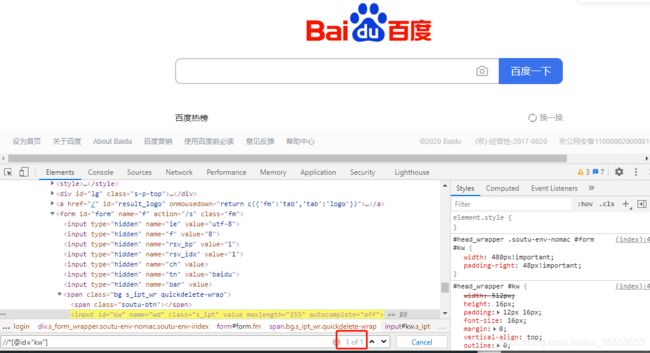
④ 如果元素找不到NoSuchElementException,可以排查以下原因
- 元素定位表达式是否正确
- 有没有等待
- 有没有在指定窗口
- 元素有没有在iframe中
- 弹窗alert是否关闭
⑤ 需要注意不规则的字符串,或者是变化的属性值,这种最好不要用来定位。
xpath定位
1) 格式
//找的标签名称[@属性名="属性值"]
//找的标签名称[@属性名="属性值" and @属性名2="属性值2"] # 单一条件无法定位时,用and连个多个条件
//*[@id="s-top-left"]/a[3] 相对路径,测试中一般都用相对路径
/html/body/div[2]/div/form/div[1]/input 绝对路径
2) 组合上下级关系
# 父亲找儿子,用/。以下等价,百度搜素框为例
//span[@id='']/input
//span/input[@class='s_ipt']
# 祖父找孙子,用//
//form[@id='form']//input[@name='wd']
# 儿子找父亲
//input[@id='kw']/..
# 儿子找祖先,逻辑是父亲的父亲的父亲,无限套娃
//input[@id='kw']/../../.. 不建议使用
# 查找兄弟姐妹,逻辑是通过..找父亲,再通过/找儿子
//input[@id='kw']/../span[1]
3)索引定位
- 从1开始
- xpath计算的索引优先级很高,记得加()
4) 组合text
//*[text()='新闻']
//a[contains(text(),'新')
5) 函数组合:contains(依据,值)模糊查找
//a[contains(text(),'闻')]
//a[text()='新闻' and contains(@class,'mnav c-font-normal c-color-t')]
6) 轴定位
# 儿子找父亲,找上级节点。parent::
//input[@id='kw']/parent::span
# 儿子找祖父,找祖父级上级节点(不限定隔几个层级)。ancestor::
//input[@id='kw']//ancestor::form[@id='form']
//input[@id='kw']//ancestor::div[@class='s_form s_form_nologin']
# 儿子找哥哥,找同级前面的节点。preceding-sibling::
//input[@id='kw']/preceding-sibling::span
#儿子找弟弟,找同级后面的节点。following-sibling::
//input[@id='kw']/following-sibling::a
css 选择器
- css vs xpath css 更简洁,xpath 更加复杂, 简单元素,css
- xpath 的功能更加强悍
- xpath 是支持使用 text 文本,text()="", 但是 css 选择器不能用 text
- css 查找元素效率会比 xpath 高一些。
# 通过 id 查找
xpath: //input[@id="kw"]
css: input#kw
# 通过 class 查找
xpath: //input[@class='s_ipt']
css: input.s_ipt
css完整格式:input[class=s_ipt]
二、等待
为什么要设置等待?
