Spring源码探究(一)
第一章 IOC容器的两个接口
在使用Spring的过程中,我们需要书写的第一行代码就为:
ApplicationContext context =new ClassPathXmlApplicationContext("SpringDao.xml");
在学习IOC的时候我们就知道:Spring提供的IOC容器实现的两个接口为BeanFactory接口和ApplicationContext接口。
(面试题)ApplicationContext接口是BeanFactory的子接口并且多了以下功能:
- 与Spring的AOP功能轻松集成
- 消息资源处理(用于国际化)
- 活动发布
- 应用层特定的上下文,例如WebApplicationContext 用于Web应用程序中的。
- 在启动的时候就把所有的Bean全部实例化了,它还可以为Bean配置lazy-init=true来让Bean延迟实例化。但是对于BeanFactory来说,它在启动的时候不会去实例化Bean,只有从容器中拿Bean的时候才会去实例化。
一. BeanFactory接口
BeanFactory 接口是 Spring 的“心脏”。它就是 Spring IoC 容器的真面目。Spring 使用该接口来实例化、配置和管理 Bean。它最重要的方法就是 getBean() ,作用是返回特定的名称的Bean,该方法是IOC容器获取bean对象和引发依赖注入的起点。以下是源码:
package org.springframework.beans.factory;
import org.springframework.beans.BeansException;
import org.springframework.core.ResolvableType;
import org.springframework.lang.Nullable;
#该接口会加载存储在配置源中的Bean定义,并使用org.springframework.beans包来配置Bean。
#但是,实现可以根据需要直接在Java代码中直接返回它创建的Java对象。
#定义的存储方式没有任何限制:LDAP,RDBMS,XML,属性文件等。鼓励实现以支持Bean之间的引用(依赖注入)
public interface BeanFactory {
// 用于返回FactoryBean对象用的前缀
String FACTORY_BEAN_PREFIX = "&";
// 返回指定名称的Bean实例。如果找不到该bean,会在父工厂中寻找
Object getBean(String name) throws BeansException;
<T> T getBean(String name, Class<T> requiredType) throws BeansException;
Object getBean(String name, Object... args) throws BeansException;
<T> T getBean(Class<T> requiredType) throws BeansException;
<T> T getBean(Class<T> requiredType, Object... args) throws BeansException;
// 获取bean的提供者(对象工厂)
<T> ObjectProvider<T> getBeanProvider(Class<T> requiredType);
<T> ObjectProvider<T> getBeanProvider(ResolvableType requiredType);
// 这个bean工厂是否包含给定名称的bean
boolean containsBean(String name);
// 是否为单例
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;
// 是否为原型
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;
// 指定名字的bean是否和指定的类型匹配
boolean isTypeMatch(String name, ResolvableType typeToMatch) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String name, Class<?> typeToMatch) throws NoSuchBeanDefinitionException;
// 获取指定名字的bean的类型
Class<?> getType(String name) throws NoSuchBeanDefinitionException;
Class<?> getType(String name, boolean allowFactoryBeanInit) throws NoSuchBeanDefinitionException;
// 获取指定名字的bean的所有别名
String[] getAliases(String name);
}
1. String FACTORY_BEAN_PREFIX = “&”
该String类型的变量是用于获取FactoryBean对象。
首先我们需要来了解什么是FactoryBean。FactoryBean属于工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑:
FactoryBean:FactoryBean 在IOC容器的基础上给 Bean 的实现加上了一个简单工厂模式和装饰模式。任何一个实现了该接口的 bean 对象都为FactoryBean,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean。
举例说明:首先创建 MyFacrotyBeanTest 类实现FactoryBean接口,重写getObject()和getObjectType()方法。内有一个其他bean对象:
public class MyFacrotyBeanTest implements FactoryBean {
//其他bean对象的引用
Student studentByFactoryBean;
//对Student这个bean的定制逻辑
//在实际开发中,我们是通过Class.forName(interfaceName)来获得bean对象,再通过代理模式增强。
//将增强的bean的返回
public Object getObject() throws Exception {
return studentByFactoryBean;
}
public Class<?> getObjectType() {
return null;
}
}
将 MyFacrotyBeanTest 加入Spring的容器后,然后通过xml(或者注解)配置该类的属性。通过以下代码返回的是MyFacrotyBeanTest类增强的Student类bean对象(也就是getObject()方法的返回值):
ApplicationContext context =new ClassPathXmlApplicationContext("SpringDao.xml");
//会返回增强的bean对象,也就是 getObject()方法返回的对象
Object bean = context.getBean("MyFacrotyBeanTest");
如果要获取MyFacrotyBeanTest对象就需要在 id 前加上 & :
Object bean = context.getBean("&MyFacrotyBeanTest");
以下是FactoryBean的源码:
package org.springframework.beans.factory;
public interface FactoryBean<T> {
//返回由FactoryBean创建的Bean实例
//如果isSingleton()返回true,则该实例会放到Spring容器中单实例缓存池中
T getObject() throws Exception;
//返回FactoryBean创建的Bean类型。
Class<?> getObjectType();
//返回由FactoryBean创建的Bean实例的作用域是singleton还是prototype
boolean isSingleton();
}
(面试题)BeanFactory和FactoryBean的区别:
- BeanFactory。是个Factory,也就是IOC容器或对象工厂, 它负责生产和管理bean的一个工厂。在Spring中,BeanFactory是IOC容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。
- FactoryBean。FactoryBean属于工厂类接口,FactoryBean是个Bean。用户可以通过实现该接口定制实例化Bean的逻辑。简单来说它是一个可以对目标bean对象修饰的工厂bean.
