在目标检测算法中,faster R-CNN达到了目前的最高mAP精度。虽然mAP使用的是一体化网络,但是其训练过程却没有实现端到端,是通过多步训练的,其仍然没有能避免提取region proposal这一步。虽然faster R-CNN精度很高,但是其检测速度却不是很快,难以达到实时检测水平,这使得它难以应用到实际工程中。本文作者提出了一种真正的端到端网络,不仅检测速度快,而且检测的mAP精度高,泛化能力强。
下面内容主要转载自<机器爱学习>YOLO v1深入理解
1、网络结构
YOLO使用的网络基础来源于GoogLeNet,只是将其中的inception module使用3x3和1x1的卷积代替了。网络结构如下:
1.1 输入与输出
网络的输入采用的是448x448大小的图片。而输出则是一个7x7*30的向量,下面对这个输出向量进行详细解释。
1.1.1 7x7网格
7x7表示输入图像被分成多少个网格,最后每一块都会输出一个预测结果,因此是7x7个预测结果。而每个网格的预测结果又包括30个值。
1.1.2 30维向量
在本文中每个网格的预测结果包括30个值,如图:
- 20个对象分类概率。由于本文中数据集有20个不同的类别,因此这里是20个类别的概率;
- 2个bounding box的置信度。bounding box的置信度 = 该bbox存在对象的概率 * 该bbox与该对象实际bbox的IOU,即 Confidence = Pr(Object) * IOU;
- 2个bounding box的位置。这里之所以是两个bbox是因为文中设置的每个网格中只预测两个bounding box的输出结果。位置信息包括bbox中心坐标(x,y)和其宽高(width,height)。
需要注意的是这里有两个概率:confidence中提到的一个bbox中存在对象的概率和这个对象属于某个类别的概率。
因此最后输出会有7x7 * ((bbox+confidence)*bbox_num + C)个结果,其中C表示类别个数。虽然每个格子都有两个bbox,但是其实最后一个格子只输出一个结果,采用的非极大抑制选择预测的比较好的那个。在本文中最后的输出就是7x7 * ((4+1)* 2 + 20)
2、训练阶段
在训练时先使用ImageNet 1000分类预训练模型,需要注意的是预训练时候输入图片的大小是224。而在检测训练时,又在模型中添加了4个卷积层和两个全连接层,这几层的权重都是随机初始化的,这样能提高网络的性能。最后的预测使用的是leaky ReLU。
2.1 训练样本构造
在上面我们知道了YOLO网络的输出是什么样子的。接下来我们看看如何准备训练集。

(1)20个对象分类的概率
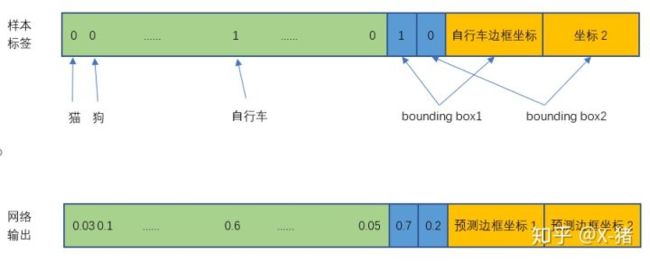
对于输入图像中的每个对象,先找到其中心点。比如图8中的自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率是1,其它对象的概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写。
(2)2个bounding box的位置
训练样本的bounding box位置应该填写对象实际的bounding box,但一个对象对应了2个bounding box,该填哪一个呢?上面讨论过,需要根据网络输出的bounding box与对象实际bounding box的IOU来选择,所以要在训练过程中动态决定到底填哪一个bounding box。参考下面第③点。
(3)2个bounding box的置信度
上式中的IOU可以利用预测的bounding box与gt bounding box一起计算出IOU。
然后看2个bounding box的IOU,哪个比较大(更接近对象实际的bounding box),就由哪个bounding box来负责预测该对象是否存在,即该bounding box的Pr(Object)=1,同时对象真实bounding box的位置也就填入该bounding box。另一个不负责预测的bounding box的 Pr(Object)=0。
总的来说就是,与对象实际bounding box最接近的那个bounding box,其 confidence = IOU,该网格的其他bounding box的confidence = 0。
举个例子,比如上图中自行车的中心点位于4行3列网格中,所以输出tensor中4行3列位置的30维向量如下图所示。
简单说这张图片的GT就是第4行第3列的网格处有一辆自行车,它的中心点在这个网格内,它的位置边框是bounding box1所填写的自行车实际边框。
注意,图中将自行车的位置放在bounding box1,但实际上是在训练过程中等网络输出以后,比较两个bounding box与自行车实际位置的IOU,自行车的位置(实际bounding box)放置在IOU比较大的那个bounding box(图中假设是bounding box1),且该bounding box的置信度设为1。
2.2 损失函数
