ARIMA模型
原文地址:http://www.jianshu.com/p/f547bb4b50c3
本文结构:
- 时间序列分析?
- 什么是ARIMA?
- ARIMA数学模型?
- input,output 是什么?
- 怎么用?-代码实例
- 常见问题?
时间序列分析?
时间序列,就是按时间顺序排列的,随时间变化的数据序列。
生活中各领域各行业太多时间序列的数据了,销售额,顾客数,访问量,股价,油价,GDP,气温。。。
随机过程的特征有均值、方差、协方差等。
如果随机过程的特征随着时间变化,则此过程是非平稳的;相反,如果随机过程的特征不随时间而变化,就称此过程是平稳的。
下图所示,左边非稳定,右边稳定。
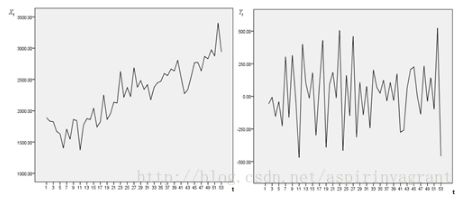
非平稳时间序列分析时,若导致非平稳的原因是确定的,可以用的方法主要有趋势拟合模型、季节调整模型、移动平均、指数平滑等方法。
若导致非平稳的原因是随机的,方法主要有ARIMA(autoregressive integrated moving average)及自回归条件异方差模型等。
什么是ARIMA?
ARIMA (Auto Regressive Integrated Moving Average) 可以用来对时间序列进行预测,常被用于需求预测和规划中。
可以用来对付 ‘随机过程的特征随着时间变化而非固定’ 且 ‘导致时间序列非平稳的原因是随机而非确定’ 的问题。不过,如果是从一个非平稳的时间序列开始, 首先需要做差分,直到得到一个平稳的序列。
模型的思想就是从历史的数据中学习到随时间变化的模式,学到了就用这个规律去预测未来。
ARIMA(p,d,q)模型,其中 d 是差分的阶数,用来得到平稳序列。
AR是自回归, p为相应的自回归项。
MA为移动平均,q为相应的移动平均项数。
ARIMA数学模型?
ARIMA(p,d,q)模型是ARMA(p,q)模型的扩展。
ARIMA(p,d,q)模型可以表示为:
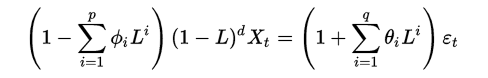
其中L 是滞后算子(Lag operator),d in Z, d>0。
AR:
当前值只是过去值的加权求和。

MA:
过去的白噪音的移动平均。

ARMA:
AR和MA的综合。

ARIMA:
和ARMA的区别,就是公式左边的x变成差分算子,保证数据的稳定性。
差分算子就是:
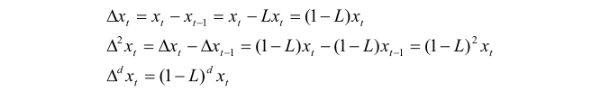
令 wt 为:
则 ARIMA 就可以写成:
input,output 是什么?
输入历史数据,预测未来时间点的数据。
怎么用?-代码实例
本文参考了:时间序列实例
另外推荐大家看这篇,36大数据上有一个python版讲的不错,里面对稳定性的定量检验的讲解比较详细:时间序列预测全攻略-附带Python代码
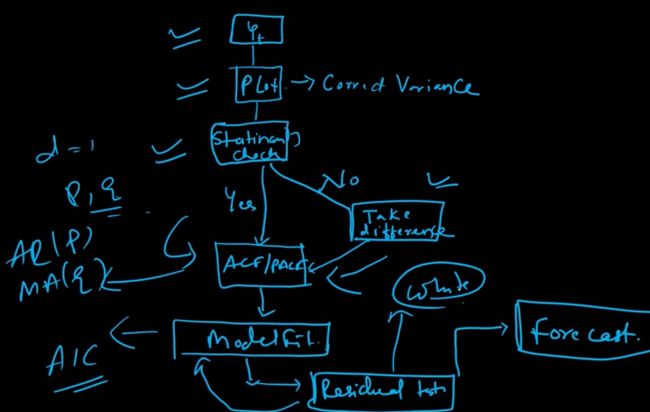
ARIMA模型运用的基本流程有几下几步:
- 数据可视化,识别平稳性。
- 对非平稳的时间序列数据,做差分,得到平稳序列。
- 建立合适的模型。
平稳化处理后,若偏自相关函数是截尾的,而自相关函数是拖尾的,则建立AR模型;
若偏自相关函数是拖尾的,而自相关函数是截尾的,则建立MA模型;
若偏自相关函数和自相关函数均是拖尾的,则序列适合ARMA模型。 - 模型的阶数在确定之后,对ARMA模型进行参数估计,比较常用是最小二乘法进行参数估计。
- 假设检验,判断(诊断)残差序列是否为白噪声序列。
- 利用已通过检验的模型进行预测。
使用ARIMA模型对裙子长度预测
1、加载数据
skirts <- scan("http://robjhyndman.com/tsdldata/roberts/skirts.dat", skip=5)str(skirts)
head(skirts)
boxplot(skirts)
length(skirts)2、把数据转化为是时间序列
skirts_ts <- ts(skirts, start=c(1886), frequency=1)1)查看时间序列对应的时间
skirts_ts2)画出时间序列图
plot.ts(skirts_ts)从图可知:女人裙子边缘的直径做成的时间序列数据,从 1866 年到 1911 年在平均值上是不平稳的