2.getBean()方法
该方法为重要方法,在以后单独讲解。
二. ApplicationContext接口
Spring官方说明,绝大多数情况下建议使用ApplicationContext。前文说过ApplicationContext对BeanFactory进行了扩展。
利用MessageSource进行国际化
BeanFactory是不支持国际化功能的,因为BeanFactory没有扩展Spring中MessageResource接口。相反,由于ApplicationContext扩展了MessageResource接口,因而具有消息处理的能力(i18N)。
事件机制(Event)
ApplicationContext的事件机制主要通过ApplicationEvent和ApplicationListener这两个接口来提供的,当ApplicationContext中发布一个事件的时,所有扩展了ApplicationListener的Bean都将会接受到这个事件,并进行相应的处理。 Spring提供了部分内置事件,主要有以下几种:
- ContextRefreshedEvent:ApplicationContext发送该事件时,表示该容器中所有的Bean都已经被装载完成,此ApplicationContext已就绪可用
- ContextStartedEvent:生命周期 beans的启动信号
- ContextStoppedEvent: 生命周期 beans的停止信号
- ContextClosedEvent:ApplicationContext关闭事件,则context不能刷新和重启,从而所有的singleton bean全部销毁(因为singleton bean是存在容器缓存中的)
用户也可根据自己需要来扩展spriong中的事物,扩展的事件都要实现ApplicationEvent接口。
底层资源的访问
ApplicationContext扩展了ResourceLoader(资源加载器)接口,从而可以用来加载多个Resource,而BeanFactory是没有扩展ResourceLoader。
对Web应用的支持
与BeanFactory通常以编程的方式被创建不同的是,ApplicationContext能以声明的方式创建,如使用ContextLoader。当然你也可以使用ApplicationContext的实现之一来以编程的方式创建ApplicationContext实例 。
| ApplicationContext常用实现类 | 作用 |
|---|---|
| AnnotationConfigApplicationContext | 从一个或多个基于java的配置类中加载上下文定义,适用于java注解的方式。 |
| ClassPathXmlApplicationContext | 从类路径下的一个或多个xml配置文件中加载上下文定义,适用于xml配置的方式。 |
| FileSystemXmlApplicationContext | 从文件系统下的一个或多个xml配置文件中加载上下文定义,也就是说系统盘符中加载xml配置文件。 |
| AnnotationConfigWebApplicationContext | 专门为web应用准备的,适用于注解方式。 |
| XmlWebApplicationContext | 从web应用下的一个或多个xml配置文件加载上下文定义,适用于xml配置方式。 |
第二章 循环依赖与三级缓存
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。注意:循环依赖不是循环调用。循环调用是方法之间的环调用,并且循环调用是无法解决的,除非有结束条件,否则就是死循环最终导致内存溢出错误。
Spring解决循环依赖的类是DefaultSingletonBeanRegistry,用于注册,获得,管理singleton单例对象,它实现了SingletonBeanRegistry接口。该类中就有解决循环依赖的三级缓存:
//一级缓存。用于保存BeanName和创建Bean实例之间的关系。用于存放完全初始化好了的Bean对象
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存。用于保存BeanName和创建Bean实例之间的关系。与singletonObjects不同之处在于:
//当一个单例Bean对象放里面后,那么当Bean还在创建过程中,就可以通过getBean()方法获取到了.
//也就是说,它是存放尚未填充属性的原始Bean对象,用于检测循环依赖的引用.
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存。用于保存BeanName和创建Bean的工厂之间的关系。
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
还有其他两个比较重要的集合:
//用于保存正在创建的Bean的标识符
private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
//用于保存已经创建完毕的Bean的标识符
private final Set<String> alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256));
一 Spring的循环依赖
关于Spring bean的创建,其本质上还是一个对象的创建,既然是对象,一定要明白一个完整的对象包含两部分:当前对象实例化和对象属性的实例化。
在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过一定的方式设置的。而循环依赖就发生在对象的属性设置的时候。
在Spring的循环依赖中一共有三种情况:构造器注入循环依赖、field属性注入(setter方法注入)循环依赖、prototype field属性注入循环依赖。
构造器注入循环依赖(无法解决)
@Service
public class A {
public A(B b) {
}
}
@Service
public class B {
public B(A a) {
}
}
对于构造器注入循环依赖,Spring本来想以普通框架的身份与我们相处,但是换来的却是BeanCurrentlyInCreationException异常,因此Spring直接摊牌了:我无法解决构造器注入循环依赖。
原因: Spring解决循环依赖依靠的是Bean的“中间态”这个概念,而这个中间态指的是已经实例化,但还没设置属性的状态。而构造器是用于完成实例化的,所以构造器的循环依赖无法解决。
setter方法循环依赖(可解决)
对于Setter方法的依赖注入,Spring会提前暴露刚完成构造器注入但未完成属性设置的Bean对象来完成的,并且只能解决单例作用域的Bean的循环依赖。通过暴露一个单例工厂方法,从而使其他Bean能引用到该Bean。
prototype field属性注入循环依赖(无法解决)
无法解决。只是由于Spring中对于prototype作用域的Bean对象不进行缓存,自然也无法提前暴露一个Bean对象供其他Bean对象引用。
原因: 多实例Bean是每次创建都会调用doGetBean方法,根本没有使用一二三级缓存,肯定不能解决循环依赖。
涉及到循环依赖处理的的方法为getSingleton的两个重载方法和doCreateBean()方法。为了分析方便我们首先建立两个类,让他们首先构成 set 注入的循环依赖:
public class A {
private B b;
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
}
public class B {
private A a;
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
}
1. getSingleton()
当通过A a=(A) context.getBean("A")来获取目标对象的时候,实际上是调用AbstractBeanFactory类的getBean()方法,内部又实际调用了doGetBean()方法。
在doGetBean()方法内部调用了以下的getSingleton()方法。首先我们需要知道单例Bean对象只在Spring容器中加载一次,后续如果要使用该对象直接从容器中获取即可。该方法是尝试从缓存中获取对象,而我们的容器才刚创建自然其中没有A对象,对于A对象来说该方法就只是走个过场,会直接返回Null
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//首先从singletonObjects集合中查看是否有A对象
//singletonObjects也就是我们的一级缓存
Object singletonObject = this.singletonObjects.get(beanName);
//如果没有获取到,并且singletonsCurrentlyInCreation集合中包含A对象
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从二级缓存中查询,获取Bean的早期引用。
//所谓早期引用是指:实例化完成但是未赋值完成的Bean。
singletonObject = this.earlySingletonObjects.get(beanName);
//二级缓存中不存在,并且allowEarlyReference=true
//allowEarlyReference:是否允许早期引用。
if (singletonObject == null && allowEarlyReference) {
//从三级缓存中查询,获取Bean的早期引用。
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
//如果从三级缓存中查询到了
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//添加至二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存中移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
注意isSingletonCurrentlyInCreation(beanName)是判断singletonsCurrentlyInCreation集合中是否包含A对象。前文我们说过该集合的作用是:用于保存正在创建的Bean的标识符。由于此时只是从缓存中查询并没有创建对象,自然返回false。
2. getSingleton()的重载
上诉方法执行完毕过后返回null,在缓存中没有找到想要的bean对象后,自然我们需要从头开始bean的加载了,但是我们需要对该bean对象进行类型检测,因为只有在单例情况下才会尝试解决循环依赖:
//如果是Prototype就抛出错误
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
检测完毕后,Spring使用getSingleton()的重载方法来进行bean的创建,但它先会记录加载状态,也就是记录A对象正在创建,记录完毕后才开始正在创建:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
//全局变量需要同步
synchronized (this.singletonObjects) {
//首先检测Bean对象是否已经加载过,因为其实Singleton模式其实就是复用以创建bean,此处是必要的!