YOLO的损失函数如下:
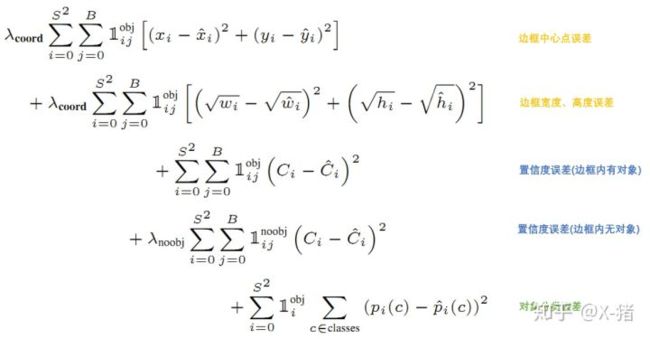
上面公式中1可以理解成指示函数{0,1}:
- 1iobj意思是网格i中存在对象;
- 1ijobj意思是网格i的第j个bounding box中存在对象;
- 1ijnoobj意思是网格i的第j个bounding box中不存在对象。
总的来说,就是用网络输出与样本标签的各项内容的误差平方和作为一个样本的整体误差。 损失函数中的几个项是与输出的30维向量中的内容相对应的。
(1)分类误差
公式第5行, 1iobj值为1即存在对象时才计算误差。
(2)bounding box的位置误差
公式第1行和第2行。
a) 都带有1ijobj意味着只有"负责"(IOU比较大)预测的那个bounding box的数据才会计入误差。
b)第2行宽度和高度先取了平方根,因为如果直接取差值的话,大的对象对差值的敏感度较低,小的对象对差值的敏感度较高,所以取平方根可以降低这种敏感度的差异,使得较大的对象和较小的对象在尺寸误差上有相似的权重。
c)乘以λcoord调节bounding box位置误差的权重(相对分类误差和置信度误差)。YOLO设置 λcoord=5,即调高位置误差的权重。
(3)bounding box置信度误差
公式第3行和第4行。
a)第3行是存在对象的bounding box的置信度误差。带有1ijobj意味着只有"负责"(IOU比较大)预测的那个bounding box的置信度才会计入误差。
b)第4行是不存在对象的bounding box的置信度误差。因为不存在对象的bounding box应该老老实实的说"我这里没有对象",也就是输出尽量低的置信度。如果它不恰当的输出较高的置信度,会与真正"负责"该对象预测的那个bounding box产生混淆。其实就像对象分类一样,正确的对象概率最好是1,所有其它对象的概率最好是0。
c)第4行会乘以 λnoobj调节不存在对象的bounding box的置信度的权重(相对其它误差)。YOLO设置λnoobj=0.5,即调低不存在对象的bounding box的置信度误差的权重。
3、预测
训练好的YOLO网络,输入一张图片,将输出一个 7730 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)。 为了从中提取出最有可能的那些对象和位置,YOLO采用NMS(Non-maximal suppression,非极大值抑制)算法。
3.1 NMS(非极大值抑制)
NMS方法并不复杂,其核心思想是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。
YOLO的NMS计算方法如下:
网络输出的7*7*30的张量,在每一个网格中,对象Ci位于第j个bounding box的得分:
它代表着某个对象 C i存在于第j个bounding box的可能性。
每个网格有:20个对象的概率*2个bounding box的置信度,共40个得分(候选对象)。49个网格共1960个得分。Andrew Ng建议每种对象分别进行NMS,那么每种对象有 1960/20=98 个得分。
NMS步骤如下:
- 1)设置一个Score的阈值,低于该阈值的候选对象排除掉(将该Score设为0);
- 2)遍历每一个对象类别;
- 2.1)遍历该对象的98个得分;
2.1.1)找到Score最大的那个对象及其bounding box,添加到输出列表;
2.1.2)对每个Score不为0的候选对象,计算其与上面2.1.1输出对象的bounding box的IOU;
2.1.3)根据预先设置的IOU阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将Score设为0);
2.1.4)如果所有bounding box要么在输出列表中,要么Score=0,则该对象类别的NMS完成,返回步骤2处理下一种对象;
3)输出列表即为预测的对象。
小结
YOLO以速度见长,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps。这得益于其识别和定位合二为一的网络设计,而且这种统一的设计也使得训练和预测可以端到端的进行,非常简便。
不足之处是(1)小对象检测效果不太好(尤其是一些聚集在一起的小对象),(2)对边框的预测准确度不是很高,总体预测精度略低于Fast RCNN。主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外Pooling层会丢失一些细节信息,对定位存在影响。 (3)模型的loss函数对待小bounding box和大bounding box是一样的,而实际上小bounding box的IOU error的影响是要远大于大bounding box 的IOU error影响的。
参考:
You Only Look Once: Unified, Real-Time Object Detection.
<机器爱学习>YOLO v1深入理解