【RL从入门到放弃】【二十六】【OpenAI gym玩打砖块游戏】
今天来看看OpenAI 团队的gym,看看能否受到启发啊!
Gym is a toolkit【工具包】 for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking to playing games like Pong or Pinball.

首页上展示的其余几个模型都是传统控制学的模型,之前也研究过。
Ant-v2
Make a four-legged creature walk forward as fast as possible.
让这个蚂蚁用四只脚尽快的往前面走。
来来来,先上一道让我胃疼的好菜。真是无语了,mujoco的安装,真是气死个人
这篇博客仅供参考
https://www.jianshu.com/p/a0a87ba6ef12
首先是安装mujoco_py,但是安装了还用不了,需要去官网上下载key,key以前可以试用一年,现在只可以试用三个月了,还必须绑定邮箱和电脑。
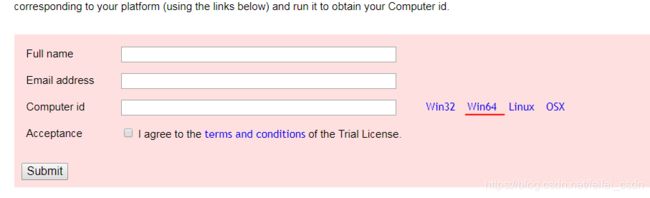
computer_id是需要点击使用他的安装包生成的。在你的邮箱里面会收到两个文件:
mjkey.txt and LICENSE.txt,将这两个文件copy到目录下:
C:\mujoco 当然这个是自己建的。
然后到官网上去下载一个mjpro131,将上面的两个文件依次copy到
以及下面的bin目录下面去:
配置环境变量:
![]()
MUJOCO_PY_MJKEY_PATH 这个对应bin的路劲
MUJOCO_PY_MJKEY_PATH 对应mjpro131的路劲
windows每次配置了环境变量都需要重启cmd窗口,使用aconda来安装的也同理了。
修改配置文件:
mujoco_py/config.py
default__key_path = os.path.expanduser('C:\\mujoco\\mjpro131\\bin\\mjkey.txt')
default_mjpro_path = os.path.expanduser('C:\\mujoco\\mjpro131')
再修改platform文件
mujoco_py/platname_targdir.py
最后一个字段,直接指定为win平台就可以了:targdir = "mujoco_win"
再修改配置文件
mujoco_py/mjlib.py
elif sys.platform.startswith("win"):
libfile = os.path.join(path_prefix, "bin/mujoco131.dll")
将lib修改为dll
最后我还遇到报错:
ERROR: Could not open activation key file C:\mujoco\mjpro131\bin
我发现他只是到了配置的环境变量,没有到具体的key文件【网上都是到了具体的key文件】
所以再次修改配置文件:
mujoco_py/config.py
#if not _key_path and os.path.exists(default__key_path):
_key_path = default__key_path
#if not mjpro_path and os.path.exists(default_mjpro_path):
mjpro_path = default_mjpro_path
基于上面为什么修改很多,或者是坑很多,是因为在开发的时候,根本就没有考虑windows客户的需求。
只能说坑还没有完:
https://www.jianshu.com/p/a0a87ba6ef12
说使用python 3.6, mujoco 0.5.7 with the mjpro131 package installed and gym 0.9.1这一整套配置就可以了。我惊喜地发现我默认安装了gym 0.10.5,我改成pip install gym==0.9.1,终于 work 了…
打砖头game
输入的是图片的信息,涉及到图片是不是就感觉要使用CNN来处理图像信息呢!毕竟人家是出了名的
输入是210 * 160 * 3的图像,我们稍作处理,把边上不需要的像素去掉之后降阶采样灰度化,将80 * 80 * 1的图像作为算法的输入
神经网络的输入不是单帧的图像,而是最近的连续四帧图像作为输入。这也很好理解,因为这样就加入了时间序列。对于打砖块这个游戏,如果只用一帧作输入的话,虽然砖块在同一个位置,但是可能是向好几个方向运动的,agent无法判断它的价值。
但是如果我们添加了最近几帧,agent就可以根据前后的时间判断出是向哪个方向运动的,这个状态就完整了
原文:https://blog.csdn.net/supercally/article/details/54784103
def ColorMat2Binary(self,state):#将210×160×3的彩色图片转换成80×80的二进制信息,具体调用的是opencv的intergace
#state_output = tf.image.rgb_to_grayscale(state_input)
#state_output = tf.image.crop_to_bounding_box(state_output,34,0,160,160)
#state_output = tf.image.resize_images(state_output,80,80,method=tf.image.ResizeMethod.NEAREST_NEIGHBOR )
#state_output = tf.squeeze(state_output)
#return state_output
height = state.shape[0]
width = state.shape[1]
nchannel = state.shape[2]
sHeight = int ( height * 0.5 )#210变成105
sWidth = CNN_INPUT_WIDTH #定义CNN输入的宽度是80
state_gray = cv2.cvtColor( state, cv2.COLOR_BGR2GRAY)#将RGB转换成灰度图像
#print(state_gray.shape)#去掉图片的高度
#cv2.imshow('test2',state_gray)
#cv2.waitkey(0)
_,state_binary = cv2.threshold( state_gray, 5, 255, cv2.THRESH_BINARY )#加上过滤器