Object singletonObject = this.singletonObjects.get(beanName);
//singletonObject为空才能继续执行
if (singletonObject == null) {
//省略代码
//记录加载状态,也就是将当前正要创建的bean记录在singletonsCurrentlyInCreation缓存中
//与前文isSingletonCurrentlyInCreation(beanName)对应!
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
//初始化Bean,真正的创建对象的代码
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
//省略代码
}
catch (BeanCreationException ex) {
//省略代码
}
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
//当bean加载结束后,A对象就不再是正在创建状态了。
//因此从singletonsCurrentlyInCreation缓存中移除。
afterSingletonCreation(beanName);
}
if (newSingleton) {
//加入singletonObjects缓存,也就是一级缓存。
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
singletonObject = singletonFactory.getObject()该段代码其实是调用AbstractBeanFactory类中的doGetBean()方法中的一段代码:
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
重要的是createBean(beanName, mbd, args)它有如下功能:
- 根据设置的class属性或者根据className来解析class;
- 对override标记进行标记及其验证
Object bean = resolveBeforeInstantiation(beanName, mbdToUse)。此行代码是我们实现AOP功能的关键。并且BeanFactoryPostProcessor与BeanPostProcessor在此处出现了!!- 调用
doCreateBean()方法来真正创建A对象!
3. doCreateBean()
doCreateBean()方法是创建Bean对象的核心方法,该方法里面包括了解析Bean对象的class属性、构造方法,依赖注入等等。此处我们只分析与循环依赖相关的代码。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
BeanWrapper instanceWrapper = null;
//省略代码
if (instanceWrapper == null) {
//创建原始对象,创建出来的对象没有填充属性
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//省略代码
//重要代码。解决循环依赖
//如果是单例bean&&允许循环依赖&&当前bean正在创建,则将创建Bean的工厂对象加入三级缓存
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// addSingletonFactory()加入三级缓存
// getEarlyBeanReference():有循环依赖的时候,AOP将在此处将Advice动态织入Bean中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
try {
//依赖注入相关。引发循环依赖。
//因为我们的A对象中含有B对象的属性,这下子B对象就要此处之前的流程了
populateBean(beanName, mbd, instanceWrapper);
// 初始化方法调用
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
//省略代码
}
//下面的if语块其实是与AOP相关
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
//省略代码
}
}
}
try {
// 注册销毁逻辑
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
}
addSingletonFactory(beanName, () ......):将A对象加入三级缓存,再次强调放入三级缓存中的Bean对象依旧只是实例化还未填充属性的对象!
-> getEarlyBeanReference(beanName, mbd, bean):通过该方法提前暴露出去的一个对象,还不是一个完整的Bean。还有个作用就是:当开启了AOP并且有循环依赖的时候,AOP将在此处将Advice动态织入Bean中。 并且在创建A对象的过程中是不会调用该方法,而是在创建B对象的过程中被调用。
populateBean(beanName, mbd, instanceWrapper):该方法起到填充属性的。但是由于A对象中含有B对象属性,因此在调用该方法的时候发现B对象属性,因此,B对象也要走前面得流程!。
当B对象走到了populateBean()这个方法时,又发现了B对象中含有A对象属性(该属性我们暂且叫它为B-A),那么B-A又要开始走前面的流程,但是别忘了第1点getSingleton()方法中:
//由于A对象正常创建,所以isSingletonCurrentlyInCreation(beanName)不再返回false而是true!!!
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//会直接到三级缓存中获取A对象的早期引用
//从而完成B对象的创建
//此处实际就调用了getEarlyBeanReference(beanName, mbd, bean)方法
singletonObject = singletonFactory.getObject();
//获得以后,二级缓存添加该对象
this.earlySingletonObjects.put(beanName, singletonObject);
//三级缓存中清除该对象的工厂对象
this.singletonFactories.remove(beanName);
}
}
}
}
由于A对象已经存放在三级缓存中了,通过以上逻辑,此时A对象(也就是B-A)会从三级缓存中移动到二级缓存中,特别注意singletonObject = singletonFactory.getObject(),这段代码实际调用的是:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
//if语块都是为了AOP做判断用
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
//如果有AOP,则进入该方法。
//实际调用AbstractAutoProxyCreator类的getEarlyBeanReference()方法
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
//如果没有AOP,就直接到此处,将对象返回
return exposedObject;
}
这段代码的作用在于,如果A开启了AOP功能,那么将A对象包装成A的代理对象并放进二级缓存中。
当B对象会从二级缓存中拿到A对象后完成赋值,B对象成功后加入一级缓存。此时需要注意,如果A开启了AOP功能,那么说明B对象中的A对象属性一定注入的是A的代理对象,换句话说A已经被代理了。Spring有多处机会可以返回一个proxy对象,但是,最终只要在其中一处处理了,其他处根本不再继续处理。因此回到doCreateBean()方法的if (earlySingletonExposure)判断语块:
//当B已经加入一级缓存,A的属性填充完毕,此处调用初始化方法开始初始化A时
// initializeBean()`方法中不再生成代理对象,左边的exposedObject为原对象
exposedObject = initializeBean(beanName, exposedObject, mbd);
//省略代码
//earlySingletonExposure=true
if (earlySingletonExposure) {
//第二个参数为false,不会从三级缓存中取值,而是从二级缓存中取值
//此处二级缓存中的B-A对象是A的代理对象,因此earlySingletonReference= A的代理对象
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
//用代理对象替换掉原对象
exposedObject = earlySingletonReference;
}
//省略代码
}
}
}
一般来说在Spring中都是在initializeBean()方法中完成AOP代理,但是在此处由于循环依赖的原因,在 getEarlyBeanReference()方法中已经提前生成了代理对象(也就是咱们的B-A),所以在initializeBean()方法中不再生成代理对象。我们在上述if语块中用代理对象替换掉原对象,保证最终A对象就是代理对象。
也就是说,Spring在实例化一个bean的时候,是首先递归的实例化其所依赖的所有bean,直到某个bean没有依赖其他bean,此时就会将该实例返回,然后反递归的将获取到的bean设置为各个上层bean的属性的。
总结如下:
- 流程从 getBean 方法开始,getBean 是个空壳方法,所有逻辑直接到doGetBean 方法中。后通过
getSingleton(beanName)方法尝试从缓存中查找是不是有该实例。 - 缓存中没有找到实例就会父工厂中寻找,还是没有的话就调用
getSingleton(String beanName, ObjectFactory singletonFactory)方法来进行bean的加载,在此方法中会对A对象进行标记,标记它为正在加载。 - 关于bean加载的重要方法为
doGetBean(),因为它涉及到对象的创建和populateBean()方法对属性赋值。对A对象属性赋值之前,会把创建A对象的工厂对象放进三级缓存。 - 当对A对象属性进行赋值的时候,会发现属性含有B对象。因此会开始创建B对象,B对象会进行前面1~3步。
- 当创建B对象的流程来到
populateBean()方法又发现了B对象中含有A对象属性。此时又将进行该属性B-A的创建,但是由于第2步我们已经对A对象进行了标记,因此会直接去三级缓存中利用工厂方法来获得A对象的早期引用,完成B对象的属性赋值并放进一级缓存中 - B对象创建完成,A对象也自然能顺利创建放入一级缓存中。
参考资料:同事踩进Spring循环依赖的坑出不来,被我diss了。里面有个动态图,非常清晰明了!
