《Python核心编程(第3版)》学习笔记及书评
《Python核心编程(第3版)》学习笔记
文章目录
- 《Python核心编程(第3版)》学习笔记
-
- 写在前面
- 1. 正则表达式
-
- 1.1 常用语法
- 1.2 re模块
- 2. 网络编程
-
- 2.1 socket网络编程
- 2.2 SocketServer 模块
- 2.3 Twisted框架介绍
- 3. 因特网客户端编程
-
- 3.1 文件传输
- 3.2 网络新闻
- 3.3 电子邮件
- 3.4 实战
- 4. 多线程编程
-
- 4.1 线程和进程
- 4.2 thread
- 4.3 threading
- 4.4 单线程和多线程执行对比
- 4.5 多线程实践
- 4.6 Queue模块
- 4.7 线程的替代方案
- 5. GUI编程
-
- 5.1 概述
- 5.2 示例
- 5.3 偏函数
- 5.4 中级Tkinter
- 5.5 其他GUI简介
- 5.6 相关模块和其他GUI
- 6. 数据库编程
-
- 6.1 python的DB-API
- 6.2 ORM
- 6.3 非关系型数据库
- 7. Microsoft Office 编程
-
- 7.1 Excel
- 7.2 Word
- 7.3 PowerPoint
- 7.4 Outlook
- 8. 扩展Python
- 9. Web客户端和服务器
-
- 9.1 概述
- 9.2 Web客户端工具
- 9.3 Web客户端
- 10. Web编程:CGI和WSGI
-
- 10.1 CGI简介
- 10.2 WSGI简介
- 11. Web框架:Django
-
- 11.1 Django简介
- 11.2 单元测试
- 12. 云计算:Google App Engine
- 写在最后
- 附录
-
- A Python关键字
- B Python标准操作符和函数
- C 数值类型操作符和函数
- D 序列类型操作符和函数
- E 字符串格式化操作符转换符号
- F 字符串格式化操作符指令
- G 字符串类型内置方法
- H 列表类型内置方法
- I 字典类型内置方法
- J 集合类型操作符和内置函数
- K 文件对象方法和数据属性
- L Python异常
- M 类的特殊方法
- N Python操作符汇总
写在前面

- 读后感:这本书与python的优雅完全的背道而驰
-
真本书写的真的八行,外国人写的书,好的是真的好,烂的是真的烂,这本书不知道为什么吹的人那么多,烂的扣jio,有的例子真的不想抄一遍了,神神叨叨的,跑也跑不通,让自己填自己连接,我特么我知道怎么填,读你干嘛啊。还有啊,翻译得真跟shi一样,直接谷歌机翻也比这翻译的好吧。
-
最严重的问题,也就是上面说的,很多例子对应的链接已经不行了,连也连不上,特别是在第二章、第三章学网络的时候,特别明显,就是学了个寂寞。
-
怎么说呢,这本书无论是对初学者还是对已经有了一定基础的python学习者,都十分的不友好,我的评价是:生硬且古板。很多已经淘汰的技术,着墨太多,并且案例无法复现。很有很多错误的地方,比如英文打错了。。。我人都傻了,点我查看打错的地方
-
数据库编程这一张是真的学的头痛,代码我一行都没敲,是真的跟不下去。就看了下逻辑和包,用的时候再去参考API吧,特别是ORM
-
扩展Python这一章,本来我是真的很感兴趣的,可能是我水平不够叭,每个字我都认识,连在一起不知道在说什么,真的很痛苦,也没学到东西。(同样这章的吐槽,可以直达,点我)
-
像以下这样的代码很多,就突然出现一个搞不清楚是什么东西的变量,我整个人直接傻掉,立刻不知所云
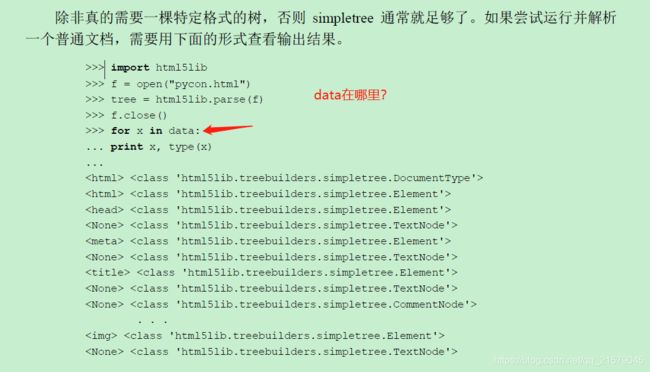
-
讲道理,这本书最大的作用,就是见证历史,看看远古操作是什么样的,我们现在用python编程门槛这么低,都是站在巨人的肩膀上。
-
很累,真心累,学了个寂寞,重在参与吧
-
1. 正则表达式
1.1 常用语法
-
正则表达式符号

-
特殊字符
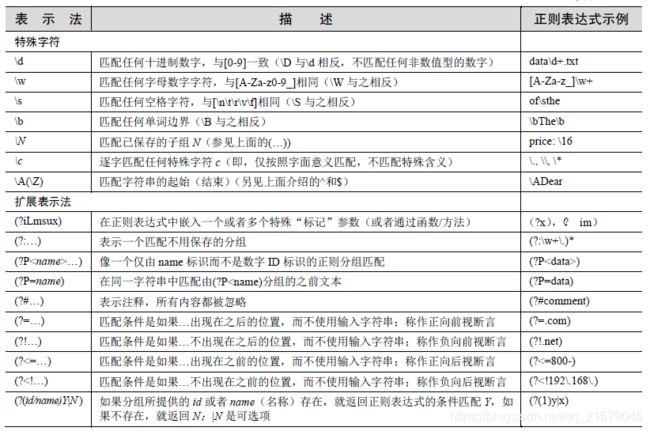
-
择一匹配(或):
| -
匹配任意单个字符:
.,除了\n意外的任何字符怎样匹配
.呢?:\. -
匹配开头位置:
^或者\A -
匹配结尾位置:
$或者\Z
-
匹配字符边界:
\b和\B-
\b用于匹配一个单词的边界,开始 -
\B用于匹配不是单词边界,即不开始
-
-
字符集的方法只适用于单字符的情况:
[abrd],否则应该使用:ab|rd -
限定范围:
a-zA-Z0-9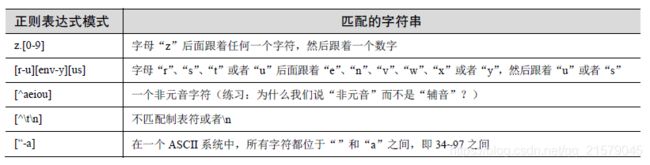
-
使用闭包操作符实现存在性和频数的匹配

-
表示字符集的特殊字符
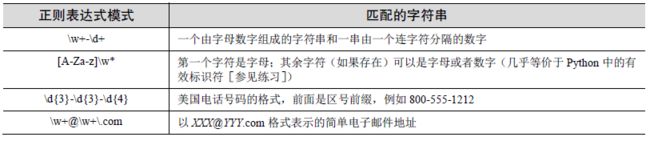
-
使用圆括号指定分组:提取任何已经成功匹配的特定字符串或者子字符串。

-
扩展表示语法
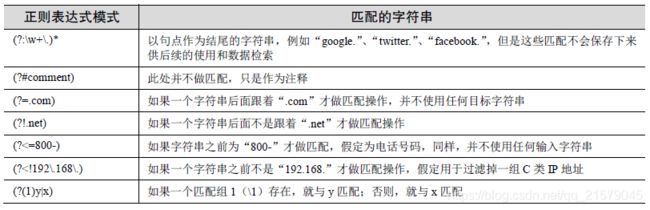
1.2 re模块
-
常见的正则表达式属性
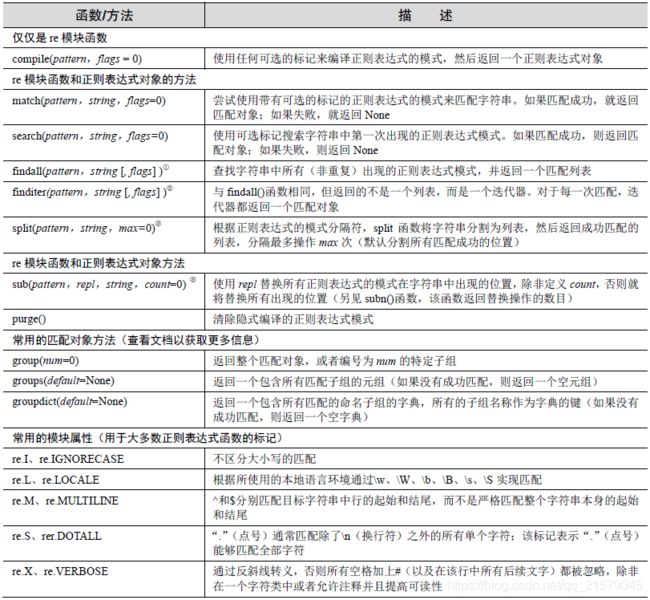
-
可选标记:
re.IGNORECASE:忽略大小写re.MULTILINE:多行字符串匹配re.DOTALL:.也包含换行符re.VERBOSE:在正则表达式字符串中允许空白字符和注释,让它更可读。
-
match():从字符串的起始部分对模式进行匹配;如匹配成功,返回一个匹配对象;若匹配失败,则返回None。使用匹配对象的group()显示成功的匹配。
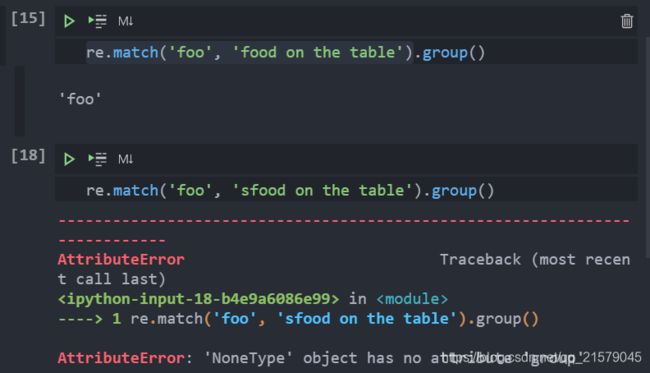
-
search():search()的工作方式与match()完全一致,不同之处在于search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回None。

-
匹配多个字符串

-
匹配任何单个字符
.不能匹配一个换行符\n或者非字符,即空字符串。
-
搜索真正的小数点
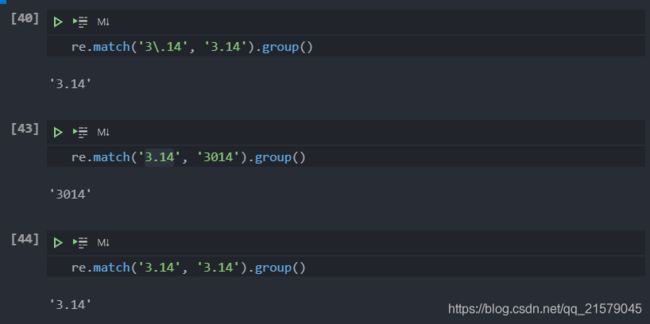
-
创建字符集
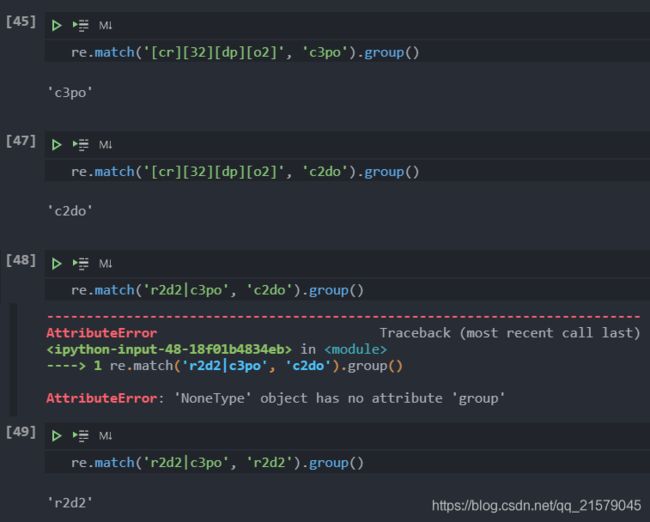
-
用
()将所选的模式框选出来,然后在后面加上?表示出现0次或1次 -
重复、特殊字符以及分组
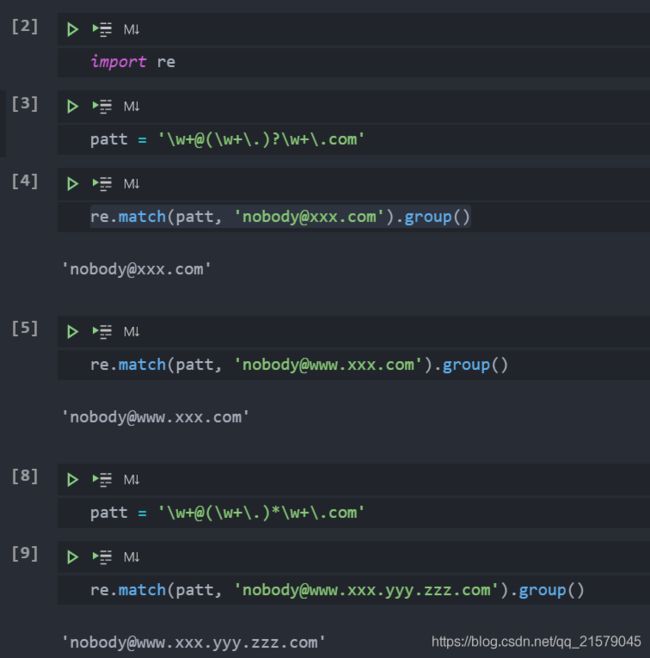
-
添加一个子组来构造一个新的正则表达式

-
提取上述正则表达式的字母和数字部分
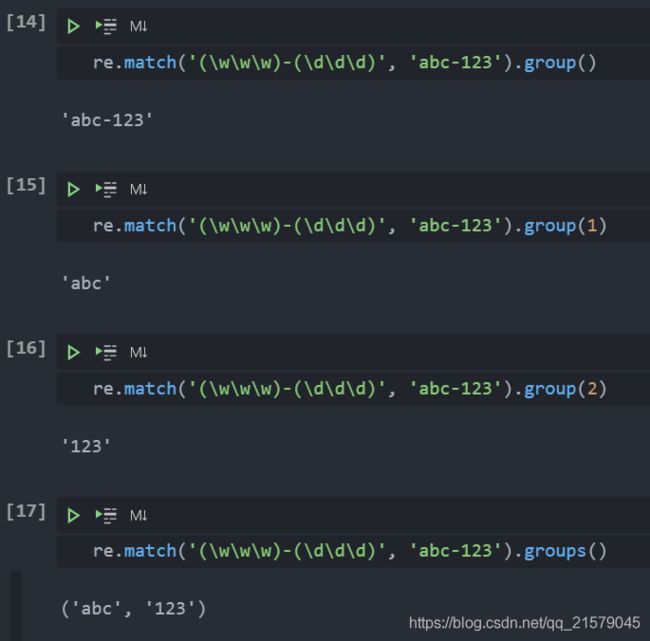
-
group()通常用于以普通方式显示所有的匹配部分,但也能用于获
取各个匹配的子组。可以使用groups()方法来获取一个包含所有匹配子字符串的元组。-
表达式中没有括号