#print(state_binary.shape)
#print(sHeight)
state_binarySmall = cv2.resize( state_binary, (sWidth,sHeight), interpolation = cv2.INTER_AREA )
#print(state_binarySmall.shape)
cnn_inputImg = state_binarySmall[25:, :]
#print(cnn_inputImg.shape)
#rstArray = state_graySmall.reshape(swidth * sHeight )
cnn_inputImg = cnn_inputImg.reshape ((CNN_INPUT_WIDTH, CNN_INPUT_HEIGHT ) )
return cnn_inputImg
然后我们choose_action的时候,除了一定的随机性之外,我们都是选择动作值函数最大的action
def get_greedy_action(self, state_shadow):
rst = self.Q_value.eval(feed_dict={self.input_layer: [state_shadow]})[0]#后面为什么加上0呢?因为他是二维的list
#print(self.Q_value.eval(feed_dict={self.input_layer: [state_shadow]}))
#print(rst)
#print(np.max( rst ))
return np.argmax(rst)
def get_action(self,state_shadow):
#其实可以尝试一下,不调节epsilon的效果如何呢?
if self.epsilon >= FINAL_EPSILON and self.observe_time > OBSERVE_TIME:
self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000
action = np.zeros(self.action_dim)
action_index = None
if random.random() < self.epsilon:
#所以这里还是只有3个
action_index = random.randint(0, self.action_dim - 1)
else:
action_index = self.get_greedy_action(state_shadow)
return action_index 来看q_eval的网络结构,卷积是肯定的了,但是多少层卷积呢?
在用神经网络判断价值方面,与之前不同。之前简单的训练网络是用了一个隐层的网络来实现的,但是对于处理图像的任务,我们使用的是卷积神经网络
def create_network(self):
INPUT_DEPTH = SERIES_LENGTH
self.input_layer = tf.placeholder(tf.float32, [None, CNN_INPUT_WIDTH, CNN_INPUT_HEIGHT, INPUT_DEPTH], name='status-input')
self.action_input = tf.placeholder(tf.float32, [None, self.action_dim])
self.y_input = tf.placeholder(tf.float32, [None])
W1 = self.get_weights([8, 8, 4, 32])
b1 = self.get_bias([32])
h_conv1 = tf.nn.relu(tf.nn.conv2d(self.input_layer, W1, strides=[1, 4, 4, 1], padding='SAME') + b1)
conv1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
W2 = self.get_weights([4, 4, 32, 64])
b2 = self.get_bias([64])
h_conv2 = tf.nn.relu(tf.nn.conv2d(conv1, W2, strides=[1, 2, 2, 1], padding='SAME') + b2)
# conv2 = tf.nn.max_pool( h_conv2, ksize = [ 1, 2, 2, 1 ], strides= [ 1, 2, 2, 1 ], padding= 'SAME' )
W3 = self.get_weights([3, 3, 64, 64])
b3 = self.get_bias([64])
h_conv3 = tf.nn.relu(tf.nn.conv2d(h_conv2, W3, strides=[1, 1, 1, 1], padding='SAME') + b3)
W_fc1 = self.get_weights([1600, 512])
b_fc1 = self.get_bias([512])
# h_conv2_flat = tf.reshape( h_conv2, [ -1, 11 * 11 * 32 ] )
conv3_flat = tf.reshape(h_conv3, [-1, 1600])
h_fc1 = tf.nn.relu(tf.matmul(conv3_flat, W_fc1) + b_fc1)
W_fc2 = self.get_weights([512, self.action_dim])
b_fc2 = self.get_bias([self.action_dim])
self.Q_value = tf.matmul(h_fc1, W_fc2) + b_fc2
Q_action = tf.reduce_sum(tf.multiply(self.Q_value,
self.action_input), reduction_indices=1)
self.cost = tf.reduce_mean(tf.square(self.y_input - Q_action))
self.optimizer = tf.train.AdamOptimizer(1e-6).minimize(self.cost)只看上面半部分就是3层卷积+2层全连接,其中第一层卷积还加上了一个max-pool
那卷积的loss值是如何定义的呢?上面也写了,但是感觉没明白为什么要这样做啊!