二 三级缓存的作用
通过对于循环依赖流程的分析,我们发现了一个问题:解决循环依赖的关键就是创建一个对象的早期引用并且缓存起来,在创建另外一个对象的时候注入进去。既然这样,似乎二级缓存就够用了,那为何还需要三级缓存?
实际上,对于普通的循环依赖,三级缓存一点用处都没有!直接上二级缓存就完事儿了。但是我们忽略了Spring的另外一个强大功能-AOP,三级缓存实际上跟Spring中的AOP相关。从源码层面详解Spring循环依赖。
首先回到doCreateBean()方法中:
package org.springframework.beans.factory.support;
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
//省略代码
if (instanceWrapper == null) {
//创建原始对象,创建出来的对象没有填充属性
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//如果是单例bean&&允许循环依赖&&当前bean正在创建,则将创建Bean的工厂对象加入三级缓存
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// getEarlyBeanReference():我们熟知的AOP就是在此处将Advice动态织入Bean中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
//因为我们的A对象中含有B对象的属性,这下子B对象就要此处之前的流程了
populateBean(beanName, mbd, instanceWrapper);
// 初始化方法调用
exposedObject = initializeBean(beanName, exposedObject, mbd);
//省略代码
}
进入getEarlyBeanReference()方法中,前文已经介绍过了,该方法作用在于:如果没有开启AOP功能,则直接将实例化阶段创建的对象返回;如果开启了AOP功能则返回代理对象! 前文提到了只有在创建B对象的过程中才会被调用,这里再明确一下:是在注入B对象中的B-A属性时才会调用该方法,也就是总结中的第5点>>去三级缓存中获取A对象的早期引用的时候。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
//if语块都是为了AOP做判断用
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
//如果有AOP,则进入该方法。
//实际调用AbstractAutoProxyCreator类的getEarlyBeanReference()方法
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
//如果没有AOP,就直接到此处,将对象返回
return exposedObject;
}
如果在开启AOP的情况下,那么就是调用到AbstractAutoProxyCreator的getEarlyBeanReference方法,对应的源码如下:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = this.getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
// 如果需要代理,返回一个代理对象,不需要代理,直接返回当前传入的这个bean对象
return this.wrapIfNecessary(bean, beanName, cacheKey);
}
现在我们知道了开启AOP后何时返回一个代理对象了。下面我们回到问题本身,为什么非得需要三级缓存而不是二级缓存?首先我们先明确两个地方:
- 最直观的,
addSingletonFactory()方法在填充属性方法populateBean()和初始化方法initializeBean()之前。 - 如果创建的 Bean 是有代理的,那么注入的就应该是代理 Bean。通常情况下(没有循环依赖的情况下),Spring 都会在完成填充属性,并且执行完初始化方法之后再为其创建AOP代理。
1.没有三级缓存
B对象中有A对象的属性构成了循环依赖。但是我们要清楚Spring是不知道的,因为它需要到填充属性方法populateBean()处才能知道是否有循环依赖,为了保证B属性注入的是A对象的代理对象 ,Spring会在A对象初始化(甚至注入属性)之前就为其创建代理对象。也就是说在没有三级缓存的情况下,为了保险,就算没有循环依赖Spring都会在初始化之前为每个对象创建代理对象:

2.有三级缓存
显然在初始化之前就给对象创建代理对象是不符合Spring的设计原则的。因此就来了三级缓存,当执行到填充属性方法populateBean()处时:
- 如果没有循环依赖,那么创建B对象的过程中不会调用
getEarlyBeanReference()方法,依然按部就班在A和B初始化后再创建代理对象; - 如果有循环依赖,那么在B需要注入A对象属性的时候调用
getEarlyBeanReference()方法创建A的代理对象 。

通过上面的解析,我们可以知道 Spring 需要三级缓存的目的是为了延迟代理对象的创建,使 Bean 的创建符合 Spring 的设计原则。
关于第二大点-三级缓存的作用资料来自于:面试必杀技,讲一讲Spring中的循环依赖。
第三章 依赖注入原理
通过依赖注入来自动解决类对象之间的引用关系,即由Spring来创建bean对象,并且在Spring的IOC容器内部自动查找或者创建该bean对象所依赖的其他bean对象,从而保证整个bean对象的属性值的完整性。
在学习Spring的过程中我们已经接触到了以下几种依赖注入的方式:
-
Set函数的依赖注入,可以注入基本类型和其他Bean对象。可以通过配置
autowire指明ByName或者ByType。如:<bean id="userServiceImpl" class="cn.com.bochy.service.impl.UserServiceImpl" autowire="byName/byType"> -
构造函数的依赖注入,可以注入基本类型和其他Bean对象
-
利用@Autowired进行依赖注入,可以注入其他Bean对象
而利用@Autowired进行依赖注入又称自动装配,它有6种模式:
- no:默认的设置,表示不启用自动装配。需要显式装配 Bean。
- byName:按名称自动装配。
- byType:按类型自动装配。
- constructor:与 byType 模式相似,不同之处在与它应用于构造器参数(依赖项),如果在容器中没有找到与构造器参数类型一致的Bean,那么将抛出异常。
- autodetect:通过 Bean 类的自省机制(introspection)来决定是使用 constructor模式还是
byType模式进行自动装配。 - default:设置上级标签的 default-autowire属性定义装配模式。
在进入学习之前我们要明确一件事情,我们常用的ApplicationContext容器有个显著的特点就是:当容器初始化时就会初始化所有非懒加载的Bean对象。IOC容器初始化最重要的方法就是refresh()方法,该方法内部又会调用finishBeanFactoryInitialization()方法,该方法就是起到了实例化所有非懒加载的单例Bean对象的作用:
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory{
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// 此处省略多行与本次无关代码
// Instantiate all remaining (non-lazy-init) singletons.
