06.ElasticSearch在Java中的使用
ElasticSearch在Java中的使用
-
- 引入依赖
- 索引、类型和映射的操作
-
- 1.创建客户端操作对象
- 2.创建索引
- 3.删除索引
- 4.创建索引、类型和映射
- 文档的操作
-
- 1.准备工作
-
- 1. 引入依赖
- 2.创建User实体类
- 3.编写TestDocumentBase公用编码
- 2.添加一个文档
-
- 1.自动生成id
- 2. 手动指定id
- 3.更新一条文档
- 4.删除一条文档
- 5.查询一条文档
- 6.按关键字查询文档
- 7.批量操作
- 8.文档的高级查询
-
- 1.查询所有
- 2.分页查询
- 3.排序
- 4.返回指定字段
- 5.term查询
- 6.range查询
- 7.wildcard查询
- 8.prefix查询
- 9.ids查询
- 10.fuzzy查询
- 11.bool查询
- 12.highLight查询
- 13.filter查询
引入依赖
我们使用上次介绍ElasticSearch远程扩展词典时创建的springboot项目es_remote_dict来讲述06.ElasticSearch在Java中的使用,首先在pom.xml中引入以下依赖
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>6.8.0version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>6.8.0version>
dependency>
<dependency>
<groupId>org.elasticsearch.plugingroupId>
<artifactId>transport-netty4-clientartifactId>
<version>6.8.0version>
dependency>
索引、类型和映射的操作
1.创建客户端操作对象
@Test
public void testCreateESClient() throws UnknownHostException {
PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY);
preBuiltTransportClient.addTransportAddress(new TransportAddress(
InetAddress.getByName("192.168.8.101"),9300));
}
2.创建索引
/**
* @Author Christy
* @Date 2021/4/29 11:19
**/
public class TestIndexTypeAndMapping {
private TransportClient transportClient;
@Before
public void before() throws UnknownHostException {
// 创建客户端
this.transportClient = new PreBuiltTransportClient(Settings.EMPTY);
// 设置ES服务地址和端口
transportClient.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.8.101"),9300));
}
@After
public void after(){
transportClient.close();
}
// 创建索引
@Test
public void createIndex(){
// 创建一个索引,前提是需要创建的索引不存在
CreateIndexResponse createIndexResponse = transportClient.admin().indices().prepareCreate("tide").get();
// 获取信息
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
}
运行createIndex(),我们可以看到索引创建成功
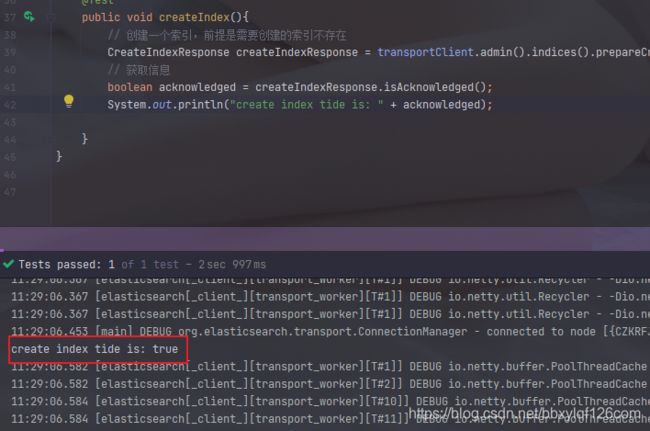
