【读书笔记】《深度学习进阶,自然语言处理》总结记录
文章目录
- 一、神经网络
-
-
- 1. mini-batch的损失计算以及反向传播
- 2. 计算图中几个常见神经元节点
- 3. 计算图中节点的代码实现以及螺旋状数据集的demo
-
- 二、自然语言以及单词的分布式表示
-
-
- 1. 同义词词典
- 2. 基于统计的方法
-
- 三、word2vec
- 四、语言模型与RNN
-
-
- 1. 语言模型的评价
- 2. RNN网络结构的优化
- 3. 使用RNN生成文本
-
- 五、Attention
-
-
- 1. 一般的Attention机制
- 2. Transformer
-
- 结语
最近需要开始做nlp相关的东西,参考知乎的问答列了一个书单,其中有这本: 《深度学习进阶,自然语言处理》。断断续续花了几周时间把这本书看完了,总结回顾了一下书中的大致内容,并在此做一个记录,不过详细的地方大家还是买书去看比较好。
这本书比较好的就是不止有原理性地描述,还有正向与反向传播计算图的说明以及不借助pytorch、tensorflow等深度学习库的底层计算实现。由于主要涉及深度学习,在传统机器学习算法以及一些公式的推导上相比西瓜书和统计学习方法来说没有那么详细,但总的来说是一本很不错的书。
一、神经网络
书中主要说了神经网络的基本构成与实现,重心放在神经元之间进行的操作上而不是整体的网络结构。涉及的一些线性代数(矩阵乘积)和python数组(Numpy)的知识就不说了,此外的几个比较值得注意的点有:
1. mini-batch的损失计算以及反向传播
交叉熵误差是多分类问题中常用的损失函数。其一般计算形式如下:
L = − ∑ k t k l o g e y k L=-\sum_{k}t_k log_ey_k L=−k∑tklogeyk
其中 y k y_k yk是网络输出,表示输出向量中第k个类别的值(概率), t k t_k tk是第k个类别的监督标签,以one-hot形式表示(比如[1,0,0]),实际上求和符号里表示的就是取对应 t k = 1 t_k=1 tk=1的类别的输出概率 y k y_k yk的自然对数。
而在mini-batch下的交叉熵误差则使用下面公式计算:
L = − 1 N ∑ n ∑ k t n k l o g e y n k L=-\frac{1}{N}\sum_{n}\sum_{k}t_{nk} log_ey_{nk} L=−N1n∑k∑tnklogeynk
其中 y n k y_{nk} ynk是第n个batch的网络输出, t n k t_{nk} tnk是第n个batch第k个类别的one-hot表示,相比于上式,其实就是加了batch的维度的并取平均。而反向传播时具体如何更新的似乎没说,猜测是使用此平均Loss基于此batch中的{输入,标签}对来更新网络参数。
2. 计算图中几个常见神经元节点
Repeat节点(复制节点/分支节点):Repeat节点实际就是将输入的x复制了几份,它的反向传播则是所有分支上传过来的相同的梯度之和。
Sum节点: z = x + y z=x+y z=x+y,此节点的反向传播是将上游传来的梯度分配到所有输入的加法分支流中。也就是说,Sum节点和Repeat节点实际上是互为逆向的关系。
乘法节点: z = x × y z=x \times y z=x×y,此时反向传播时的倒数很简单,分别是: ∂ z ∂ x = y \frac{\partial z}{\partial x}=y ∂x∂z=y, ∂ z ∂ y = x \frac{\partial z}{\partial y}=x ∂y∂z=x。此时的计算图如下所示:

MatMul节点:矩阵的乘积节点,这个是一个比较重要的节点,具体的推导过程书上有,这里就不说了,主要说一下它的反向传播公式。
