Python————面向对象练习及python基础回顾
文章目录
-
-
-
- 面向对象练习
-
-
- question1. 队列数据结构的封装
- question2.最近请求次数(队列的应用)
-
- Python基础回顾
-
- 常见 python 面试题目整理
-
- 1. 列举 Python2 和 Python3 的区别?
- 2. 简述 Python 的深浅拷贝以及应用场景?
- 3. 能否解释一下 *args 和 **kwargs?
- 4. 简述 生成器、迭代器、可迭代对象 以及应用场景?
- 5. 请说明 yield 关键字的工作机制。
- 6. 请简单谈谈装饰器的作用和功能。
- 7. Python 中如何读取大数据的文件内容?
- 8. Python 中的模块和包是什么?
- 9. python 是如何进行内存管理的(python 是如何实现垃圾回收机制的)?
- 10. 谈谈你对面向对象的理解?
- 11. Python 面向对象中的继承有什么特点?
- 12. 面向对象中 super 的作用?
- 13. 面向对象深度优先和广度优先是什么, 并说明应用场景?
- 14. 请简述__init__和__len__这两个魔术方法的作用
-
-
面向对象练习
question1. 队列数据结构的封装
队列类。队列(queue)是具有先进先出(FIFO)特性的数据结构。一个队
列就像是一行队伍,数据从前端被移除,从后端被加入。这个类必须支持
下面几种方法:
并实现下面的功能: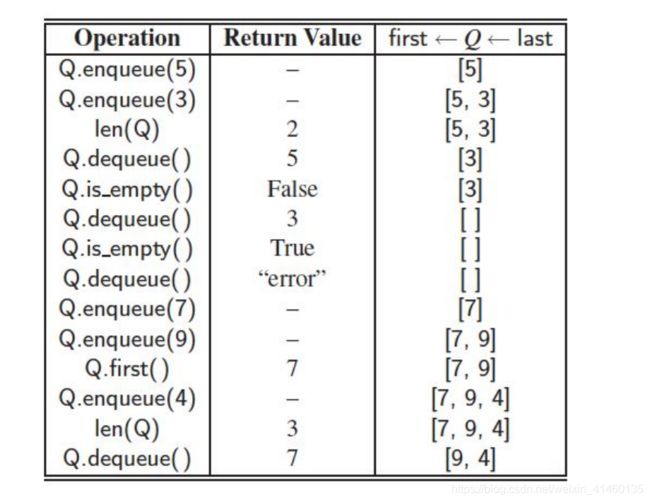
代码如下:
class Queue(object):
"""
根据列表的数据结构封装栈的数据结构
"""
# 构造方法
def __init__(self):
# 定义一个空队列, 用来存储队列的元素
self.__queue = []
# len(queueobj)自动会调用该方法
def __len__(self):
return len(self.__queue)
def push(self, item):
"""入队列"""
self.__queue.append(item)
print("元素[%s]加入队列成功" % (item))
def pop(self):
"""出队列, 判断队列是否为空"""
if not self.is_empty():
# 获取出栈的元素
item = self.__queue.pop(0)
print("元素[%s]弹出队列成功" % (item))
else:
raise Exception("队列为空")
def top(self):
"""获取队列顶元素"""
if not self.is_empty():
# 获取出栈的元素
item = self.__queue[0]
print("队列顶元素为: [%s] " % (item))
else:
raise Exception("队列为空")
def length(self):
"""获取栈的元素个数"""
return len(self.__queue)
def is_empty(self):
"""判断栈是否为空"""
return len(self.__queue) == 0
queue = Queue()
queue.push(5)
print(len(queue))
queue.push(3)
queue.pop()
print(queue.is_empty())
queue.pop()
print(queue.is_empty())
print(len(queue))
结果如下:

question2.最近请求次数(队列的应用)