然后我们去kibana执行命令GET /_cat/indices?v查询一下索引是否存在

3.删除索引
// 删除索引
@Test
public void deleteIndex(){
AcknowledgedResponse tide = transportClient.admin().indices().prepareDelete("tide").get();
System.out.println("delete index tide is:" + tide.isAcknowledged());
}
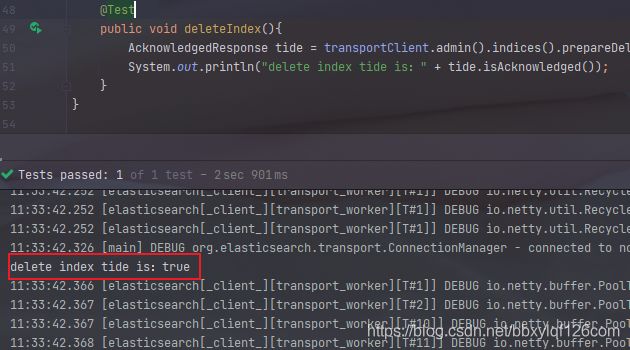
再去kibana中查询看索引是否还在

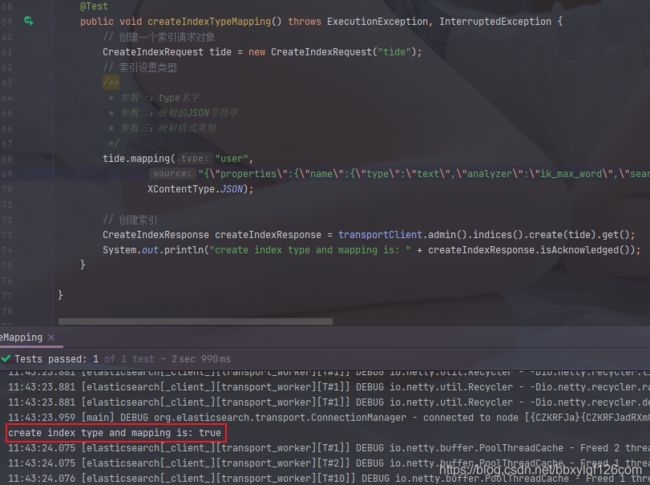
4.创建索引、类型和映射
// 创建索引 类型 映射
@Test
public void createIndexTypeMapping() throws ExecutionException, InterruptedException {
// 创建一个索引请求对象
CreateIndexRequest tide = new CreateIndexRequest("tide");
// 索引设置类型
/**
* 参数一:type名字
* 参数二:映射的JSON字符串
* 参数三:映射格式类型
*/
tide.mapping("user",
"{\"properties\":{\"name\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"search_analyzer\":\"ik_max_word\"},\"age\":{\"type\":\"integer\"},\"bir\":{\"type\":\"date\"},\"introduce\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"search_analyzer\":\"ik_max_word\"},\"address\":{\"type\":\"keyword\"}}}",
XContentType.JSON);
// 创建索引
CreateIndexResponse createIndexResponse = transportClient.admin().indices().create(tide).get();
System.out.println("create index type and mapping is: " + createIndexResponse.isAcknowledged());
}
执行结果显示成功
文档的操作
1.准备工作
1. 引入依赖
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.70version>
dependency>
2.创建User实体类
/**
* @Author Christy
* @Date 2021/4/29 12:40
**/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class User {
private String id;
private String name;
private Integer age;
private Date bir;
private String introduce;
private String address;
}
注意:User实体类中的属性必须跟ES中type的字段对应
3.编写TestDocumentBase公用编码
/**
* 文档的基本操作
* @author Christy
* @date 2021/4/29 12:44
* @return
*/
public class TestDocumentBase {
private TransportClient transportClient;
@Before
public void init() throws UnknownHostException {
// 创建客户端
this.transportClient = new PreBuiltTransportClient(Settings.EMPTY);
// 设置es服务地址