3、做差分得到平稳序列
1)做时间序列的一阶差分
skirts_diff <- diff(skirts_ts, differences = 1)
plot.ts(skirts_diff)从一阶差分的图中可以看出,数据仍是不平稳的,继续差分

2)做时间序列的二阶差分
skirts_diff2 <- diff(skirts_ts, differences = 2)
plot.ts(skirts_diff2)二次差分后的时间序列在均值和方差上看起来是平稳了
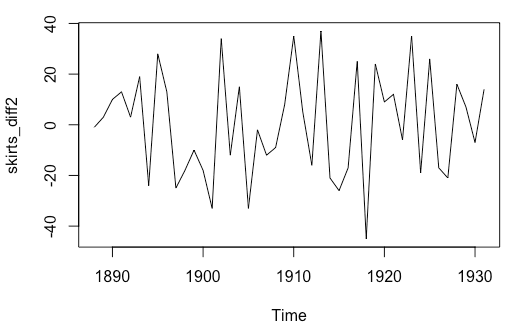
4、找到合适的ARIMA模型
寻找 ARIMA(p,d,q)中合适的 p 值和 q
1)自相关图ACF
acf(skirts_diff2, lag.max = 20)acf(skirts_diff2, lag.max = 20, plot = F)自相关图显示滞后1阶自相关值基本没有超过边界值,虽然5阶自相关值超出边界,那么很可能属于偶然出现的,而自相关值在其他上都没有超出显著边界, 而且我们可以期望 1 到 20 之间的会偶尔超出 95%的置信边界。 自相关图5阶后结尾

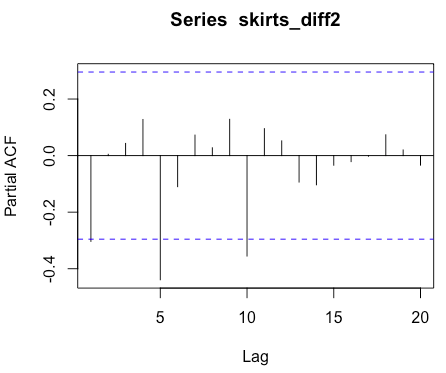
2)偏相关图PACF
pacf(skirts_diff2, lag.max = 20)pacf(skirts_diff2, lag.max = 20, plot = F) 偏自相关值选1阶后结尾
故我们的ARMIA模型为armia(1,2,5
3)使用auto.arima()函数,自动获取最佳的ARIMA模型
library(forecast)auto.arima(skirts_ts, ic=c("aicc", "aic", "bic"), trace = T)Best model: ARIMA(1,2,0)
5、建立ARIMA模型:并对比arima(1, 2, 0)与arima(1, 2, 5)模型

