数据库学习笔记(一):认识数据库与SQL基础
文章目录
-
- 数据库概念
-
- 1.概念
- 2.数据库的发展历程
- 3.常见数据库
- 4.理解数据库
- 5. 应用程序与数据库
- SQL语言概述
-
- 1.SQL
- 2.SQL语法
- 3.SQL语句分类(重要)
- DDL:数据定义语言
-
- 1.操作数据库
- 2.数据类型
- 3.操作表
- DML:数据操作语言
-
- 1.插入数据-insert
- 2.修改数据-update
- 3.删除数据-delete
- DCL:数据控制语言
-
- 1.创建用户
- 2.给用户授权
- 3.撤销授权
- 4.查看权限
- 5.删除用户
- DQL:数据查询语言
-
- 1.基础查询
-
- 1.1 字段(列)控制
- 1.2 条件控制
- 2.排序
- 3.聚合函数
- 4.分组查询
- 5.limit方言
- 备份与恢复
-
- 1.备份
- 2.恢复
数据库概念
1.概念
数据库是用来存储和管理数据的仓库。
数据库存储数据的优先:
- 可储存大量数据
- 方便检索
- 保持数据的一致性、完整性
- 安全,可共享
- 通过组合分析,可产生新数据
2.数据库的发展历程
- 没有数据库,使用磁盘文件存储数据
- 层次结构模型数据库
- 网状结构模型数据库
- 关系模型结构数据库,使用二维表格来存储数据(关系型数据库:MySQL)
- 关系-对象模型数据库
3.常见数据库
oracle:甲骨文(最高)
DB2:IBM
SQL server:微软
Sybase:赛尔斯
MySQL:甲骨文
4.理解数据库
我们现在所说的数据库泛指“关系型数据库管理系统”(RDBMS-Retational database management system),即“数据库服务器”。
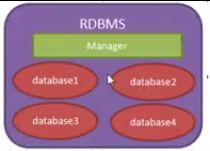 安装数据库服务器后,就可以再数据库服务器中创建库,每个库中包含多张表。
安装数据库服务器后,就可以再数据库服务器中创建库,每个库中包含多张表。
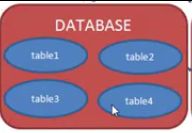 数据库表是一个多行多列的表格,表格分两个层面:表结构与表记录;
数据库表是一个多行多列的表格,表格分两个层面:表结构与表记录;
在创建表时,需要指定表的列数、列名称、列类型等信息(不需指定行数,行数没有上限),下图是一个表结构:
 创建表结构后,就能在表中以行为单位插入数据,叫表记录。
创建表结构后,就能在表中以行为单位插入数据,叫表记录。
 总结:
总结:
- RDBMS = 管理员+仓库
- database = N个table
- table:
- 表结构:定义表的列名和类型
- 表记录:一行一行的记录
5. 应用程序与数据库
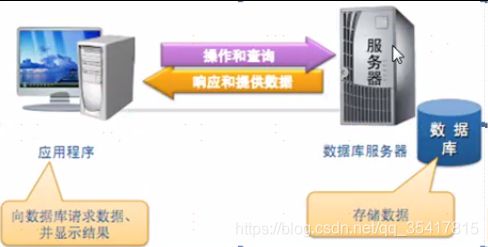
应用程序使用数据库完成对数据的存储
SQL语言概述
1.SQL
- 什么是SQL:结构化查询语言(structured query language)。
- SQL的作用:客户端使用SQL来操作服务器。
- 启动MySQL.exe,链接服务器后,就可以使用sql来操作服务器了;
- 将来会使用Java程序链接服务器,然后使用sql来操作服务器。
- SQL标准(例如SQL99,即1999年制定的标准);
- 由国际标准组织(ISO)制定的,对DBMS的同一操作方式(例如相同的语句可以操作:MySQL、oracle等)。
- SQL方言
- 某种DBMS不只会支持SQL标准,而且还会有一些自己独有的语法,称之为方言;例如:limit语句只在MySQL中可以使用。
2.SQL语法
- SQL语句可以在单行或多行书写,以分号结尾;
- 可以使用空格和缩进来增强语句的可读性;
- MySQL不区别大小写,建议使用大写;
3.SQL语句分类(重要)
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
- 创建、删除、修改:库、表结构
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
- 增、删、改:表记录
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)
总结:
ddl:数据库或表的结构操作(***** )
dml:对表的记录进行更新(增删改)( ***** )
dql:对表的记录的查询(*****,难点)
dcl:对用户的创建及授权
DDL:数据定义语言
1.操作数据库