有运算: y = x W y=xW y=xW,其中 x x x与 y y y都是一维向量(batch_size=1),W是一个矩阵,上游传来的梯度为 ∂ L ∂ y \frac{\partial L}{\partial y} ∂y∂L。
则可以得到对应的反向传播公式为:
∂ L ∂ x = ∂ L ∂ y W T \frac{\partial L}{\partial x}=\frac{\partial L}{\partial y}W^T ∂x∂L=∂y∂LWT
∂ L ∂ W = x T ∂ L ∂ y \frac{\partial L}{\partial W}=x^T\frac{\partial L}{\partial y} ∂W∂L=xT∂y∂L
3. 计算图中节点的代码实现以及螺旋状数据集的demo
这个在书中都有很详细的实现,实现了Affine层( y = x W + b y=xW+b y=xW+b),使用的是SGD,这里可以再拿书仔细看一遍。
二、自然语言以及单词的分布式表示
书中的这一部分说的是一些基础的自然语言处理知识,其中提到单词表示有以下几类方法:
- 基于同义词词典的方法(人工整理)
- 基于统计的方法(计数)
- 基于推理的方法(word2vec)
1. 同义词词典
同义词词典是通过人工定义单词含义得到的,它将含义相同或相近的词归为同一个组,有时还会定义更细粒度的关系,比如“上级-下级”、“整体-部分”关系,最著名的同义词词典是普林斯顿大学在1985年开发的WordNet。显然,同义词词典所需的人工成本过高,难以扩展,且不能准确地表示单词间的细微差别,是非常落后的方法了。
2. 基于统计的方法
将单词表示为一个固定长度向量称为单词的分布式表示,这是所有单词表示方法都在做的事,为了能够自动化此过程需要使用到语料库(corpus)。从这里开始引入了一个非常重要的假设——分布式假设:某个单词的含义由它的上下文(周围的单词)构成。其中上下文的数量通常称为窗口大小。
简单的基于统计的方法:利用单词共现矩阵可以实现简单的基于统计的表示方法,共现矩阵的形状为 N × N N\times N N×N(语料库中总共有 N N N个单词),而如果单词 c i c_i ci和 c j c_j cj同时在一句话中出现,则将矩阵中 ( i , j ) (i,j) (i,j)的值设置为1。构造完成后,可以将共现矩阵中的每一行(或每一列,因为实际上是一个对称矩阵)视为单词的表示。可以采用向量之间的相似度计算方法(余弦相似度)来衡量两单词是否相似。
-
统计方法改进1——互点信息:只依据单词出现次数显然是不够的,因为有很多常用词在哪一个句子中出现频率都很高,需要能够清洗此类噪声的方法,而实际上我们的目的是表示两个单词之间的相关程度,因此互点信息(Pointwise Mutual Information)就很自然地可以用到这上面来,PMI值越高,相关性越强。看公式就可以发现互点信息相比于原始的方法,加入了单词本身在语料库中出现的次数这一信息,减少了因为词语使用过于频繁而带来的噪声。
P M I ( x , y ) = l o g 2 P ( x , y ) P ( x ) P ( y ) ≈ l o g 2 C ( x , y ) × N C ( x ) C ( y ) PMI(x,y)=log_2 \frac{P(x,y)}{P(x)P(y)} \approx log_2 \frac{C(x,y)\times N}{C(x)C(y)} PMI(x,y)=log2P(x)P(y)P(x,y)≈log2C(x)C(y)C(x,y)×N -