-
表达式中有括号

-
表达式中多个括号
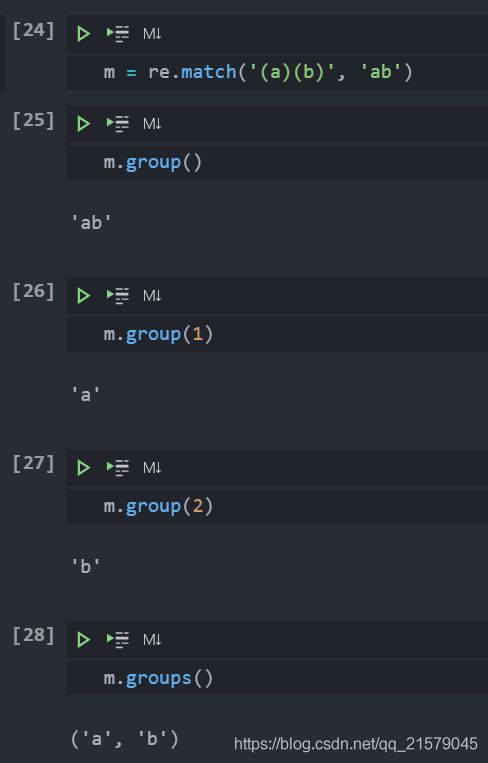
-
表达式中嵌套括号

-
-
匹配字符串的起始和结尾以及单词边界
-
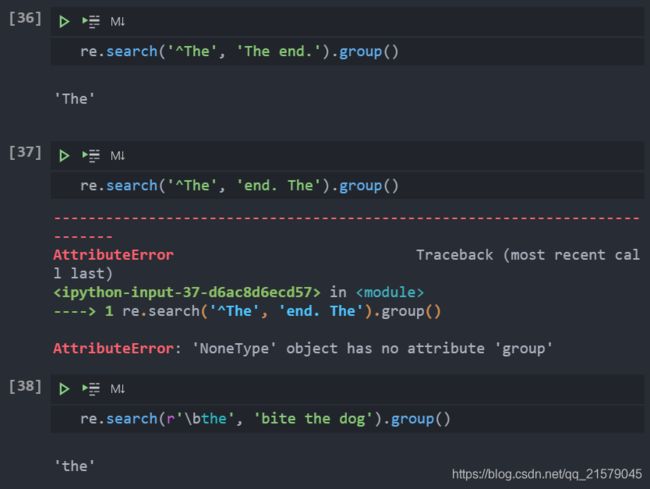
匹配+不作为起始+在边界
单词边界是单词和空格之间的位置。这里检测到the是有边界的,然后从the前面的边界开始找the
-
有边界+没有边界
这里的
\B找没有边界的the,并匹配边界后面的the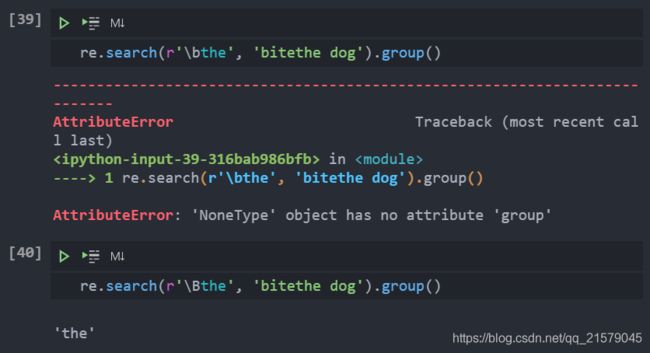
-
-
在正则表达式字符串前记得加原始字符串:
r -
findall():
-
findall()查询字符串中某个正则表达式模式全部的非重复出现情况。这与search()在执行字符串搜索时类似,但与match()和search()的不同之处在于,findall()总是返回一个列表。如果findall()没有找到匹配的部分,就返回一个空列表,但如果匹配成功,列表将包含所有成功的匹配部分(从左向右按出现顺序排列)。
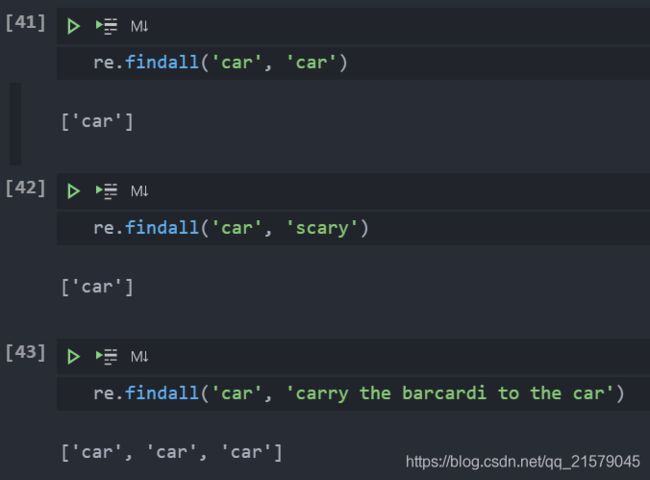
-
-
finditer():
-
finditer()函数是在Python 2.2 版本中添加回来的,这是一个与findall()函数类似但是更节省内存的变体。两者之间以及和其他变体函数之间的差异(很明显不同于返回的是一个迭代器还是列表)在于,和返回的匹配字符串相比,finditer()在匹配对象中迭代。

-
这里需要注意的是:如果
next()报错,则需要改为__next__()
-
-
在单个字符串中执行单个分组的多重匹配

-
用finditer()完成

-
使用
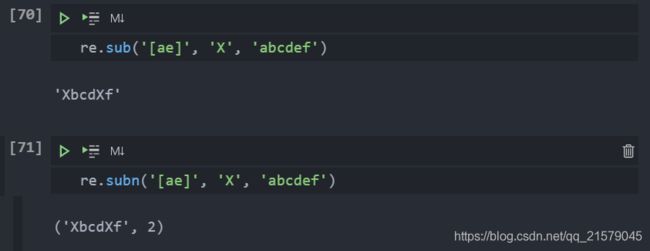
sub()和subn()搜索与替换-
有两个函数/方法用于实现搜索和替换功能:
sub()和subn()。两者几乎一样,都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换。用来替换的部分通常是一个字符串,但它也可能是一个函数,该函数返回一个用来替换的字符串。subn()和sub()一样,但subn()还返回一个表示替换的总数,替换后的字符串和表示替换总数的数字一起作为一个拥有两个元素的元组返回。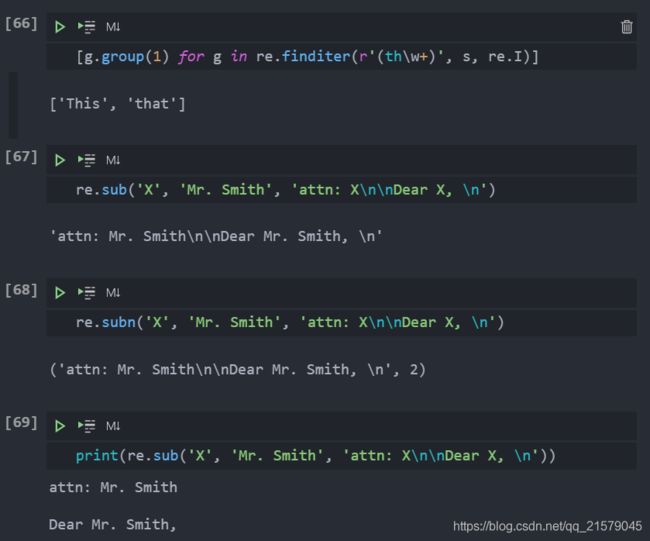
-
多组匹配
-
-
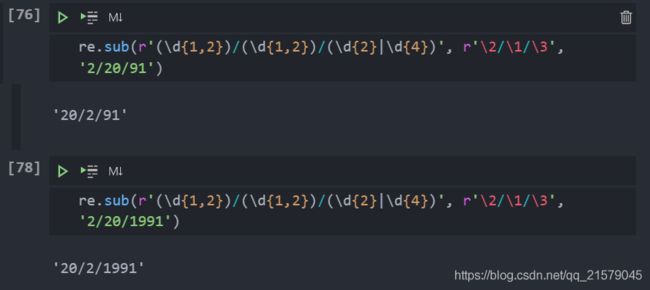
根据分组结果,重新组合成新的结果
使用匹配对象的group()方法除了能够取出匹配分组编号外,还可以使用\N,其中N 是在替换字符串中使用的分组编号。
-
在限定模式上使用
split()分隔字符串-
如果给定分隔符不是使用特殊符号来匹配多重模式的正则表达式,那么
re.split()与str.split()的工作方式相同
-
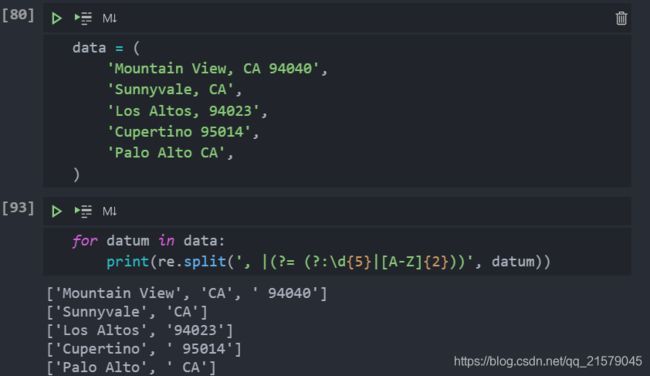
复杂分割
如果空格紧跟在五个数字(ZIP 编码)或者两个大写字母(美国联邦州缩写)之后,就用split 语句分割该空格。这就允许我们在城市名中放置空格。
-
-
扩展符号
-
re.I和re.M实现多行混合
-
re.S/re.DOTALL获取\n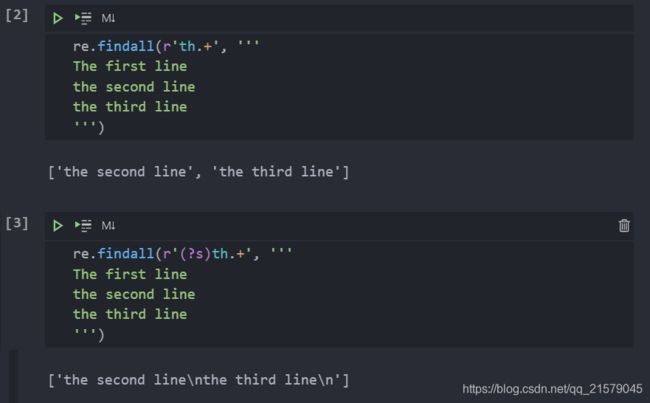
-
re.X/re.VERBOSE:在正则表达式字符串中允许空白字符和注释,让它更可读。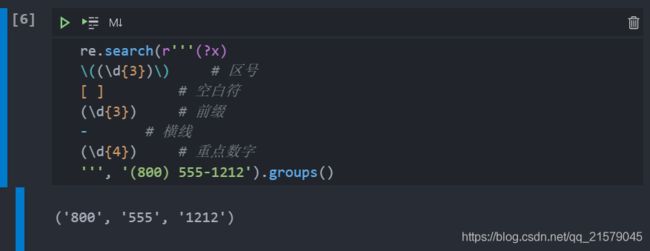
-
?::意思是不捕获分组,(?:X)这样表示X不作为一个分组,就是为了划分而已,不匹配。re.findall(r'http://(?:\w+\.)*(\w+\.com)', 'http://google.com http://www.google.com http://code.google.com') # ['google.com', 'google.com', 'google.com'] -
(?P:给组命名为) name通过使用一个名称标识符而不是使用从1 开始增加到N 的增量数字来保存匹配,如果使用数字来保存匹配结果,我们就可以通过使用
\1,\2 ...,\N,\来检索re.search(r'\((?P\d{3})\) (?P , '(800) 555-1212').groupdict() # {'areacode': '800', 'prefix': '555'}\d{3})-(?:\d{4})' re.sub(r'\((?P\d{3})\) (?P , '(\g\d{3})-(?:\d{4})' ) \g , '(800) 555-1212') # '(800) 555-xxxx'-xxxx' -
(?P=name):匹配前面已命名的组,比如验证号码是否符合规范bool(re.match(r'\((?P\d{3})\) (?P , '(800) 555-1212 800-555-1212 18005551212')) # 好看的版本 bool(re.match(r'''(?x) # 匹配(800) 555-1212,保存 areacode、prefix、no \((?P\d{3})-(?P \d{4}) (?P=areacode)-(?P=prefix)-(?P=number) 1(?P=areacode)(?P=prefix)(?P=number)' \d{3})\) [ ] (?P , '(800) 555-1212 800-555-1212 18005551212' )) # 结果如下 # True\d{3})-(?P \d{4}) # 空格 [ ] # 匹配 800-555-1212 (?P=areacode)-(?P=prefix)-(?P=number) # 空格 [ ] # 匹配 18005551212 1(?P=areacode)(?P=prefix)(?P=number) ''' -
(?=):正向前视断言如下,找到后面跟着
van Rossum的字符串,不匹配(?=)本身re.findall(r'\w+(?= van Rossum)', ''' Guido van Rossum Tim Peters Alex Martelli Just van Rossum Raymond Hettinger ''') # ['Guido', 'Just'] -
(?!):负向前视断言如下,找到后面不跟着
noreply或postmaster的字符串,不匹配(?!)本身及以后re.findall(r'(?m)^\s+(?!noreply|postmaster)(\w+)', ''' [email protected] [email protected] [email protected] [email protected] [email protected] ''' ) # ['sales', 'eng', 'adimn'] -
使用
finditer循环遍历结果,生成list['%[email protected]' % e.group(1) for e in re.finditer(r'(?m)^\s+(?!noreply|postmaster)(\w+)', ''' [email protected] [email protected] [email protected] [email protected] [email protected] ''')] # ['[email protected]', '[email protected]', '[email protected]'] -
(?(num或name)X|Y):如果分组所提供的num或者变量名存在,则返回X,否则返回Ybool(re.search(r'(?:(x)|y)(?(1)y|x)', 'xx')) # False bool(re.search(r'(?:(x)|y)(?(1)y|x)', 'yx')) # True这里,如果第1个是x,则有编号1,即
(x);是y,则没有编号1。后面的如果前面有编号,则返回y,即xy;如果前面的没有编号,则返回x,即yx注意:
(?:)指的是不捕获外面这个括号的分组,所以里面的x是捕获的,而(x)|y是不捕获的。
-
-
杂项
-
\w 和\W 字母数字字符集同时受re.L/LOCALE 和Unicode(re.U/UNICODE)标记所影响。
-
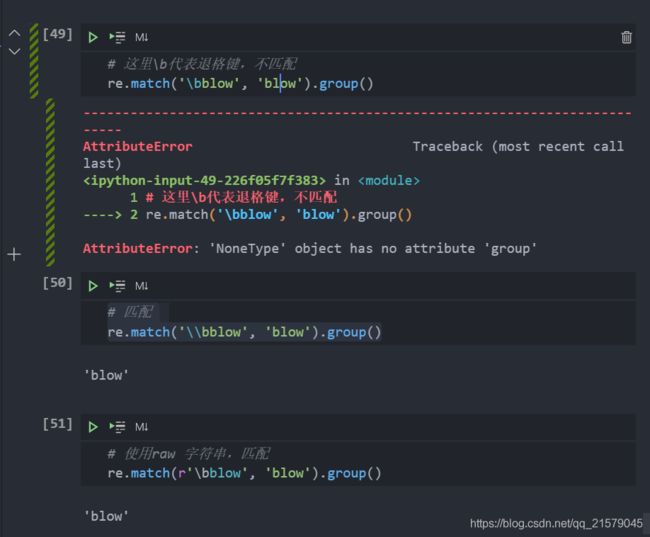
退格符\b 和正则表达式\b 之间的差异
-
2. 网络编程
- 套接字:是计算机网络数据结构,socket。Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
- 有两种类型的套接字:基于文件的和面向网络的。
- 如果一个套接字像一个电话插孔——允许通信的一些基础设施,那么主机名和端口号就像区号和电话号码的组合
2.1 socket网络编程
-
socket:套接字
-
socket(socket_family, socket_type, protocol=0):socket_family是AF_UNIX或AF_INET,socket_type是SOCK_STREAM或SOCK_DGRAM,protocol通常省略,默认为0。- 创建TCP/IP套接字:
tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) - 创建UDP/IP套接字:
udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
- 创建TCP/IP套接字:
-
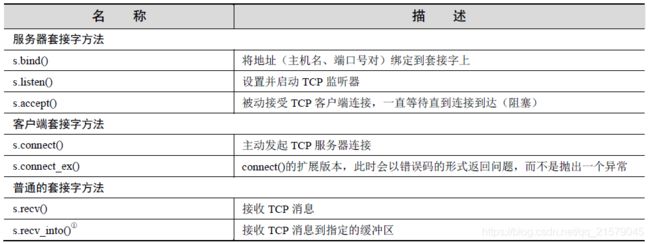
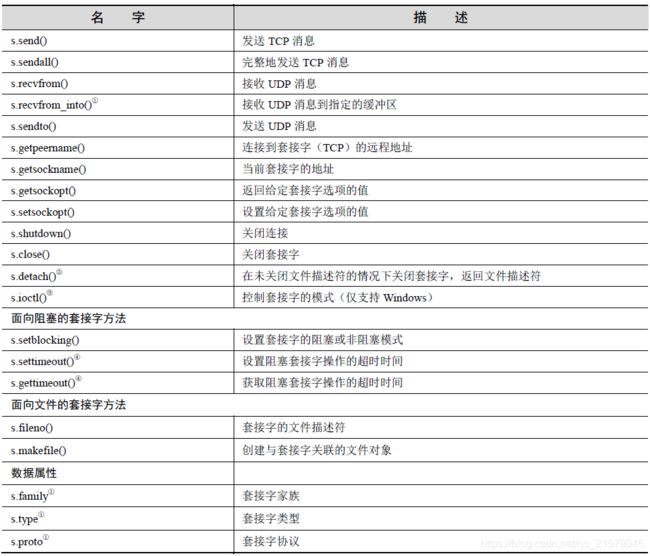
常见的套接字对象方法和属性
-
创建TCP服务器
from socket import * from time import ctime HOST = '' PORT = 21567 BUFSIZ = 1024 ADDR = (HOST, PORT) tcpSerSock = socket(AF_INET, SOCK_STREAM) tcpSerSock.bind(ADDR) tcpSerSock.listen(5) while True: print('等待连接...') tcpCliSock, addr =tcpSerSock.accept() print('...连接自:', addr) while True: data = tcpCliSock.recv(BUFSIZ) if not data: break tcpCliSock.send('[%s] %s' % (bytes(ctime(), 'utf-8'), data)) tcpCliSock.close() tcpSerSock.close() -
创建TCP客户端
from socket import * HOST = 'localhost' PORT = 21567 BUFSIZ = 1024 ADDR = (HOST, PORT) tcpCliSock = socket(AF_INET, SOCK_STREAM) tcpCliSock.connect(ADDR) while True: data = input('> ') if not data: break tcpCliSock.send(bytes(data, encoding="utf-8")) data = tcpCliSock.recv(BUFSIZ) if not data: break print(str(data, encoding="utf-8")) tcpCliSock.close() -
UDP 和TCP 服务器之间的另一个显著差异是,因为数据报套接字是无连接的,所以就没有为了成功通信而使一个客户端连接到一个独立的套接字“转换”的操作。这些服务器仅仅接受消息并有可能回复数据。
-
UDP 客户端循环工作方式几乎和TCP 客户端完全一样。唯一的区别是,事先不需要建立与UDP 服务器的连接,只是简单地发送一条消息并等待服务器的回复。
-
socket模块属性