浏览器打开、刷新、加载元素等操作需要时间,而我们自动化代码的运行速度比网页加载速度快,如果代码已经执行,但浏览器元素还没加载出来,这样我们去操作页面元素就会找不到。这时候我们就需要设置等待,等浏览器加载完成。
等待有三种,强制等待,隐性等待,显性等待。
强制等待
即无论如何,都要等待指定的时长,格式如下:
import time
time.sleep(5) # 指定等待的时长
强制等待应用场景:
- 在超出 selenium 处理范围,需要和其他系统交互的时候,比如js,文件上传(系统的上传界面);
- 调试代码的时候。
隐性等待
设置一个超时时间,在这个时间内去查找元素,如果找到,执行下一步,不继续等待;如果找不到就继续查找;到达超时时间节点,还是找不到,则返回超时异常。格式如下:
tip:需要注意隐性等待设置的时间是全局生效的。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.implicitly_wait(10)
显性等待
设置一个超时时间,在这个时间内,如果不满足某个条件,都继续查找,直到满足该条件,才退出查找循环。格式如下:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
wait = WebDriverWait(driver,20,poll=frequency=0.2) # 初始化一个等待器,参数一为浏览器对象,参数二为超时时间,参数三为间隔时间
locator = ('xpath', '//*[@id='kw']') # 元素定位
el = wait.untill(expected_conditions.element_to_be_clickable(locator)).click() # 等待元素可点击再去操作点击
常用的3种条件:
expected_conditions.presence_of_element_located # 等待元素出现
expected_conditions.visibility_of_element_located # 等待元素可见
expected_conditions.element_to_be_clickable # 等待元素可以被点击
等待方式的顺序选择
1)隐性等待,初始化一个浏览器对象时,就设置隐性等待;
2)显性等待,元素找不到,就加上显性等待;
3)强制等待,如非必要,避免使用强制等待,优化 web 自动化测试的效率。
三、浏览器的一些常用基础操作
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get() # 打开网址
browser.maximize_window() # 浏览器最大化
browser.minimize_window() # 浏览器最小化
browser.set_window_size(400, 600) # 设置窗口指定大小
browser.back() # 在浏览器历史记录中后退一步
browser.forward() # 在浏览器历史记录中前几一步
browser.refresh() # 刷新页面
browser.close() # 关闭窗口
browser.quit() # 关闭浏览器
四、switch to切换
switch_to.frame()
TODO:要操作iframe中的元素,一定一定记得要先切换到iframe中!!!
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
frame_el = driver.find_element_by_xpath("//iframe[@name='baidu']")
driver.switch_to.frame(frame_el)
driver.find_element_by_id('kw')
# 使用显性等待切换到iframe
locator = ("xpath", "//iframe[@name='baidu']")
WebDriverWait(driver, 20).until( expected_conditions.frame_to_be_available_and_switch_to_it(locator)
)
# TODO: 返回主页面
driver.switch_to.default_content()
# 在一个 iframe 如果嵌套了另一个iframe。一个一个进
driver.switch_to.parent_frame()
switch_to.window()
有时候操作会打开多个窗口(对应多个Url地址),需要切换到对应窗口才能继续操作
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 获取所有窗口句柄
windows = driver.window_handles
# 获取当前窗口句柄
current_window = driver.current_window_handle
# 切换到最新窗口
driver.switch_to.window(windows[-1])
# 切换到当前窗口的下一窗口,一般也是最新窗口,相当于windows[-1]
driver.switch_to.window(windows[windows.index(driver.current_window_handle)+1])
# 执行后续操作
driver.find_element_by_xpath("//ul[@class='toolbar-menus csdn-toolbar-fl']/li[1]/a[1]").click()
switch_to.alert
切换到弹窗,注意alert没有()
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
alert = driver.switch_to.alert
# 点击确认关闭弹窗
alert.accept()
# 点击取消关闭弹窗
alert.dismiss()
五、鼠标操作,ActionChains
- move_to_element # 鼠标悬停
- double_click # 双击
- context_click right_click # 右键
- drag_and_drop # 鼠标拖拽
- click # 单击,不常用
move_to_element
from selenium.webdriver import ActionChains
def move_to(driver,locator):
"""
鼠标悬停操作
:param driver: 浏览器驱动对象
:param locator: 需要操作的元素定位,元组
"""
action = ActionChains(driver) # 初始化一个 action_chains 对象
el = WebDriverWait(driver,20).untill(expected_conditions.visibility_of_element_located(locator))
action.move_to_element(el).perform() # 后面一定要加perform()
return None
drag_and_drop
from selenium.webdriver import ActionChains
def drag_drop(driver, locator1, locator2):
"""
鼠标拖拽操作
:param driver: 浏览器驱动对象
:param locator1: 开始位置元素,元组
:param locator2: 结束位置元素,元组
:return: None
"""
wait = WebDriverWait(driver, 20)
source_el = wait.until(expected_conditions.presence_of_element_located(locator1))
target_el = wait.until(expected_conditions.presence_of_element_located(locator2))
ActionChains(driver).drag_and_drop(source_el, target_el).perform()
return None
double_click
def double_click(driver, locator):
"""
鼠标双击操作
:param driver: 浏览器驱动对象
:param locator: 需要操作的元素定位,元组
:return: None
"""
action = ActionChains(driver)
el = WebDriverWait(driver, 20).until(expected_conditions.visibility_of_element_located(locator))
action.double_click(el).perform()
context_click
def contex_click(driver,locator):
"""
鼠标右键操作
:param driver: 浏览器驱动对象
:param locator: 需要操作的元素定位,元组
:return: None
"""
action = ActionChains(driver)
el = WebDriverWait(driver, 20).until(
expected_conditions.visibility_of_element_located(locator)
)
action.context_click(el).perform()
- 为什么ActionChains 中要有 perform 才运行动作。
- _action 添加方法名称,只有调用perform才会调用方法
- 为什么 action.move_to().perform() 和 action.move_to() action.perform()效果一样 ?
