在数据分析工作中,Pandas 的使用频率是很高的,一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 json 的契合度很高,转换起来就很方便。
另一方面,如果我们日常的数据清理工作不是很复杂的话,你通常用几句 Pandas 代码就可以对数据进行规整。
Pandas 可以说是基于 NumPy 构建的含有更高级数据结构和分析能力的工具包。在 NumPy 中数据结构是围绕 ndarray 展开的,那么在 Pandas 中的核心数据结构是什么呢?
下面主要给你讲下Series 和 DataFrame 这两个核心数据结构,他们分别代表着一维的序列和二维的表结构。基于这两种数据结构,Pandas 可以对数据进行导入、清洗、处理、统计和输出。
数据结构Series 和 Dataframe
Series
Series 是个定长的字典序列。说是定长是因为在存储的时候,相当于两个 ndarray,这也是和字典结构最大的不同。因为在字典的结构里,元素的个数是不固定的。
Series 的两个基本属性有两个基本属性:index 和 values。在 Series 结构中,index 默认是 0,1,2,……递增的整数序列,当然我们也可以自己来指定索引,比如 index=[‘a’, ‘b’, ‘c’, ‘d’]。
例子:
import pandas as pd
from pandas import Series, DataFrame
x1 = Series([1,2,3,4])
x2 = Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
print (x1)
print (x2)
运行结果:
10 1
21 2
32 3
43 4
5dtype: int64
6a 1
7b 2
8c 3
9d 4
10dtype: int64
这个例子中,x1 中的 index 采用的是默认值,x2 中 index 进行了指定。我们也可以采用字典的方式来创建 Series,比如:
例子:
d = {'a':1, 'b':2, 'c':3, 'd':4}
2x3 = Series(d)3print (x3 )
运行结果:
1a 1
2b 2
3c 3
4d 4
5dtype: int64
DataFrame
DataFrame 类型数据结构类似数据库表。
它包括了行索引和列索引,我们可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
我们虚构一个考试的场景,想要输出几位英雄的考试成绩:
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
df1= DataFrame(data)
df2 = DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
print (df1)
print (df2)
在后面的案例中,我一般会用 df, df1, df2 这些作为 DataFrame 数据类型的变量名,我们以例子中的 df2 为例,
列索引是 [‘English’, ‘Math’, ‘Chinese’],行索引是 [‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’],所以 df2 的输出是:
English Math Chinese
ZhangFei 65 30 66
GuanYu 85 98 95
ZhaoYun 92 96 93
HuangZhong 88 77 90
DianWei 90 90 80
在了解了 Series 和 DataFrame 这两个数据结构后,我们就从数据处理的流程角度,来看下他们的使用方法。
Pandas 允许直接从 xlsx,csv 等文件中导入数据,也可以输出到 xlsx, csv 等文件,非常方便。
import pandas as pd
from pandas import Series, DataFrame
score = DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
print (score)
需要说明的是,在运行的过程可能会存在缺少 xlrd 和 openpyxl 包的情况,到时候如果缺少了,可以在命令行模式下使用“pip install”命令来进行安装。
数据清洗
数据清洗是数据准备过程中必不可少的环节,Pandas 也为我们提供了数据清洗的工具,在后面数据清洗的章节中会给你做详细的介绍,这里简单介绍下 Pandas 在数据清洗中的使用方法。
还是以上面这些英雄人物的数据为例。
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
df2 = DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
在数据清洗过程中,一般都会遇到以下这几种情况,下面我来简单介绍一下。
1. 删除 DataFrame 中的不必要的列或行:
Pandas 提供了一个便捷的方法 drop() 函数来删除我们不想要的列或行。比如我们想把“语文”这列删掉。
df2 = df2.drop(columns=['Chinese'])
