线性回归模型结合疫情实战
python环境搭建:
下载地址:https://www.anaconda.com/products/individual


安装pycharm:https://www.jetbrains.com/pycharm/download/

python基础语法学习:
具体学习可以去:https://www.runoob.com/python/python-tutorial.html
元组不可更新,列表允许更新
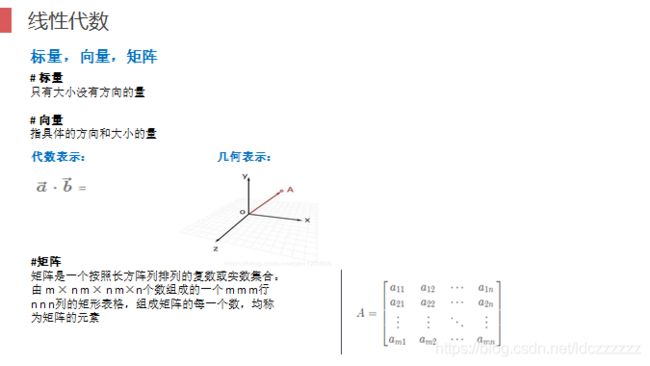
数学基础
- 线性代数



python3个主要库:
- Numpy
主要应用科学计算,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
官网:http://www.numpy.org/
import numpy as np
# 一维数组
a = np.array([1, 2, 3])
# 二维数组
b = np.array([[3, 4, 5],
[1,2,3]])
# 从1到100平均生产10个数,包含右区间
c = np.linspace(1,100,10)
# 从2到20每隔3个生成一个数,不包含右区间
d = np.arange(2,20,2)
# 随机数,从0到100,随机生成10个数
f = np.random.randint(0,100,10)
# 随机数,从0到100,随机生成4行5列
e = np.random.randint(0,100,(4,5))
# 浮点数,默认从0到1
h = np.random.random(10)
# array类型
j = np.shape(b)
# 个数
size = np.size(b)
# 数据类型
dt = a.dtype
# 取值,表示a数组第1个数
a0 = a[0]
# 切片
b0 = b[1:,2:]
# 倒序
i = e[::-1,::-1]
# 行列从新排
m = e.reshape(5,-1)
# 按列求和 axis=0按列,axis=1按行
s = b.sum(axis=0)
# 平均值
avg = b.mean()
# 开方
sq = np.sqrt(b)
# 标准差
st = np.std(a)
# e为底的指数
ex = np.exp(10)
# 对数,e为底
lo = np.log(10)
- Panada
主要用于数据分析问题
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
官方文档:https://www.pypandas.cn/
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典
import pandas as pd
import numpy as np
# 使用字典创建DataFrame
dict = {
'zhangsan': [70,90,60], 'lisi': [80,98,99]}
a = pd.DataFrame(data=dict,index=['语文','数学','英语'])
# 使用numpy创建DataFrame
b = pd.DataFrame(np.random.randn(6, 4), index=("a","b","4","c","6","7"), columns=list('ABCD'))
# 取头部数据
h = b.head(3)
# 取尾部数据
t = b.tail(3)
# 索引
i = b.index
# 列名
j = b.columns
# 排序 按列,降序
s = a.sort_index(axis=1,ascending=True)
# 按 列名 A,升序排序
s1 = b.sort_values(by='A')
- Matplotlib
Python 的绘图库
官方文档:https://matplotlib.org/stable/tutorials/index.html
demo展示:
https://live.csdn.net/v/156412
基本处理步骤:
- 读取疫情数据
- 提取要预测的数据,并保存,demo的数据比较规范,这里不需做数据预处理,如果数据杂乱,要先数据预处理
- 先把数据图形展示,分析是否符合线性关系
- 建立模型,假设是线性回归算法
- 训练模型
- 预测
- 绘图,用不同颜色,检查是否拟合
- 图一明显不拟合
- 更换模型,考虑多项式回归算法,再执行4,5,6,7步骤
10.图二显示已经几乎重合,说明拟合

(图一)

(图二)
核心代码
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
France = []
# 读数据
with open(file="owid-covid-data.csv", mode='r', encoding='utf-8') as f:
data = f.readlines()
for line in data:
field = [item for item in line.split(',')]
if field[2] == 'France':
France.append(field[4])
France = np.array(France, dtype=np.float).astype(int)
# 保存数据
np.savez('covid-france', France=France)
# print(France)
X = np.arange(np.size(France)).reshape(-1, 1)
# 建立模型
mode = LinearRegression()
# 训练模型
mode.fit(X, France)
# 预测
Y = mode.predict(X)
# print(mode.coef_)
# print(mode.intercept_)
# y1 = 1279.79635979*X -49970.12661520863
# 画图
plt.scatter(X, France)
plt.plot(X, Y, color='r')
# plt.plot(X, y1, color='g')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
data = np.load('covid-france.npz')
France = data['France']
# print(France)
X = np.arange(np.size(France)).reshape(-1, 1)
# z = (x - u) / s
# 建立模型
Poly_Fe = Pipeline(steps=[('poly', PolynomialFeatures(degree=20)), # 特征扩展
('St_sc', StandardScaler()), # 归一化(x-均值)/方差
('lr', LinearRegression())]) # 线性回归
# 训练模型
Poly_Fe.fit(X, France)
# 预测
y = Poly_Fe.predict(X)
# 画图
plt.scatter(X, France)
plt.plot(X, y, color='r')
plt.show()