transportClient.addTransportAddresses(new TransportAddress(InetAddress.getByName("192.168.8.101"),9300));
}
@After
public void after(){
transportClient.close();
}
}
2.添加一个文档
1.自动生成id
/**
* 添加一个文档自动生成一个id
* @author Christy
* @date 2021/4/29 12:48
* @return
*/
public void createDocAutoId(){
// 构建一个文档
User user = new User(null, "孙悟空", 685, new Date(), "花果山水帘洞美猴王齐天大圣孙悟空", "花果山");
// 转为JSON
String userJSON = JSONObject.toJSONStringWithDateFormat(user, "yyyy-MM-dd");
IndexResponse indexResponse = transportClient.prepareIndex("tide", "user").setSource(userJSON, XContentType.JSON).get();
System.out.println("孙悟空出生了:" + indexResponse.status());
}

2. 手动指定id
/**
* 添加一个文档指定一个id
* @author Christy
* @date 2021/4/29 12:53
* @return
*/
public void createDocOptionId(){
// 构建一个文档
User user = new User("1", "猪八戒", 965, new Date(), "天蓬元帅猪刚鬣", "高老庄");
// 转为JSON
String userJSON = JSONObject.toJSONStringWithDateFormat(user, "yyyy-MM-dd");
IndexResponse indexResponse = transportClient.prepareIndex("tide", "user",user.getId()).setSource(userJSON, XContentType.JSON).get();
System.out.println("猪八戒投胎了:" + indexResponse.status());
}
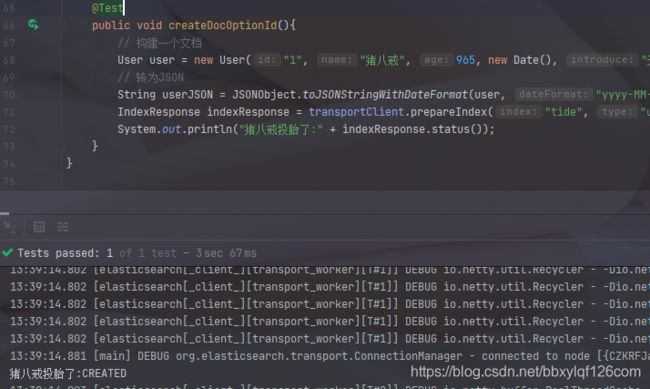
我们根据id的生成方式不同添加了两条数据,现在我们去kibana中查看一下

3.更新一条文档
/**
* 更新一条文档
* @author Christy
* @date 2021/4/29 13:41
* @return
*/
@Test
public void updateDoc(){
User user = new User();
user.setIntroduce("天蓬元帅猪八戒掌管10万天河水军,威风凛凛!");
String userJSON = JSONObject.toJSONString(user);
UpdateResponse updateResponse = transportClient.prepareUpdate("tide", "user", "1").setDoc(userJSON, XContentType.JSON).get();
System.out.println("猪八戒简介更新了:" + updateResponse.status());
}
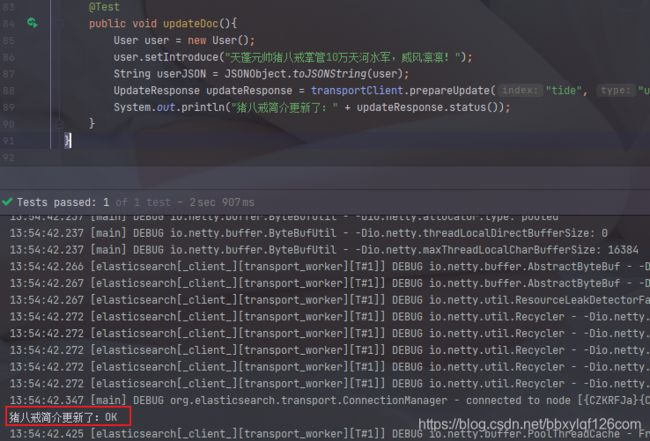
4.删除一条文档
/**
* 删除一条文档
* @author Christy
* @date 2021/4/29 13:57
* @return
*/
@Test
public void deleteOne(){
DeleteResponse deleteResponse = transportClient.prepareDelete("tide", "user", "roAjHHkBRz-Sn-2fB1gg").get();