https://github.com/openai/gym/blob/master/gym/envs/atari/atari_env.py
训练的时候如何训练呢?
def train_network(self):
self.time_step += 1
minibatch = random.sample(self.replay_buffer, BATCH_SIZE)
#依次在里面取数据出来
state_batch = [data[0] for data in minibatch]
action_batch = [data[1] for data in minibatch]
reward_batch = [data[2] for data in minibatch]
next_state_batch = [data[3] for data in minibatch]
done_batch = [data[4] for data in minibatch]
y_batch = []
Q_value_batch = self.Q_value.eval(feed_dict={self.input_layer: next_state_batch})
for i in range(BATCH_SIZE):
if done_batch[i]:
y_batch.append(reward_batch[i])
else:
y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i]))
#y_batch实际上就是q现实
self.optimizer.run( feed_dict={
self.input_layer: state_batch,
self.action_input: action_batch,
self.y_input: y_batch } )
def percieve(self, state_shadow, action_index, reward, state_shadow_next, done, episode):
action = np.zeros(self.action_dim)
action[action_index] = 1 #为什么要在这里设置成1呢?
self.replay_buffer.append([state_shadow, action, reward, state_shadow_next, done]) #为什么将done也一起放在里面进行处理呢?
self.observe_time += 1
if self.observe_time % 1000 and self.observe_time <= OBSERVE_TIME == 0:
print(self.observe_time)
if len(self.replay_buffer) > REPLAY_SIZE:
self.replay_buffer.popleft() #左边的就开始弹出来了
if len(self.replay_buffer) > BATCH_SIZE and self.observe_time > OBSERVE_TIME:
#如何进行训练学习呢?
self.train_network() 为什么q估计是那样计算的呢?难道不是网络出来的结果就是直接是q估计吗?
里面的网络结构具体可以看这个:

本篇文章中神经网络的结构主要来自于DeepMind的这篇论文
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
别人的网络结构都是在著名的论文里面抄的,我要去哪里抄啊!
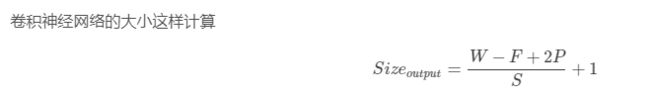
最后算出最后一个卷积层的大小是5 * 5,深度是64,所以先reshape成一组1600维的向量,就是原来的一个输入,然后再进行全连接就可以了。再经过两层全连接,得到的action_dim大小的向量,每一维就代表相应action的价值
其他的都和我们在前一篇文章里提到的大致一样。因为是图像作为输入,所以训练时间比较长,对于这个游戏,基本上训练一天以上,就能看出学习的效果有明显的增长
具体可以看看这个code:
https://github.com/feifeiyuan/python_training/blob/master/Breakout-v0
这里的神经网络不同于传统的神经网络,传统的强化学习的神经网络只有一个单独的隐藏层。