beanFactory.preInstantiateSingletons();
}
这个方法就是一个傀儡方法,真正起作用的是preInstantiateSingletons()方法,代码解释来自于Spring 源码分析之 bean 依赖注入原理(注入属性):
public void preInstantiateSingletons() throws BeansException {
// 所有beanDefinition集合
List<String> beanNames = new ArrayList<String>(this.beanDefinitionNames);
// 触发所有非懒加载单例bean的初始化
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 判断是否是懒加载单例bean,如果是单例的并且不是懒加载的则在Spring 容器
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判断是否是FactoryBean
if (isFactoryBean(beanName)) {
// 对FactoryBean的处理
}else {
// 如果是普通bean则进行初始化依赖注入,此 getBean(beanName)接下来触发的逻辑跟
// context.getBean("beanName") 所触发的逻辑是一样的
getBean(beanName);
}
}
}
}
又看到了熟悉的getBean()方法,它的逻辑与context.getBean()方法一样的。该方法在循环依赖中我们已经初步的介绍了,也知道了属性注入最重要的方法就是:
populateBean(beanName, mbd, instanceWrapper);
该方法中出现了两个重要方法autowireByName()和autowireByType(),这两个方法分别代表按照名称注入和按照类型注入。
下面我们分代码块进行分析,第一个代码块比较简单,就是查看是否有属性,没有属性就直接return:
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
//没有可填充的属性就直接return
if (bw == null) {
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
//省略代码
}
第二个代码块是判断是否自定义了InstantiationAwareBeanPostProcessor接口的实现类,给该实现类一次机会在注入属性前来改变Bean对象。首先它会遍历所有实现了BeanPostProcessor接口的实现类,再判断是否是InstantiationAwareBeanPostProcessor接口的实现类,然后调用对应的postProcessAfterInstantiation()方法,如果该方法返回false直接return结束。
这段代码也解释了:为什么在InstantiationAwareBeanPostProcessor接口中postProcessAfterInstantiation()方法返回false后,postProcessPropertyValues()方法不会执行。
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
//省略代码
//是否自定义了InstantiationAwareBeanPostProcessor接口的实现类
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//遍历所有BeanPostProcessor接口实现类
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
}
}
//省略代码
第三个代码是与自动装配有关。处理autowire的注入,这里的autowire指的是在配置文件中通过autowire="byName"或者autowire="byType"等属性配置的bean。通过autowire的值来判断调用autowireByName()还是autowireByType()方法。
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
//省略第二个代码块
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// 按照名称注入
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// 按照类型注入
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
}
//省略代码
第四个代码块很重要,这里也是InstantiationAwareBeanPostProcessor的生命周期回调,特别是ibp.postProcessPropertyValues()方法,这个方法涉及到了@Autowired注解是如何注入属性的 。此方法会在@Autowired注解实现原理章节中单独分析。
而applyPropertyValues()方法是用来处理xml配置文件中Property属性注入,我们需要单独分析。
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
//省略代码
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
// 这里会处理对注解形式的注入 重点!!!!
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
//省略代码
if (pvs != null) {
//处理Property属性注入,也是真正注入属性的地方
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
下面我们进入applyPropertyValues(beanName, mbd, bw, pvs)方法进行分析,该方法是真正注入属性的地方,beanName代表Bean对象的名字,mbd为合并的 BeanDefinition,bw为包装目标对象的BeanWrapper,pvs为新的属性值。
该方法内部一共做了三件事情:
- 判断是否已转换。若已经转换了就直接返回;
- 利用
resolveValueIfNecessary()方法进行类型转换。由于我们在xml文件中获取的值都是String类型的值,需要将其转换为Bean对象的真正属性。在该方法内部有着大量的if-else判断,对于属性的类型进行判断,然后将值转换为该属性类型; - 利用
setPropertyValues()方法将转换好的值注入进Bean的属性。原理就是利用反射调用set方法对属性进行赋值。
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
//如果新的属性值为空直接return
if (pvs.isEmpty()) {
return;
}
//省略代码
// 判断是否已转换,已经转换了则return
if (mpvs.isConverted()) {
// Shortcut: use the pre-converted values as-is.
try {
bw.setPropertyValues(mpvs);
return;
}
}
original = mpvs.getPropertyValueList();
}
else {
original = Arrays.asList(pvs.getPropertyValues());
}
//创建用于解析BeanDefinition的解析器
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
// Create a deep copy, resolving any references for values.