想把“张飞”这行删掉。
df2 = df2.drop(index=['ZhangFei'])
2. 重命名列名 columns,让列表名更容易识别:
如果你想对 DataFrame 中的 columns 进行重命名,可以直接使用 rename(columns=new_names, inplace=True) 函数,比如我把列名 Chinese 改成 YuWen,English 改成 YingYu。
# inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改。
df2.rename(columns={'Chinese': 'YuWen', 'English': 'Yingyu'}, inplace = True)
3. 去重复的值:
数据采集可能存在重复的行,这时只要使用 drop_duplicates() 就会自动把重复的行去掉。
df = df.drop_duplicates() # 去除重复行
4. 格式问题:
这是个比较常用的操作,因为很多时候数据格式不规范,我们可以使用 astype 函数来规范数据格式,比如我们把 Chinese 字段的值改成 str 类型,或者 int64 可以这么写:
df2['Chinese'].astype('str')
df2['Chinese'].astype(np.int64)
数据间的空格
有时候我们先把格式转成了 str 类型,是为了方便对数据进行操作,这时想要删除数据间的空格,我们就可以使用 strip 函数:
# 删除左右两边空格
df2['Chinese']=df2['Chinese'].map(str.strip)
# 删除左边空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
# 删除右边空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
如果数据里有某个特殊的符号,我们想要删除怎么办?同样可以使用 strip 函数,比如 Chinese 字段里有美元符号,我们想把这个删掉,可以这么写:
df2['Chinese']=df2['Chinese'].str.strip('$')
大小写转换:
大小写是个比较常见的操作,比如人名、城市名等的统一都可能用到大小写的转换,在 Python 里直接使用 upper(), lower(), title() 函数,方法如下:
# 全部大写
df2.columns = df2.columns.str.upper()
# 全部小写
df2.columns = df2.columns.str.lower()
# 首字母大写
df2.columns = df2.columns.str.title()
查找空值:
数据量大的情况下,有些字段存在空值 NaN 的可能,这时就需要使用 Pandas 中的 isnull 函数进行查找。比如,我们输入一个数据表如下:
姓名 语文 英语 数学
张飞 66 65
关羽 95 85 98
赵云 95 92 96
黄忠 90 88 77
典韦 80 90 90
如果我们想看下哪个地方存在空值 NaN,可以针对数据表 df进行df.isnull():结果如下
姓名 语文 英语 数学
0 False False False True
1 False False False False
2 False False False False
3 False False False False
4 False False False False
如果我想知道哪列存在空值,可以使用 df.isnull().any(),结果如下:
姓名 False
语文 False
英语 False
数学 True
使用 apply 函数对数据进行清洗
apply 函数是 Pandas 中自由度非常高的函数,使用频率也非常高。
比如我们想对 name 列的数值都进行大写转化可以用:
df['name'] = df['name'].apply(str.upper)
我们也可以定义个函数,在 apply 中进行使用。比如定义 double_df 函数是将原来的数值 *2 进行返回。然后对 df1 中的“语文”列的数值进行 *2 处理,可以写成:
def double_df(x):
return 2*x
df1[u'语文'] = df1[u'语文'].apply(double_df)
我们也可以定义更复杂的函数,比如对于 DataFrame,我们新增两列,其中’new1’列是“语文”和“英语”成绩之和的 m 倍,'new2’列是“语文”和“英语”成绩之和的 n 倍,我们可以这样写:
def plus(df,n,m):
df['new1'] = (df[u'语文']+df[u'英语']) * m
df['new2'] = (df[u'语文']+df[u'英语']) * n
return df
df1 = df1.apply(plus,axis=1,args=(2,3,))
其中 axis=1 代表按照列为轴进行操作,axis=0 代表按照行为轴进行操作,args 是传递的两个参数,即 n=2, m=3,在 plus 函数中使用到了 n 和 m,从而生成新的 df。
自定义函数apply
def search_hundredth(train_content):