统计方法改进2——降维:使用上述方法得到的每个单词表示都是一个 N N N维向量,且大部分单词都是一个稀疏向量,这显然是冗余的,因此需要对单词表示进行降维,经典的降维方法就是基于奇异值分解(SVD)的方法。简而言之就是可以利用奇异值分解将任意矩阵分解为三个矩阵的乘积,其中 U , V U,V U,V是列向量彼此正交的正交矩阵,而 S S S是一个对角矩阵,对角线上的值(奇异值)表示了矩阵 U U U中对应列向量(基轴)的重要性,据此我们就可以删除奇异值较小的基轴来实现降维,并得到降维后的矩阵 U ′ U' U′作为单词的分布式表示。不过一般SVD的复杂度为 O ( N 3 ) O(N^3) O(N3),计算量过于巨大,所以一般会使用一些改进的方法加快速度(比如Truncated SVD)。
X = U S V T X=USV^T X=USVT
最后,这本书还在PTB数据集上实现了改进后的基于统计的方法,可以做参考。
三、word2vec
基于推理的方法实际就是求解一个预测任务,即给定单词的上下文预测此单词(CBOW)或给定此单词预测此单词的上下文(skip-gram),显然这也是遵循单词分布式假设的。通过上一节可以看到基于计数的方法需要构造矩阵并分解,所以需要一次性处理全部数据,在大型预料库中这类方法由于计算量太大而没办法很好地学习,而使用神经网络来学习的基于推理的方法在这方面有很大优势。word2vec是基于推理的方法中的一类典型模型(以至于现在一般都直接说word2vec而不说基于推理的方法了)
word2vec的基本思路就是:通过求解预测任务,优化神经网络,最终将优化得到的权重矩阵(一般是用的输入权重矩阵) 作为单词的分布式表示。

- 这里其实有一个很容易被忽略的问题,就是word2vec的目的是获得自然语言中单词的向量表示,而我们word2vec网络的输入又必须得是单词的向量表示,乍一看有点像鸡生蛋、蛋生鸡的问题。因此,这里实际需要定义一个单词的简单表示(即one-hot)来作为原始word2vec的输入,然后让word2vec从语料库中学习并得到更优的单词表示。使用one-hot表示有一个十分巧妙的地方就是:输入 c c c与权重矩阵 W W W的乘积实际上就是提取矩阵中的某一行,也正因如此,我们才可以直观地将权重矩阵的每一行视为每个单词的分布式表示。

- word2vec改进1——embedding层:在词汇量大的时候,输入层部分one-hot形式的输入与 W i n W_{in} Win矩阵的乘积计算量是比较大的,而实际上这项操作只是取了矩阵中的某一行,因此可以直接定义并实现一个神经网络层,功能是取矩阵的某一行从而避免矩阵乘积运算(这样反向传播时从上游传来的梯度只被应用到权重梯度的某一行)。这里主要是代码实现方面有区别,还是看书上的解释比较好。
- word2vec改进2——negative sample:在输出层与最后的softmax环节,也会因为词汇量太大导致计算量激增,此时我们可以采用负采样的方法。这里书中花了很多篇幅来说明,也比较复杂,大致来说就是:首先我们只关注正确标签输出的概率值必须接近1,这时即转化为一个二分类问题(输出是/不是正确的),这样我们就可以只使用输出矩阵 W o u t W_{out} Wout中对应标签的那一列(在 W i n W_{in} Win中的每行是单词向量表示,在 W o u t W_{out} Wout中每列是单词向量表示)与上一层的神经元进行点积来得到二分类概率,理想情况下这样学习得到的网络正确标签对应的输出接近1。然后针对负例,就需要使用负采样的方法,依据上述二分类学习策略,使部分错误标签的输出概率值接近0。 这些负例一般是概率性地选择语料库中出现频率比较高的词,这样不仅大幅减少了计算量,且对最终结果准确率的影响不大。
四、语言模型与RNN
RNN由于其在处理时间序列数据上的优越性,是之前nlp中最常使用的模型。关于RNN的细节以及实现在书中也都有,而且RNN又是很经典的一种网络结构,因此在这里就不多说了。除RNN本身之外,这部分需要注意的还有以下几个点:
1. 语言模型的评价
语言模型表示的是一个单词序列发生的可能性,从概率的角度上来说就是求m个单词的联合概率。困惑度(概率的倒数)是一个常用的评价指标, P e = 1 P ( x ) Pe=\frac{1}{P(x)} Pe=P(x)1。困惑度在某种程度上也可以叫做分叉度,实际上就是指可能的候选词个数,显然困惑度越低,模型越好。
