LeNet图像分类网络一(Pytorch)
原文档地址:https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html#neural-networks
从官方给的文档开始学起,搭建出下图中的卷积神经网络,代码有很多不懂的地方,查过之后都做了注释,希望和大家一起交流学习。
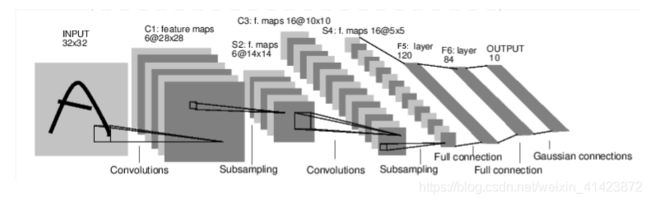
############################搭建一个神经网络######################################
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim #更新网络权重的时候用
class Net(nn.Module): #定义一个类,这个类是从nn.Moudle继承而来的
def __init__(self): #类的构造函数
super(Net, self).__init__() #子类继承所有父类的属性和方法,而且用父类的初始化方法初始化继承的属性
# 1 input image channel, 6 output channels, 3x3 square convolution
#一个图像输入通道,6个输出通道,3*3的卷积核,输入的图像是32*32*1的
#一般把网络中具有可学习参数的层放在构造函数__init__()中,这里就是两个卷积层和三个全连接层
#不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
#本例中的两个池化层和两个激活函数就放在了forword中
# kernel核函数
self.conv1 = nn.Conv2d(1, 6, 5) #卷积层1,6个5*5*1的卷积核(输入深度为1,输出深度为6)
self.conv2 = nn.Conv2d(6, 16, 5) #卷积层2,16个5*5*6的卷积核(输入深度为6,输出深度为16)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 6*6 from image dimension
# 全连接层1 权重系数为16*6*6*120,将16*5*5个节点连接到120个节点上
self.fc2 = nn.Linear(120, 84) #全连接层2 权重系数为120*84,将120个节点连接到84个节点上
self.fc3 = nn.Linear(84, 10) #全连接层3 权重系数为84*10,将84个节点连接到10个节点上
#定义该神经网络的向前传播函数,该函数必须定义,一旦定义成功,向后传播函数也会自动生成(autograd)
def forward(self, x): #定义一个类的方法,前向传播
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) #最大池化层1,滑动窗口的大小为2*2
#x经过卷积层1之后,再激活,再输入到池化层1,最后更新x
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2) #最大池化层2,滑动窗口的大小为2*2
#x经过卷积层2之后,再激活,再输入到池化层2,最后更行x
x = x.view(-1, self.num_flat_features(x)) #view函数将张量x变形成一维的向量形式,总特征数并不改变,为接下来的全连接作准备
x = F.relu(self.fc1(x)) #经过全连接层1,再激活,再更新x
x = F.relu(self.fc2(x)) #经过全连接层2,再激活,再更新x
x = self.fc3(x) ##输入x经过全连接3,然后更新x
return x
# 使用num_flat_features函数计算张量x的总特征量(把每个数字都看出是一个特征,即特征总量),比如x是4*2*2的张量,那么它的特征总量就是16。
def num_flat_features(self, x): #定义一个类的方法
size = x.size()[1:] # all dimensions except the batch dimension,第一维是输入图片的数量
# 这里为什么要使用[1:],是因为pytorch只接受批输入,也就是说一次性输入好几张图片,
# 那么输入数据张量的维度自然上升到了4维。【1:】让我们把注意力放在后3维上面
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
#看一下需要训练的参数的数量
params = list(net.parameters()) #返回可被学习的参数(权重)的列表和值
print(len(params)) #输出需要训练的参数的个数
print(params[0].size()) # conv1's .weight,输出卷积层1的权重,通过修改【】中的数字也可以输出其他层的权重
#做一个测试
input = torch.randn(1, 1, 32, 32) #输入一个单通道的随机的32*32矩阵
out = net(input)
print(out) #输出结果
#用随机梯度将所有参数和反向传播器的梯度缓冲区归零
net.zero_grad()
out.backward(torch.randn(1, 10))
##################损失函数部分,损失函数用来表示结果的准确性,这里用的是均方差#####################
output = net(input)
target = torch.randn(10) # a dummy target, for example,指定了一个随机的真值
target = target.view(1, -1) # make it the same shape as output,将他的格式改成和网络的输出相同
criterion = nn.MSELoss() #定义损失函数的类型
loss = criterion(output, target) #计算损失
print(loss) #输出损失
关于特征图大小的计算:

卷积层和池化层都是这个公式,不过卷积层的默认步长是1,池化层的默认步长是滑动窗口的边长
参考资料:https://www.cnblogs.com/CATHY-MU/p/7760570.html