List<PropertyValue> deepCopy = new ArrayList<>(original.size());
boolean resolveNecessary = false;
for (PropertyValue pv : original) {
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
// 属性名 如(name,orderService)
String propertyName = pv.getName();
// 未转换前的值,
Object originalValue = pv.getValue();
// 转换后的值,进行转换处理
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
//省略代码
// 转换完成
if (mpvs != null && !resolveNecessary) {
mpvs.setConverted();
}
// 这里就是进行属性注入的地方。
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
参考资料:Spring 源码分析之 bean 依赖注入原理(注入属性)。
第四章 Srping的生命周期
Spring 容器可以管理 singleton作用域 Bean的生命周期,在此作用域下,Spring能够精确地知道该Bean 何时被创建,何时初始化完成,以及何时被销毁。
而对于prototype作用域的Bean,Spring只负责创建,当容器创建了Bean的实例后,Bean的实例就交给客户端代码管理,Spring 容器将不再跟踪其生命周期。每次客户端请求prototype作用域的Bean时,Spring容器都会创建一个新的实例,并且不会管那些被配置成prototype作用域的Bean的生命周期。
了解Spring生命周期的意义就在于,可以利用Bean在其存活期间的指定时刻完成一些相关操作。这种时刻可能有很多,但一般情况下,会在Bean被初始化后和被销毁前执行一些相关操作。Spring 容器中 Bean 的生命周期流程 下图所示:
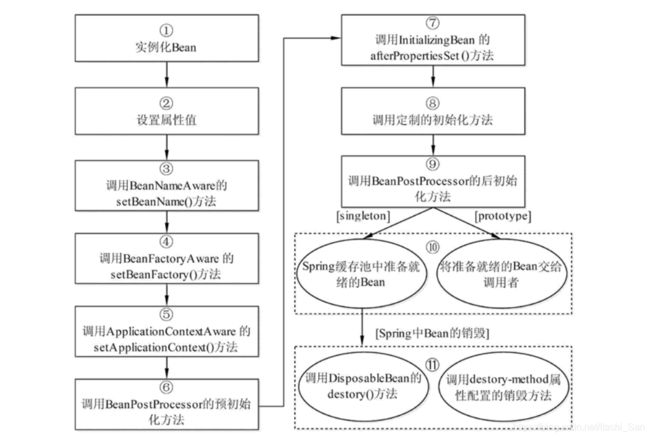
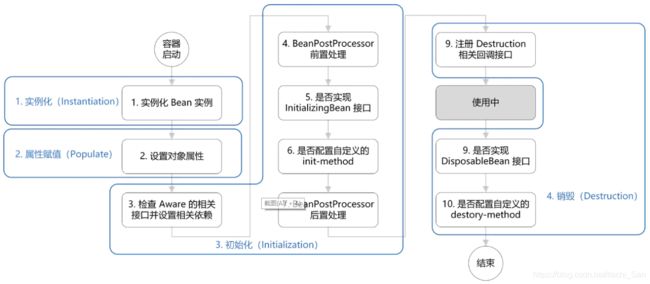
下图是 Spring 的生命周期,它是包括了Bean的生命周期,图片来自:Spring Bean的生命周期分析。

在进行学习之前,我们先建一个Demo,一个Teacher类:
public class Teacher {
private String tname;
private int tage;
private String tsex;
private Student tStudent;
public Teacher(){
System.out.println("teacher类--空构造方法");
}
//省略set、get、toString方法
}
Student类:
public class Student {
private String sname;
private int sage;
//省略set、get、toString方法
}
对应的xml文件配置类:
<bean id="teacher" class="com.itachi.Dao.Teacher">
<property name="tage" value="16">property>
<property name="tname" value="李大嘴 ">property>
<property name="tsex" value="男">property>
<property name="tStudent" ref="student">property>
bean>
<bean id="student" class="com.itachi.Dao.Student">
<property name="sname" value="白展堂">property>
<property name="sage" value="16">property>
bean>
一 BeanFactoryPostProcessor接口
BeanFactoryPostProcessor:在Bean Factory容器初始化完成之后,该接口可以在容器实例化任何bean之前读取bean的定义,并且修改、覆盖或者添加Bean属性。该接口只有一个postProcessBeanFactory方法,
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}
该方法中只有一个ConfigurableListableBeanFactory接口类型的参数,该接口提供Bean definition的解析,注册功能和对单例预加载(解决循环依赖问题):
package org.springframework.beans.factory.config;
public interface ConfigurableListableBeanFactory
extends ListableBeanFactory, AutowireCapableBeanFactory, ConfigurableBeanFactory {
//忽略自动装配的依赖类型
void ignoreDependencyType(Class<?> type);
//忽略自动装配的接口
//这个通常被使用由application contexts去注册依赖,可以以多种方式实现。
//例如BeanFactory通过BeanFactoryAware,ApplicationContext 通过ApplicationContextAware。
//默认情况下,仅BeanFactoryAware接口是被忽略,需要忽略其他接口,调用此方法。
void ignoreDependencyInterface(Class<?> ifc);
//注册一个可分解的依赖
void registerResolvableDependency(Class<?> dependencyType, @Nullable Object autowiredValue);
//确认这个被指定的bean是否是一个autowire候选,将被注入到其他声明匹配类型的依赖的bean中。
boolean isAutowireCandidate(String beanName, DependencyDescriptor descriptor)
throws NoSuchBeanDefinitionException;
//根据指定的bean name返回被注册的bean定义,允许访问其属性值和构造函数参数值(可以在bean工厂后期处理期间被修改)。
//这个被返回的bean definition对象不应该是副本而是原始在工厂被注册的。这意味着如果需要它可以被转换为更具体的实现类型。
BeanDefinition getBeanDefinition(String beanName) throws NoSuchBeanDefinitionException;
//返回由这个bean factory管理的所有bean name统一视图。
Iterator<String> getBeanNamesIterator();
void clearMetadataCache();
//冻结全部bean定义。标明注册的bean定义不在修改或后置处理
void freezeConfiguration();
//返回该工厂的bean definnitions是否被冻结。
boolean isConfigurationFrozen();
//确保所有非懒加载的单例bean被实例化,包括factoryBeans。
//用于解决循环依赖问题
void preInstantiateSingletons() throws BeansException;
}
其中getBeanDefinition方法是我们常用的一个,通过返回的BeanDefinition对象来获取属性并进行修改,下面我们来测试一下,首先先创建自定义BeanFactoryPostProcessor类:
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
public MyBeanFactoryPostProcessor(){
super();
System.out.println("BeanFactoryPostProcessor实现类--构造方法");
}
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
//获取BeanDefinition对象
BeanDefinition beanDefinition=beanFactory.getBeanDefinition("teacher");
//对属性值进行更改
beanDefinition.getPropertyValues().add("tname", "BeanFactoryPostProcessor-李大嘴");
}
}
内容比较简单:就是通过获取到的BeanDefinition对象来改变配置文件中Bean对象的属性值!我们将teacher类中的tname属性值改为了" BeanFactoryPostProcessor-李大嘴 “(xml文件中配置的是” 李大嘴 ")。
此处涉及到的beanDefinition的方法不做探讨,以后深入研究。创建该类后,还需要配置到xml文件中:
<bean id="beanFactoryPostProcessor" class="com.itachi.config.MyBeanFactoryPostProcessor">
bean>
下面我们来进行测试:
@Test
public void HAHA(){
ApplicationContext context =new ClassPathXmlApplicationContext("Singleton.xml");
Teacher teacher= (Teacher) context.getBean("teacher");
System.out.println(teacher);
}
测试结果:
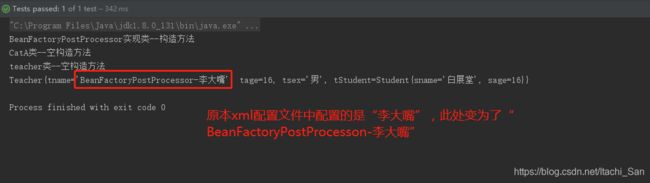
除此之外我们还发现:
- 由于xml文件中我们还配置了其他类(也就是图中的CatA),在容器启动后,虽然没有主动获取CatA类对象,但是依旧发现它构造完毕了(因为空构造方法启动了)。这就验证了前面我们说的:
ApplicationContext接口在启动的时候就把所有的Bean全部实例化了。 BeanFactoryPostProcessor接口实现类构造时机在Bean对象之前!
