机器学习之随机森林实践:手写字识别、天气最高温度预测
1、RandomForestClassifier基本参数说明
要使用RandomForestClassifier算法进行分类,我们需要先了解RandomForestClassifier算法的一些基本参数。
RandomForestClassifier(n_estimators=10,
criterion=’gini’,
max_depth=None,
bootstrap=True,
random_state=None,
min_samples_split=2)
n_estimators:
integer,optional(default = 10),森林里的树木数量 120,200,300,500,800,1200
criteria:
string,可选(default =“gini”)分割特征的测量方法
max_depth:
integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
max_features="auto”,每个决策树的最大特征数量
If “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features) (same as “auto”).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features.
bootstrap:
boolean,optional(default = True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
超参数:
n_estimator
max_depth
min_samples_split
min_samples_leaf
2、 随机森林预测tanic生存状况(简单示例代码)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# 1> 实例化一个估计器
estimator=RandomForestClassifier()
# 2> 网格搜索优化随机森林模型
param_dict={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=5)
# 3> 传入训练集,进行模型训练
estimator.fit(x_train,y_train)
# 4> 模型评估
# 方法1,比较真实值与预测值
y_predict=estimator.predict(x_test)
print("预测值为:\n",y_predict)
print("比较真实值与预测值结果为:\n",y_predict==y_test)
# 方法2,计算模型准确率
print("模型准确率为:\n",estimator.score(x_test,y_test))
print("在交叉验证中最的结果:\n",estimator.best_score_)
print("最好的参数模型:\n",estimator.best_estimator_)
print("每次交叉验证后的结果准确率为/n",estimator.cv_results_)
3、手写字识别
from sklearn.datasets import load_digits
digits = load_digits()
#显示前几个数字图像
fig = plt.figure(figsize=(6,6))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(64):
ax = fig.add_subplot(8,8,i+1, xticks=[], yticks=[])
ax.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest')
ax.text(0,7,str(digits.target[i]))
#用随机森林快速对数字进行分类
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
x_train, x_test, y_train, y_test = train_test_split(digits.data, digits.target, random_state=0)
model = RandomForestClassifier(n_estimators=1000)
model.fit(x_train, y_train)
ypre = model.predict(x_test)
#查看分类器的分类结果报告
from sklearn import metrics
print(metrics.classification_report(ypre, y_test))
#输出结果:
precision recall f1-score support
0 1.00 0.97 0.99 38
1 0.98 0.98 0.98 43
2 0.95 1.00 0.98 42
3 0.98 0.96 0.97 46
4 0.97 1.00 0.99 37
5 0.98 0.96 0.97 49
6 1.00 1.00 1.00 52
7 1.00 0.96 0.98 50
8 0.94 0.98 0.96 46
9 0.98 0.98 0.98 47
avg / total 0.98 0.98 0.98 450#画出混淆矩阵
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(y_test, ypre)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False)
plt.xlabel('true label')
plt.ylabel('predicted label')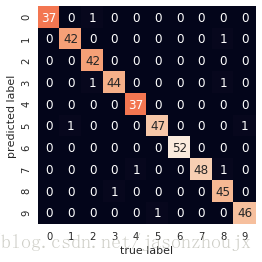
4、随机森林预测天气最高温度
4.1、载入数据
import pandas as pd
# 载入数据
features = pd.read_csv('data/temps.csv')
# 数据前五行
features.head(5)
# 数据特征
print('The shape of our features is:', features.shape)
features.describe()
4.2、数据预处理
# one-hot 编码
features = pd.get_dummies(features)
features.head(5)
# 标签与数据划分
import numpy as np
# 标签
labels = np.array(features['actual'])
# 数据
features= features.drop('actual', axis = 1)
# 转变成列表
feature_list = list(features.columns)
# 转变成np.array格式
features = np.array(features)
4.3、数据划分处理
# 训练集与测试集划分
from sklearn.model_selection import train_test_split
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size = 0.25,random_state = 42)4.4、建立模型
from sklearn.ensemble import RandomForestRegressor
# 模型建立
rf = RandomForestRegressor(n_estimators= 1000, random_state=42)
# 训练
rf.fit(train_features, train_labels)
4.5、天气预测
# 使用随机森林带的预测方法进行预测
predictions = rf.predict(test_features)
# 计算绝对误差
errors = abs(predictions - test_labels)
# 绝对误差,保留两位小数
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
# 计算 平均绝对百分误差mean absolute percentage error (MAPE)
mape = 100 * (errors / test_labels)
# 准确率,这里使用了平均绝对百分误差来计算准确率
accuracy = 100 - np.mean(mape)
print('Accuracy:', round(accuracy, 2), '%.')计算结果是:Accuracy: 93.99 %.
4.6、特征重要性
# 数字特征重要性
importances = list(rf.feature_importances_)
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# 排序
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)
[print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances];
结果:

从而可知最重要的特征是temp1,接下来我们根据此特征重新构建模型
4.7、使用最重要的特征构建模型
# 使用最重要的两个特征构建模型
rf_most_important = RandomForestRegressor(n_estimators= 1000, random_state=42)
# 获取这两个最重要的特征,划分数据集
important_indices = [feature_list.index('temp_1'), feature_list.index('average')]
train_important = train_features[:, important_indices]
test_important = test_features[:, important_indices]
# 训练
rf_most_important.fit(train_important, train_labels)
# 预测
predictions = rf_most_important.predict(test_important)
# 误差
errors = abs(predictions - test_labels)
print('Mean Absolute Error:', round(np.mean(errors), 2), 'degrees.')
mape = np.mean(100 * (errors / test_labels))
accuracy = 100 - mape
# 准确率
print('Accuracy:', round(accuracy, 2), '%.')
结果是:
Mean Absolute Error: 3.9 degrees.
Accuracy: 93.8 %.4.8、构建随机森林完整代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# 载入数据,one-hot化
original_features = pd.read_csv('data/temps.csv')
original_features = pd.get_dummies(original_features)
# 标签
original_labels = np.array(original_features['actual'])
# 去除标签值
original_features= original_features.drop('actual', axis = 1)
# 特征
original_feature_list = list(original_features.columns)
# 转变成numpy.array格式
original_features = np.array(original_features)
# 切分数据集
original_train_features, original_test_features, original_train_labels, original_test_labels = train_test_split(original_features, original_labels, test_size = 0.25, random_state = 42)
# 模型建立
rf = RandomForestRegressor(n_estimators= 1000, random_state=42)
# 模型训练
rf.fit(original_train_features, original_train_labels);
# 预测
predictions = rf.predict(original_test_features)
# 计算误差
errors = abs(predictions - original_test_labels)
# 计算mean absolute error (mae)
print('Average model error:', round(np.mean(errors), 2), 'degrees.')
# 计算mean absolute percentage error (MAPE)
mape = 100 * (errors / original_test_labels)
# 计算准确率
accuracy = 100 - np.mean(mape)
print('Accuracy:', round(accuracy, 2), '%.')