hundredth=train_content.loc[99]
return hundredth
search_func=train_content.apply(search_hundredth)
print(search_func)
数据统计
在数据清洗后,我们就要对数据进行统计了。Pandas 和 NumPy 一样,都有常用的统计函数,如果遇到空值 NaN,会自动排除。
常用的统计函数包括:
count() 统计个数,空值NaN不计算
describe() 一次性输出多个统计指标,包括:count,mean,std,min,max 等
min() 最小值
max() 最大值
sum() 总和
mean() 平均值
median() 中位数
var() 方差
std() 标准差
argmin() 统计最小值的索引位置
argmax() 统计最大值的索引位置
idxmin() 统计最小值的索引值
idxmax() 统计最大值的索引值
表格中有一个 describe() 函数,统计函数千千万,describe() 函数最简便。它是个统计大礼包,可以快速让我们对数据有个全面的了解。下面我直接使用 df1.descirbe() 输出结果为:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
print df1.describe()
运行结果:
Image text
数据表合并
有时候我们需要将多个渠道源的多个数据表进行合并,一个 DataFrame 相当于一个数据库的数据表,那么多个 DataFrame 数据表的合并就相当于多个数据库的表合并。
比如我要创建两个 DataFrame:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = DataFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
1. 基于指定列进行连接
比如我们可以基于 name 这列进行连接。
`df3 = pd.merge(df1, df2, on='name')`
运行结果:

2. inner 内连接
inner 内链接是 merge 合并的默认情况,inner 内连接其实也就是键的交集,在这里 df1, df2 相同的键是 name,所以是基于 name 字段做的连接:
`df3 = pd.merge(df1, df2, how='inner')`
运行结果:
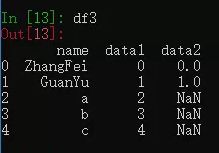
3. left 左连接
左连接是以第一个 DataFrame 为主进行的连接,第二个 DataFrame 作为补充。
`df3 = pd.merge(df1, df2, how='left')`
运行结果:
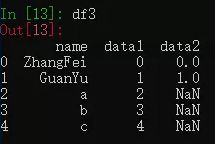
4. right 右连接
右连接是以第二个 DataFrame 为主进行的连接,第一个 DataFrame 作为补充。
`df3 = pd.merge(df1, df2, how='right')`
运行结果:
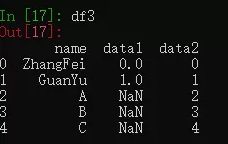
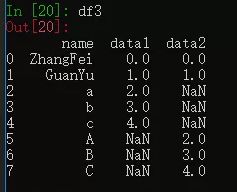
5. outer 外连接
外连接相当于求两个 DataFrame 的并集。
df3 = pd.merge(df1, df2, how='outer')
运行结果:
如何用 SQL 方式打开 Pandas
Pandas 的 DataFrame 数据类型可以让我们像处理数据表一样进行操作,比如数据表的增删改查,都可以用 Pandas 工具来完成。
不过也会有很多人记不住这些 Pandas 的命令,相比之下还是用 SQL 语句更熟练,用 SQL 对数据表进行操作是最方便的,它的语句描述形式更接近我们的自然语言。
事实上,在 Python 里可以直接使用 SQL 语句来操作 Pandas。
这里给你介绍个工具:pandasql
pandasql 中的主要函数是 sqldf,它接收两个参数:一个 SQL 查询语句,还有一组环境变量 globals() 或 locals()。这样我们就可以在 Python 里,直接用 SQL 语句中对 DataFrame 进行操作,举个例子:import pandas as pd
例子:
from pandas import DataFrame
from pandasql import sqldf, load_meat, load_births
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
pysqldf = lambda sql: sqldf(sql, globals())
sql = "select * from df1 where name ='ZhangFei'"
print pysqldf(sql)
运行结果:
data1 name
0 0 ZhangFei
上面这个例子中,我们是对“name='ZhangFei”“的行进行了输出。当然你会看到我们用到了 lambda,lambda 在 python 中算是使用频率很高的,那 lambda 是用来做什么的呢?