- 返回 self
六、js命令,execute_script
- 通过execute_script(script, *args)提交js,script参数是js语句,*args有多个,表示js语句中的参数
- arguments[0]可以理解为format函数的{},表示占坑,[0]表示第一个js参数
- document表示对象本身
- 定义变量用var
修改属性
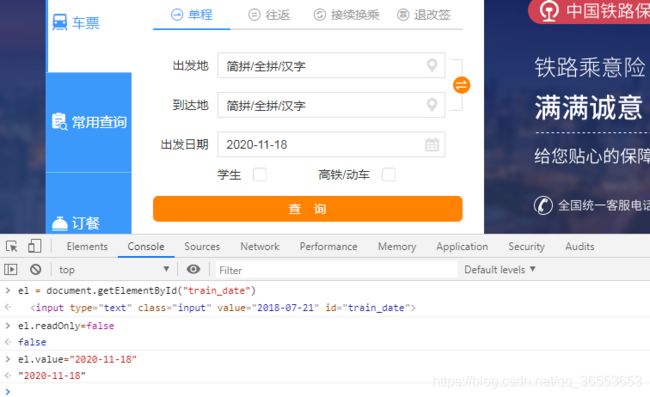
用Python实现上述截图代码
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10)
url = 'https://www.12306.cn/index/'
driver.get(url)
# 方法1,直接通过js找元素,修改属性,赋值
js_code = "var el = document.getElementById('train_date');el.readOnly = false;el.value='2020-11-12';"
driver.execute_script(js_code) # 提交js代码
time.sleep(2)
driver.quit()
# 方法 2: python 先定位元素,然后在通过 js 脚本修改元素属性。
time.sleep(2)
el = driver.find_element_by_id('train_date')
js_code = "arguments[0].readOnly = false; arguments[0].value = '2020-11-12'"
driver.execute_script(js_code, el)
time.sleep(2)
driver.quit()
窗口滚动
- srollTo(x,y)
- HTML页面中(0,0)表示左上角坐标,往右x递增,往下y递增
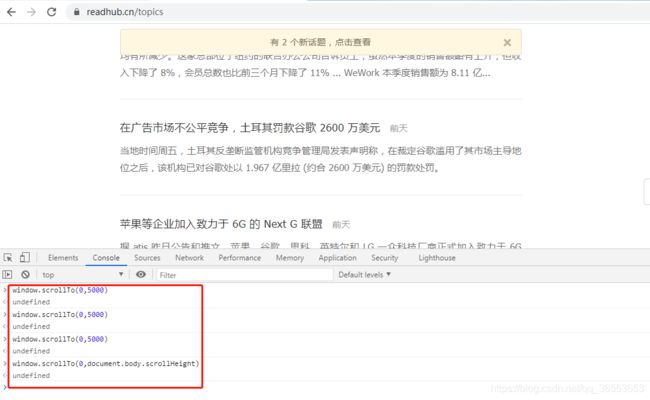
"""窗口滚动"""
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://readhub.cn/")
# 滚动到指定高度
js_code = "window.scollTo(0, 5000)"
driver.execute_script(js_code)
# 滚动到窗口底部
js_code = "window.scollTo(0, document.body.scrollHeight)"
driver.execute_script(js_code)
# 特定滚动,把元素滚动到可以看见范围之内,不是很常用
el = driver.find_element_by_xpath("//div[@class='tips___TK28D'][2]")
el.location_once_scrolled_into_view
七、文件上传
上传元素是input标签
- 都是 input,和用户输入是一样,都可以通过send_keys操作
- 文件, 用户名, 键盘
- 参数是文件的路径, 在 windows 当中,因为路径是反斜杠,在Python中有特殊含义,所以记得在路径之前加一个 r防止转义。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get(r'****')
file_el = driver.find_element_by_name("****")
file_el.send_keys(r'D:\test20201115.txt') # 传文件在本地的路径
上传元素不是input标签
- windows系统使用pywinauto,非windows系统(如mac)使用pyautogui
import time
from selenium import webdriver
from pywinauto.keyboard import send_keys
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get(r'****')
file_el = driver.find_element_by_name("user") # 找到上传文件元素
print(file_el)
time.sleep(2)
file_el.click()
time.sleep(1) # 文件上传页面是操作系统页面,不受sellenium控制,需要用强制等待
# TODO: 只能在 windows 使用
send_keys(r"d:\test20201115.log")
send_keys("{VK_RETURN}") # 回车
time.sleep(3)