System.out.println("孙悟空被六耳猕猴打死了:" + deleteResponse.status());
}
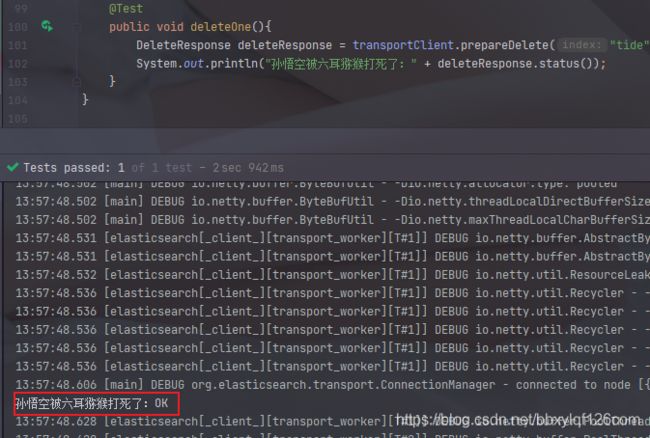
我们再去kibana中查看一下数据,发现孙悟空真的被六耳猕猴打死了o(╥﹏╥)o
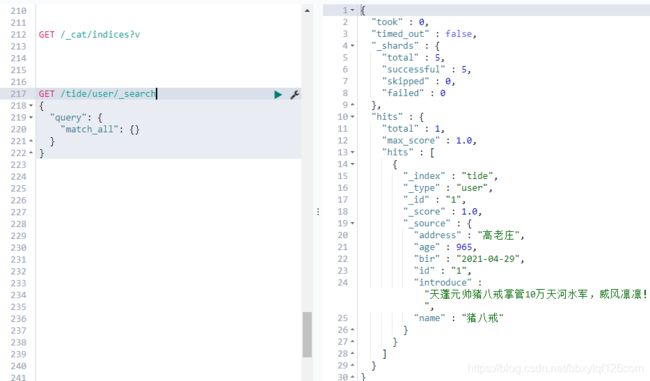
5.查询一条文档
/**
* 查询一条文档
* @author Christy
* @date 2021/4/29 14:08
* @param
* @return void
*/
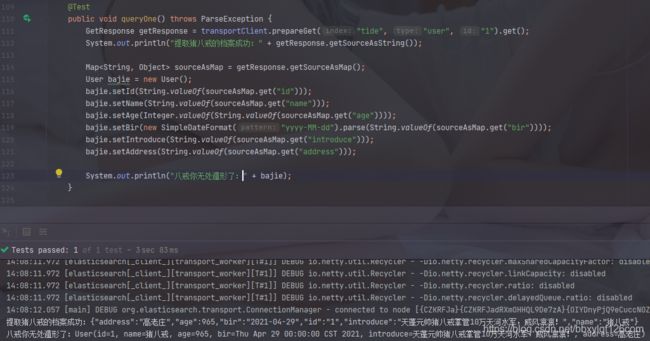
@Test
public void queryOne() throws ParseException {
GetResponse getResponse = transportClient.prepareGet("tide", "user", "1").get();
System.out.println("提取猪八戒的档案成功:" + getResponse.getSourceAsString());
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
User bajie = new User();
bajie.setId(String.valueOf(sourceAsMap.get("id")));
bajie.setName(String.valueOf(sourceAsMap.get("name")));
bajie.setAge(Integer.valueOf(String.valueOf(sourceAsMap.get("age"))));
bajie.setBir(new SimpleDateFormat("yyyy-MM-dd").parse(String.valueOf(sourceAsMap.get("bir"))));
bajie.setIntroduce(String.valueOf(sourceAsMap.get("introduce")));
bajie.setAddress(String.valueOf(sourceAsMap.get("address")));
System.out.println("八戒你无处遁形了:" + bajie);
}
6.按关键字查询文档
/**
* 查询所有符合条件的记录
* @author Christy
* @date 2021/4/29 14:34
* @param
* @return void
*/
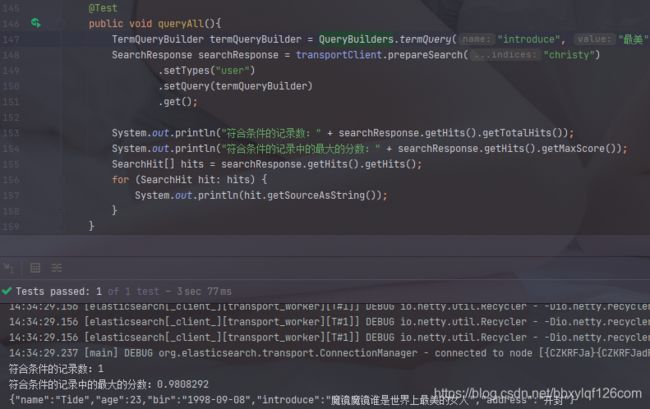
@Test
public void queryTerm(){
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("introduce", "最美");
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(termQueryBuilder)
.get();
System.out.println("符合条件的记录数:" + searchResponse.getHits().getTotalHits());
System.out.println("符合条件的记录中的最大的分数:" + searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit: hits) {
System.out.println(hit.getSourceAsString());
}
}
7.批量操作
/**
* 批量操作
* @author Christy
* @date 2021/4/29 14:50
* @param
* @return void
*/
@Test
public void bulk(){
User user = new User("10", "女娲", 100000, new Date(), "我是万物之主,整个宇宙都是我的", "九重天");
// 添加
