在工作的项目中使用到了阿里的开源工具Arouter作为页面跳转路由,这里记录一下自己对于该框架使用一次跳转的研究。
首先附上github链接GitHub - alibaba/ARouter: An android router middleware that help app navigating to activities and custom services.,对于Arouter的适用性、优点和用法可以自行了解。
在项目中加入了Arouter跳转的代码后,运行项目,首先你会发现一些清单文件,位置在/build/generated/source/apt/release/com/alibaba/android/arouter/routes/下:
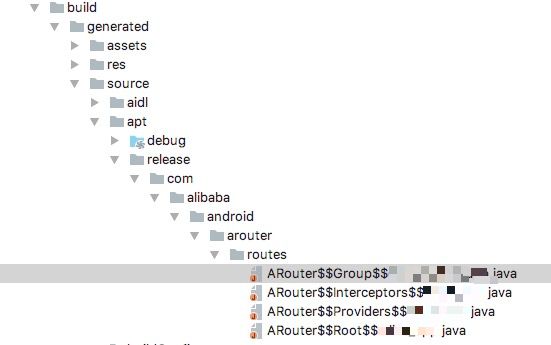
这里的几个类分别实现了不同的接口,IRouteGroup、IInterceptorGroup、IProviderGroup、IRouteRoot,这里我们以页面的跳转分析为主,点开IRouteRoot、IRouteGroup的实现类,你会发现它们都在loadInto方法对传入的容器填充了一些数据,在IRouteRoot的实现类中传了IRouteGroup实现类的类名,在IRouteGroup实现类中传入了一个封装的RouteMeta的对象:
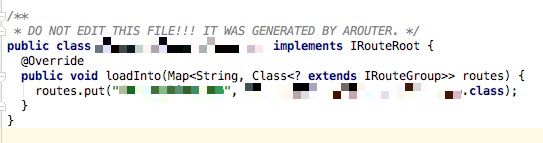
仔细一看每个RouteMeta的参数是不是很熟悉?里面出现了你已配置路径的页面名以及注解@Route中设置的path值:

其实在开发者配置完成后,ARouter会生成这些清单文件,在调用初始化方法init时会去加载这些清单文件,将配置的页面缓存起来,同时你也已经发现在loadinfo方法中体现的调用关系是存在root、group这些概念的。
如果你已经了解过Arouter,一定知道Arouter的一个特点:
映射关系按组分类、多级管理,按需初始化
在这里按组分类、多级管理其实已经体现出来了。
看完了清单文件,我们从Arouter的初始化开始入手:
ARouter.init(application);
往下查看,我们发现其实是调用了
_ARouter.init(application)
最终加载清单文件是LogisticsCenter.init方法中实现,关键代码如下:

首先我们按照正常的rlease版本的流程,进入else的代码块,这里发现routerMap是从数据库里面拿出来的,接来下对routerMap的内容className做循环判断,这里className的三个判断条件其实分别是:
ROUTE_ROOT_PAKCAGE +DOT +SDK_NAME +SEPARATOR +SUFFIX_ROOT:
com.alibaba.android.arouter.routes.ARouter$$Root
ROUTE_ROOT_PAKCAGE +DOT +SDK_NAME +SEPARATOR +SUFFIX_INTERCEPTORS:
com.alibaba.android.arouter.routes.ARouter$$Interceptors
ROUTE_ROOT_PAKCAGE+DOT +SDK_NAME +SEPARATOR +SUFFIX_PROVIDERS:
com.alibaba.android.arouter.routes.ARouter$$Providers
找到了清单文件类之后传入了Warehouse类中的成员变量并表用loadInfo方法,到此初始化已经结束,再进入Warehouse中瞧一瞧:
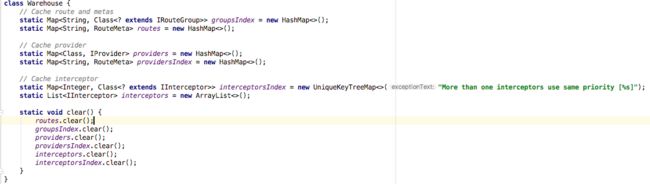
可见对于页面来说,清单的配置最后被缓存到了WareHouse这个类,页面只缓存到了节点不做下级的加载,这也就是之前说的按需加载,这里只存到了类名并没有把节点全部缓存下来。
在发起一个页面跳转的请求的时,所有的请求都被封装成了一个Postcard对象,我们先来看看这个对象如何生成的,最开始Arouter调用的是build方法:

_Arouter的build方法返回了一个新的Postcar对象:

看看这个PathReplaceService是如何生成的,顺着navigation方法往下看,最后在_Arouter的navigation的方法中返回

这里在buildProvider中会对IRouterProvider的缓存中查询是否注册了对应的provider,仅仅只做页面跳转这里可以不用注册,那么整个方法会抛出异常,在catch块中返回null。那么在build中则会进入build(path, extractGroup(path))方法:

在这个方法中,由上面的分析可知这里的pService为空,所以最简单的情况就是返回一个新的由path和group决定的Postcard。
再进行跳转时,将会调用Postcard的navigation方法,最终是将自己传入了_Arouter的navigation方法中:
protected Object navigation(final Context context,final Postcard postcard,final int requestCode,final NavigationCallback callback)
在该方法中首先调用了LogisticsCenter.completion(postcard),这方法比较长,一段一段来看,其实这是个注册Postcard的方法:

首先从Root容器中去查找有没有对应的内容,从我们之前的加载过程中看是肯定找不到的,那么第二步则从Group中去找,找到了之后则把页面的内容加载到routes容器中,这里是通过之前init缓存的类名找到对应的Group,然后调用Group的loadInfo方法缓存具体的每个节点,也就是到了要使用的时候再加载具体的节点,loadInfo是最开始清单文件中IRouterGroup实现类的方法,具体的填充过程看一下就知道了,再重新reload。
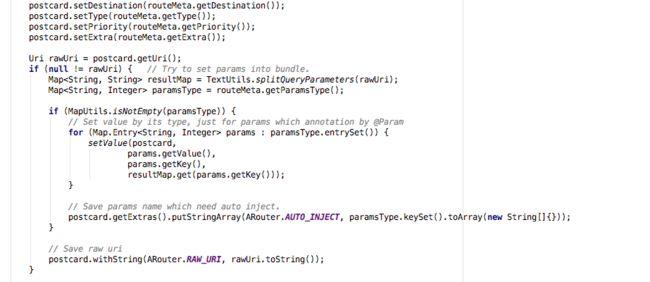
else代码块里对于已经缓存的内容,则把相应的属性填入Postcard中,也就是把routeMeta转化为Postcard

在最后会对routeMeta的类型做判断,在清单文件类中,new reoutMeta时会将页面的类型传入,所以这里是可以判断的。
在LogisticsCenter.completion(postcard)完成之后接着判断是否走的是绿色通道greenChanel(跳过所有的拦截器):

我们先看跳过拦截器的else内的代码块,接着调用_navigation()方法:
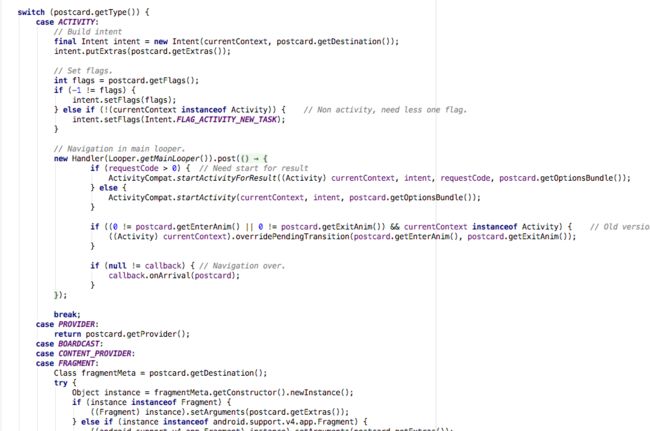
可见跳转的地方就在这里啦,在回到之前是否走绿色通道的逻辑,如果是不跳过拦截器,则会调用interceptorService.doInterceptions(postcard,new InterceptorCallback()),这里interceptorService是一个接口,我们找到它的实现类com.alibaba.android.arouter.core.InterceptorServiceImpl瞧一瞧doInterceptions()方法:

着这个方法中首先会判断是否注册了拦截器被缓存进来,拦截器的缓存也是在init的操作中已经做过的,如果有的话则开启一个线程,这里拦截器相关都是异步的,因为拦截器的操作可能非常耗时,其中_excute()方法是拦截器操作的地方,接着看下去:

根据index依次取出拦截器,并调用process()方法,而当我们定义一个拦截器的时候,最重要的便是重写IInterceptor的process()方法,那么到这里拦截器是如何运作已经一目了然了:
还有一个问题,拦截器是有优先级的,这里又是怎么按照优先级拦截,如果断开后续拦截又是怎么断开的,首先我们看在代码中定义的拦截器,这里使用了注解去定义该拦截器的优先级:
在清单文件中加载拦截器时会将该优先级作为key填充到容器中:

在_excute()方法中从缓存中调用拦截器是从index=0作为索引开始的,如果继续拦截则在continue中使index+1并递归,这样就实现了按照优先级拦截:
在清单文件中拦截器的加载说明Warehouse中interceptorsIndex存储的内容以拦截器的优先级作为key,拦截器的类名作为value,并且interceptorsIndex是一个TreeMap,而拦截器具体的类在使用的时候是从interceptors中加载过来的,这其实是在InterceptorServiceImpl中完成的,在_Arouter完成init之后马上会调用一次afterInit():
interceptorService = (InterceptorService) ARouter.getInstance().build("/arouter/service/interceptor").navigation();
到最后会走到LogisticsCenter.completion()方法,在之前我们发现这个方法最后会对routMeta的类型做判断:
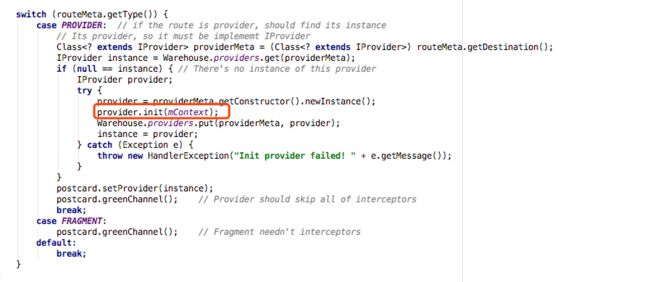
当判断为IProvider接口类型时会调用init的方法,回到InterceptorServiceImpl你会发现这个类实现了InterceptorService接口,而InterceptorService又继承自IProvider接口,那么很明显了,看看InterceptorServiceImpl的init()方法:

Warehouse.interceptors的填充就在这里了。