08.ElasticSearch集群搭建
ElasticSearch集群搭建
-
- 概念
-
- 集群(cluster)
- 节点(node)
- 分片和复制
- 集群架构图
- 集群搭建
- 安装head插件
-
- 下载head nodejs
- root用户上传包
- 安装nodejs
-
- 解压缩node.js
-
- 1.将node解压成tar包
- 2.执行tar命令解压缩node
- 配置环境变量
- 安装elasticsearch-head
-
- 1.解压缩
- 2.设置镜像
- 3.安装
- 4.启动head
- 5.配置跨域
-
- 1.关闭ES
- 2.配置跨域
- 6.重新启动集群
- 7.数据测试
概念
集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有完整的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
集群能解决以下问题
1.单节点压力问题 并发压力 物理资源上限压力
2.数据冗余备份能力
节点(node)
一个节点是集群中的一个服务器,作为集群的一部分存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,这个名字会在启动的时候赋予节点。
默认情况下,每个节点都会被安排加入到一个叫 做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点, 这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
分片和复制
Elasticsearch提供了将索引划分成多份的能力,每一份都就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置 到集群中的任何节点上。
Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。注意复制分片从不与原/主要 (original/primary)分片置于同一节点上是非常重要的。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个 索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,
Elasticsearch中的每个索引被分片5个主分片和1个复制(6.x),这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个 索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的
集群架构图

集群搭建
1.首先要关闭我们正在运行的ElasticSearch服务,然后将安装包复制三份
cp -r elasticsearch-6.8.0 node01
cp -r elasticsearch-6.8.0 node02
cp -r elasticsearch-6.8.0 node03
2.删除复制节点中的data目录(创建集群之前需要删除之前的使用数据)
rm -rf node01/data
rm -rf node02/data
rm -rf node03/data
3.设置ElasticSearch每个节点所占用内存的大小
还记得我们安装虚拟机的时候设置的内存大小是2G,安装ElasticSearch的时候设置的占用内存是1G,现在如果有三个节点同时启动的话显然内存是不够用的,这里有两种方案
1).更改虚拟机的内存大小为4G(最大不能超过物理机的内存大小)
2).更改每个节点所占内存的大小,内存2G,三个节点,每个节点我们分成512M即可
vim node01/config/jvm.options
vim node02/config/jvm.options
vim node03/config/jvm.options
# 进去之后更改-Xms1g -Xms512m; -Xmx1g -Xmx512m
这里我们选择用第一种方法,更改虚拟机的内存为4G(虚拟机-设置-内存,这里需要关闭虚拟机才可以)
4.分别修改三个节点中config目录中elasticsearch.yml文件
vim node01/config/elasticsearch.yml
vim node02/config/elasticsearch.yml
vim node03/config/elasticsearch.yml
# 分别修改以下配置
cluster.name: christy-es #集群名称(集群名称必须一致)
node.name: node01 #节点名称(节点名称不能一致)
network.host: 0.0.0.0 #监听地址(必须开启远程权限,并关闭防火墙)
http.port: 9201 #监听端口(在一台机器时服务端口不能一致)
# 另外两个节点的ip
discovery.zen.ping.unicast.hosts: ["192.168.8.101:9302", "192.168.8.101:9303"]
gateway.recover_after_nodes: 3 #集群可做master的最小节点数
transport.tcp.port: 9301 #集群TCP端口(在一台机器搭建必须修改)
5.分别启动三个ES节点
./node01/bin/elasticsearch
./node02/bin/elasticsearch
./node03/bin/elasticsearch
6.查看节点状态
curl http://192.168.8.101:9201
curl http://192.168.8.101:9202
curl http://192.168.8.101:9203
7. 查看集群健康(可以在任何一个节点上查看集群状态)
http://192.168.8.101:9201/_cat/health?v
8.kibana中查看集群
这个时候需要更改kibana的配置文件,修改elasticsearch.hosts:[host(集群中任何一个节点即可)],然后重新启动kibana就可以了
安装head插件
下载head nodejs
点击下面的链接直接下载即可
elasticsearch-head
nodejs_v12.13.1
root用户上传包
安装nodejs
解压缩node.js
因为nodejs的后缀名是xz,这里分两步
1.将node解压成tar包
2.执行tar命令解压缩node

配置环境变量
执行命令vim /etc/profile,配置一下命令
export NODE_HOME=/usr/tools/node-v12.13.1-linux-x64
export PATH=$PATH:$JAVA_HOME/bin:$NODE_HOME/bin
完了不要忘记执行命令source /etc/profile,使命令立即生效
当您在任意目录执行node -v能查看到node的具体版本,就说明node安装成功了

安装elasticsearch-head
1.解压缩
执行命令unzip elasticsearch-head-master.zip解压缩head安装包

2.设置镜像
这个原理就像设置maven的国内镜像一样,执行以下命令设置node的镜像为淘宝的镜像
npm config set registry https://registry.npm.taobao.org
3.安装
执行命令npm install安装node(这会有一个安装插件的过程需耐心等待)
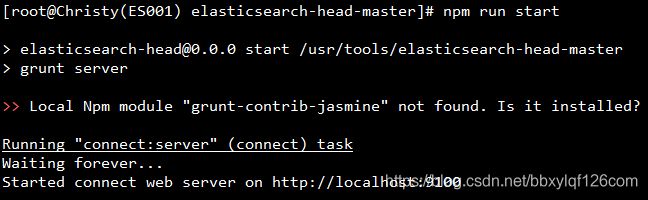
4.启动head
执行命令npm run start,如果出现下图则说明head插件安装成功了(head的默认端口9100)
5.配置跨域
上面head插件虽然已经安装成功了,但是由于head是一个第三方插件,我们上面也说了head的端口是9100。直接访问ES的话会存在跨域的问题而访问不了

上图可以看到head的网址可以访问,但是链接不上我们的ElasticSearch集群
1.关闭ES
首先关闭我们ELasticSearch集群的所有节点,由于我们之前是前台启动的方式,所以直接Ctrl+c就可以了
2.配置跨域
执行编辑命令vim node01/config/elasticsearch.yml,vim node02/config/elasticsearch.yml,vim node03/config/elasticsearch.yml,在每个节点的配置文件末尾添加以下代码
# 开启head插件的访问
http.cors.enabled: true
http.cors.allow-origin: "*"
6.重新启动集群
重新启动集群之后,我们再次访问各个节点查看状态


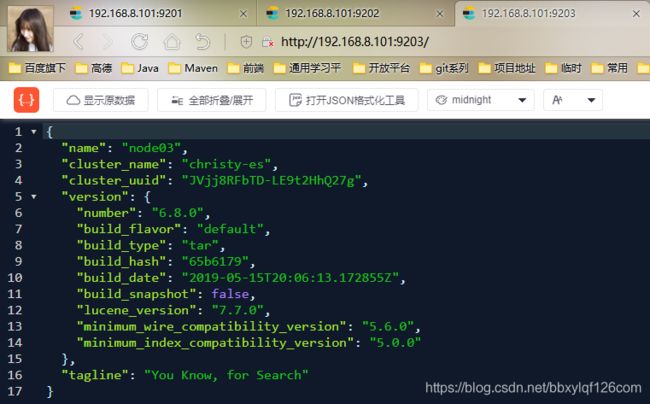
三个节点都已经正常启动,我们再去访问head的地址http://192.168.8.101:9100/,然后输入集群中任一节点的地址进行连接,这里我们就连接node01的地址http://192.168.8.101:9201/看看效果

上图就说明我们的head插件已经连接上了我们之前搭建的ElasticSearch集群
7.数据测试
打开我们的kibana(不要忘记修改kibana的配置文件连接我们的集群),在Monitoring中也能看到我们集群状态

进入到Dev Tools中往集群中插入数据
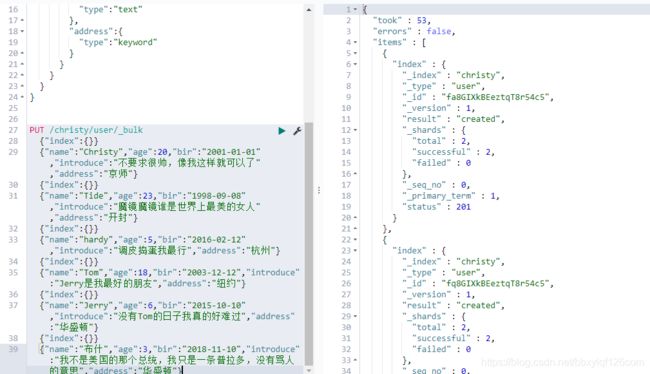
然后我们再回到head中刷新一下页面,可以看到这次页面就跟没有数据的时候的差别了