IndexRequest indexRequest = new IndexRequest("christy", "user", user.getId())
.source(JSONObject.toJSONStringWithDateFormat(user,"yyyy-MM-dd"), XContentType.JSON);
// 删除 我们将Elastic、TOM和Jerry删除掉
DeleteRequest deleteRequest01 = new DeleteRequest("christy", "user", "qYAtG3kBRz-Sn-2fMFjj");
DeleteRequest deleteRequest02 = new DeleteRequest("christy", "user", "qIAtG3kBRz-Sn-2fMFjj");
DeleteRequest deleteRequest03 = new DeleteRequest("christy", "user", "q4AtG3kBRz-Sn-2fMFjj");
// 更新
User user01 = new User();
user01.setIntroduce("我是一个干饭人,干饭人之歌说的就是我");
UpdateRequest updateRequest = new UpdateRequest("christy", "user", "CszCGHkB5KgTrUTeLyE_").doc(JSONObject.toJSONString(user01), XContentType.JSON);
BulkRequestBuilder bulkRequestBuilder = transportClient.prepareBulk();
BulkResponse bulkItemResponses = bulkRequestBuilder.add(indexRequest)
.add(deleteRequest01)
.add(deleteRequest02)
.add(deleteRequest03)
.add(updateRequest)
.get();
BulkItemResponse[] items = bulkItemResponses.getItems();
for (BulkItemResponse item : items) {
System.out.println(item.status());
}
}
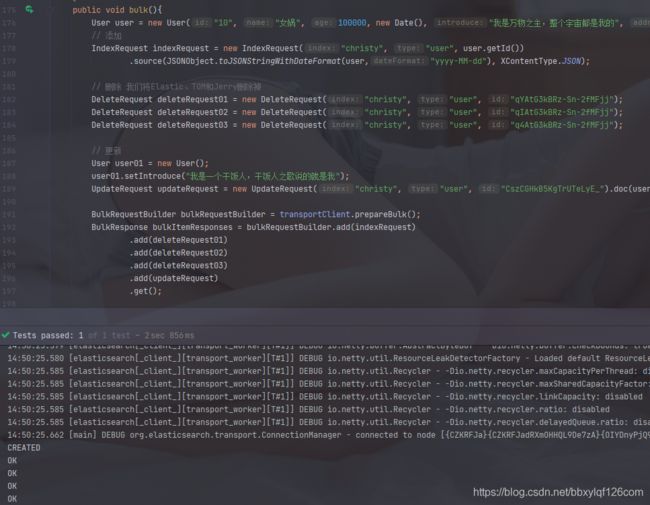
我们再去kibana查询一下结果,本来我们有12条数据,删除三条,新增一条,目前总数应该在10条,而且我们修改了干饭人的简介
8.文档的高级查询
1.查询所有
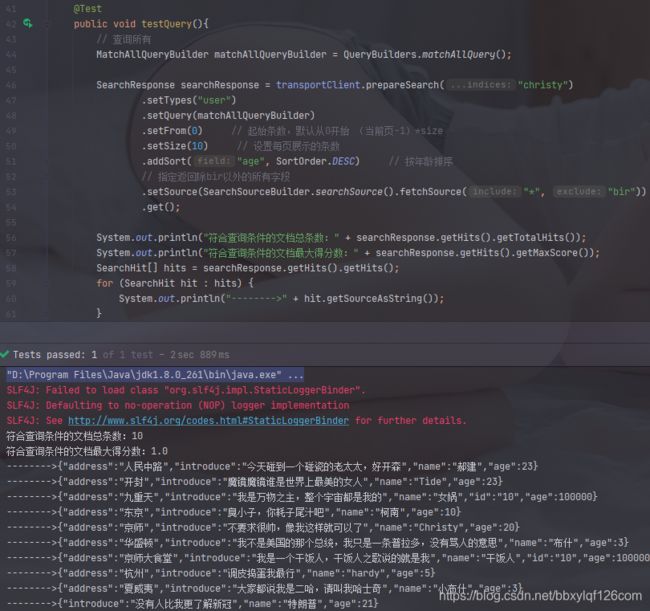
@Test
public void testQuery(){
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(matchAllQueryBuilder)
.get();
System.out.println("符合查询条件的文档总条数:" + searchResponse.getHits().getTotalHits());
System.out.println("符合查询条件的文档最大得分数:" + searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("-------->" + hit.getSourceAsString());
}
}

2.分页查询
@Test
public void testQuery(){
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(matchAllQueryBuilder)
.setFrom(0) // 起始条数,默认从0开始 (当前页-1)*size
.setSize(5) // 设置每页展示的条数
.get();
System.out.println("符合查询条件的文档总条数:" + searchResponse.getHits().getTotalHits());
System.out.println("符合查询条件的文档最大得分数:" + searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("-------->" + hit.getSourceAsString());
}
}

3.排序
@Test
public void testQuery(){
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(matchAllQueryBuilder)
.setFrom(0) // 起始条数,默认从0开始 (当前页-1)*size
.setSize(5) // 设置每页展示的条数
.addSort("age", SortOrder.DESC) // 按年龄排序
.get();
System.out.println("符合查询条件的文档总条数:" + searchResponse.getHits().getTotalHits());
System.out.println("符合查询条件的文档最大得分数:" + searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("-------->" + hit.getSourceAsString());
}
}

上面的输出结果中最大的分数为NaN,是因为我们自定义了排序规则导致原先系统的按分数排序失效
4.返回指定字段
@Test
public void testQuery(){
// 查询所有
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(matchAllQueryBuilder)
.setFrom(0) // 起始条数,默认从0开始 (当前页-1)*size
.setSize(10) // 设置每页展示的条数
.addSort("age", SortOrder.DESC) // 按年龄排序
// 指定返回除bir以外的所有字段
.setSource(SearchSourceBuilder.searchSource().fetchSource("*", "bir"))
.get();
System.out.println("符合查询条件的文档总条数:" + searchResponse.getHits().getTotalHits());
System.out.println("符合查询条件的文档最大得分数:" + searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("-------->" + hit.getSourceAsString());
}
query(matchAllQueryBuilder);
}
5.term查询
通过以上例子我们发现除了查询条件不一样,其余的代码可以公用,我们先来封装一下代码
public void query(QueryBuilder queryBuilder){
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(queryBuilder)
.setFrom(0) // 起始条数,默认从0开始 (当前页-1)*size
.setSize(10) // 设置每页展示的条数
.addSort("age", SortOrder.DESC) // 按年龄排序
.get();
System.out.println("符合查询条件的文档总条数:" + searchResponse.getHits().getTotalHits());
System.out.println("符合查询条件的文档最大得分数:" + searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("-------->" + hit.getSourceAsString());
}
}
构造一个term查询的queryBuilder
@Test
public void testQuery(){
// 查询所有
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// term查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("introduce", "最美");
query(termQueryBuilder);
}

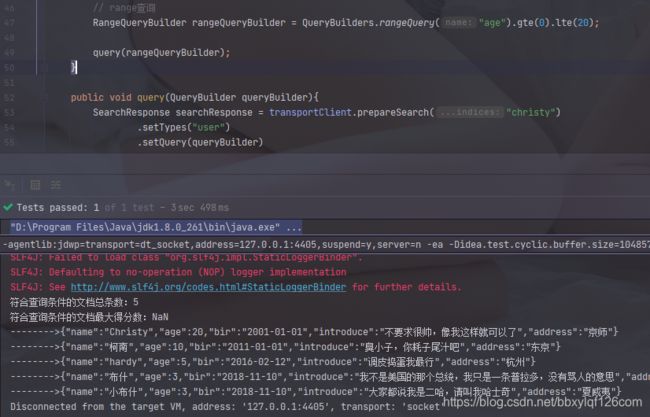
6.range查询
// range查询
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age").gte(0).lte(20);
query(rangeQueryBuilder);
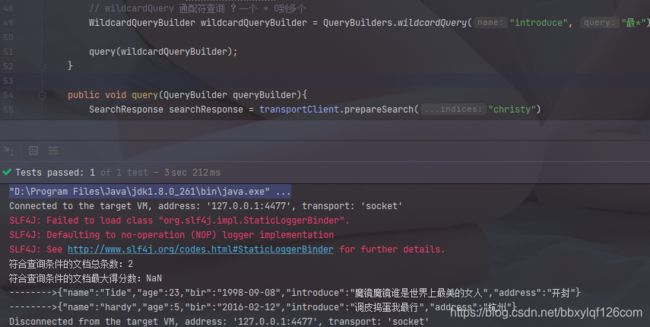
7.wildcard查询
// wildcardQuery 通配符查询 ?一个 * 0到多个
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("introduce", "最*");
query(wildcardQueryBuilder);
8.prefix查询
//prefixQuery 前缀查询
PrefixQueryBuilder prefixQueryBuilder = QueryBuilders.prefixQuery("introduce", "最");
query(prefixQueryBuilder);

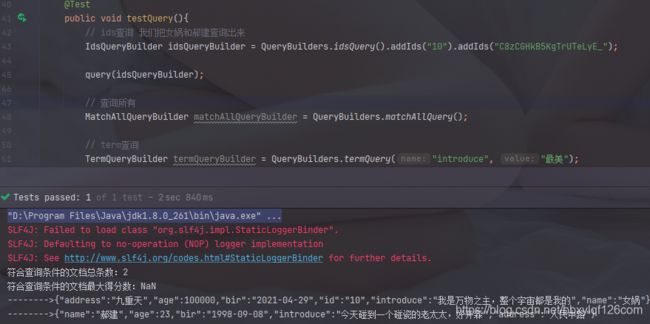
9.ids查询
// ids查询 我们把女娲和郝建查询出来
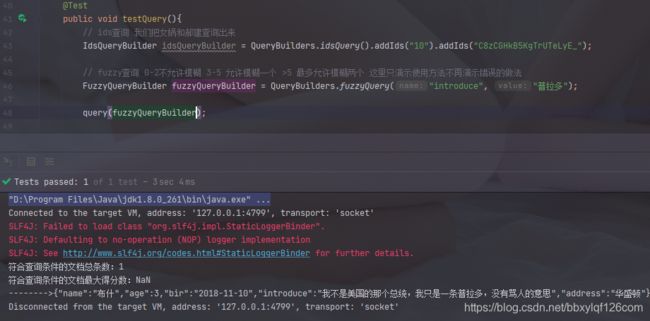
IdsQueryBuilder idsQueryBuilder = QueryBuilders.idsQuery().addIds("10").addIds("C8zCGHkB5KgTrUTeLyE_");
query(idsQueryBuilder);
10.fuzzy查询
// fuzzy查询 0-2不允许模糊 3-5 允许模糊一个 >5 最多允许模糊两个 这里只演示使用方法不再演示错误的做法
FuzzyQueryBuilder fuzzyQueryBuilder = QueryBuilders.fuzzyQuery("introduce", "普拉多");
query(fuzzyQueryBuilder);
11.bool查询
// bool查询 must must not should
// introduce 中包含最的
BoolQueryBuilder mustQueryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.termQuery("introduce", "最"));
query(mustQueryBuilder);
// introduce 中不包含最的
BoolQueryBuilder mustNotQueryBuilder = QueryBuilders.boolQuery().mustNot(QueryBuilders.termQuery("introduce", "最"));
query(mustNotQueryBuilder);
// introduce中包含最或者年龄大于等于10岁的
BoolQueryBuilder shouldQueryBuilder = QueryBuilders.boolQuery().should(QueryBuilders.termQuery("introduce", "最"))
.should(QueryBuilders.rangeQuery("age").gte(10));
query(shouldQueryBuilder);

12.highLight查询
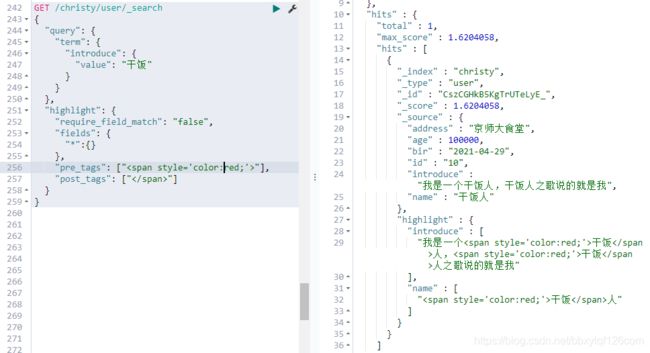
我们先回忆一下高亮的查询语法和查询结果,然后按照高亮的语法和结果来写这个高亮查询
GET /christy/user/_search
{
"query": {
"term": {
"introduce": {
"value": "干饭"
}
}
},
"highlight": {
"require_field_match": "false",
"fields": {
"*":{
}
},
"pre_tags": [""],
"post_tags": [""]
}
}
那么我们的Java的代码应该像下面这这样
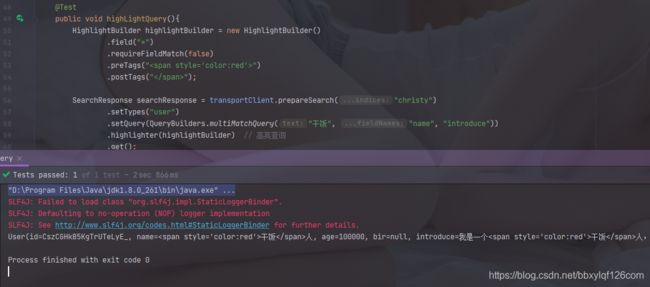
@Test
public void highLightQuery(){
HighlightBuilder highlightBuilder = new HighlightBuilder()
.field("*")
.requireFieldMatch(false)
.preTags("")
.postTags("");
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setQuery(QueryBuilders.multiMatchQuery("干饭", "name", "introduce"))
.highlighter(highlightBuilder) // 高亮查询
.get();
List<User> userList = new ArrayList<>();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
User user = new User();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
user.setId(hit.getId());
user.setName(sourceAsMap.get("name").toString());
user.setAge(Integer.valueOf(sourceAsMap.get("age").toString()));
// user.setBir(new SimpleDateFormat("yyyy-MM-dd").parse(sourceAsMap.get("bir").toString());
user.setIntroduce(sourceAsMap.get("introduce").toString());
user.setAddress(sourceAsMap.get("address").toString());
// 获取高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if(highlightFields.containsKey("name")){
String highLightName = highlightFields.get("name").fragments()[0].toString();
user.setName(highLightName);
}
if(highlightFields.containsKey("introduce")){
String highLightIntroduce = highlightFields.get("introduce").fragments()[0].toString();
user.setIntroduce(highLightIntroduce);
}
userList.add(user);
}
// 遍历输出替换高亮后的结果
userList.forEach(user -> System.out.println(user));
}
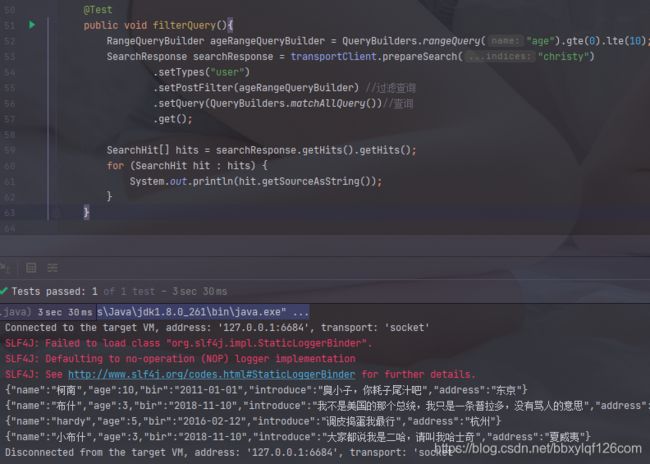
13.filter查询
/**
* 过滤查询 主要用在查询执行之前对大量数据进行筛选
* postFilter 用来过滤 * @author Christy
* @date 2021/4/29 18:43
* @return
*/
@Test
public void filterQuery(){
RangeQueryBuilder ageRangeQueryBuilder = QueryBuilders.rangeQuery("age").gte(0).lte(10);
SearchResponse searchResponse = transportClient.prepareSearch("christy")
.setTypes("user")
.setPostFilter(ageRangeQueryBuilder) //过滤查询
.setQuery(QueryBuilders.matchAllQuery())//查询
.get();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}