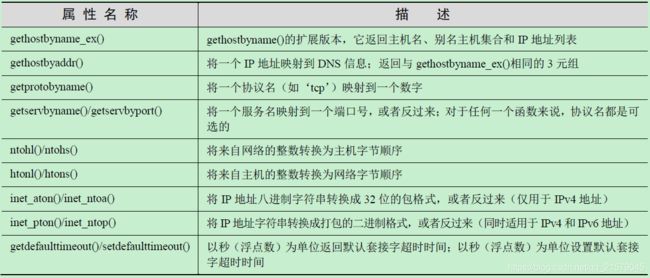
2.2 SocketServer 模块
-
创建SocketServer TCP服务器
from socketserver import (TCPServer as TCP, StreamRequestHandler as SRH) from time import ctime HOST = '' PORT = 21567 ADDR = (HOST, PORT) class MyRequestHandler(SRH): def handle(self): print('...连自:', self.client_address) self.wfile.write('[%s] %s' % (ctime(), self.rfile.readline())) tcpServ = TCP(ADDR, MyRequestHandler) print('等待连接...') tcpServ.serve_forever() -
创建SocketServer TCP 客户端
from socket import * HOST = 'localhost' PORT = 21567 BUFSIZ = 1024 ADDR = (HOST, PORT) while True: tcpCliSock = socket(AF_INET, SOCK_STREAM) tcpCliSock.connect(ADDR) data = input('> ') if not data: break tcpCliSock.send(bytes('%s\r\n' % data, encoding='utf-8')) data = tcpCliSock.recv(BUFSIZ) if not data: break print(str(data, encoding='utf-8').strip()) tcpCliSock.close()
2.3 Twisted框架介绍
-
创建Twisted Reactor TCP 服务器
from twisted.internet import protocol, reactor from time import ctime PORT = 21567 class TSServProtocol(protocol.Protocol): def connectionMade(self): clnt = self.clnt = self.transport.getPeer().host print('...连接自:', clnt) def dataReceived(self, data): self.transport.write(bytes('[%s] %s' % (ctime(), str(data, encoding='utf-8')), encoding='utf-8')) factory = protocol.Factory() factory.protocol = TSServProtocol print('等待连接...') reactor.listenTCP(PORT, factory) reactor.run() -
创建Twisted Reactor TCP 客户端
from twisted.internet import protocol, reactor HOST = 'localhost' PORT = 21567 class TSClntProtocol(protocol.Protocol): def sendData(self): data = input('> ') if data: print('...发送: %s...' % data) self.transport.write(bytes(data, encoding='utf-8')) else: self.transport.loseConnection() def connectionMade(self): self.sendData() def dataReceived(self, data): print(str(data, encoding='utf-8')) self.sendData() class TSClntFactory(protocol.ClientFactory): protocol = TSClntProtocol clientConnectionLost = clientConnectionFailed = lambda self, connector, reason: reactor.stop() reactor.connectTCP(HOST, PORT, TSClntFactory()) reactor.run()
3. 因特网客户端编程
3.1 文件传输
-
常见的文件传输协议:
- HTTP
- FTP
- scp/rsync
-
FTP,File Transfer Protocol,文件传输协议
- FTP只使用TCP,而不是UDP
- FTP可以看作客户端/服务器编程中的特殊情况,因这里的客户端和服务器都使用两个套接字来通信:
- 一个是控制和命令端口,21
- 一个是数据端口,20
- FTP有两种模式:主动和被动,只有在主动模式下服务器才使用数据端口。
-
使用Python编写FTP客户端程序:
-
流程:
- 连接到服务器
- 登录
- 发出服务请求
- 退出
-
ftplib.FTP对象的方法:

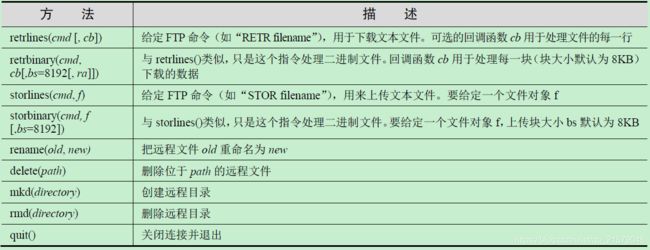
-
客户端FTP程序示例
import ftplib import os import socket HOST = 'ftp.mozilla.org' DIRN = 'pub/mozilla.org/webtools' FILE = 'bugzilla-LATEST.tar.gz' def main(): # 创建一个FTP对象,尝试连接到FTP服务器 try: f = ftplib.FTP(HOST) except (socket.error, socket.gaierror) as e: print('error: cannot reach "%s"' % HOST) return print('*** Connected to host "%s"' % HOST) # 尝试用anonymous登录 try: f.login() except ftplib.error_perm: print('ERROR: cannot login anonymously') f.quit() return print('*** Logged in as "anonymous"') # 转到发布目录 try: f.cwd(DIRN) except ftplib.error_perm: print('ERROR: cannot CD to "%s"' % DIRN) f.quit() return print('*** Changed to "%s" folder' % DIRN) # 下载文件 try: f.retrbinary('RETR %s' % FILE, open(FILE, 'wb').write) except ftplib.error_perm: print('ERROR: cannot read file "%s"' % FILE) os.unlink(FILE) else: print('*** Downloaded "%s" to CWD' % FILE) f.quit() if __name__ == '__main__': main()
-
3.2 网络新闻
-
NNTP对象的方法

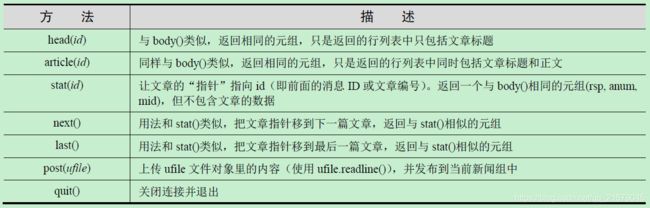
-
真本书的网络编程写的真的八行,外国人写的书,好的是真的好,烂的是真的烂,这本书不知道为什么吹的人那么多,烂的扣jio,这里的例子真的不想抄一遍了,神神叨叨的,跑也跑不通,学网络建议直接去看flask和django的书。
3.3 电子邮件
-
MTA:传送代理,Mail Transfer Agent
-
MTS:消息传输系统
-
为了发送电子邮件,邮件客户端必须要连接到一个MTA,MTA 靠某种协议进行通信。MTA之间通过消息传输系统(MTS)互相通信。只有两个MTA 都使用这个协议时,才能进行通信。
-
SMTP:简单邮件传输协议,Simple Mail Transfer Protocol
-
ESMTP:扩展 SMTP,Extended SMTP,对标准 SMTP 协议进行的扩展。它与 SMTP 服务的区别仅仅是,使用 SMTP 发信不需要验证用户帐户,而用 ESMTP 发信时,服务器会要求用户提供用户名和密码以便验证身份。在所有的验证机制中,信息全部采用Base64编码。验证之后的邮件发送过程与 SMTP 方式没有两样。
-
LMTP:本地邮件传输协议,Local Mail Transfer Protocol。SMTP和SMTP服务扩展(ESMTP)提供了一种高效安全传送电子邮件的方法,而在实现SMTP时需要管理一个邮件传送队列,在有些时候这样做可能有麻烦,需要一种没有队列的邮件传送系统,而LMTP就是这样的一个系统,它使用ESMTP的语法,而它和ESMTP可不是一回事,而LMTP也不能用于TCP端口25。
-
SMTP 是在因特网上的MTA 之间消息交换的最常用MTSMTA。用SMTP 把电子邮件从一台(MTA)主机传送到另一台(MTA)主机。发电子邮件时,必须要连接到一个外部SMTP服务器,此时邮件程序是一个SMTP 客户端。而SMTP 服务器也因此成为消息的第一站。
-
MUA:Mail User Agent,邮件用户代理,在家用电脑中运行的应用程序。
-
POP:Post Office Protocal,邮局协议,第一个用于下载邮件的协议。
-
IMAP:Internet Message Access Protocol,因特网消息访问协议。
POP无法很好地应对多邮件客户端,因此现在被废弃了,IMAP4rev1现在广泛使用。
-
MIME,Mail Interchange Message Extension,邮件呼唤消息扩展(这啥呀,百度都搜不到,搜到的是Multipurpose Internet Mail Extensions,多用途互联网邮件扩展类型,这本书真的没有瞎编吗,还是译者瞎翻译?)
3.4 实战
-
憋实战了叭,根本跑不通
from email.mime.image import MIMEImage from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from smtplib import SMTP def make_mpa_msg(): email = MIMEMultipart('alternative') text = MIMEText('Hello World!\r\n', 'plain') email.attach(text) html = MIMEText('Hello World!
', 'html') email.attach(html) return email def make_img_msg(fn): f = open(fn, 'r') data = f.read() f.close() email = MIMEImage(data, name=fn) email.add_header('Content-Dispostion', 'attachment; filename="%s"' % fn) return email def sendMsg(fr, to, msg): s = SMTP('localhost') errs = s.sendmail(fr, to, msg) s.quit() if __name__ == '__main__': print('Sending multipart alternative msg...') msg = make_mpa_msg() SENDER = '' RECIPS = '' SOME_IMG_FILE = r'' msg['From'] = SENDER msg['To'] = ', '.join(RECIPS) msg['Subject'] = 'multipart alternative test' sendMsg(SENDER, RECIPS, msg.as_string()) print(('Sending image msg...')) msg = make_img_msg(SOME_IMG_FILE) msg['From'] = SENDER msg['To'] = ', '.join(RECIPS) msg['Subject'] = 'Image file test' sendMsg(SENDER, RECIPS, msg.as_string()) -
SaaS:Software as a Service,软件即服务(这里的Service书中还打错了。。。我佛了)
-
使用
timeit查看代码运行时长 -
TLS:Transport Layer Security,传输层安全
4. 多线程编程
4.1 线程和进程
-
多线程:multithreaded,MT
-
IPC:Inter-Process Communication,进程间通信
-
线程包括开始、执行顺序和结束三部分。它有一个指令指针,用于记录当前运行的上下文。当其他线程运行时,它可以被抢占(中断)和临时挂起(也称为睡眠)——这种做法叫做让步(yielding)。
-
GIL:Global Interpreter Lock,全局解释器锁
-
不建议使用thread模块:,其中最明显的一个原因是在主线程退出之后,所有其他线程都会在没有清理的情况下直接退出。而另一个模块threading 会确保在所有“重要的”子线程退出前,保持整个进程的存活。
-
下面的脚本在一个单线程程序里连续执行两个循环。一个循环必须在另一个开始前完成。总共消耗的时间是每个循环所用时间之和。
from time import sleep, ctime def loop0(): print('start loop 0 at: ', ctime()) sleep(4) print('loop 0 done at: ', ctime()) def loop1(): print('start loop 1 at: ', ctime()) sleep(2) print('loop 1 done at:', ctime()) def main(): print('starting at: ', ctime()) loop0() loop1() print('all Done at: ', ctime()) if __name__ == '__main__': main()
4.2 thread
-
thread模块和锁对象
-
锁对象:lock object,原语锁、简单锁、互斥锁、互斥和二进制信号锁。

-
-
thread.start_new_thread()必须包含开始的两个参数,于是即使要执行的函数不需要参数,也需要传递一个空元组。这里需要注意的是,在python3中想要使用thread,导入的是_threadimport _thread as thread from time import sleep, ctime def loop0(): print('start loop 0 at: ', ctime()) sleep(4) print('loop 0 done at: ', ctime()) def loop1(): print('start loop 1 at: ', ctime()) sleep(2) print('loop 1 done at: ', ctime()) def main(): print('starting at: ', ctime()) thread.start_new_thread(loop0, ()) thread.start_new_thread(loop1, ()) sleep(6) print('all DONE at: ', ctime()) if __name__ == '__main__': main() -
引入锁,并去除单独的循环函数
import _thread as thread from time import sleep, ctime loops = [4, 2] def loop(nloop, nsec, lock): print('start loop', nloop, 'at: ', ctime()) sleep(nsec) print('loop', nloop, 'done at:', ctime()) lock.release() def main(): print('starting at: ', ctime()) locks = [] nloops = range(len(loops)) # 首先创建一个锁列表 for i in nloops: # 得到锁对象,获取锁需要花费一些时间 lock = thread.allocate_lock() # 获得每个锁,把锁锁上 lock.acquire() locks.append(lock) for i in nloops: thread.start_new_thread(loop, (i, loops[i], locks[i])) # 等待/暂停主线程,直到所有锁都被释放之后才会继续执行。 for i in nloops: while locks[i].locked(): pass print('all Done at: ', ctime()) if __name__ == '__main__': main()
4.3 threading
-
thread仅供学习用,正常用的话,都选threading。除了Thread 类以外,该模块还包括许多非常好用的同步机制。
避免使用thread 模块的另一个原因是该模块不支持守护线程这个概念。当主线程退出时,所有子线程都将终止,不管它们是否仍在工作。如果你不希望发生这种行为,就要引入守护线程的概念了。

-
守护线程:进程退出时不需要等待这个线程执行完成。
-
threading 模块的Thread 类是主要的执行对象
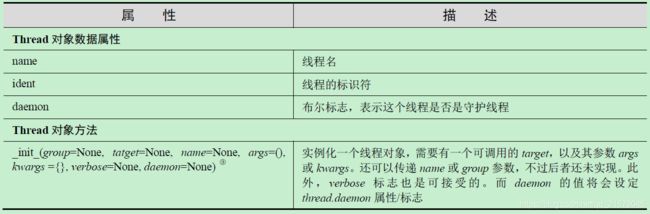
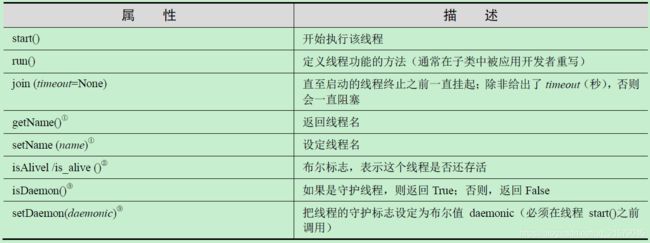
-
使用Thread的方法:
-
创建Thread 的实例,传给它一个函数。
import threading from time import sleep, ctime loops = [4, 2] def loop(nloop, nsec): print('start loop', nloop, 'at: ', ctime()) sleep(nsec) print('loop', nloop, 'done at:', ctime()) def main(): print('starting at: ', ctime()) threads = [] nloops = range(len(loops)) for i in nloops: t = threading.Thread(target=loop, args=(i, loops[i])) threads.append(t) for i in nloops: threads[i].start() for i in nloops: threads[i].join() print('all Done at: ', ctime()) if __name__ == '__main__': main() -
创建Thread 的实例,传给它一个可调用的类实例。
import threading from time import sleep, ctime loops = [4, 2] class ThreadFunc(object): def __init__(self, f, args, name=''): self.name = name self.f = f self.args = args def __call__(self): self.f(*self.args) def loop(nloop, nsec): print('start loop', nloop, 'at: ', ctime()) sleep(nsec) print('loop', nloop, 'done at:', ctime()) def main(): print('starting at: ', ctime()) threads = [] nloops = range(len(loops)) for i in nloops: t = threading.Thread(target=ThreadFunc(loop, (i, loops[i]), loop.__name__)) threads.append(t) for i in nloops: threads[i].start() for i in nloops: threads[i].join() print('all Done at: ', ctime()) if __name__ == '__main__': main() -
派生Thread 的子类,并创建子类的实例。
对Thread 子类化,而不是直接对其实例化。这将使我们在定制线程对象时拥有更多的灵活性,也能够简化线程创建的调用过程。
运行时报错:
AssertionError: Thread.__init__() not called解决方案:这是因为在子类的初始化函数中没有初始化父类初始化函数,所以需要加上:
super().__init__()import threading from time import sleep, ctime loops = [4, 2] class MyThread(threading.Thread): def __init__(self, f, args, name=''): super().__init__() self.name = name self.f = f self.args = args def run(self): self.f(*self.args) def loop(nloop, nsec): print('start loop', nloop, 'at: ', ctime()) sleep(nsec) print('loop', nloop, 'done at:', ctime()) def main(): print('starting at: ', ctime()) threads = [] nloops = range(len(loops)) for i in nloops: t = MyThread(loop, (i, loops[i]), loop.__name__) threads.append(t) for i in nloops: threads[i].start() for i in nloops: threads[i].join() print('all Done at: ', ctime()) if __name__ == '__main__': main()
-
-
实例化
Thread(调用Thread())和调用thread.start_new_thread()的最大区别是新线程不会立即开始执行。 -
join()方法将等待线程结束,或者在提供了超时时间的情况下,达到超时时间。使用join()方法要比等待锁释放的无限循环更加清晰(这也是这种锁又称为自旋锁的原因)。 -
__call__()方法:主要实现的是将类的对象当作函数直接调用。 -
之前的特殊方法
__call__()在这个子类中必须要写为run()。 -
threading模块的其他函数
4.4 单线程和多线程执行对比
-
为了让
Thread的子类更加通用,将这个子类移到一个专门的模块中,并添加了可调用的getResult()方法来取得返回值。import threading from time import ctime class MyThread(threading.Thread): def __init__(self, func, args, name=''): super().__init__() self.name = name self.func = func self.args = args self.res = None def __post_init__(self): super().__init__() def getResult(self): return self.res def run(self): print('starting', self.name, 'at: ', ctime()) self.res = self.func(*self.args) print(self.name, 'finished at: ', ctime()) -
单线程执行斐波那契、阶乘和累加
from myThread import MyThread from time import ctime, sleep def fib(x): sleep(0.005) if x < 2: return 1 return (fib(x-2) + fib(x-1)) def fac(x): sleep(0.1) if x < 2: return 1 return (x * fac(x-1)) def sums(x): sleep(0.1) if x < 2: return 1 return (x + sums(x-1)) funcs = [fib, fac, sums] n = 12 def main(): nfuncs = range(len(funcs)) print('*** SINGLE THREAD') for i in nfuncs: print('starting', funcs[i].__name__, 'at: ', ctime()) print(funcs[i](n)) print(funcs[i].__name__, 'finished at: ', ctime()) print('\n*** MULTIPLE THREADS') threads = [] for i in nfuncs: t = MyThread(funcs[i], (n, ), funcs[i].__name__) threads.append(t) for i in nfuncs: threads[i].start() for i in nfuncs: threads[i].getResult() print('all DONE') if __name__ == '__main__': main()
4.5 多线程实践
-
函数名最前面的单下划线表示这是一个特殊函数,只能被本模块的代码使用,不能被其他使用本文件作为库或者工具模块的应用导入。
-
同步:
- 需求背景:如果两个线程运行的顺序发生变化,就有可能造成代码的执行轨迹或行为不相同,或者产生不一致的数据。(比如数据库写入内容,读取内容)
- 含义:当任意数量的线程可以访问临界区的代码,但在给定的时刻只有一个线程可以通过时,就是使用同步的时候了。
-
当多线程争夺锁时,允许第一个获得锁的线程进入临界区,并执行代码。所有之后到达的线程将被阻塞,直到第一个线程执行结束,退出临界区,并释放锁。
from atexit import register from random import randrange from threading import Thread, Lock, currentThread from time import sleep, ctime class CleanOutputSet(set): def __str__(self): return ', '.join(x for x in self) lock = Lock() loops = (randrange(2, 5) for x in range(randrange(3, 7))) remaining = CleanOutputSet() def loop(nsec): myname = currentThread().name lock.acquire() remaining.add(myname) print('[%s] Started %s' % (ctime(), myname)) lock.release() sleep(nsec) lock.acquire() remaining.remove(myname) print('[%s] Completed %s (%d secs)' % (ctime(), myname, nsec)) print('(remaining: %s)' % (remaining or 'None')) lock.release() def _main(): for pause in loops: Thread(target=loop, args=(pause, )).start() @register def _atexit(): print('all DONE at: ', ctime()) if __name__ == '__main__': _main() -
使用上下文管理:还有一种方案可以不再调用锁的acquire()和release()方法,从而更进一步简化代码。这就是使用
with 语句,此时每个对象的上下文管理器负责在进入该套件之前调用acquire()并在完成执行之后调用release()。 -
信号量:信号量是最古老的同步原语之一。它是一个计数器,当资源消耗时递减,当资源释放时递增。信号量代表资源是否可用。信号量比锁更加灵活,因为可以有多个线程,每个线程拥有有限资源的一个实例。
from atexit import register from random import randrange from threading import BoundedSemaphore, Lock, Thread from time import sleep, ctime lock = Lock() MAX = 5 candytray = BoundedSemaphore(MAX) def refill(): lock.acquire() print('Refilling candy...') try: candytray.release() except ValueError: print('full, skipping') else: print('OK') lock.release() def buy(): lock.acquire() print('Buy candy...') if candytray.acquire(False): print('OK') else: print('empty, skipping') lock.release() def producer(loops): for i in range(loops): refill() sleep(randrange(3)) def consumer(loops): for i in range(loops): buy() sleep(randrange(3)) def _main(): print('starting at:', ctime()) nloops=randrange(2, 6) print('THE CANDY MACHINE (full with %d bars)' % MAX) Thread(target=consumer, args=(randrange(nloops, nloops+MAX+2),)).start() Thread(target=producer, args=(nloops,)).start() @register def _atexit(): print('all Done at: ', ctime()) if __name__ == '__main__': _main()
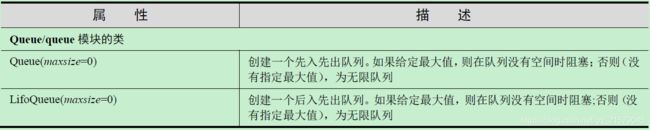
4.6 Queue模块
-
Queue/queue模块常用属性

-
生产消费者问题
from random import randint from time import sleep from queue import Queue from myThread import MyThread def writeQ(queue): print('producing object for Q...', end='') queue.put('xxx', 1) print('size now', queue.qsize()) def readQ(queue): val = queue.get(1) print('consumed object from Q...size now', queue.qsize()) def writer(queue, loops): for i in range(loops): writeQ(queue) sleep(randint(1, 3)) def reader(queue, loops): for i in range(loops): readQ(queue) sleep(randint(3, 5)) funcs = [writer, reader] nfuncs = range(len(funcs)) def main(): nloops = randint(2, 5) q = Queue(maxsize=32) threads = [] for i in nfuncs: t = MyThread(funcs[i], [q, nloops], funcs[i].__name__) threads.append(t) for i in nfuncs: threads[i].start() for i in nfuncs: threads[i].join() print('all DONE') if __name__ == '__main__': main()
4.7 线程的替代方案
-
由于Python 的GIL 的限制,多线程更适合于I/O 密集型应用(I/O 释放了GIL,可以允许更多的并发),而不是计算密集型应用。对于后一种情况而言,为了实现更好的并行性,你需要使用多进程,以便让CPU 的其他内核来执行。
-
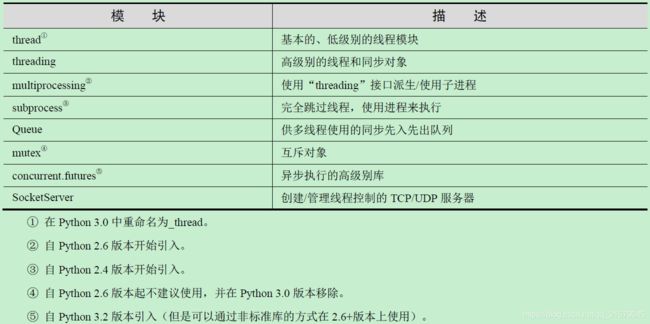
对于多线程或多进程而言,threading模块的主要替代品包括以下几个:
- subprocess
- multiprocessing
- concurrent.futures
- I/O密集型应用:concurrent.futures.ThreadPoolExecutor
- 计算密集型应用:concurrent.futures.ProcessPoolExecutor
-
使用
concurrent.futures模块的图书排名from concurrent.futures import ThreadPoolExecutor from re import compile from time import ctime from urllib.request import urlopen as uopen REGEX = compile(b'#([\d,]+) in Books ') AMZN = 'http://amazon.com/dp/' ISBNs = { '0132269937': 'Core Python Programming', '0132356139': 'Python Web Development with Django', '0137143419': 'Python Fundamentals' } def getRanking(isbn): with uopen('{0}{1}'.format(AMZN, isbn)) as page: return str(REGEX.findall(page.read())[0], 'utf-8') def _main(): print('At', ctime(), 'on Amazon...') with ThreadPoolExecutor(3) as executor: for isbn, ranking in zip(ISBNs, executor.map(getRanking, ISBNs)): print('- %r ranked %s' % (ISBNs[isbn], ranking)) print('all DONE at: ', ctime()) if __name__ == '__main__': _main() -
相关模块总结
-
一些问题:
-
进程和线程的区别是什么?
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位。
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
-
在Python 中,哪种类型的多线程应用表现得更好,I/O 密集型还是计算密集型?
由于Python 的GIL 的限制,多线程更适合于I/O 密集型应用(I/O 释放了GIL,可以允许更多的并发),而不是计算密集型应用。对于后一种情况而言,为了实现更好的并行性,你需要使用多进程,以便让CPU 的其他内核来执行。
-
5. GUI编程
5.1 概述
-
GUI:图形用户界面,Graphical User Interface。
-
Tkinter是python默认的GUI库,基于Tk工具包,该工具包最初是为 工具命令语言 (Tool Command Language,Tcl)设计的。
-
Tk控件:
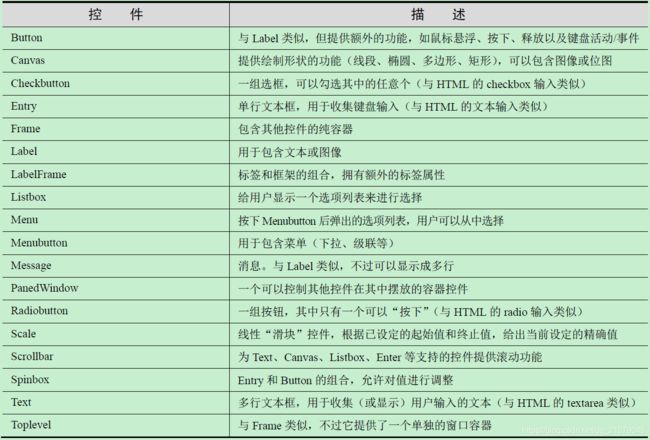
5.2 示例
-
Label控件
import tkinter as tk top = tk.Tk() label = tk.Label(top, text='Hello World') label.pack() tk.mainloop() -
Button控件
import tkinter as tk top = tk.Tk() quit = tk.Button(top, text='Hello World', command=top.quit) quit.pack() tk.mainloop() -
label和button控件演示
import tkinter as tk top = tk.Tk() hello = tk.Label(top, text='Hello World!') hello.pack() quit = tk.Button(top, text='QUIT', command=top.quit, bg='red', fg='white') quit.pack(fill=tk.X, expand=1) tk.mainloop() -
label、button和scale控件
import tkinter as tk def resize(ev=None): label.config(font='Helvetica -%d bold' % scale.get()) top = tk.Tk() top.geometry('250x150') label = tk.Label(top, text='Hello World!', font='Helvetica -12 bold') label.pack() scale = tk.Scale(top, from_=10, to=40, orient=tk.HORIZONTAL, command=resize) scale.set(12) scale.pack(fill=tk.X, expand=1) quit = tk.Button(top, text='QUIT', command=top.quit, activeforeground='white', activebackground='red') quit.pack() tk.mainloop()
5.3 偏函数
-
根据标志类型创建拥有合适前景色和背景色的路标。使用偏函数可以帮助你“模板化”通用的GUI 参数。
from functools import partial as pto from tkinter import Tk, Button, X from tkinter.messagebox import showinfo, showwarning, showerror WARN = 'warn' CRIT = 'crit' REGU = 'regu' SIGNS = { 'do not enter': CRIT, 'railroad crossing': WARN, '55\nspeed limit': REGU, 'wrong way': CRIT, 'merging traffic': WARN, 'one way': REGU, } critCB = lambda: showerror('Error', 'Error Button Pressed!') warnCB = lambda: showwarning('Warning', 'Warning Button Pressed!') infoCB = lambda: showinfo('Info', 'Info Button Pressed!') top = Tk() top.title('Road Signs') Button(top, text='Quit', command=top.quit, bg='red', fg='white').pack() MyButton = pto(Button, top) CritButton = pto(MyButton, command=critCB, bg='white', fg='red') WarnButton = pto(MyButton, command=warnCB, bg='goldenrod1') ReguButton = pto(MyButton, command=infoCB, bg='white') for eachSign in SIGNS: # 获取每个字典的值 signType = SIGNS[eachSign] # 获取值的.title()也就是第一个字母大写,对应了不同的Button cmd = '%sButton(text=%r%s).pack(fill=X, expand=True)' % (signType.title(), eachSign, '.upper()' if signType == CRIT else '.title()') eval(cmd) top.mainloop() -
functools详解-
patial
用于创建一个偏函数,将默认参数包装一个可调用对象,返回结果也是可调用对象。
偏函数可以固定住原函数的部分参数,从而在调用时更简单。from functools import partial def add(a, b): return a+b addOne = partial(add, 10) print(add(1, 2)) # 3 print(addOne(1)) # 11 -
update_wrapper
使用
partial包装的函数是没有__name__和__doc__属性的。
update_wrapper作用:将被包装函数的__name__等属性,拷贝到新的函数中去。from functools import update_wrapper def wrapper(f): def wrapper_function(*args, **kwargs): """这个是修饰函数""" return f(*args, **kwargs) return wrapper_function @wrapper def wrapped(): """这个是被修饰的函数""" print('wrapped') print(wrapped.__doc__) # 这个是修饰函数 print(wrapped.__name__) # wrapper_function def wrapper2(f): def wrapper_function2(*args, **kwargs): """这个是修饰函数""" return f(*args, **kwargs) update_wrapper(wrapper_function2, f) return wrapper_function2 @wrapper2 def wrapped2(): """这个是被修饰的函数""" print('wrapped') print(wrapped2.__doc__) # 这个是被修饰的函数 print(wrapped2.__name__) # wrapped2 -
wraps
warps函数是为了在装饰器拷贝被装饰函数的__name__。
就是在update_wrapper上进行一个包装from functools import wraps def wrap1(func): # 去掉就会返回inner @wraps(func) def inner(*args): print(func.__name__) return func(*args) return inner @wrap1 def demo(): print('Hello World!') print(demo.__name__) # demo -
reduce
在 Python2 中等同于内建函数 reduce
函数的作用是将一个序列归纳为一个输出
reduce(function, sequence, startValue)在 Python2 中等同于内建函数 reduce 函数的作用是将一个序列归纳为一个输出 reduce(function, sequence, startValue) -
cmp_to_key
在 list.sort 和 内建函数 sorted 中都有一个 key 参数
x = ['hello', 'world', 'ni'] x.sort(key=len) print(x) from functools import cmp_to_key ll = [9, 2, 23, 1, 2] print(sorted(ll, key=cmp_to_key(lambda x, y: y - x))) print(sorted(ll, key=cmp_to_key(lambda x, y: x - y))) -
lru_cache
允许我们将一个函数的返回值快速地缓存或取消缓存。
该装饰器用于缓存函数的调用结果,对于需要多次调用的函数,而且每次调用参数都相同,则可以用该装饰器缓存调用结果,从而加快程序运行。
该装饰器会将不同的调用结果缓存在内存中,因此需要注意内存占用问题。from functools import lru_cache # maxsize参数告诉lru_cache混村最近多少个返回值 @lru_cache(maxsize=30) def fib(n): if n < 2: return n return fib(n-1) + fib(n-2) print([fib(n) for n in range(10)]) fib.cache_clear() -
singledispatch
单分发器, Python3.4新增,用于实现泛型函数。
根据单一参数的类型来判断调用哪个函数。from functools import singledispatch @singledispatch def fun(text): print('String: ' + text) @fun.register(int) def _(text): print(text) @fun.register(list) def _(text): for k, v in enumerate(text): print(k, v) @fun.register(float) @fun.register(tuple) def _(text): print('float, tuple') fun('i am is gouzei') fun(123) fun(['a', 'b', 'c', 'd']) fun(1.243) print(fun.registry) print(fun.registry[int])
-
5.4 中级Tkinter
-
这个应用是一个目录树遍历工具。它会从当前目录开始,提供一个文件列表。双击列表中任意其他目录,就会使得工具切换到新目录中,用新目录中的文件列表代替旧文件列表。
-
hasattr():该函数用于判断对象是否包含对应的属性。 -
os.chdir():用于改变当前工作目录到指定的路径。 -
实现代码:
import os from time import sleep from tkinter import * class DirList(object): def __init__(self, initdir=None): self.top = Tk() self.label = Label(self.top, text='Directory Lister v1.1') self.label.pack() self.cwd = StringVar(self.top) self.dirl = Label(self.top, fg='blue', font=('Helvetica', 12, 'bold')) self.dirl.pack() self.dirfm = Frame(self.top) self.dirsb = Scrollbar(self.dirfm) self.dirsb.pack(side=RIGHT, fill=Y) self.dirs = Listbox(self.dirfm, height=15, width=50, yscrollcommand=self.dirsb.set) self.dirs.bind('' , self.setDirAndGo) self.dirsb.config(command=self.dirs.yview) self.dirs.pack(side=LEFT, fill=BOTH) self.dirfm.pack() self.dirn = Entry(self.top, width=50, textvariable=self.cwd) self.dirn.bind('' , self.doLS) self.dirn.pack() self.bfm = Frame(self.top) self.clr = Button(self.bfm, text='Clear', command=self.clrDir, activeforeground='white', activebackground='blue') self.ls = Button(self.bfm, text='List Directory', command=self.doLS, activeforeground='white', activebackground='green') self.quit = Button(self.bfm, text='Quit', command=self.top.quit, activeforeground='white', activebackground='red') self.clr.pack(side=LEFT) self.ls.pack(side=LEFT) self.quit.pack(side=LEFT) self.bfm.pack() if initdir: self.cwd.set(os.curdir) self.doLS() def clrDir(self, ev=None): self.cwd.set("") def setDirAndGo(self, ev=None): self.last = self.cwd.get() self.dirs.config(selectbackground='red') check = self.dirs.get(self.dirs.curselection()) if not check: check = os.curdir self.cwd.set(check) self.doLS() def doLS(self, ev=None): error = '' tdir = self.cwd.get() if not tdir: tdir = os.curdir if not os.path.exists(tdir): error = tdir + ': no such file' elif not os.path.isdir(tdir): error = tdir + ': not a directory' if error: self.cwd.set(error) self.top.update() sleep(2) if not (hasattr(self, 'last') and self.last): self.last = os.curdir self.cwd.set(self.last) self.dirs.config(selectbackground='LightSkyBlue') self.top.update() return self.cwd.set('FETCHING DIRECTORY CONTENTS...') self.top.update() dirlist = os.listdir(tdir) dirlist.sort() os.chdir(tdir) self.dirl.config(text=os.getcwd()) self.dirs.delete(0, END) self.dirs.insert(END, os.curdir) self.dirs.insert(END, os.pardir) for eachFile in dirlist: self.dirs.insert(END, eachFile) self.cwd.set(os.curdir) self.dirs.config(selectbackground='LightSkyBlue') def main(): d = DirList(os.curdir) mainloop() if __name__ == '__main__': main()
5.5 其他GUI简介
-
Tk接口扩展(Tix)
from functools import partial as pto from tkinter import Tk, Button, X from tkinter.messagebox import showinfo, showwarning, showerror WARN = 'warn' CRIT = 'crit' REGU = 'regu' SIGNS = { 'do not enter': CRIT, 'railroad crossing': WARN, '55\nspeed limit': REGU, 'wrong way': CRIT, 'merging traffic': WARN, 'one way': REGU, } critCB = lambda: showerror('Error', 'Error Button Pressed!') warnCB = lambda: showwarning('Warning', 'Warning Button Pressed!') infoCB = lambda: showinfo('Info', 'Info Button Pressed!') top = Tk() top.title('Road Signs') Button(top, text='Quit', command=top.quit, bg='red', fg='white').pack() MyButton = pto(Button, top) CritButton = pto(MyButton, command=critCB, bg='white', fg='red') WarnButton = pto(MyButton, command=warnCB, bg='goldenrod1') ReguButton = pto(MyButton, command=infoCB, bg='white') for eachSign in SIGNS: # 获取每个字典的值 signType = SIGNS[eachSign] # 获取值的.title()也就是第一个字母大写,对应了不同的Button cmd = '%sButton(text=%r%s).pack(fill=X, expand=True)' % (signType.title(), eachSign, '.upper()' if signType == CRIT else '.title()') eval(cmd) top.mainloop() -
Python MegaWidgets(PMW)
from tkinter import Button, END, Label, W from Pmw import initialise, ComboBox, Counter top = initialise() lb = Label(top, text='Animals (in pairs; min: pair, max: dozen)') lb.pack() ct = Counter(top, labelpos=W, label_text='Number: ', datatype='integer', entryfield_value=2, increment=2, entryfield_validate={ 'validator': 'integer', 'min': 2, 'max': 12}) ct.pack() cb = ComboBox(top, labelpos=W, label_text='Type: ') for animal in ('dog', 'cat', 'hamster', 'python'): cb.insert(END, animal) cb.pack() qb = Button(top, text='QUIT', command=top.quit, bg='red', fg='white') qb.pack() top.mainloop() -
wxWidgets和wxPython
import wx class MyFrame(wx.Frame): def __init__(self, parent=None, id=-1, title=""): wx.Frame.__init__(self, parent, id, title, size=(200, 140)) top = wx.Panel(self) sizer = wx.BoxSizer(wx.VERTICAL) font = wx.Font(9, wx.SWISS, wx.NORMAL, wx.BOLD) lb = wx.StaticText(top, -1, 'Animals (in pairs; min: pair, max: dozen)') sizer.Add(lb) c1 = wx.StaticText(top, -1, 'Number: ') c1.SetFont(font) ct = wx.SpinCtrl(top, -1, '2', min=2, max=12) sizer.Add(c1) sizer.Add(ct) c2 = wx.StaticText(top, -1, 'Type: ') c2.SetFont(font) cb = wx.ComboBox(top, -1, '', choices=('dog', 'cat', 'hamster', 'python')) sizer.Add(c2) sizer.Add(cb) top.SetSizer(sizer) self.Layout() class MyApp(wx.App): def OnInit(self): frame = MyFrame(title='wxWidgets') frame.Show(True) self.SetTopWindow(frame) return True def main(): app = MyApp() app.MainLoop() if __name__ == '__main__': main() -
GTK+和PyGTK
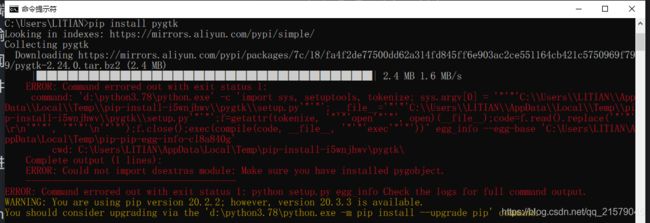
很离谱,这个包因为编码的原因,竟然安装不了,直接跳过吧。。。
-
Tile/Ttk
from tkinter import Tk, Spinbox from tkinter.ttk import Style, Label, Button, Combobox top = Tk() Style().configure("TButton", foreground='white', background='red') Label(top, text='Animals (in pairs; min: pair, max: dozen)').pack() Spinbox(top, from_=2, to=12, increment=2, font='Helvetica -14 bold').pack() Label(top, text='Type: ').pack() Combobox(top, values=('dog', 'cat', 'hamster', 'python')).pack() Button(top, text='QUIT', command=top.quit, style='TButton').pack() top.mainloop()
5.6 相关模块和其他GUI
-
Python中可用的GUI系统




6. 数据库编程
6.1 python的DB-API
-
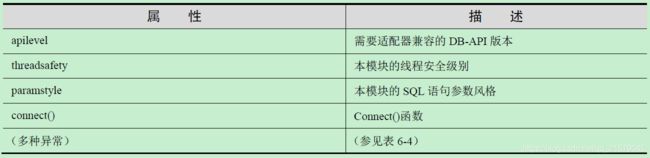
DB-API模块属性
-
connect()函数属性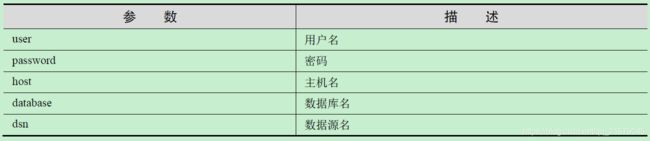
-
Connect对象方法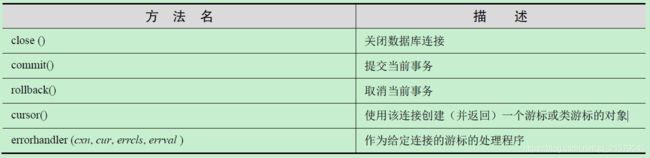
-
Cursor对象属性
-
类型对象和构造函数
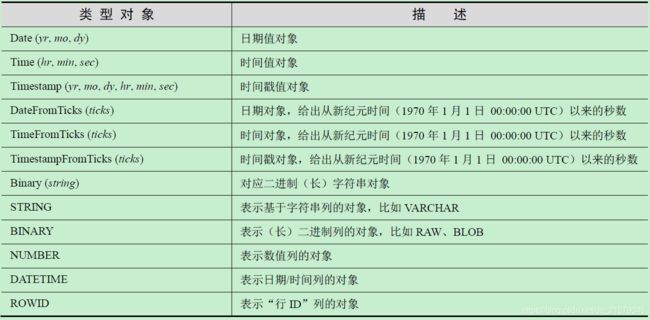
-
RDBMS:关系数据库管理系统,Relational DataBase Management System
6.2 ORM
- 数据库这一章的代码也忒乱了,根本没有敲一遍的欲望,还需要自己配置好数据库之后,才能敲代码,再见了您嘞。
- 这本书最大的问题是,很多内容都是基于python2的,然后python3很多都是提了一嘴,写的代码为了兼容两个版本,显得十分冗杂,讲道理,看到这么乱的思路和代码,我是真的无法纯粹的学习ijing 数据库编程的相关内容。
- 后面的ORM主要包括的是
SQLAlchemy和SQLObject,需要用的时候,百度API吧。
6.3 非关系型数据库
- 背景:Web 和社交服务的流行趋势会导致产生大量的数据,并且数据产生的速率可能要比关系数据库能够处理得更快。
- NoSQL:Not Only SQL,非关系型数据库,它们不保证关系数据的ACID特性。
- 单就非关系数据库而言,就有对象数据库、键-值对存储、文档存储(或者数据存储)、图形数据库、表格数据库、列/可扩展记录/宽列数据库、多值数据库等很多种类。
- 简单的键值对存储:
- Redis
- Voldemort
- Amazon
- Dynamo
- 列存储
- Cassandra
- Google Bigtable
- HBase
- MongoDB:有点像关系数据库的无模式衍生品,比基于列的存储更简单、约束更少,但是比普通的键-值对存储更加灵活。一般情况下其数据会另存为JSON 对象,并且允许诸如字符串、数值、列表甚至嵌套等数据类型。
- NoSQL中的术语是:文档、集合,而不是关系型数据库中的行、列。
- PyMongo:注意,这里不要
from pymongo import Connection了,会报错的,应该用from pymongo import MongoClient
7. Microsoft Office 编程
7.1 Excel
-
这里用tkinter和win32com的包,可以显式操作Excel
-
Tk().withdraw():不让Tk顶级窗口出现 -
这里用的是
win32.gencache.EnsureDispatch('%s.Application' % app)这个是静态调度,对象和属性经过了缓存,如果需要运行时构建,那就是动态调度:
win32com.client.Dispatch('%s.Application' % app) -
Visible必须设置为True,这样才能够在桌面上看见应用 -
这里的
ss.Close(False),意思时关闭时不保存。from tkinter import Tk from time import sleep from tkinter.messagebox import showwarning import win32com.client as win32 warn = lambda app: showwarning(app, 'Exit?') RANGE = range(3, 8) def excel(): app = 'Excel' xl = win32.gencache.EnsureDispatch('%s.Application' % app) ss = xl.Workbooks.Add() sh = ss.ActiveSheet xl.Visible = True sleep(1) sh.Cells(1, 1).Value = 'Python-to-%s Demo' % app sleep(1) for i in RANGE: sh.Cells(i, 1).Value = 'Line %d' % i sleep(1) sh.Cells(i+2, 1).Value = "Th-th-th-that's all folks!" warn(app) ss.Close(False) xl.Application.Quit() if __name__ == '__main__': Tk().withdraw() excel() -
中级就是获取网页的数据,然后写入excel,讲道理,现在用的时候,根本不会这么麻烦。
7.2 Word
-
Word中的代码,几乎跟excel一毛一样
from tkinter import Tk from time import sleep from tkinter.messagebox import showwarning import win32com.client as win32 warn = lambda app: showwarning(app, 'Exit?') RANGE = range(3, 8) def word(): app = 'Word' word = win32.gencache.EnsureDispatch('%s.Application' % app) doc = word.Documents.Add() word.Visible = True sleep(1) rng = doc.Range(0, 0) rng.InsertAfter('Python-to-%s Test\r\n\r\n' % app) sleep(1) for i in RANGE: rng.InsertAfter('Line %d\r\n' % i) sleep(1) rng.InsertAfter("\r\nTh-th-th-that's all folks!\r\n") warn(app) doc.Close(False) word.Application.Quit() if __name__ == '__main__': Tk().withdraw() word()
7.3 PowerPoint
-
讲道理,都什么年代了,用python操作ppt就很扯。
-
代码我是敲完了,但是这都啥啊,各种报错,也没法解决。
TypeError: 'Shapes' object is not subscriptable脑阔疼
from tkinter import Tk from time import sleep from tkinter.messagebox import showwarning import win32com.client as win32 warn = lambda app: showwarning(app, "Exit?") RANGE = range(3, 8) def ppoint(): app = 'PowerPoint' ppoint = win32.gencache.EnsureDispatch('%s.Application' % app) pres = ppoint.Presentations.Add() ppoint.Visible = True sl = pres.Slides.Add(1, win32.constants.ppLayoutText) sleep(1) sla = sl.Shapes[0].TextFrame.TextRange sla.Text = 'Python-to-%s Demo' % app sleep(1) slb = sl.Shapes[1].TextFrame.TextRange for i in RANGE: slb.InsertAfter("Line %d\r\n" % i) sleep(1) slb.InsertAfter("\r\nTh-th-th-that's all folks!") warn(app) pres.Close() ppoint.Quit() if __name__ == '__main__': Tk().withdraw() ppoint()
7.4 Outlook
-
不会吧不会吧不会吧,不会还有人用Outlook吧(狗头)
-
特别是中级示例,我一看用的outlook2003,我就想关闭退出一起合成了。
from tkinter import Tk from tkinter.messagebox import showwarning import win32com.client as win32 def warn(app): return showwarning(app, 'Exit?') RANGE = range(3, 8) def outlook(): app = 'Outlook' olook = win32.gencache.EnsureDispatch('%s.Application' % app) mail = olook.CreateItem(win32.constants.olMailItem) recip = mail.Recipients.Add('[email protected]') subj = mail.Subject = 'Python-to-%s Demo' % app body = ["Line %d" % i for i in RANGE] body.insert(0, '%s\r\n' % subj) body.append("\r\nTh-th-th-that's all folks!") mail.Body = '\r\n'.join(body) mail.send() ns = olook.GetNamespace("MAPI") obox = ns.GetDefaultFolder(win32.constants.olFolderOutbox) obox.Display() warn(app) olook.Quit() if __name__ == '__main__': Tk().withdraw() outlook()
8. 扩展Python
-
配置vscode运行c代码,参考链接,参考连接2
-
一键配置环境的工具:VSCodeConfigHelper
-
C程序调试时报错:
Unable to start debugging. Unexpected GDB output from command "-environment -cd xxx",这是因为路径中有中文的原因,所以调试报错。并不影响编译和运行:参考链接- 编译:
gcc -g test.c -o test.exe - 运行:
./test.exe
这里配置真的是太难了,好歹是配好了
- 编译:
-
成功:
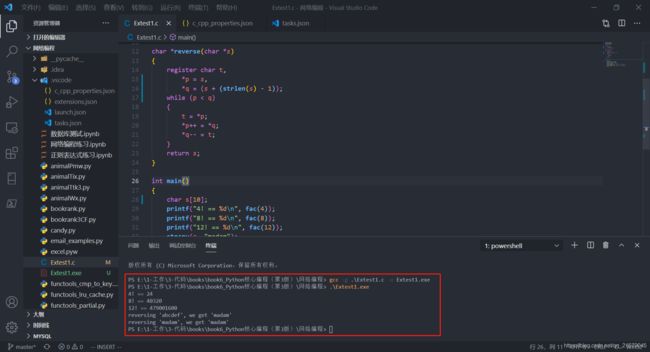
-
我真的不懂这里的
bufsiz是要干嘛,也没定义这个值,我就奇了怪了,不就是定义数组的长度么,你也没传参,也没定义,你传你呢?
-
你这个大括号又是从哪里来的,是我瞎了吗?

-
上面都是我抄代码的经过,遇到这些问题,实在是觉得抄一遍也没用,也没法运行,浪费我的时间,但凡有一点用,我都会抄一遍来着。哎,真心累。
-
常用的编写扩展的工具
- SWIG
- Pyrex
- Cython
- Psyco
- PyPy
- 嵌入Python
9. Web客户端和服务器
9.1 概述
-
SSL:安全套接字层,Secure Socket Layer。为了对传输数据进行加密,需要在普通的套接字(Socket)上添加一个额外的安全层,加密通过该套接字传输的数据。
-
正向代理:通过代理服务器,网络管理员可以只让一部分计算机访问网络,也可以更好地监控网络的数据传输。另一个有用的特征是可以缓存数据,再次访问时,网页的加载速度会快很多。
-
反向代理:反向代理的行为像是有一个服务器,客户端可以连接这个服务器。客户端访问这个后端服务器,接着后端服务器在网上进行真正的操作,获得客户端请求的数据。
-
正向代理用来处理缓存数据,更接近客户端。反向代理更接近后端服务器,扮演服务器端角色,如缓存服务器的数据,、负载平衡等。反向代理服务器还可以用来作为防火墙或加密数据(通过SSL、HTTPS、安全FTP(SFTP)等)。
-
URL:统一资源定位符,Uniform Resource Locator。
-
URI:统一资源标识符,Uniform Resource Identifier。
-
URL是URI的一部分。
-
URN:统一资源名称,Uniform Resource Name,非URL的URI。
-
现在唯一使用URI的只有URL,而很少听到URI和URN,后者只作为可能会用到的XML标识符了。
-
URL的格式:
prot_sch:://net_loc/path;params?query#frag,其中:net_loc可以进一步拆分成多个组件,一些是必备的,另一些是可选的:
user:passwd@host:portURL组件 描述 prot_sch 网络协议或下载方案 net_loc 服务器所在地(也许含有用户信息) path 使用斜杠(/)分割的文件或CGI应用的路径 params 可选参数 query 连接符(&)分割的一系列键值对 frag 指定文档内特定锚的部分 user 用户名 passwd 用户密码 host 运行Web服务器的计算机名称或地址(必须的) port 端口号(如果不是默认的80)
9.2 Web客户端工具
-
from urllib.parse import urlparse, urlunparse, urljoin-
urlparse将urlstr字符串拆分成6个元组urlparse (urlstr, defProtSch=None, allowFrag=None) -
urlunparse的功能与urlparse相反,其将敬urlparse处理的URL生成urltup这个6元组:(prot_sch, net_loc, path, params, query, frag),拼接成URL并返回urlunparse(urltup) -
urljoin取得根域名,并将其根路径与newurl连接起来urljoin (baseurl, newurl, allowFrag=None) -
总结:

-
测试:
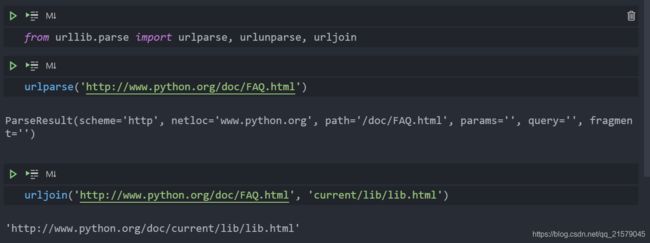
-
-
from urllib.request import urlopen-
urlopen (urlstr, postQueryData=None) -
urlopen打开urlstr所指向的URL。如果没有给定协议或者下载方案(Scheme),或者传入了file方案,urlopen会打开一个本地文件 -
MIME:多目标因特网邮件扩展,Multipurpose Internet Mail Extension,
f.info()方法可以返回MIME头文件,这个头文件通知浏览器返回的文件类型,以及可以用哪些应用程序打开 -
urlopen文件类型对象的方法
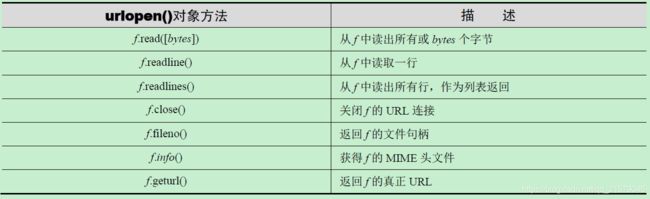
-
-
from urllib.request import urlretrieveurlretrieve(url, filename=None, reporthook=None, data=None)urlretrieve不是用来以文件的形式访问并打开URL,而是用于下载完整的HTML,把另存为文件urlretrieve返回一个二元组(filename, mime_hdrs),filename是含有下载数据的本地文件名,mime_hdrs是Web服务器响应后返回的一系列MIME文件头,对本地文件来说,mime_hdrs是空的
-
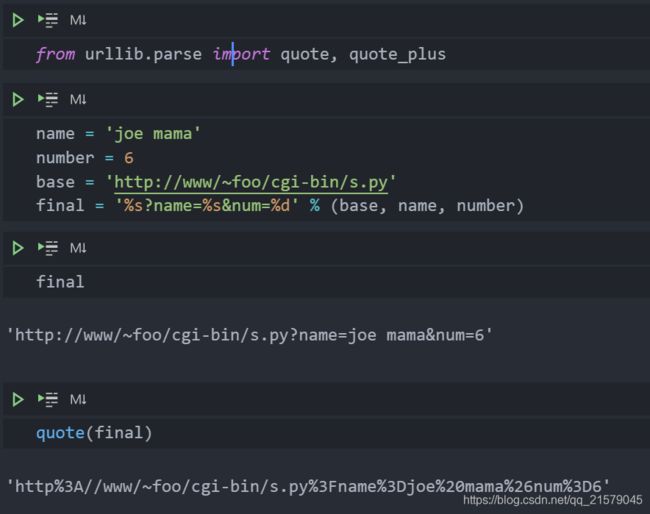
from urllib.parse import quote, quote_plus-
quote(urldata, safe='/') -
quote函数用来获取URL数据,并将其编码,使其可以用于URL字符串中。 -
quote_plus与quote很像,只是它还可以将空格编码成+号 -
测试:
-
-
from urllib.parse import unquote, unquote_plusunquote与quote函数的功能完全相反,前者将所有编码为%xx式的字符转换成等价的ASCII码值unquote(urldate)
-
from urllib.parse import urlencode-
将字典的键值对通过
quote_plus编译成有效的CGI查询字符串,用quote_plus对这个字符串进行编码 -
测试:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NM1vGGos-1619084626151)(E:\typora_pics_savepath\image-20210305145335998.png)]
-
-
urllib.parse和urllib.request函数总结:
9.3 Web客户端
-
SGML:标准通用标记语言,Standard Generalized Markup Language
-
__slots__:正常情况下,当我们定义了一个class,创建了一个class的实例后,我们可以给该实例绑定任何属性和方法。但是,如果我们想要限制实例的属性怎么办?为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的slots变量,来限制该class实例能添加的属性。- slots 存在的真正原因是用于优化,否则我们是以*dict*来存储实例属性,如果我们涉及到很多需要处理的数据,使用元组来存储当然会节省时间和内存。
- 如果我们还是想要有可以随意添加实例属性,那么把
__dict__放入__slots__中既可,实例会在元组中保存各个实例的属性,此外还支持动态创建属性,这些属性存储在常规的__dict__中。优化完全就不见了。
-
BeautifulSoup的简单应用
from html.parser import HTMLParser from io import StringIO from urllib.request import urlopen, urlparse from urllib.parse import urljoin from bs4 import BeautifulSoup, SoupStrainer from html5lib import parse, treebuilders URLs = ( 'http://python.org', 'http://google.com', ) def output(x): print('\n'.join(sorted(set(x)))) def simpleBS(url, f): # simpleBS(): use BeautifulSoup to parse all tags to get anchors output(urljoin(url, x['href']) for x in BeautifulSoup(f).findAll('a')) def fasterBS(url, f): # fasterBS(): use BeautifulSoup to parse only anchor tags output(urljoin(url, x['href']) for x in BeautifulSoup(f, parse_only=SoupStrainer('a'))) def htmlparser(url, f): # htmlparser(): user HTMLParser to parse anchor tags class AnchorParser(HTMLParser): def handle_starttag(self, tag, attrs): if tag != 'a': return if not hasattr(self, 'data'): self.data = [] for attr in attrs: if attr[0] == 'href': self.data.append(attr[1]) parser = AnchorParser() parser.feed(f.read()) output(urljoin(url, x) for x in parser.data) def html5libparse(url, f): # html5libparse(): use html5lib to parse anchor tags output(urljoin(url, x.attributes['href']) for x in parse(f) if isinstance(x, treebuilders.simpletree.Element) and x.name=='a') def process(url, data): print('\n*** simple BS') simpleBS(url, data) data.seek(0) print('\n*** faster BS') fasterBS(url, data) data.seek(0) print('\n*** HTMLParser') htmlparser(url, data) data.seek(0) print('\n*** HTML5lib') html5libparse(url, data) def main(): for url in URLs: f = urlopen(url) data = StringIO(f.read()) f.close() process(url, data) if __name__ == '__main__': main() -
Mechanize:可以编程的Web浏览方式
10. Web编程:CGI和WSGI
10.1 CGI简介
-
Web 最初目的是在全球范围内对文档进行在线存储和归档。这些文件通常用静态文本表示,一般是HTML。
-
CGI:Common Gateway Interface,公共网关接口。
-
表单:成为了Web站点从用户获得特定信息的唯一形式(在Java applet出现之前)
-
CGI工作方式概览

-
若想要在浏览器中看到的是Web应用程序的回溯消息,而不是“内部服务器错误”,可以使用cgitb模块。
import cgitb cgitb.enable()
10.2 WSGI简介
-
为什么需要CGI:
因为服务器无法创建动态内容,它们不知道用户特定的应用信息和数据,如验证信息、银行账户、在线支付等。Web服务器必须与外部的进程通信才能处理这些自定义工作。
-
CGI的局限:
- CGI方式无法扩展,CGI进程针对每个请求进行创建,用完就抛弃。
- 如果应用程序接受数千个请求,创建大量的语言解释器进程很快就会导致服务器停机。
- 有两种方法可以解决这个问题:一是服务器集成;而是外部进程。
-
服务器集成,也成为服务器API。
-
服务器根据对应的API 通过一组预先创建的进程或线程来处理工作。
-
缺点:对于服务器API,这种方式会带来许多问题,如含有bug 的代码会影响到服务器实现执行效率,不同语言的实现无法完全兼容,需要API 开发者使用与Web 服务器实现相同的编程语言,应用程序需要整合到商业解决方案中(如果没有使用开源服务器API),应用程序必须是线程安全的,等等。
-
-
外部进程
- 这是让CGI 应用在服务器外部运行。当有请求进入时,服务器将这个请求传递到外部进程中。这种方式的可扩展性比纯CGI 要好,因为外部进程存在的时间很长,而不是处理完单个请求后就终止。
- 有了外部进程,就可以利用服务器API 的好处,同时避免了其缺点。比如,在服务器外部运行就可以自由选择实现语言,应用程序的缺陷不会影响到Web 服务器,不需要必须与闭源的商业软件结合起来。
-
WSGI:Web Server Gateway Interface,Web服务器网络接口。WSGI 不是服务器,也不是用于与程序交互的API,更不是真实的代码,而只是定义的一个接口。
-
中间件:在某些情况下,除了运行应用本身之外,还想在应用执行之前(处理请求)或之后(发送响应)添加一些处理程序。这就是熟知的中间件,它用于在Web 服务器和Web 应用之间添加额外的功能。
中间件要么对来自用户的数据进行预处理,然后发送给应用;要么在应用将响应负载返回给用户之前,对结果数据进行一些最终的调整。这种方式类似洋葱结构,应用程序在内部,而额外的处理层在周围。
-
Web编程相关模块


11. Web框架:Django
11.1 Django简介
-
SQLite:SQLite 数据库适配器是所有Python 版本中自带的。
-
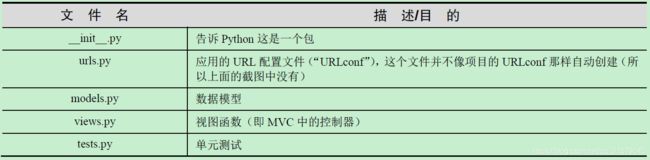
Django项目文件:

-
Django应用文件
-
使用
django-admin startproject 项目名称创建项目 -
使用
python manage.py startapp app名称来创建app -
在
settings.py文件中的INSTALLED_APPS中添加app名,来告诉django这个新应用是项目的一部分INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog', ] -
数据模型表示将会存储在数据库每条记录中的数据类型。BlogPost 中的字段就像普通的类属性那样定义,每个都是特定字段类的实例,每个实例对应数据库中的一条记录。
- 除了三个字段外,还有一个Django默认自动创建的字段,该字段可以自增
CharField:用于较短的单行文本TextField:用于较长的文本,比如博文的正文DateTimeField:时间戳
class BlogPost(models.Model): title = models.CharField(max_length=150) body = models.TextField() timestamp = models.DateTimeField() -
SQLite 一般用于测试。它甚至可以用于特定环境下的部署,如应用于无须大量同时写入
需求的场景。SQLite 没有主机、端口、用户,或密码信息。因为SQLite 使用本地文件来存储数据,本地文件系统的访问权限就是数据库的访问控制。SQLite 不仅可以使用本地文件,还可以使用纯内存数据库。因此针对SQLite 数据库的配置,在settings.py 中的DATABASES配置中只有ENGINE 和NAME 字段。 -
python manage.py syncdb是迁移数据库的命令,当执行这个命令后,Django会查找INSTALLED_APPS中列出的应用的models.py文件。对于每个找到的模型,它会创建一个数据库表。如果使用的是SQLite,会注意到mysite.db这个数据文件刚好创建在设置中指定的文件夹里。现在已改为
python manage.py migrate,于django2.0之后失效 -
django创建超级用户:https://www.cnblogs.com/nanjo4373977/p/12880967.html
python manage.py createsuperuser -
在django中使用python shell:
python manage.py shell;如果不想进入ipython的话,可以指定对应的解析器:python manage.py shell -i python -
在
admin.py中给app注册,这样admin就可以管理数据库中app的对象from django.contrib import admin from blog import models admin.site.register(models.BlogPost) -
如果admin看不到app可能出现的情况:
- 忘记通过
admin.site.register()注册模型类 - 应用的
models.py文件中存在错误 - 忘记将应用添加到
settings.py文件中的INSTALLED_APPS元组中
- 忘记通过
-
有效的显示应用的列表
from django.contrib import admin from blog import models class BlogPostAdmin(admin.ModelAdmin): list_display = ('title', 'timestamp') admin.site.register(models.BlogPost, BlogPostAdmin) -
Django是如何处理请求的:Django 自底向上 处理请求,它首先查找匹配的URL模式,接着调用对应的视图函数,最后将渲染好的数据通过模板展现给用户。
-
Django中的 测试驱动模型(TDD),构建应用的顺序:
- 创建基本的模板(需要一些可以观察的内容)
- 设计一个简单的URL模式,让Django可以立刻访问应用
- 开发出一个视图函数原型,然后在此基础上迭代开发
使用这个顺序的主要原因是因为模板和URL模式不会发生较大的改变。而应用的核心是视图,所以先快速构建一个基本视图,在此基础上逐步完善。
-
变量标签:
{ { post.title }}
-
过滤器:
{ { post.title|title }}
.title()方法 -
块标签:
{% endfor %},表示循环 -
注意:这里的archive视图函数的context一定记住了,要写
:而不是,,不要犯我这样的低级错误,不然会报错:unhashable type: 'list'from django.shortcuts import render, HttpResponse from datetime import datetime from blog.models import BlogPost # Create your views here. def archieve(request): mypost = BlogPost(title='mocktitle', body='mockbody', timestamp=datetime.now()) data = { 'posts': [mypost] } return render(request, 'archive.html', context={ 'posts': [mypost]}) -
我们常常用的是class.objects.all()方法来获取QuerySet,可以认为QuerySet是数据库中的每行数据,但其实QuerySet不是真实的每一行数据,因为QuerySet执行”惰性迭代“,只有在求值的时候才会真正查询数据库。换句话说,QuerySet可以进行任何操作,但并没有接触到数据。
-
设置模型的默认排序方式:在models中新增一个内部类:
class Meta: ordering = ('-timestamp',) -
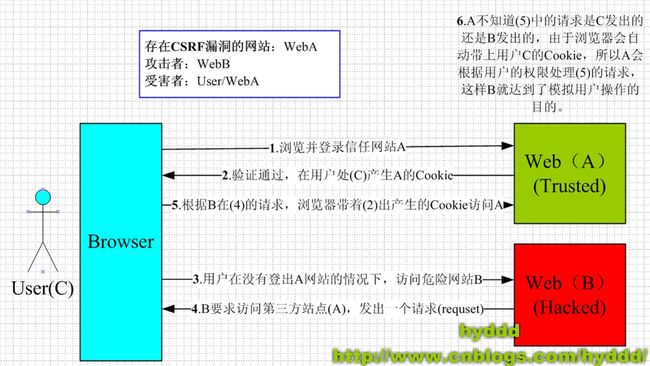
Django有数据保留特性。这不允许不安全的POST通过 跨站点请求伪造 (Cross-Site Request Forgery,CSRF)来进行攻击。参考链接,参考链接2
为了解决这个问题,需要在表单中添加CSRF标记:
{% csrf_token %} -
使用ModelForm 来生成HTML 表单:
-
models:新增BlogPostForm类
exclude是指:不额外生成timestamp的属性,保留原有的,即从生成的HTML 中
移除这个表单项。from django.db import models from django import forms class BlogPost(models.Model): title = models.CharField(max_length=150) body = models.TextField() timestamp = models.DateTimeField() class Meta: ordering = ('-timestamp',) class BlogPostForm(forms.ModelForm): class Meta: model = BlogPost exclude = ('timestamp', ) -
views:新增一个form键值对,指向models中的类
这里可以直接通过类获取request中的post中的相关类信息,由于timestamp的原因,所以只能先获取部分类属性,再更新timestamp属性,最后保存。
# archive = lambda req: render(req, 'archive.html', {'posts': BlogPost.objects.all()[11:20]}) archive = lambda req: render(req, 'archive.html', { 'posts': BlogPost.objects.all()[11:20], 'form': BlogPostForm()}) def create_blogpost(request): if request.method == 'POST': # BlogPost(title=request.POST.get('title'), body=request.POST.get('body'), timestamp=datetime.now(),).save() form = BlogPostForm(request.POST) if form.is_valid(): post = form.save(commit=False) post.timestamp=datetime.now() post.save() return redirect('/blog/') -
templates:将原来表单的格式换成
<form action="/blog/create/" method="post"> {% csrf_token %} <table>{ { form }}table><br> <input type=submit> form> <hr> -
如果不想用HTML表格的行和列的形式输入,也可以通过
as_*()的方法输出。比如{ {form.as_p}}会以...
{ { form.as_ul }}会以列表元素显示等等。
-
-
在url中配置redirect_to或者RedirecView,参考链接
urlpatterns = [ path('', RedirectView.as_view(url='/blog/')), path('admin/', admin.site.urls), path('blog/', include('blog.urls')), ]
11.2 单元测试
-
在创建应用时,Django通过自动生成
test.py文件来促使开发者创建测试from django.test import TestCase from django.test.client import Client from datetime import datetime from blog.models import BlogPost class BlogPostTest(TestCase): def test_obj_create(self): """通过测试确保对象成功创建,并验证标题的内容""" BlogPost.objects.create(title='raw title', body='raw body', timestamp=datetime.now()) self.assertEqual(1, BlogPost.objects.count()) self.assertEqual('raw title', BlogPost.objects.get(id=1).title) def test_home(self): """检测用户界面""" response = self.client.get('/blog/') self.failUnlessEqual(response.status_code, 200) def test_slash(self): """检测用户界面""" response = self.client.get('/') self.assertIn(response.status_code, (301, 302)) def test_empty_create(self): """测试某人在没有任何数据就错误地生成GET 请求这样的情形,代码应该忽略这个请求,并重定向""" response = self.client.get('/blog/create/') self.assertIn(response.status_code, (301, 302)) def test_post_create(self): """模拟真实用户请求通过POST发送真实数据""" response = self.client.post('/blog/create/', { 'title': 'post title', 'body': 'post body', }) self.assertIn(response.status_code, (301, 302)) self.assertEqual(1, BlogPost.objects.count()) self.assertEqual('post title', BlogPost.objects.get(id=1).title) -
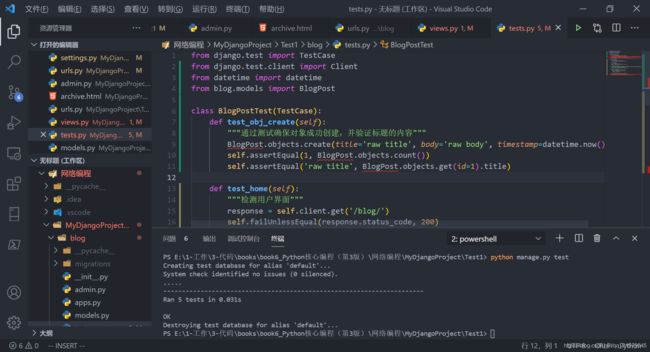
调用测试:
python manage.py test -
测试结果:
-
默认情况下,系统会创建独立的内存数据库(default)进行测试,所以无需担心测试会损坏实际生产数据。其中的每个点表示通过了一个测试。对于未通过测试的,
E表示错误,F表示失败。
12. 云计算:Google App Engine
-
云计算的三个层次
- IaaS:Infrastructure-as-a-Service,即提供计算机本身基本的计算能力(物理形式或虚拟形式)、存储(通常是磁盘)、计算。
- PaaS:Platform-as-a-Service,这一层为用户的应用提供执行平台。
- SaaS:用户只需简单地访问应用,这些应用位于本地,但只能通过因特网访问。