1)arima(1, 2, 0)模型
(skirts_arima <- arima(skirts_ts, order = c(1, 2, 0)))aic = 391.33
2)arima(1, 2, 5)模型
(skirts_arima <- arima(skirts_ts, order = c(1, 2, 5)))aic = 381.6
AIC是赤池消息准则SC是施瓦茨准则,当两个数值最小时,则是最优滞后分布的长度。我们进行模型选择时,AIC值越小越好。所以arima(1, 2, 5)模型较好
6、预测:预测5年后裙子的边缘直径
(skirts_forecast <- forecast.Arima(skirts_arima, h=5, level = c(99.5)))plot.forecast(skirts_forecast)
7、检验
观察 ARIMA 模型的预测误差是否是平均值为 0 且方差为常数的正态分布,同时也要观察连续预测误差是否自相关
1)检验预测误差的自相关性
tsdiag(skirts_arima)下面第一个图表代表估计模型误差的绘图。图中竖线的长度比较相似,都处在稳定范围之内,即估计的模型没产生不符合要求的误差分布。
第二张绘图,显示估计的模型没造成误差之间的任何关系。这是符合数据生成时每个数据都是独立的这个前提的。由此可见,这ACF图符合检测要求。
第三张图,也就是Ljung-Box 指标。这个指标可对每一个时间序列的延迟进行显著性的评估。判定技巧是,P-value点的高度越高,我们的模型越可信。
acf(skirts_forecast$residuals, lag.max = 20)Box.test(skirts_forecast$residuals, lag=20, type = "Ljung-Box") p-value = 0.9871
相关图显示出在滞后1-20阶中样本自相关值都没有超出显著置信边界,而且Ljung-Box检验的p值为0.99,所以我们推断在滞后1-20阶(lags1-20)中没明显证据说明预测误差是非零自相关的。
Acf检验说明:残差没有明显的自相关性,Ljung-Box测试显示:所有的P-value>0.05,说明残差为白噪声。

2)判断预测误差是否是平均值为零且方差为常数的正态分布
做预测误差的时间曲线图和直方图(具有正态分布曲线)
预测误差的均值是否为0
plot.ts(skirts_forecast$residuals)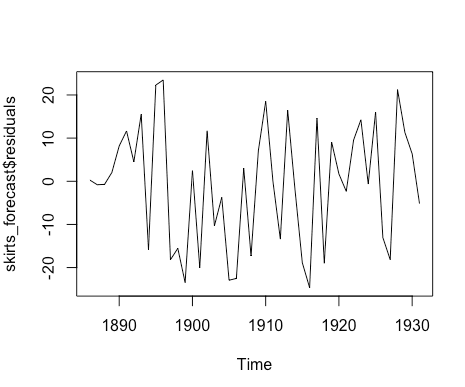
自定义判断预测误差的方差是正态分布的函数
plotForecastErrors <- function(forecasterrors){
#画预测误差的直方图
hist(forecasterrors, col="red", freq = F)
#画方差是预测误差数据的方差,平均值是0的正态分布数据的线
mysd <- sd(forecasterrors)
mynorm <- rnorm(10000, mean = 0, sd = mysd)
myhist <- hist(mynorm, plot = F)
points(myhist$mids, myhist$density, type="l", col="blue", lwd=2)
}
plotForecastErrors(skirts_forecast$residuals)下图显示时间序列的直方图显示预测误大致是正态分布的且平均值接近于0。因此,把预测误差看作平均值为0方差为服从零均值、方差不变的正态分布是合理的。

既然依次连续的预测误差看起来不是相关,而且服从零均值、方差不变的正态分布,那么对于裙子直径的数据,ARIMA(1,2,5)看起来是可以提供非常合适预测的模型。
常见问题?
1.ARIMA建模的步骤

- 观察数据是否是时间序列数据,是否有seasonal等因素。
- transform:Box-correlation,保证variance是uniform的。如果用box-cor还不能稳定,还要继续深入挖掘。
- ACF/PACF 是为了找到 MA 和 AR 的order。
- d=0-stationarity,1,2-non stationarity
- 白噪音check:确定这个模型是optimize的,mean=0,平方差=1.
- 误差是白噪音的时候,model就ok了,就可以预测了
2.决定ARIMA参数的方法

d是差分的阶数,几阶后就可以保证稳定:

modelfit,计算出来的参数是 1,1,1 ,但可能 2,1,1 预测效果更好,那就用后者。

或者用AIC比较俩模型。
推荐阅读:
这一篇实例也不错:python时间序列分析
AR和MA的定义,有图比较:
关于ACF,PACF可以看Duke的材料:
关于AIC,BIC:aic-bic-vs-crossvalidation
理论简介的不错:
需求预测与分仓规划:
一个课程:Time Series Forecasting Theory | AR, MA, ARMA, ARIMA