创建项目在开始爬取之前,您必须创建一个新的Scrapy项目。
进入您打算存储代码的目录中,运行下列命令:
scrapy startproject tutorial
该命令将会创建包含下列内容的 tutorial 目录:

这些文件分别是:scrapy.cfg:
项目的配置文件tutorial/: 该项目的python模块。
之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
编写第一个爬虫(Spider)
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
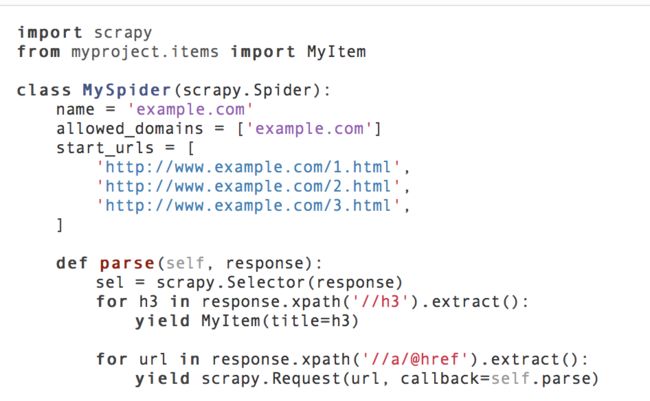
以下为我们的第一个Spider代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:

爬取
进入项目的根目录,执行下列命令启动spider:
scrapy crawl dmoz
提取Item
Selectors选择器简介
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors。 关于selector和其他提取机制的信息请参考 Selector文档 。
Selector有四个基本的方法(点击相应的方法可以看到详细的API文档):
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.
extract(): 序列化该节点为unicode字符串并返回list。
re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
这里给出XPath表达式的例子及对应的含义:
/html/head/title: 选择HTML文档中 标签内的 元素
/html/head/title/text(): 选择上面提到的 元素的文字
//td: 选择所有的 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
Spider
class scrapy.spider.Spider
Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。 Spider并没有提供什么特殊的功能。 其仅仅请求给定的 start_urls/start_requests ,并根据返回的结果(resulting responses)调用spider的 parse方法。
name
定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。 不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的。
如果该spider爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite 。
allowed_domains
可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
start_urls
URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
start_requests()
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。
当spider启动爬取并且未制定URL时,该方法被调用。 当指定了URL时,make_requests_from_url() 将被调用来创建Request对象。 该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。
该方法的默认实现是使用 start_urls 的url生成Request。
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。 例如,如果您需要在启动时以POST登录某个网站,你可以这么写:
defstart_requests(self):return[scrapy.FormRequest("http://www.example.com/login",formdata={'user':'john','pass':'secret'},callback=self.logged_in)]deflogged_in(self,response):# here you would extract links to follow and return Requests for# each of them, with another callbackpass
make_requests_from_url(url)
该方法接受一个URL并返回用于爬取的 Request 对象。 该方法在初始化request时被 start_requests() 调用,也被用于转化url为request。
默认未被复写(overridden)的情况下,该方法返回的Request对象中, parse() 作为回调函数,dont_filter参数也被设置为开启。 (详情参见 Request).
parse(response)
当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse 负责处理response并返回处理的数据以及(/或)跟进的URL。 Spider 对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
参数:response (Response) – 用于分析的response
log(message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。 log中自动带上该spider的 name 属性。 更多数据请参见 Logging 。
closed(reason)
当spider关闭时,该函数被调用。 该方法提供了一个替代调用signals.connect()来监听 spider_closed 信号的快捷方式。

另一个在单个回调函数中返回多个Request以及Item的例子: