transformer在图像分类上的应用以及pytorch代码实现
文章目录
- 1.对transformers的简单介绍
-
- 1.1序列数据的介绍(seq2seq)
- 1.2self-Attention
- 1.3 transformer的完整结构
- 2.transformers在图像分类上的pytorch代码
-
- 2.1加载cifar10数据集
- 2.2构建transformers模型
-
- 2.2.1构建图像编码模块 Embeddings
- 2.2.3构建前向传播神经网络模块
- 2.2.4构建编码器的可重复利用Block模块
- 2.2.5构建Encoder模块
- 2.2.6 构建完整的transformers
- 2.2.7构建VisionTransformers,用于图像分类
- 3.参考文献
本文简单介绍transformers的原理,主要介绍transformers如何应用在图像分类上的任务。
完整代码连接:
https://download.csdn.net/download/qq_37937847/16592999
1.对transformers的简单介绍
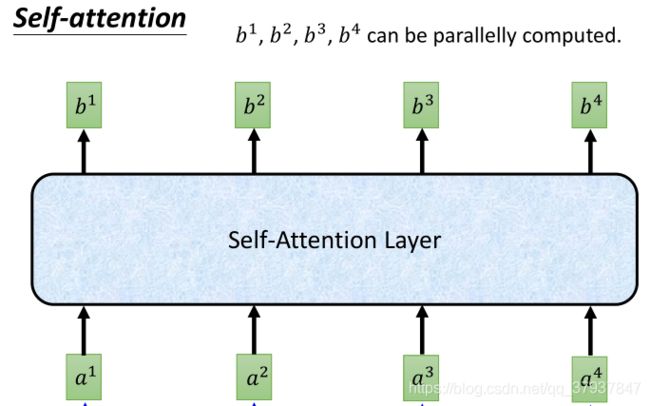
transformers在自然语言处理领域有着天然的优势,transformers改进了RNN(循环神经网络)训练慢,不能够建立序列之间的长期依赖,记忆消失的缺点。transformers的核心在是self-attention,输入一组序列,它能够平行的计算并平行的输出另一组经过编码的序列。
1.1序列数据的介绍(seq2seq)
比如说在机器翻译领域:
输入的数据是一整串(单词)的句子,那么首先就需要对单词进行编码,将每个单词用一个固定维度的向量(比如512维度)来表示,网络的输入的是一个句子,那么就是一个向量列表,而列表的长度应该是训练集中最长的句子的长度。
在图像分类的领域:类比机器翻译领域,一张图片就是一个句子,然后将图片进行切块(可以用卷积来完成),切成n_patch快,那么每一个图像块就是一个单词。
比如(bs,3,224,224)经过卷积–>(bs,768,14,14)—>(bs,768,196)
1.2self-Attention
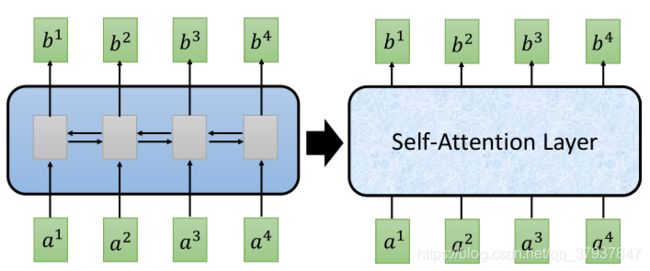
左边的网络结构,是最开始的RNN循环神经网络,b的输出不是平行的,需要等待前面的b生成结束才能继续后面的生成。
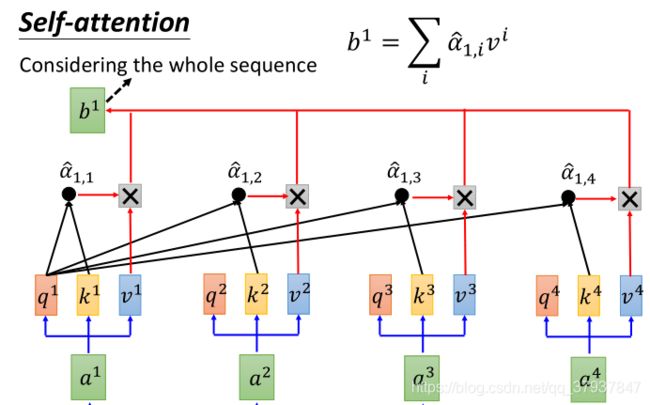
右边的是transformers中的Self-Attention结构,输入一组序列a1,a2,…,可以平行的输出另一组序列b1,b2,b3,…。
那么在self-attention具体做了哪些操作呢?
上图的a1,a2,…都是一个固定维度的向量,表示一个词向量。
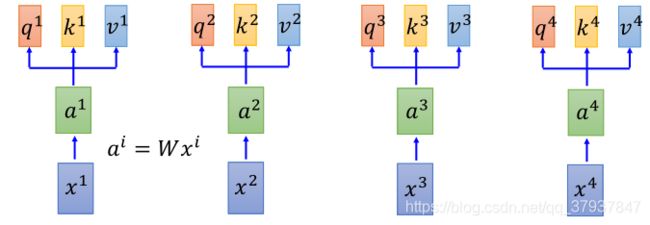
首先将a通过3个不同的矩阵(Q,K,V)映射成三个不同的向量q(查询向量),k(匹配向量),v(该单词的信息向量),
然后拿每一个q与其他的k进行点乘(做attention):
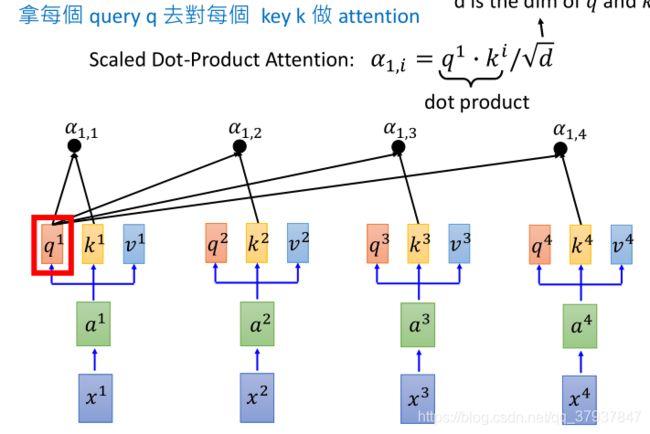
点乘的结果:
a1.1,a1.2,a1.3,…,都是标量,代表着当前a1这个单词与其他单词之间的某种attenttion关系(相关程度的打分值),然后再将q2与每一个k做点乘,得到a2.1,a2.2,a2.3,…,代表着a2这个单词与其他单词的关系。这样对一句话中所有的单词进行同样的操作,那么就可以建立所有单词之间的某种attention关系。
实际举例:如果一句话的长度为32个单词构成,那么进行上述的操作结果后,应该得到一个(32,32)的矩阵,每一行代表着,其他32个单词对当前行(单词)的贡献程度或者某种的attention关系。
然后在对点乘的结果做softmax()函数操作,将打分情况转换为0-1之间的概率。实际上就是表示,一句话中,其他单词对当前这个单词的贡献程度。
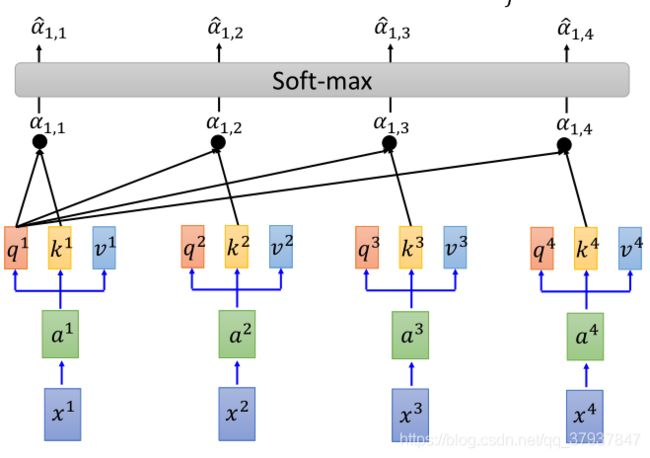
经过上述的操作,可获得:

这里A’为(32,32),每一列的值的和为1,每一个值代表第几个单词对当前列的单词的贡献程度
假设单词的信息向量为64维度(这个维度可以自己调整,不需要和前面的Q,K的维度一致),一句话的单词长度为32,那么句子的信息矩阵Value为(32,64)
接下来将每个信息向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
最后是对加权值向量求和(译注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(单词的信息向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到。),然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。
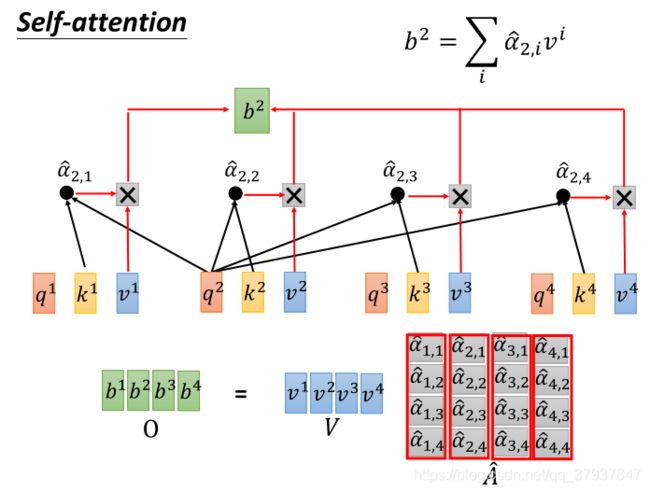
#这里的v为向量,具体操作时代码,可以写成下列形式
query_layer#(bs,32,64)
key_layer#(bs,32,64)
value_layer#(bs,32,64)
#1.首先q和k进行匹配相乘,得到每个单词之前的关系
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))# 将q向量和k向量进行相乘(bs,32,32)
#2.将得分情况进行softmax()操作
attention_scores = attention_scores / math.sqrt(attention_head_size) #将结果除以向量维数的开方
attention_probs = softmax(attention_scores) # 将得到的分数进行softmax,得到概率
#3.将概率与value详细进行相乘
context_layer = torch.matmul(attention_probs, value_layer) #(bs,32,64)
1.3 transformer的完整结构
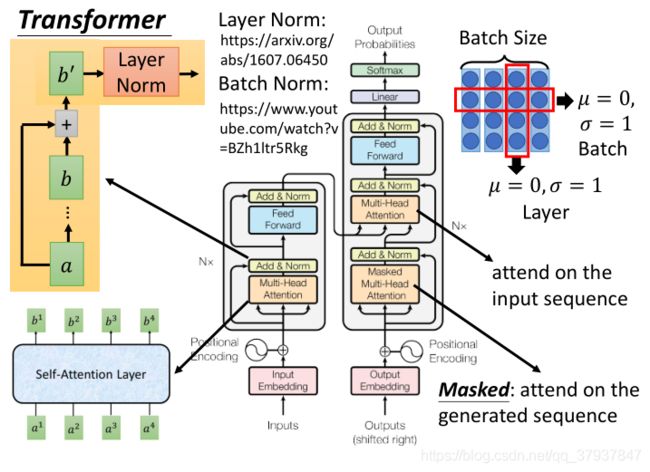
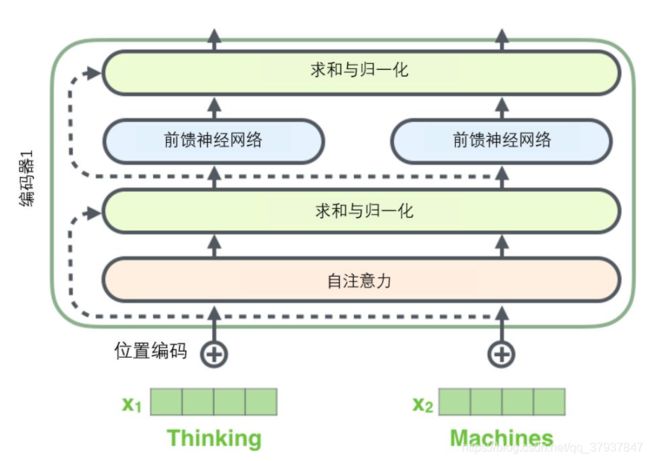
2.transformers在图像分类上的pytorch代码
2.1加载cifar10数据集
#1.加载cifar10数据集,返回的是train_loader,test_loader
def get_loader(args):
#设置数据加载时的变换形式,包括撞转成tensor,裁剪,归一化
transform_train=transforms.Compose([
transforms.RandomResizedCrop((args.img_size,args.img_size),scale=(0.05,1.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
])
transform_test = transforms.Compose([
transforms.Resize((args.img_size, args.img_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
#默认使用cifar10数据集
if args.dataset=="cifar10":
trainset=datasets.CIFAR10(root=r'../data',
train=True,
download=False,
transform=transform_train)
testset=datasets.CIFAR10(root=r'../data',
train=False,
download=False,
transform=transform_train)
else:
trainset = datasets.CIFAR100(root='./data',
train=True,
download=True,
transform=transform_train)
testset = datasets.CIFAR100(root='./data',
train=False, download=True,
transform=transform_train)
print("train number:",len(trainset))
print("test number:",len(testset))
train_loader=DataLoader(trainset,batch_size=args.train_batch_size,shuffle=True)
test_loader=DataLoader(testset,batch_size=args.eval_batch_size,shuffle=False)
print("train_loader:",len(train_loader))
print("test_loader:",len(test_loader))
return train_loader,test_loader
进行测试:
#定义一个实例配置文件
parser = argparse.ArgumentParser()
parser.add_argument("--dataset", choices=["cifar10", "cifar100"], default="cifar10")
parser.add_argument("--img_size", type=int, default=224,)
parser.add_argument("--train_batch-size", default=16, type=int,)
parser.add_argument("--eval_batch-size", default=16, type=int,)
args = parser.parse_args()
get_loader(args)
结果为:

2.2构建transformers模型
2.2.1构建图像编码模块 Embeddings
class Embeddings(nn.Module):
'''
对图像进行编码,把图片当做一个句子,把图片分割成块,每一块表示一个单词
'''
def __init__(self,config,img_size,in_channels=3):
super(Embeddings,self).__init__()
img_size=img_size#224
patch_size=config.patches["size"]#16
##将图片分割成多少块(224/16)*(224/16)=196
n_patches=(img_size//patch_size)*(img_size//patch_size)
#对图片进行卷积获取图片的块,并且将每一块映射成config.hidden_size维(768)
self.patch_embeddings=Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=patch_size,
stride=patch_size)
#设置可学习的位置编码信息,(1,196+1,786)
self.position_embeddings=nn.Parameter(torch.zeros(1,
n_patches+1,
config.hidden_size))
#设置可学习的分类信息的维度
self.classifer_token=nn.Parameter(torch.zeros(1,1,config.hidden_size))
self.dropout=Dropout((config.transformer["dropout_rate"]))
def forward(self,x):
bs=x.shape[0]
cls_tokens=self.classifer_token.expand(bs,-1,-1)(bs,1,768)
x=self.patch_embeddings(x)#(bs,768,14,14)
x=x.flatten(2)#(bs,768,196)
x=x.transpose(-1,-2)#(bs,196,768)
x=torch.cat((cls_tokens,x),dim=1)#将分类信息与图片块进行拼接(bs,197,768)
embeddings=x+self.position_embeddings#将图片块信息和对其位置信息进行相加(bs,197,768)
embeddings=self.dropout(embeddings)
return embeddings
进行测试:
def get_config():
"""Returns the ViT-B/16 configuration."""
config = ml_collections.ConfigDict()
config.patches = ml_collections.ConfigDict({
'size':16})
config.hidden_size = 768
config.transformer = ml_collections.ConfigDict()
config.transformer.mlp_dim = 3072
config.transformer.num_heads = 12
config.transformer.num_layers = 12
config.transformer.attention_dropout_rate = 0.0
config.transformer.dropout_rate = 0.1
config.classifier = 'token'
config.representation_size = None
return config
config=get_config()
embedding=Embeddings(config,img_size=224)
#模拟图片信息
img=torch.rand(2,3,224,224)
out_embedding=embedding(img)
print("img_embedding shape:\n",out_embedding.shape)

注:这个模块实际就已经完成将图片分割成块,每一块类比nlp领域就是一个词向量,在本代码中,这个词向量的维度
是config.hidden_size=768.而图片相当于一个句子,句子的长度就是图片分割成块的数目,这里是14x14=196块,这里每一个块的位置编码信息,采用可学习的编码方式加到了每个块的向量上。由于本文是将transformers应用在图像分类上的,所有这里添加了一个cls_token(bs,1,768)这样一个维度,主要是用了完成后期分类任务所添加的
###2.2构建self-Attention模块
#2.构建self-Attention模块
class Attention(nn.Module):
def __init__(self,config,vis):
super(Attention,self).__init__()
self.vis=vis
self.num_attention_heads=config.transformer["num_heads"]#12
self.attention_head_size = int(config.hidden_size / self.num_attention_heads) # 768/12=64
self.all_head_size = self.num_attention_heads * self.attention_head_size # 12*64=768
self.query = Linear(config.hidden_size, self.all_head_size)#wm,768->768,Wq矩阵为(768,768)
self.key = Linear(config.hidden_size, self.all_head_size)#wm,768->768,Wk矩阵为(768,768)
self.value = Linear(config.hidden_size, self.all_head_size)#wm,768->768,Wv矩阵为(768,768)
self.out = Linear(config.hidden_size, config.hidden_size) # wm,768->768
self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.softmax = Softmax(dim=-1)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (
self.num_attention_heads, self.attention_head_size) # wm,(bs,197)+(12,64)=(bs,197,12,64)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3) # wm,(bs,12,197,64)
def forward(self, hidden_states):
# hidden_states为:(bs,197,768)
mixed_query_layer = self.query(hidden_states)#wm,768->768
mixed_key_layer = self.key(hidden_states)#wm,768->768
mixed_value_layer = self.value(hidden_states)#wm,768->768
query_layer = self.transpose_for_scores(mixed_query_layer)#wm,(bs,12,197,64)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))#将q向量和k向量进行相乘(bs,12,197,197)
attention_scores = attention_scores / math.sqrt(self.attention_head_size)#将结果除以向量维数的开方
attention_probs = self.softmax(attention_scores)#将得到的分数进行softmax,得到概率
weights = attention_probs if self.vis else None#wm,实际上就是权重
attention_probs = self.attn_dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)#将概率与内容向量相乘
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)#wm,(bs,197)+(768,)=(bs,197,768)
context_layer = context_layer.view(*new_context_layer_shape)
attention_output = self.out(context_layer)
attention_output = self.proj_dropout(attention_output)
return attention_output, weights#wm,(bs,197,768),(bs,197,197)
进行测试self-attention
attention=Attention(config,vis=True)
out_selfattention,_=attention(out_embedding)
print("out_selfattention shape:",out_selfattention.shape)
结果:
![]()
2.2.3构建前向传播神经网络模块
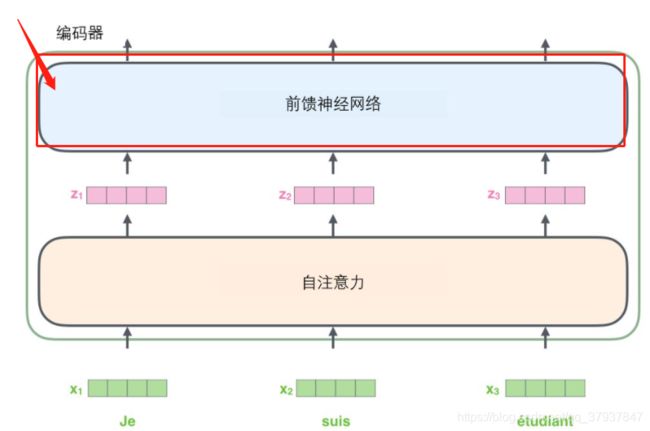
#3.构建前向传播神经网络
#两个全连接神经网络,中间加了激活函数
class Mlp(nn.Module):
def __init__(self, config):
super(Mlp, self).__init__()
self.fc1 = Linear(config.hidden_size, config.transformer["mlp_dim"])#wm,786->3072
self.fc2 = Linear(config.transformer["mlp_dim"], config.hidden_size)#wm,3072->786
self.act_fn = torch.nn.functional.gelu#wm,激活函数
self.dropout = Dropout(config.transformer["dropout_rate"])
self._init_weights()
def _init_weights(self):
nn.init.xavier_uniform_(self.fc1.weight)
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.normal_(self.fc1.bias, std=1e-6)
nn.init.normal_(self.fc2.bias, std=1e-6)
def forward(self, x):
x = self.fc1(x)#wm,786->3072
x = self.act_fn(x)#激活函数
x = self.dropout(x)#wm,丢弃
x = self.fc2(x)#wm3072->786
x = self.dropout(x)
return x
测试mlp模块:
##################测试3.MLP模块###########################################################
mlp=Mlp(config)
out_mlp=mlp(out_selfattention)
print("out_mlp shape:",out_mlp.shape)
结果:
![]()
2.2.4构建编码器的可重复利用Block模块
该模块是可以重复利用的,原始论文中,堆叠了6个该模块,构成一个transformers的编码器
该模块包含了self-attention模块和mlp模块,还有残差结构,层归一化
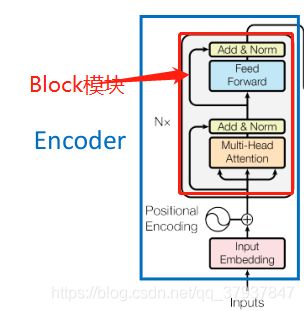
#4.构建编码器的可重复利用的Block()模块:每一个block包含了self-attention模块和MLP模块
class Block(nn.Module):
def __init__(self, config, vis):
super(Block, self).__init__()
self.hidden_size = config.hidden_size#wm,768
self.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)#wm,层归一化
self.ffn_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn = Mlp(config)
self.attn = Attention(config, vis)
def forward(self, x):
h = x
x = self.attention_norm(x)
x, weights = self.attn(x)
x = x + h#残差结构
h = x
x = self.ffn_norm(x)
x = self.ffn(x)
x = x + hh#残差结构
return x, weights
测试Block模块:
#############################4.测试Block模块###########################
block=Block(config,vis=True)
out_block,_=block(out_embedding)
print("out_block shape:",out_block.shape)
结果:

2.2.5构建Encoder模块
该模块实际上就是堆叠N个Block模块,结构图如上图所示:
#5.构建Encoder模块,该模块实际上就是堆叠N个Block模块
class Encoder(nn.Module):
def __init__(self, config, vis):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)
for _ in range(config.transformer["num_layers"]):
layer = Block(config, vis)
self.layer.append(copy.deepcopy(layer))
def forward(self, hidden_states):
attn_weights = []
for layer_block in self.layer:
hidden_states, weights = layer_block(hidden_states)
if self.vis:
attn_weights.append(weights)
encoded = self.encoder_norm(hidden_states)
return encoded, attn_weights
测试Encoder模块:
##################5.测试Encoder模块############################
encoder=Encoder(config,vis=True)
out_encoder,_=encoder(out_embedding)
print("5:out_encoder shape:",out_encoder.shape)
结果:

2.2.6 构建完整的transformers
#6构建transformers完整结构,首先图片被embedding模块编码成序列数据,然后送入Encoder中进行编码
class Transformer(nn.Module):
def __init__(self, config, img_size, vis):
super(Transformer, self).__init__()
self.embeddings = Embeddings(config, img_size=img_size)#wm,对一幅图片进行切块编码,得到的是(bs,n_patch+1(196),每一块的维度(768))
self.encoder = Encoder(config, vis)
def forward(self, input_ids):
embedding_output = self.embeddings(input_ids)#wm,输出的是(bs,196,768)
encoded, attn_weights = self.encoder(embedding_output)#wm,输入的是(bs,196,768)
return encoded, attn_weights#输出的是(bs,197,768)
测试transformers
###################6.测试transformers的完整结构#########################
#transformers的输入数据是图像数据,输出的数据(bs,197,768)中197的第一个的向量(768)可以用于图像分类
transformers=Transformer(config,img_size=224,vis=True)
out_transformers,_=transformers(img)
print("6:out_transformers shape:",out_transformers.shape)

2.2.7构建VisionTransformers,用于图像分类
#7构建VisionTransformer,用于图像分类
class VisionTransformer(nn.Module):
def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.zero_head = zero_head
self.classifier = config.classifier
self.transformer = Transformer(config, img_size, vis)
self.head = Linear(config.hidden_size, num_classes)#wm,768-->10
def forward(self, x, labels=None):
x, attn_weights = self.transformer(x)
logits = self.head(x[:, 0])
#如果传入真实标签,就直接计算损失值
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_classes), labels.view(-1))
return loss
else:
return logits, attn_weights
测试VisionTransformer模块:
#################7.验证visionTransformers###########################
visiontransformer=VisionTransformer(config,num_classes=10,vis=True)
out_visiontransformer,_=visiontransformer(img)
print("7.out_visiontransformers shape:",out_visiontransformer.shape)
结果:

##2.3.利用VisionTransformer模块,训练图像分类模型
新建一个train.py文件
import ml_collections
import argparse
from wm.modeling import VisionTransformer
from wm.load_cifa10 import get_loader
import torch
import os
import numpy as np
def get_config():
'''
配置transformer的模型的参数
'''
config = ml_collections.ConfigDict()
config.patches = ml_collections.ConfigDict({
'size':16})
config.hidden_size = 768
config.transformer = ml_collections.ConfigDict()
config.transformer.mlp_dim = 3072
config.transformer.num_heads = 12
config.transformer.num_layers = 12
config.transformer.attention_dropout_rate = 0.0
config.transformer.dropout_rate = 0.1
config.classifier = 'token'
config.representation_size = None
return config
def save_model(args, model,epoch_index):
'''
保存每个epoch训练的模型
'''
model_to_save = model.module if hasattr(model, 'module') else model
model_checkpoint = os.path.join(args.output_dir, "epoch%s_checkpoint.bin" % epoch_index)
torch.save(model_to_save.state_dict(), model_checkpoint)
#实例化模型
def getVisionTransformers_model(args):
config=get_config()#获取模型的配置文件
num_classes = 10 if args.dataset == "cifar10" else 100
model = VisionTransformer(config, args.img_size, zero_head=True, num_classes=num_classes)
model.to(args.device)
return args,model
#用测试集评估模型的训练好坏
def eval(args,model,test_loader):
eval_loss=0.0
total_acc=0.0
model.eval()
loss_function = torch.nn.CrossEntropyLoss()
for i,batch in enumerate(test_loader):
batch = tuple(t.to(args.device) for t in batch)
x, y = batch
with torch.no_grad():
logits,_= model(x)#model返回的是(bs,num_classes)和weight
batch_loss=loss_function(logits,y)
#记录误差
eval_loss+=batch_loss.item()
#记录准确率
_,preds= logits.max(1)
num_correct=(preds==y).sum().item()
total_acc+=num_correct
loss=eval_loss/len(test_loader)
acc=total_acc/(len(test_loader)*args.eval_batch_size)
return loss,acc
def train(args,model):
print("load dataset.........................")
#加载数据
train_loader, test_loader = get_loader(args)
# Prepare optimizer and scheduler
optimizer = torch.optim.SGD(model.parameters(),
lr=args.learning_rate,
momentum=0.9,
weight_decay=args.weight_decay)
print("training.........................")
#设置测试损失list,和测试acc 列表
val_loss_list=[]
val_acc_list=[]
#设置训练损失list
train_loss_list=[]
for i in range(args.total_epoch):
model.train()
train_loss=0
for step, batch in enumerate(train_loader):
batch = tuple(t.to(args.device) for t in batch)
x, y = batch
loss = model(x, y)
train_loss +=loss.item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
#每训练一个epoch,记录一次训练损失
train_loss=train_loss/len(train_loader)
train_loss_list.append(train_loss)
np.savetxt("train_loss_list.txt", train_loss_list)
print("train Epoch:{},loss:{}".format(i,train_loss))
# 每个epcoh保存一次模型参数
save_model(args, model,i)
# 每训练一个epoch,用当前训练的模型对验证集进行测试
eval_loss, eval_acc = eval(args, model, test_loader)
#将每一个测试集验证的结果加入列表
val_loss_list.append(eval_loss)
val_acc_list.append(eval_acc)
np.savetxt("val_loss_list.txt",val_loss_list)
np.savetxt("val_acc_list.txt",val_acc_list)
print("val Epoch:{},eval_loss:{},eval_acc:{}".format(i, eval_loss, eval_acc))
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument("--dataset", choices=["cifar10", "cifar100"], default="cifar10",
help="Which downstream task.")
parser.add_argument("--output_dir", default="../output", type=str,
help="The output directory where checkpoints will be written.")
parser.add_argument("--img_size", default=224, type=int,help="Resolution size")
parser.add_argument("--train_batch_size", default=32, type=int,
help="Total batch size for training.")
parser.add_argument("--eval_batch_size", default=32, type=int,
help="Total batch size for eval.")
parser.add_argument("--learning_rate", default=3e-2, type=float,
help="The initial learning rate for SGD.")
parser.add_argument("--weight_decay", default=0, type=float,
help="Weight deay if we apply some.")
parser.add_argument("--total_epoch", default=1000, type=int,
help="Total number of training epochs to perform.")
args = parser.parse_args()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
args.device = device
args,modle=getVisionTransformers_model(args)
train(args,modle)
if __name__ == "__main__":
main()
后续待更新
3.参考文献
1.A N I MAGE IS W ORTH 16 X 16 W ORDS :T RANSFORMERS FOR I MAGE R ECOGNITION AT S CALE
2.https://blog.csdn.net/longxinchen_ml/article/details/86533005
3.李宏毅transformers视频讲解