代码如下:
#根据题意首先建立一个RecentCounter类来计算请求次数
class RecentCounter:
def __init__(self):
#结果返回ping数,故建立一个列表将ping值存储起来,便于计数
self.pings = list()
# 根据题意只有一个方法,建立一个函数ping
def ping(self,t):
#将ping存储
self.pings.append(t)
#如果列表中最小的ping值小于t-3000,弹出之。
while self.pings[0] < t - 3000:
self.pings.pop(0)
#返回列表长度,即ping数
return len(self.pings)
r = RecentCounter()
print(r.ping(1))
print(r.ping(100))
print(r.ping(3001))
print(r.ping(3002))
Python基础回顾
常见 python 面试题目整理
1. 列举 Python2 和 Python3 的区别?
-
1)默认编码:
python2–>ascii,python3–>utf-8 -
2)print的区别:
python2中print是一个语句,不论想输出什么,直接放到print关键字后面即可。python3里,print()是一个函数,
像其他函数一样,print()需要你将要输出的东西作为参数传给它。 -
3)input的区别:
python2有两个全局函数,用在命令行请求用户输入。第一个叫input(),它等待用户输入一个python表达式(然后返回结果)。
第二个叫做raw_input(),用户输入什么他就返回什么。python3 通过input替代了他们 -
4)字符串:
python2中有两种字符串类型:Unicode字符串和非Unicode字符串。
Python3中只有一种类型:Unicode字符串。 -
5)xrange()
python2里,有两种方法获得一定范围内的数字:range(),返回一个列表,还有xrange(),返回一个迭代器。
python3 里,range()返回迭代器,xrange()不再存在。 -
6)数值类型的区别
python3中不在有long,将其归为int类 -
7) 类的区别
在Python 2及以前的版本中,由任意内置类型派生出的类,都属于“新式类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,则称之为“经典类”。
2. 简述 Python 的深浅拷贝以及应用场景?
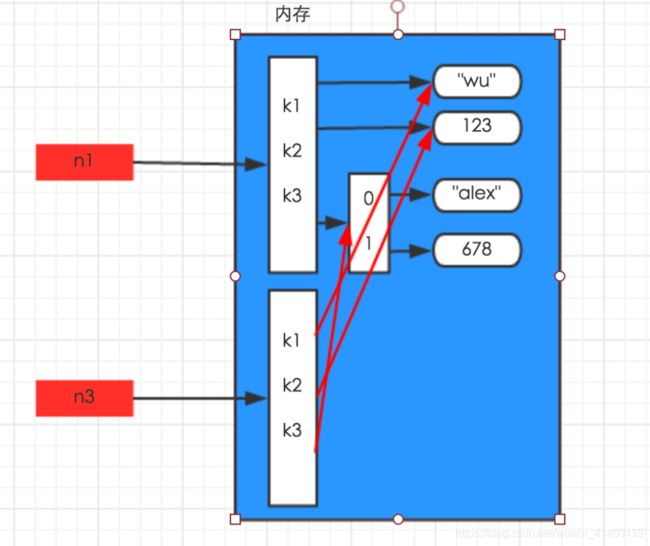
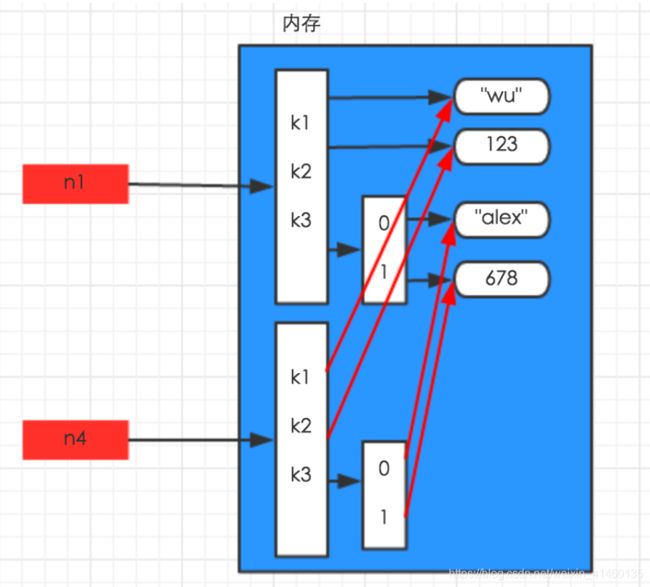
- 浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层。所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字,还有仅仅一层的字典、列表、元祖等.
- 但对于含有多层的字典、列表、元祖等,便有了很大区别。
- 浅拷贝:
深拷贝:
3. 能否解释一下 *args 和 **kwargs?
- 当我们不知道向函数传递多少参数时,比如我们向传递一个列表或元组,我们就使用*args
- 当我们不知道该传递多少关键字参数时,使用**kwargs来收集关键字参数
4. 简述 生成器、迭代器、可迭代对象 以及应用场景?

5. 请说明 yield 关键字的工作机制。
yield关键字的用法类似于return,但是区别在于yield关键使得函数返回一个generator对象。
6. 请简单谈谈装饰器的作用和功能。
装饰器本质上是一个函数,该函数用来处理其他函数,它可以让其他函数在不需要修改代码的
前提下增加额外的功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,
比如:插入日志、性能测试、事务处理、缓存、权限校验等应用场景。
7. Python 中如何读取大数据的文件内容?
python中对文件的读取有read(),readline(),readlines()三种方法,
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便。
8. Python 中的模块和包是什么?
python模块是:
自我包含并且有组织的代码片段为模块。
表现形式为:写的代码保存为文件。这个文件就是一个模块。sample.py 其中文件名smaple为模块名字。
python包是:
包是一个有层次的文件目录结构,它定义了由n个模块或n个子包组成的python应用程序执行环境。
通俗一点:包是一个包含__init__.py 文件的目录,该目录下一定得有这个__init__.py文件和其它模块或子包。
python库是参考其它编程语言的说法,就是指python中的完成一定功能的代码集合,供用户使用的代码组合。在python中是包和模块的形式。
9. python 是如何进行内存管理的(python 是如何实现垃圾回收机制的)?
Python 采用引用计数的方式来管理分配的内存。Python 的每个对象都有一个引用计数,这个引用计数表明了有多少对象在指向它。当这个引用计数为 0 时,释放该对象的内存。为了解决循环引用的问题,Python提供了“标记-清除”法,用于释放循环引用的对象。
10. 谈谈你对面向对象的理解?
在我理解,面向对象是向现实世界模型的自然延伸,这是一种“万物皆对象”的编程思想。在现实生活中的任何物体都可以归为一类事物,而每一个个体都是一类事物的实例。面向对象的编程是以对象为中心,以消息为驱动,所以程序=对象+消息。
11. Python 面向对象中的继承有什么特点?
1、在继承中基类的构造(init()方法)不会被自动调用,它需要在其派生类的构造中亲自专门调用。有别于C#
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量。区别于在类中调用普通函数时并不需要带上self参数
3、Python总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
12. 面向对象中 super 的作用?
super() 函数是用于调用父类(超类)的一个方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
13. 面向对象深度优先和广度优先是什么, 并说明应用场景?
最明显的区别在于继承搜索的顺序不同,即:
经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。
新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找。

14. 请简述__init__和__len__这两个魔术方法的作用
- 由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的__init__方法,在创建实例的时候,就把其他属性绑上去:
- 可以用len()函数返回对象实例的“长度”