且具有目标网络,但是这里将目标网络和价值网络是没有分开的。
进入真正的Atari游戏
经过上面的讲解,我们了解到几条事实:
所谓玩游戏的策略,其实就是一张记录着Q-value的表格
这个表格可以用神经网络来替代
我们没有监督数据来训练这个网络,所有的训练数据都是由网络自身生成的,当然还有环境给出的Reward(英语有个词叫做Bootstrapping,意思是提着自己的鞋带把自己提起来)
其实我们可以什么都不做,算法自己会找出最佳策略
由于本文并不涉及如何编写代码,所以我只想用文字来描述一下,在训练的过程中到底发生了些什么。
假设我们选择了Breakout(打砖块)游戏。
起初,我们建立了一个卷积神经网络,这就是AI的大脑。网络前端接受屏幕传来的图像,网络后端只有三个输出节点,分别代表向左移动,向右移动和不移动。网络的内部参数是随机初始化的,网络末端的Q-value也基本是随机的。这个大脑里面是一片混沌,它不会根据眼前的画面做出判断,只会随机的移动屏幕最下方的“球拍”。
我们打开开关,游戏开始运行。小球开始从上方掉下来。我们的“球拍”几乎不可能接到小球。每次小球掉落下去之后游戏就结束了。但马上又重新开始。
在这个过程中,屏幕图像源源不断的从神经网络的前端传进来,通过无数随机权重的神经脉络,连接到最后端的三个输出节点上。
"大脑“在做出随机动作的同时也在不停的学习。由于根本没有获得Reward,”大脑“只是单纯的拿n+1帧的图像对应的3个Q-value作为第n帧图像的学习目标。
这时的学习其实是盲目的。用随机初始化的网络随机的生成一些数据来训练,得到的结果也必然是一片混乱。所以,在这个阶段,神经网络跟没有学习到任何有意义的东西。
直到......
小球偶尔也会落在球拍上反弹回去。击中球拍并不会获得Reward,所以网络的训练仍然和之前一样无动于衷。
当小球向上击中一个砖块的时候,游戏给出1分作为Reward。从这时开始,“训练”才真正变得有意义了。在小球击中砖块的瞬间,砖块消失不见。由于神经网络接受的是4帧连续的图像,实际上是一个小动画,记录了砖块消失的过程。在这一帧发生的训练,其输入样本用的是上一帧的4幅图像(小球马上要击中砖块),而输出样本是击中砖块后的图像通过网络所生成的3个Q-value再加上刚才得到的1分。
这一帧的训练意义非同寻常,它告诉“大脑”:在小球马上要击中砖块这样一种状态下,不论你做出什么动作,都会得到比随机水平高出1分。
这一过程不断的重复,当“大脑”经历过多次击中砖块的瞬间,它脑中的卷积核就会试图找出这些画面中有哪些共同点。终于有一天,当击中过足够多次砖块之后,“大脑”终于明白,这些画面的共同点是:画面的某处都存在一个相同的pattern——小球和砖块非常接近而且小球正在向砖块飞去。“大脑”终于明白了它人生中的第一件事。
以后的每帧图像,它都会在图像中寻找这样的pattern,如果找到了,就会在输出端的3个动作节点给出3个比平时高一点的Q-value。
这时,“大脑”并没有将得分和动作联系在一起。这3个动作对它来说价值没有什么区别。它仍然是随机的给出一些动作。
“大脑”也会发现击中砖块前两帧的图像会“导致”前一帧的图像。在小球接近砖块的过程中,算法会不断的把下一帧的Q-value拿过来作为前一帧的图像的结果来训练。
渐渐地,“大脑”会认为所有小球飞向砖块的图像都应该对应较高的Q-value。也就是说,这些状态都是“有利”的。
下一步,“大脑”会继续领悟:是小球与球拍的碰撞“导致”了小球向上运动,并有很大可能是飞向砖块。所以小球与球拍的碰撞是“有利”的。
到目前为止,“大脑”还是没有搞清楚这3个动作到底有什么区别。
游戏继续,“大脑”继续随机的发出动作。
有时候,小球会贴着球拍的边缘掉下去。只有在这个时候,才能体现出动作带来的好处。比如,小球落到球拍左边缘时,如果这时碰巧发出了一个向左的动作,那么就会引发碰撞,否则小球就会跌落下去。在引发碰撞的情况下,“大脑”会把“碰撞”的Q-value(比较高)赋给向左这个动作。而向右和不移动这两个动作得到的却只是小球落下去的Q-value(比较低)。
久而久之,“大脑”就会明白当小球将要从左边略过球拍的时候,向左的动作比较有利;将要从右边略过的时候,向右的动作比较有利。
这样推广开来,“大脑”就会慢慢的找出合适的策略,越玩越好,逐渐达到完美的程度
原文:https://blog.csdn.net/revolver/article/details/50177219