在多个输入的情况下,困惑度计算公式则为 P e = e L o s s Pe=e^{Loss} Pe=eLoss,当然,也是困惑度越低,模型越好。目前许多模型困惑度能够达到50左右甚至更低。
2. RNN网络结构的优化
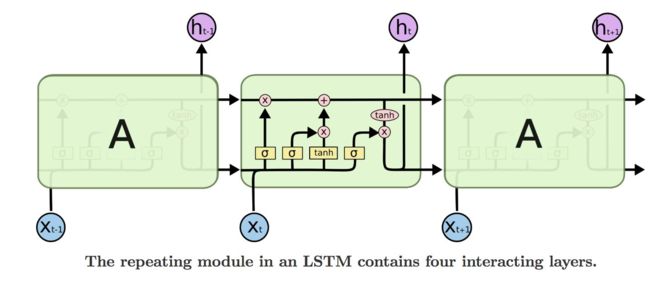
gated RNN:RNN极其容易产生梯度消失和梯度爆炸的问题,本质上是反向传播时激活函数以及链式求导法则导致的。虽然可以通过修改激活函数为ReLu等改善部分梯度消失问题,也可以通过梯度裁剪改善部分梯度爆炸问题,而由于网络层数过深导致链式求导过程中出现的梯度消失问题则需要从网络结构入手进行改进,带门控的RNN就是一个比较好的改进结构。LSTM就是一个著名的门控型RNN,它在普通RNN基础上加上了输入们、输出门和遗忘门,并且在学习过程中内部多传递了一个记忆单元 c c c,具体细节在书和许多其它博客中都有说明,在此就不多说了,放上一张经典的LSTM结构图:
一般来说,RNN只是作为整个语言模型中的一个网络层,一个比较完整的网络结构应该还包括起到word2vec作用的Embedding层与Affine层,以及使最终输出转变为概率的Softmax层。如下图是一个简单的以一个单词为起点不断生成接下来的单词的语言模型:

针对各种语言模型,为了提升模型精度,书中提到了如下几个优化方案:
- 多层RNN:即纵向加深RNN层,这与图像处理时中加深卷积层的思路是一样的,当数据量足够时可以考虑多加几层来提升模型学习能力,谷歌翻译使用的GNMT模型就是叠加了8层LSTM。
- dropout抑制过拟合:dropout指在训练时随机忽略一部分神经元,通常以单独的一层来实现。为了不丢失必要数据通常在纵向上使用dropout(即加深)而不是在RNN自身的时间轴上使用。不过也有研究提出了一种变分dropout能够在时间轴上使用以提升模型精度。
- 权值共享:这里实际就是将Embedding层和Affine层设置为相同的权重,两矩阵互为转置,这样可以减少参数数量并提升学习精度。
3. 使用RNN生成文本
上面所讲的语言模型输出的只是一些概率数值,是没办法生成文本的。以文本翻译为例,人在翻译过程中首先会理解源语句的含义,然后再根据含义翻译成其它语言的语句。类比到机器,很容易就可以想到我们首先通过一个编码器(Encoder)将源文本变成一个中间向量表示,这个向量中应当包含了文本的含义,然后再通过一个解码器(Decoder)将此向量再转化为其它自然语言 。因此,此类seq2seq的任务通常都是由Encoder-Decoder架构来解决,结构如下: 
如果用RNN实现其实就是将Encoder中RNN层最后一个神经元的隐藏状态输出 h h h作为Decoder中RNN层第一个神经元的初始隐藏状态。这里在书中有很详细的结构说明和代码实现,除此之外,书中还提到了两个改进结构的方案:
- Reverse Input:即将训练数据的输入翻转过来,输出不翻转。这个方法不仅扩充了数据集,更重要的一点是,这种方法调整了encoder和decoder中相对应的单词的距离。比如说原本单词 w 0 w_0 w0是长度为 m m m的源文本中的第一个单词,其对应的输出单词为目标语句的第一个单词 y 0 y_0 y0,那么两个单词所所对应的神经元相距为 N − 1 N-1 N−1,而如果翻转输入,则两个单词所对应的神经元变为了相邻的神经元,这样能够在seq2seq任务中更好地学习到对应单词间的依赖关系。
- Peeky Decoder:针对编码器,其所有的信息来源只有Encoder传过来的 h h h,而 h h h又只用于第一个神经元的隐藏层初始化。为了更好地利用信息,很容易就可以想到把 h h h共享给Decoder中除第一个循环神经元以外的其它结构,比如可以作为一部分Affine层的输入使用。
