【小白学爬虫连载(11)】--pyquery库详解
前面的分享如何获取免费高匿代理IP代码中我们用到了pyquery这个解析库,这个库在之前的分享中还不曾讲到,前面我们主要用的是beautiful soup解析库,如果你比较喜欢用CSS选择器,如果你对jQuery有所了解,可以选择使用pyquery,它的语法相对更为简单。下面我们看看该如何使用它吧!
本次分享将从以下四个方面介绍pyquery库:
如何安装pyquery
如何初始化
如何查找节点、获取信息
如何安装pyquery
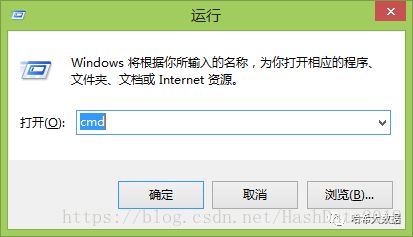
Windows系统 利用win + R快捷键打开运行窗口,输入cmd点击确定,打开命令行,然后直接输入:pip install pyquery,等待完成安装后在命令行中输入python,然后输入import pyquery检查是否安装成功,如下图输入import pyquery后没有出现问题就说明安装成功。


如何初始化
pyquery提供了多种初始化方法例如:直接传入字符串,传入URL,传入文件名,传入lxml等。对于爬虫来说我们很少的时候使用传入URL的方式,更多的是使用传入由requests或其他HTTP库请求URL得到的response。例如:
from pyquery import PyQuery as pq
# 出入URL
doc = pq(url='https://www.baidu.com/')
# 传入字符串的形式
import requests
r = requests.get('https://www.baidu.com/')
html = r.text
doc = pq(html)
因为请求url涉及到user-agent,cookies,检查是否成功返回等各种问题,所以还是交给专业的HTTP库去做比较好。
如何查找节点、获取信息
1.基本CSS选择器
我们可以利用class、id、标签名称或者是一个序列的方式定位到某个标签。
例如:
from pyquery import PyQuery as pq
# 传入字符串的形式
html_doc = """
<html><head><title>The Dormouse's storytitle>head>
<p class="title"><b>The Dormouse's storyb>p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsiea>,
<a href="http://example.com/lacie" class="sister" id="link2">Laciea> and
<a href="http://example.com/tillie" class="sister" id="link3">Tilliea>;
and they lived at the bottom of a well.p>
<p class="story">...p>
"""
doc = pq(html_doc)
title = doc('.title')#选择class为title的所有标签,及其子孙标签
print(title)
link1 = doc('html .story #link1')#选择所有html标签下的所有class为story的标签下的所有id为link1的标签。
print(link1)
查找子节点
查找子节点需要用到find()方法,传入的参数是CSS选择器,我们还是以上面的HTML为例。
doc = pq(html_doc)
title = doc('.title')#选择class为title的所有标签,及其子孙标签
print(title)
title_b = title.find('b')#找到b子标签
遍历
PyQuery的选择结果可能是多个节点,可能是单个节点,类型都是PyQuery类型,并没有返回像BeautifulSoup一样的列表。对于多个节点的结果,我们需要调用items()方法获取一个列表。
doc = pq(html_doc)
names = doc('.story a').items()
for name in names:
print(name)
获取属性、文本、HTML等信息
提取到某个PyQuery类型的节点之后,我们可以调用attr()方法来获取属性。
doc = pq(html_doc)
name = doc('.story #link1')
print(name.attr('href'))
我们可以调用text()方法来获取标签内的所有文本,例如:
doc = pq(html_doc)
text = doc('.story')
print(text.text())
这里我们将p标签的子标签a中的文本也获取出来了,有时候需要这样,但有时候我们只想获取其自身的text,不想得到其子标签的text这时候我们需要remove函数的帮助。
doc = pq(html_doc)
text = doc('.story')
text.find('a').remove()
print(text.text())
这时候就将a标签剔除掉了,只留下p标签的内容。
pyquery利用class、id、标签名称返回符合条件的所有元素,但有时候我们只需要第一个或最后一个或其中几个。这时候我们利用伪类选择器就十分方便了。
2.伪类选择器
| p:first-child | 选择属于父元素的第一个子元素的每个 元素。 |
| p:last-child | 选择属于其父元素最后一个子元素每个 元素。 |
| a[src^="htpps"] | 选择其 src 属性值以 "https" 开头的每个 元素。 |
| a[src*="htpps"] | 选择其 src 属性中包含 "abc" 子串的每个 元素。 |
更多伪选择器的用法可以参考:http://www.w3school.com.cn/cssref/css_selectors.asp
小结
本次分享主要介绍了pyquery的安装、初始化以及查找节点获取信息的方法,pyquery相对于beautiful soup库语法更为简单,而且对于熟悉jQuery的朋友来说是零门槛。但pyquery有时候会出现解析不出内容的情况,这也是之前没给大家介绍的原因,不过这种情况毕竟很少,为了快速搞定爬取任务,很多时候pyquery是不错的选择。