- 查看所有数据库:SHOW DATABASES
- 切换(选择要操作的)数据库:USE 数据库名
- 创建数据库:CREATE DATABASE [IF NOT EXISTS] mydb1 [CHARSET=utf-8]
- 删除数据库:DROP DATABASES [IF EXISTS] mydb1
- 修改数据库编码:ALTER DATABASE mydb1 CHARACTER SET utf-8
2.数据类型
数据库的数据类型即列类型
- int:整型
- double:浮点型,例如double(5,2)标识最多五位,其中必须两位小数,即最大值为999.99
- decimal:浮点型,在表单钱方面使用该类型,因为不会出现精度缺失问题
- char:固定长度字符串类型,char(255),数据的长度不是指定长度,补足带指定长度
- varchar:可变长度字符串类型,varchar(65535)
- char和varchar
- char是固定长度的,身份证号码、uuid等长度相似或相等的字段可用char类型;varchar是可变长度,用户名、备注、描述等字段可用varchar;
- varchar需要耗费最少一个字节记录长度;char比varchar节省时间,varchar在插入数据时不会补零 - text(clob):text是MySQL的方言,标准语言是clob,字符串类型,存储文本文字,可变长度字符串
| 类型 | 大小 |
|---|---|
| tinytext | 2的8次方-1B(256B) |
| text | 2的16次方-1B(64K) |
| mediumtext | 2的24次方-1B(16M) |
| longtext | 2的32次方-1B (4G) |
可参考:https://www.w3school.com.cn/sql/sql_datatypes.asp
- blob:字节类型,可变长度二进制类型
| 类型 | 大小 |
|---|---|
| tinyblob | 2的8次方-1B(256B) |
| blob | 2的16次方-1B (64K) |
| mediumblob | 2的24次方-1B(16M) |
| longblob | 2的32次方-1B (4G) |
- date:日期类型,格式为:yyyy-MM-dd;
- time:时间类型。格式为:hh:mm:ss;
- timestamp:时间戳类型;
3.操作表
- 创建表
CREATE TABLE [IF NOT EXISTS] 表名(
列名 列类型,
列名 列类型,
…
列名 列类型
);
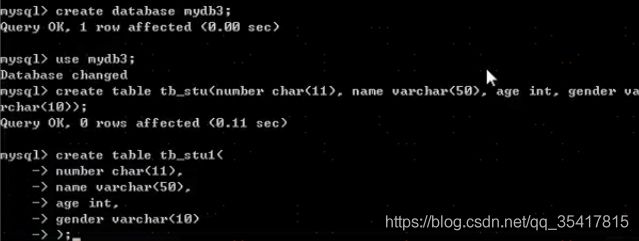
- 查看当前数据库中所有表名称:
SHOW TABLES;

- 查看指定表的创建语句(了解):
SHOW CREAT TABLE 表名;
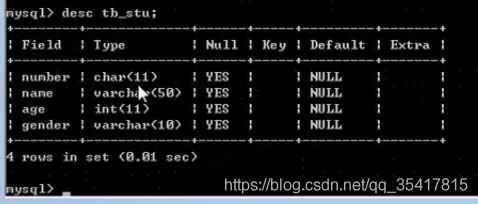
- 查看表结构:
DESC 表名;
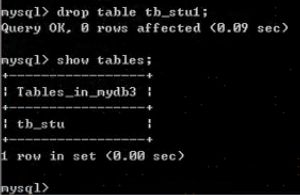
- 删除表:
DROP TABLE 表名;
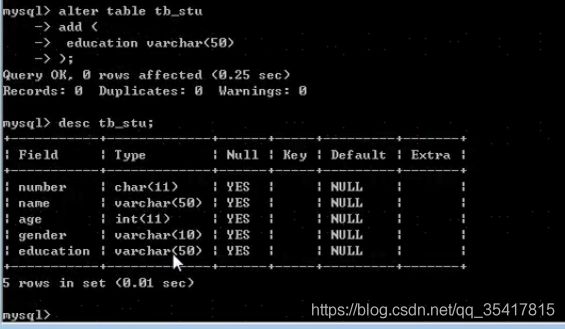
- 修改表:前缀 ALTER TABLE 表名
-
修改之添加列:
ALTER TABLE 表名 ADD(
列名 列类型,
列名 列类型,
…
列名 列类型
);
-
修改之修改列类型:
(如果被修改的列已存在数据,那么新的类型可能会影响到已存在数据)ALTER TABLE 表名 MODIFY 列名 列类型;

-
修改之修改列名:
ALTER TABLE 表名 CHANGE 原列名 新列名 列类型;
-
修改之删除列:
ALTER TABLE 表名 DROP 列名;
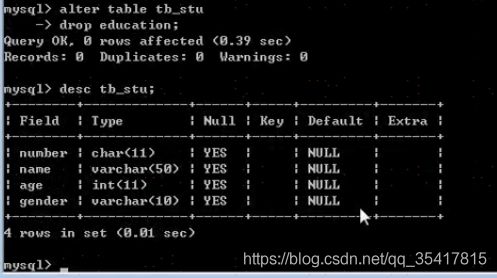
-
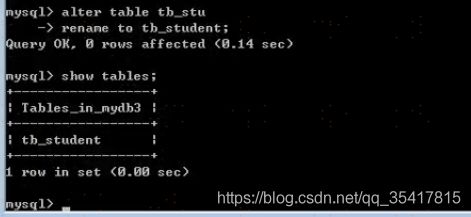
修改表名称:
ALTER TABLE 原表名 RENAME TO 新表名;
-
DML:数据操作语言
DML:对表记录的增删改。
1.插入数据-insert
- INSERT INTO 表名 (列名1,列名2,…) VALUES (列值1,列值2,…);
-在表名后给出要插入的列名,其他没有指定的列等同于插入null值。所以插入记录总是插入一行,不可能是半行。
-在values后给出的列值,值的顺序和个数必须与前面指定的列对应 - INSERT INTO 表名 VALUES (列值1,列值2,…);
-没有给出要插入的列,那么表示插入所有列。