它实际上是用来定义一个匿名函数的,具体的使用形式为:
lambda argument_list: expression
这里 argument_list 是参数列表,expression 是关于参数的表达式,会根据 expression 表达式计算结果进行输出返回。
在上面的代码中,我们定义了:
pysqldf = lambda sql: sqldf(sql, globals())
在这个例子里,输入的参数是 sql,返回的结果是 sqldf 对 sql 的运行结果,当然 sqldf 中也输入了 globals 全局参数,因为在 sql 中有对全局参数 df1 的使用。
读取文件里的内容
以csv的格式读取文件里的内容
train_content=pd.read_csv("train.csv")
显示pd_content的前面三行(不包括列名字)
print(train_content.head(3)
pivot_table函数
pivot_table有四个最重要的参数index、values、columns、aggfunc
index index代表索引,每个pivot_table必须拥有一个index。
Values Values可以对需要的计算数据进行筛选
Aggfunc aggfunc参数可以设置我们对数据聚合时进行的函数操作。当我们未设置aggfunc时,它默认aggfunc='mean'计算均值,可以设置多个 如: [aggfunc=[np.sum,np.mean]] 此时会显示np.sum和np.mean统计出来的数据。
Columns Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
#以 Pclass(船舱)为索引 查看不同船舱人员的平均存活率Survived。
train_survived=train_content.pivot_table(index="Pclass",values="Survived")
# 查看不同船舱的收费均值是多少
train_age_fare=train_content.pivot_table(index="Pclass",values=["Age","Fare"])
# 查看不同船舱人员的的人均年龄
train_survived=train_content.pivot_table(index="Pclass",values="Age")
icol和col 取范围
iloc和loc的区别是 iloc只能跟整数,而loc可以跟数字
print(train_content.iloc[83,3]) #找的是除title以外的第84行,因为数组默认是从0开始向上增长的
print(train_content.iloc[82:83,3:5]) #去尾的83不包括 5不包括
print(train_content.iloc[82:84,3:6]) #去尾的83不包括 5不包括
print(train_content.loc[83,"Age"])
print(train_content.loc[82:83,"Name":"Age"]) #还可以跟范围
将Pandas中的DataFrame类型转换成Numpy中array类型的三种方法
dataframe 转列表
1、使用DataFrame中的values方法
df.values
2、使用DataFrame中的as_matrix()方法
df.as_matrix()
3、使用Numpy中的array方法
np.array(df)
pandas.DataFrame.fillna 用指定的方法填充NA/NaN
DataFrame.fillna(value = None,method = None,axis = None,inplace = False,limit = None,downcast = None,** kwargs )
value:标量,字典,系列或DataFrame用于填充孔的值(例如0),或者用于指定每个索引(对于Series)或列(对于DataFrame)使用哪个值的Dict /Series / DataFrame。(不会填写dict / Series / DataFrame中的值)。该值不能是列表。method: {'backfill','bfill','pad','ffill',None},默认无 用于填充重新索引的填充孔的方法系列填充/填充axis: {0或'索引',1或'列'}
例子:
>>> df = pd.DataFrame([[np.nan, 2, np.nan, 0],
... [3, 4, np.nan, 1],
... [np.nan, np.nan, np.nan, 5],
... [np.nan, 3, np.nan, 4]],
... columns=list('ABCD'))
>>> df
A B C D
0 NaN 2.0 NaN 0
1 3.0 4.0 NaN 1
2 NaN NaN NaN 5
3 NaN 3.0 NaN 4
用0替换所有NaN元素
>>> df.fillna(0)
A B C D
0 0.0 2.0 0.0 0
1 3.0 4.0 0.0 1
2 0.0 0.0 0.0 5
3 0.0 3.0 0.0 4
我们还可以向前或向后传播非空值。
>>> df.fillna(method='ffill')
A B C D
0 NaN 2.0 NaN 0
1 3.0 4.0 NaN 152 3.0 4.0 NaN 5
3 3.0 3.0 NaN 4
将“A”,“B”,“C”和“D”列中的所有NaN元素分别替换为0,1,2和3。
>>> values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
>>> df.fillna(value=values)
A B C D
0 0.0 2.0 2.0 0
1 3.0 4.0 2.0 1
2 0.0 1.0 2.0 5