写在最后
后面的内容我也在仔细看,也努力尝试敲代码,自己实现一遍,相信我,后面的知识很有学习的意义,但作者的水平及翻译的水平使得这种意义大打折扣(12、13、14、15章)。讲道理外国人写的书,特别是里面的实现,不是很适合我们直接学习,一个是链接打不开,一个是Facebook啊Twitter啊我们用不了(科学上网也没必要对吧)。还有一点是,每一章节之间并不是解耦的,有的章节会用到之前章节的代码,就离谱。
附录
A Python关键字

B Python标准操作符和函数
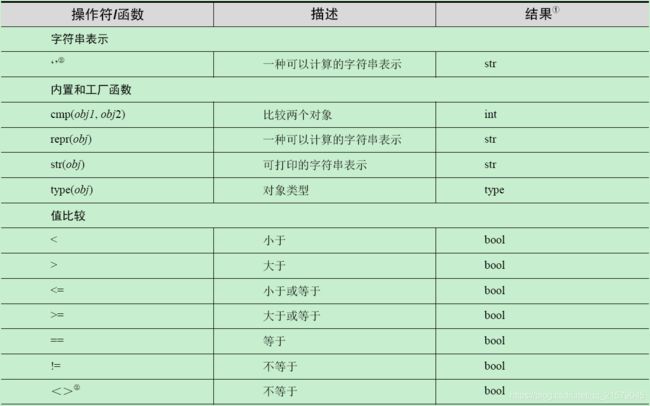

C 数值类型操作符和函数


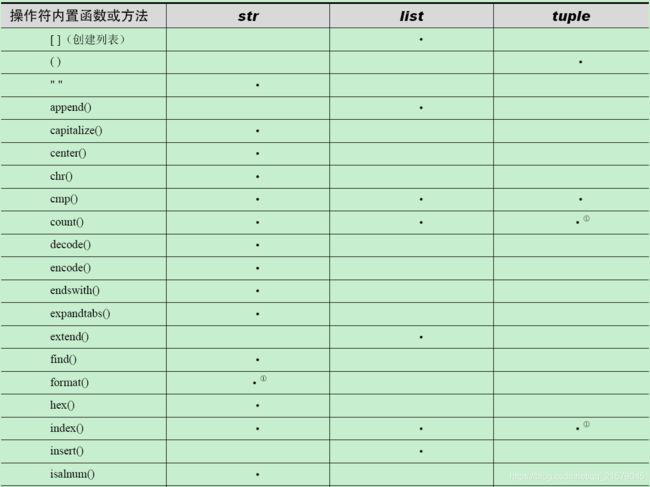
D 序列类型操作符和函数



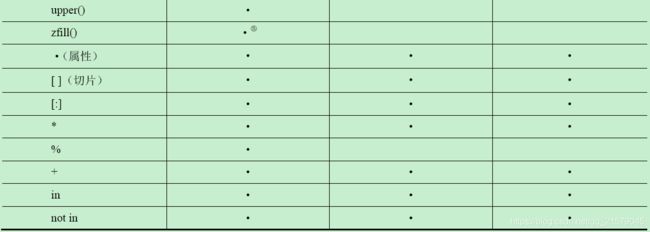
E 字符串格式化操作符转换符号
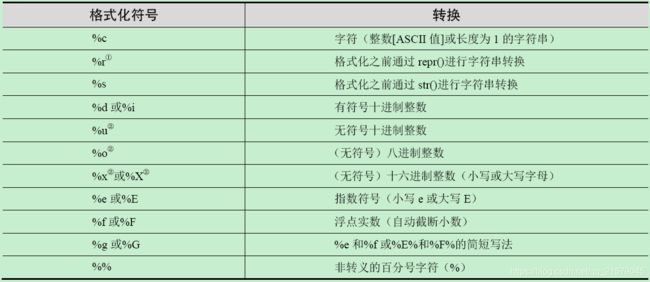
F 字符串格式化操作符指令

G 字符串类型内置方法
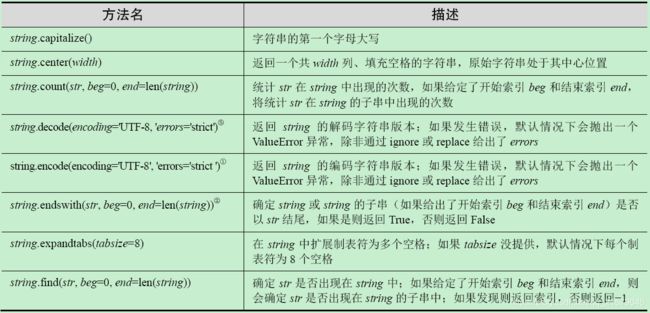

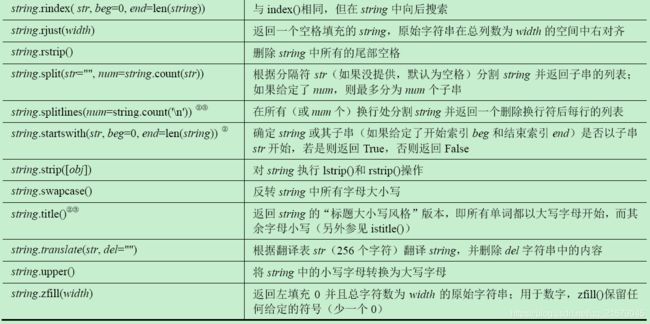
H 列表类型内置方法
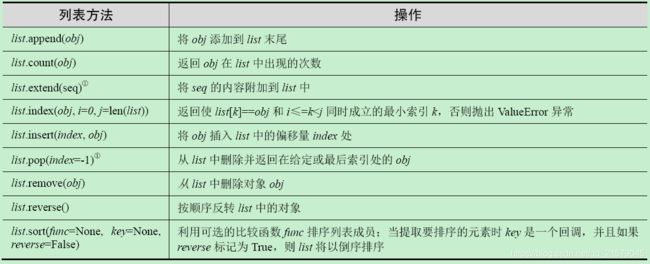
I 字典类型内置方法
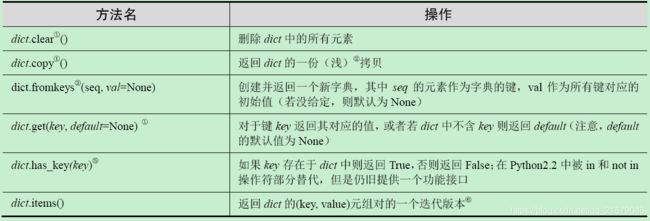
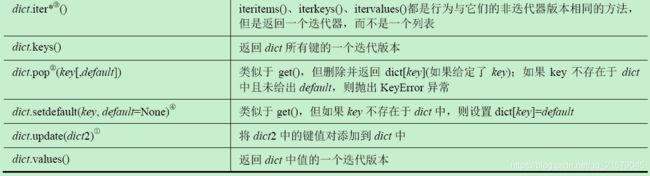
J 集合类型操作符和内置函数


K 文件对象方法和数据属性

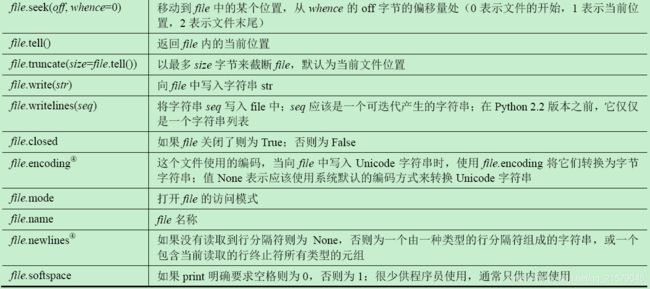
L Python异常

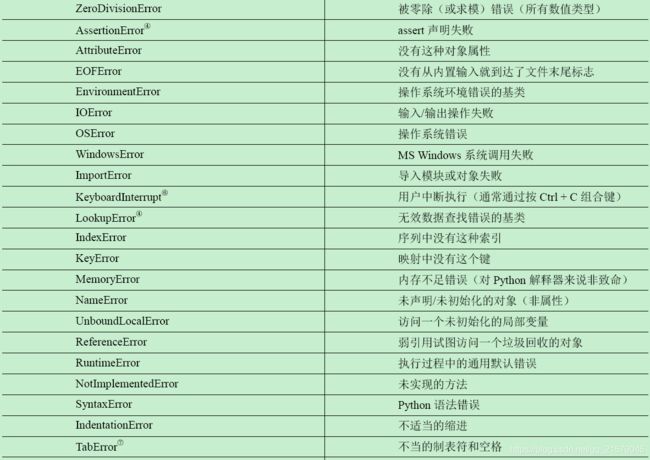
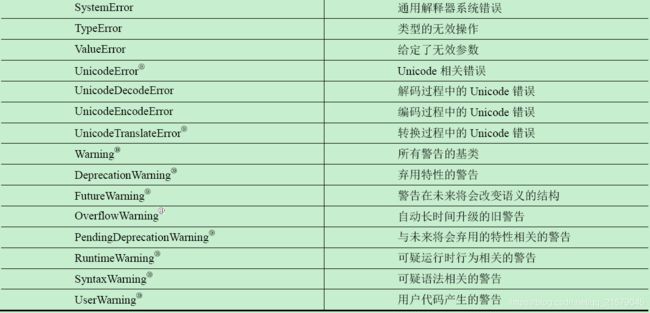
M 类的特殊方法
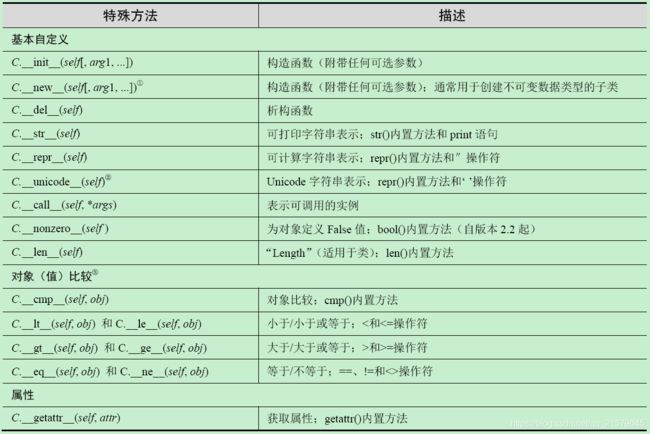

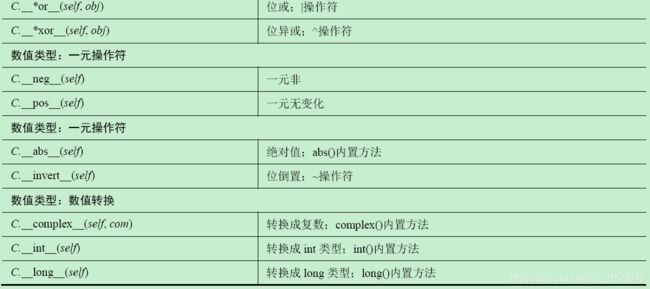

![]()
N Python操作符汇总
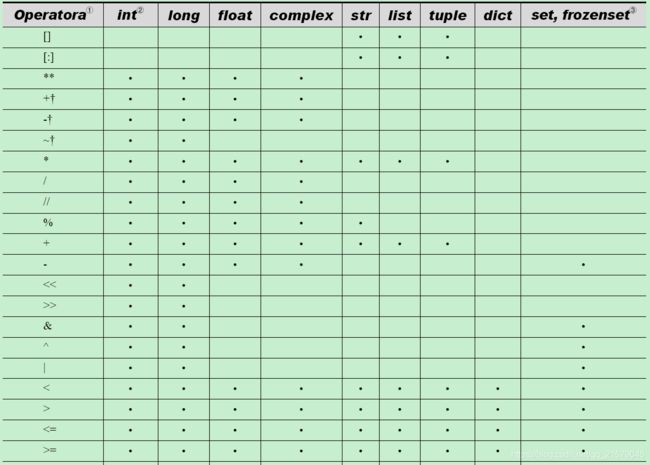
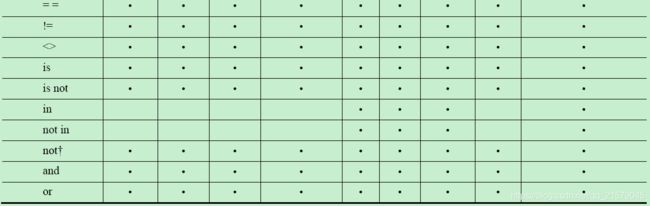
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友