-值的个数必须是该表列的个数。
-值的顺序,必须与表创建时给出的列的顺序相同。
2.修改数据-update
-
UPDATE 表名 SET 列名1=列值1, 列名2=列值2,…[WHERE 条件];
-
条件(条件可选的):
-条件必须是一个Boolean类型的值或表达式:-运算符:=、!=、<>、>、<、>=、<=、BETWEEN…AND、IN(…)、IS NULL、NOT、OR、AND
3.删除数据-delete
- DELETE FROM 表名 [WHERE 条件];
- TRUNCATE TABLE 表名 ;
-TRUNCATE是DDL语句,他是先删除drop该表,再create该表,而且无法回滚!
注意:
- 在数据库中所有的字符串类型,必须使用单引号,不能使用双引号;
- 日期类型也要使用单引号;
DCL:数据控制语言
(理解内容)
1.创建用户
- CREATE USER 用户名@IP地址 IDENTIFIED BY ‘密码’;
用户只能在指定的IP地址上登录
- CREATE USER 用户名@’%’ IDENTIFIED BY ‘密码’;
用户可以在任意IP地址上登录
2.给用户授权
- GRANT 权限1,…,权限n ON 数据库.* TO 用户名@IP地址
权限、用户、数据库
给用户分派在指定的数据库上指定的权限
例如:GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON mydb1.* TO user@localhost;- 给用户user1分派在数据库mydb1上的create、alter、drop、insert、update、delete、select权限
- GRANT ALL ON 数据库.* TO 用户名@IP地址
给用户分派指定数据库上的所有权限
3.撤销授权
- REVOKE 权限1,…,权限n ON 数据库.* FROM 用户名@IP地址
撤销指定用户在指定数据库上的指定权限
例如:REVOKE CREATE,ALTER,DROP ON mydb1.* FROM user@localhost;- 撤销用户user1在数据库mydb1上的create、alter、drop权限
4.查看权限
- SHOW GRANT FOR 用户名@IP地址
查看指定用户的权限
5.删除用户
- DROP USER 用户名@IP地址
DQL:数据查询语言
查询不会修改数据库表记录
1.基础查询
1.1 字段(列)控制
1)查询所有列
select * from 表名;
—>’*'表示查询所有列
2)查询指定列
select 列1,列2,…,列n from 表名;
3)完全重复的记录只一次
当查询结果中的多行记录一样时,只显示一行。
select distinct * | 列1,…,列n from 表名;
4)列运算
-
数量类型的列可以做加减乘除运算
select sal*1.5 from emp;
select sal+comm from emp; -
字符串类型可以做连续运算
select concat(’$’, sal) from emp;
把表中的两列字符串连接:
SELECT CONCAT(‘我叫’, ename,’,我的工作是’,job) FROM emp
-
转换null值
有时候需要把NULL转换成其他值,例如comm+1000时,如果comm列存在NULL值,那么NULL+1000还是NULL,这时需要把NULL当做0运算select ifnull(comm, 0)+1000 from emp;
—> ifnull(comm, 0):如果comm是NULL,那么当成0运算;
转换成字符串:IFNULL(列名,‘字符串’) -
给列起别名
select ifnull(comm, 0)+1000 as 奖金 from emp;
–>as可以省略
1.2 条件控制
1)条件查询
与前面介绍的update和delete语句一样,select语句也可以使用where字句来控制记录
SELECT 列名 FROM 表名 [WHERE 条件]
条件中运算符:=、!=、<>、>、<、>=、<=、BETWEEN…AND、IN(…)、IS NULL、IS NOT NULL、OR、AND…
2)模糊查询
关键字:LIKE、_、%
以姓名为例:
- 查询姓张,并且姓名一共两个字的员工:
SELECT * FROM emp WHERE ename LIKE ‘张_’;
模糊查询需要使用运算符:LIKE,其中_匹配一个任意字符,注:只能匹配一个字符。
-
查询姓张姓名三个字的员工:
SELECT * FROM emp WHERE ename LIKE ‘张__’;
-
查询姓张,名字字数不限制的员工:
SELECT * FROM emp WHERE ename LIKE ‘张%’;
%表示匹配任意字符(0-N)SELECT * FROM emp WHERE ename LIKE ‘%哈%’;
查询姓名中以哈开头、结尾、在中间的员工SELECT * FROM emp WHERE ename LIKE ‘%’;
这个条件等同于不存在,如果姓名为NULL则查不出来
2.排序
- 升序
SELECT * FROM emp ORDER BY sal ASC
-- 按sal排序,升序
-- ASC可以省略
- 降序
SELECT * FROM emp ORDER BY comm DESC
-- 按scomm排序,降序
-- DESC不能省略
- 使用多列作为排序条件
SELECT * FROM emp ORDER BY sal ASC, comm DESC
-- 按sal升序排序,如果sal相同,则按comm降序排序
3.聚合函数
聚合函数用来做某列的纵向运算
1)COUNT()
SELECT COUNT(*) FROM emp
-- 计算emp表中所有列都不为NULL的记录的行数
SELECT COUNT(comm) FROM emp
-- 计算emp表中comm列不为NULL的记录的行数
2)MAX()
SELECT MAX(sal) FROM emp
-- 查询最高工资
3)MIN()
SELECT MIN(sal) FROM emp
-- 查询最低工资
4)SUM()
SELECT SUM(sal) FROM emp
-- 查询工资总和
5)AVG()
SELECT AVG(sal) FROM emp
-- 查询平均工资
4.分组查询
分组查询是把记录使用某一列进行分组,然后查询组信息
关键字:GROUP BY , HAVING
例如:查看所有部门的记录数
SELECT deptno, COUNT(*) FROM emp GROUP BY deptno
-- 使用deptno分组,查询部门编码和每个部门的记录数
SELECT job, MAX(sal) FROM emp GROUP BY job
-- 使用job分组,查询工作的最高工资
/*
组条件
以部门分组,查询每组记录数,条件为记录数大于3
*/
SELECT deptno, COUNT(*) FROM emp GROUP BY deptno HAVING COUNT(*) >3
5.limit方言
MySQL中独有的关键字:limit
用来限定查询结果的起始行,以及总行数。
/*
查询起始行为第5行,一共查询3行记录
*/
SELECT * FROM emp LIMIT 4, 3;
-- 其中4表示从第5行开始,3表示一共查询3行,即结果返回第5/6/7行记录
/*
应用场景:
1.一页记录数:10行
2.查询第3页
*/
SELECT * FROM emp LIMIT 20, 10;
-- LIMIT [(当前页-1)*每页记录数], [每页记录数];
小结:
查询语句顺序:
select
from [where…] #分组之前的筛选在where中
group by [having…] #分组后再筛选用having
order by
备份与恢复
1.备份
备份:数据库导出SQL脚本,备份的是数据库内容(表和数据),并不是备份数据库。
cmd命令:
mysqldump -u用户名 -p密码 数据库名>生成的脚本文件路径

- 注:不要打分号,不要登录MySQL,直接在cmd下运行
- 注:生成的脚本文件中不包含create database语句
2.恢复
- 方式一:
mysql -u用户名 -p密码 数据库名<生成的脚本文件路径

注:不要打分号,不要登录MySQL,直接在cmd下运行
练习:
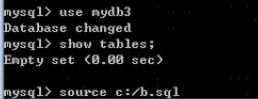
- 先删除mydb3库,再重新创建mydb3库
- 退出登录MySQL,执行mysql -uroot -p123 mydb3
- 方式二:
- 登录MySQL
- source SQL脚本路径
练习:
1.先删除mydb3库,再重新创建mydb3库
2.切换到mydb3库
3.source c:\mydb1.sql
小结:
- 备份:数据库—>SQL语句
mysqldump -uroot -p123 mydb3>c:/a.sql - 恢复:SQL语句—>数据库
mysql -uroot -p123 mydb3
source c:\mydb1.sql