3 0.0 3.0 2.0 4
只替换第一个NaN元素。
>>> df.fillna(value=values, limit=1)
A B C D
0 0.0 2.0 2.0 0
1 3.0 4.0 NaN 1
2 NaN 1.0 NaN 5
3 NaN 3.0 NaN 4
pandas.DataFrame.groupby
groupby操作涉及拆分对象,应用函数和组合结果的某种组合。这可用于对这些组上的大量数据和计算操作进行分组。
例子:指定以什么为组执行操作
>>> df = pd.DataFrame({'Animal' : ['Falcon', 'Falcon',
'Parrot', 'Parrot'],
. 'Max Speed' : [380., 370., 24., 26.]})
>>> df
Animal Max Speed
0 Falcon 380.0
1 Falcon 370.0
2 Parrot 24.0
3 Parrot 26.0
>>> df.groupby(['Animal']).mean()
Max Speed
Animal
Falcon 375.0
Parrot 25.0
例子2:可以指定显示的内容
print(train_data.groupby(['Pclass'])['Pclass','Survived'].mean())
Pclass Survived
Pclass
1 1.0 0.629630
2 2.0 0.472826
3 3.0 0.242363
print(train_data.groupby(['Pclass'])['Pclass','Survived','Age'].mean())
Pclass Survived Age
Pclass
1.0 0.629630 37.048118
2.0 0.472826 29.866958
3.0 0.242363 26.40325
分层索引
我们可以使用level参数对不同级别的层次索引进行分组:
>>> arrays = [['Falcon', 'Falcon', 'Parrot', 'Parrot'],
... ['Capitve', 'Wild', 'Capitve', 'Wild']]
>>> index = pd.MultiIndex.from_arrays(arrays, names=('Animal', 'Type'))
>>> df = pd.DataFrame({'Max Speed' : [390., 350., 30., 20.]},
... index=index)
>>> df
Max Speed
Animal Type1Falcon Capitve 390.0
Wild 350.0
Parrot Capitve 30.0
Wild 20.0
>> df.groupby(level=0).mean()
Max Speed
Animal
Falcon 370.0
Parrot 25.0
>>> df.groupby(level=1).mean()
Max Speed
Type
Capitve 210.0
Wild 185.0
pandas按若干个列的组合条件筛选数据
取年龄等于26,并且存活的数据的数量
print(train_data[(train_data['Age']==29) & (train_data['Survived']==1)].count())
pandas.Series.map
根据输入的对应关系映射系列的值。
用于将系列中的每个值替换为另一个值,该值可以从函数,a dict或a 派生Series。
例子:
>>> s = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
>>> s
0 cat
1 dog
2 NaN
3 rabbit
dtype: object
map接受a dict或a Series。除非dict具有默认值(例如),否则将dict转换为未找到的NaN值defaultdict:
>>> s.map({'cat': 'kitten', 'dog': 'puppy'})
0 kitten
1 puppy
2 NaN
3 NaN
dtype: object
它还接受一个功能:
>>> s.map('I am a {}'.format)
0 I am a cat
1 I am a dog
2 I am a nan
3 I am a rabbit
dtype: object
为避免将函数应用于缺失值(并将其保留为 NaN),na_action='ignore'可以使用:
>>> s.map('I am a {}'.format, na_action='ignore')
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
dtype: object
pandas.set_option
可以设置pandas的属性,比如打印出来数据时显示多少列,显示多宽等等,可以一次性设置多个格式如下
例子:
print(pd.set_option('display.max_columns',None,'display.width',10))
python dataframe 获得 列名columns 和行名称 index
dfname._stat_axis.values.tolist() == dfname.index.values.tolist() # 行名称
dfname.columns.values.tolist() # 列名称
总结:
和 NumPy 一样,Pandas 有两个非常重要的数据结构:Series 和 DataFrame。使用 Pandas 可以直接从 csv 或 xlsx 等文件中导入数据,以及最终输出到 excel 表中。
Pandas 包与 NumPy 工具库配合使用可以发挥巨大的威力,正是有了 Pandas 工具,Python 做数据挖掘才具有优势。