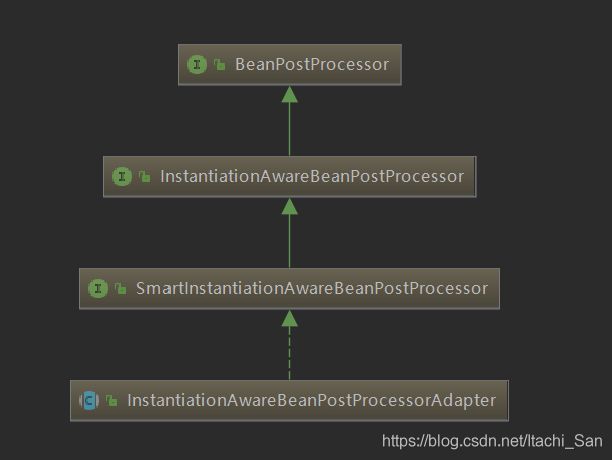
二 InstantiationAwareBeanPostProcessor接口
此处我们跳过了BeanPostProcessor接口和InstantiationAwareBeanPostProcessorAdapter类。其实这三个东西是继承实现关系:
对于该接口的官方介绍为:
它是BeanPostProcessor的子接口,它可以作用于Bean对象实例化前后,通常用于替换bean默认创建方式。注意:此接口是专用接口,主要供框架内部使用,尽可能使用它的实现类InstantiationAwareBeanPostProcessorAdapter,或者实现BeanPostProcessor接口,以免对该接口进行扩展。
此处特别强调实例化的概念,所谓实例化是指:调用Bean的构造函数,将生成的单例Bean放入单例池中,但是此时的Bean还没有填充属性! 在我们熟悉的doCreateBean()中,实例化的代码在此处:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
//省略代码
//实例化。内部会对Bean对象的构造器方法进行分析
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//省略代码
}
JDK8之后由于default关键字,InstantiationAwareBeanPostProcessor接口不再需要实现BeanPostProcessor接口的两个方法了。它内部提供了4个方法(最后一个方法不去探究,因为我不会!)该类位于org.springframework.beans.factory.config包下。
package org.springframework.beans.factory.config;
public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor {
//自身方法,是最先执行的方法,它在目标对象实例化之前调用。
default Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
return null;
}
//在目标对象实例化之后调用,这个时候对象已经被实例化,但是该实例的属性还未被设置,都是null。
//因为它的返回值是决定要不要调用postProcessProperties方法的其中一个因素
//如果该方法返回false,并且不需要check,那么postProcessProperties就会被忽略不执行,并且Bean对象不会填充属性!
//默认返回true,postProcessPropertyValues就会被执行
default boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
return true;
}
//对属性值进行修改,如果postProcessAfterInstantiation方法返回false,该方法可能不会被调用。
//可以在该方法内对属性值进行修改
default PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName)
throws BeansException {
return null;
}
}
下面我们来写个简答的例子来验证InstantiationAwareBeanPostProcessor接口方法的执行顺序。但是采用的是继承InstantiationAwareBeanPostProcessorAdapter的方式来验证。在验证之前给Student类加了一个空构造函数:
public Student(){
System.out.println("Student类--空构造方法");
}
然后是自定义的继承InstantiationAwareBeanPostProcessorAdapter的子类:
public class MyIABeanPostProcessor extends InstantiationAwareBeanPostProcessorAdapter{
public MyIABeanPostProcessor(){
super();
System.out.println("MyIABeanPostProcessor类构造器!!");
}
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
System.out
.println("MyIABeanPostProcessor调用postProcessBeforeInstantiation方法-构造方法之前执行");
return super.postProcessBeforeInstantiation(beanClass, beanName);
}
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
System.out
.println("MyIABeanPostProcessor调用postProcessAfterInitialization方法-构造方法之后执行,若返回false,Bean对象不会填充属性");
return true;
}
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException {
System.out
.println("MyIABeanPostProcessor调用postProcessPropertyValues方法");
return super.postProcessProperties(pvs, bean, beanName);
}
}
配置在xml文件中:
<bean class="com.itachi.config.MyIABeanPostProcessor">bean>
测试结果如下,由于Teacher类中含有Student类的属性,所以执行了两次:
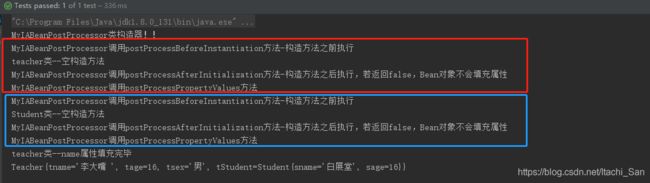
1. postProcessBeforeInstantiation
该方法在目标对象实例化之前调用。该方法有以下特性:
- 由于方法的返回值类型是Object,我们可以返回任何类型的值。
- 这个时候目标对象还未实例化,所以这个返回值可以用来代替原本该生成的目标对象的实例(比如代理对象)。
- 若该方法的返回值代替原本生成的目标对象,后续只有
postProcessAfterInitialization方法会调用,其它方法不再调用;否则按照正常的流程走。
以下例子为采用Cglib的代理模式来生成关于teahcer类的代理对象,用来替换原本对象。查看替换后的方法执行情况。
需要定义一个Enhancer类的局部变量,用它来生成代理对象;通过它的setSuperclass()方法来指定teahcer类为父类,因为Cglib是基于子类的。最后使用它的setCallback()实现代理逻辑:
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("MyIABeanPostProcessor调用postProcessBeforeInstantiation方法-构造方法之前执行");
if(beanClass== Teacher.class) {
//创建Enhancer类局部变量
Enhancer enhancer = new Enhancer();
//指定Teacher类为父类
enhancer.setSuperclass(beanClass);
//代理逻辑
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object obj, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
//无特殊逻辑
Object object = methodProxy.invokeSuper(obj, objects);
return object;
}
});
//生成Teacher类的代理对象
Teacher tByClib=(Teacher)enhancer.create();
//打印一下代理对象
System.out.println(tByClib.getClass());
return tByClib;
}
return null;
}
测试结果如下:
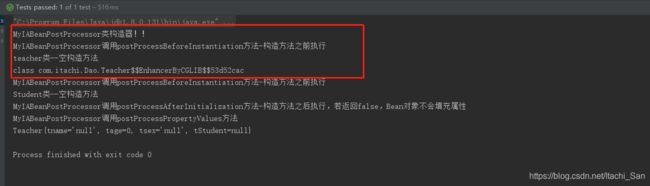
可以看见当返回了代理对象后,跳过了postProcessAfterInstantiation()方法和postProcessProperties方法(自定义初始化方法也会跳过)。
为什么会跳过?在之前学习循环依赖的时候说过createBean(beanName, mbd, args)方法中调用了一个重要方法,它是实现AOP功能的关键:
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args){
//省略代码
try {
//根据bean判断如果不为空null就直接返回了,而不执行doCreateBean()方法了
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
//省略代码
}
进入resolveBeforeInstantiation(beanName, mbdToUse)方法查看:
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// 判断是否有注册过InstantiationAwareBeanPostProcessor类型的bean
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class<?> targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
// 直接执行BeanPostProcessor接口的postProcessAfterInitialization方法
//该方法之前的方法不再执行
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}
applyBeanPostProcessorsAfterInitialization方法的作用是获取到所有实现了BeanPostProcessor接口的实现类,并调用对应的postProcessAfterInitialization方法,如果该方法返回不为null,则这个bean就直接返回给ioc容器。
2. postProcessProperties
该方法允许:在Bean对象属性注入之前对已配置好的属性值进行修改。该方法能执行的前提是:postProcessAfterInstantiation()方法返回true。
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException {
System.out.println("MyIABeanPostProcessor调用postProcessPropertyValues方法");
if(bean instanceof Teacher){
//获取name属性
PropertyValue value = pvs.getPropertyValue("tname");
System.out.println("修改前的属性值为:"+value.getValue());
//对name属性的值进行修改
value.setConvertedValue("李大嘴-InstantiationAwareBeanPostProcessor");
}
return super.postProcessProperties(pvs, bean, beanName);
}
测试结果:
![]()
三 ApplicationContextAware接口
四 BeanPostProcessor接口
该接口我们也叫后置处理器,作用是在Bean对象在实例化和依赖注入完毕后,在显示调用初始化方法(init-method)的前后添加我们自己的逻辑:
public interface BeanPostProcessor {
//在Bean对象实例化和属性注入后,该方法执行
@Nullable
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
//在int-method方法执行后,该方法执行。
//int-method方法的执行时机在Bean对象实例化和属性注入之后
@Nullable
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
前文学习的InstantiationAwareBeanPostProcessor接口是它的子接口,只是两个接口内部方法的作用时机不一样。在测试之前,我们首先对实体Teacher类添加一个init-method初始化方法和destory销毁方法:
public void init(){
System.out.println("teacher类--init-method初始化方法");
}
public void destroy(){
System.out.println("teacher类--destroy销毁方法");
}
并且在xml文件中对这两个方法进行定义:
<bean id="teacher" class="com.itachi.Dao.Teacher" init-method="init" destroy-method="destroy">bean>
下面我们定义MyBeanPostProcessor类,验证方法的执行流程:
public class MyBeanPostProcessor implements BeanPostProcessor {
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("实例化》注入属性》postProcessBeforeInitialization"+"\t"+beanName);
return null;
}
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("init-Method》postProcessAfterInitialization"+"\t"+beanName);
return null;
}
}
测试结果如下,可以看到会先对Student属性进行赋值然后在给Teacher的其他属性赋值,方法执行流程也正确。
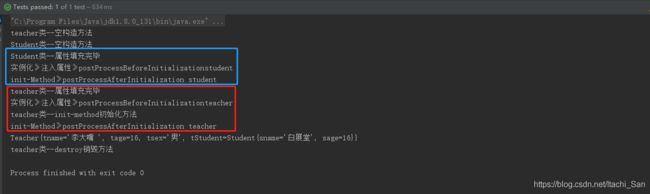
当然我们可以在postProcessBeforeInitialization方法中返回自定义或者代理对象,但是其实该接口一般用于自定义注解用,关于自定义注解,后续再学习!
当有多个BeanPostProcessor接口实现类时,默认情况下Spring容器会根据后置处理器的定义顺序来依次调用。
我们也可以让实现类再多实现一个Ordered接口,利用它的getOrder()方法来指定顺序,该方法返回一整数,默认值为 0,优先级最高,值越大优先级越低:
public class MyBeanPostProcessor implements BeanPostProcessor, Ordered {
//省略代码
public int getOrder() {
return 10;
}
}
关于BeanPostProcessor接口还有几个注意点:
- 若
BeanPostProcessor接口的实现类A中含有其他Bean对象属性,那么该Bean对象属性不会执行A的重写方法。 - BeanPostProcessor实现类以及依赖的Bean对象属性无法使用AOP
五 InitializingBean接口
InitializingBean接口为bean提供了属性初始化后的处理方法,只有afterPropertiesSet方法,凡是继承该接口的类,在bean的属性初始化后都会执行该方法。
public interface InitializingBean {
//该方法在设置属性后才执行
void afterPropertiesSet() throws Exception;
}
该接口比较简单,此处就不再演示,关于该接口的总结如下:
- Spring为bean提供了两种初始化bean的方式,实现InitializingBean接口,实现afterPropertiesSet方法,或者在配置文件中同过init-method指定,两种方式可以同时使用
- 实现InitializingBean接口是直接调用afterPropertiesSet方法,比通过反射调用init-method指定的方法效率相对来说要高点。但是init-method方式消除了对spring的依赖