五、Attention
这一章讲的就是大名鼎鼎的注意力机制了。
1. 一般的Attention机制
使用Attention机制的Encoder-Decoder架构与一般架构的不同之处如图所示,上面是普通法的encoder-decoder架构而下面是加入了注意力机制的encoder-decoder架构:
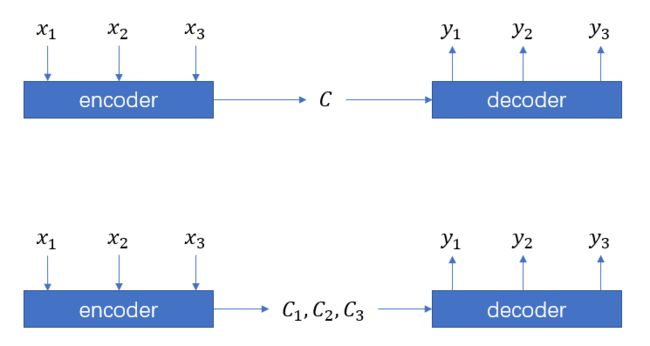
公式表示如下:
N o r m a l : y i = D ( C , y 1 , y 2 , . . . , y i − 1 ) Normal:y_i=D(C,y_1,y_2,...,y_{i-1}) Normal:yi=D(C,y1,y2,...,yi−1)
A t t e n t i o n : y i = D ( C i , y 1 , . . . , y i − 1 ) Attention:y_i=D(C_i,y_1,...,y_{i-1}) Attention:yi=D(Ci,y1,...,yi−1)
实际上就是对于decoder不同时刻的输出使用不同 C i C_i Ci(一般称之为上下文向量)来计算, C i C_i Ci的引入是基于一种对齐的思想,即想要得到输入的哪一部分对于输出的哪一部分影响更大,这里自然就想到可以用权重来表示,权重的表示方法是可微的也就是可以用梯度反向传播算法训练的。因此有了如下的Attention公式:
C i = ∑ j n α i j h j C_i=\sum_j^n\alpha_{ij}h_j Ci=j∑nαijhj
其中 h j h_j hj是从编码器中传过来的源语句中每一个单词对应的中间向量表示(如果编码器是RNN结构,那么一般是每个循环神经元的隐藏状态输出),而 α i j \alpha_{ij} αij就是我们想要学习的权重,也是注意力机制算法的关键。它的含义可以解释为第j个位置的输入与第i个位置的输出的相似程度,于是可以将上面的公式更为一般化,这个公式可以与下面的经典注意力机制图相对应:
A t t e n t i o n ( Q u e r y , S o u r c e ) = ∑ j n S i m i l a r i t y ( Q u e r y , k e y j ) × V a l u e j Attention(Query,Source)=\sum_j^nSimilarity(Query,key_j)\times Value_j Attention(Query,Source)=j∑nSimilarity(Query,keyj)×Valuej
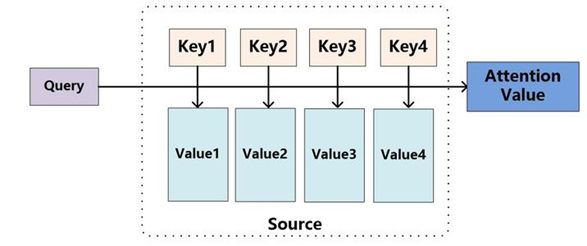
对于公式中 S i m i l a r i t y Similarity Similarity函数,不同的论文有不同的计算实现方法,比如使用向量点积算相似度、使用余弦相似度甚至使用一个小型的MLP直接学习相似度等等。
这样的注意力机制一般是作为一个单独的注意力层,加在原来语言模型RNN层的后面。
2. Transformer
transformer是一个完全不用CNN或RNN,完全使用Attention与MLP的Encoder-Decoder架构,经过实验表明它能够达到与其它CNN、RNN模型一样甚至更高的准确率,除此之外还有计算可并行度高、更好地学习远程依赖关系、更具解释性等优点,是近年来大火的网络结构。Transformer的结构如下:

总的来说包括以下几个结构:

其中还加入了多头注意力、自注意力等机制,具体细节建议去认真看看这篇transformer开山之作《Attention is all you need》,真的特别经典,而且写得很好很详细。
结语
至此整本书差不多总结完了,其中的内容都是书中所讲解的再加上我自己的理解,如果我有哪里理解不到位的地方,还请各位不吝赐教。