【PyTorch】基于自然语言处理和长短期记忆网络的“AI诗人”
目录
- 长短期记忆网络 (LSTM)
- 自然语言处理之词嵌入 (Word Embedding)
- get_data.py - 数据预处理
- model.py - 定义神经网络模型
- train.py - 训练神经网络
- 一些比较好的AI生成诗句
长短期记忆网络 (LSTM)
长短期记忆网络 (Long Short-Term Memory, LSTM) 是循环神经网络 (Recurrent Neural Network, RNN) 的一种变体。RNN存在梯度消失 (vanishing gradient) 或梯度爆炸 (exploding gradient) 问题,所以尽管很多问题对RNN是适用的,但实际上并不能应用于解决这些问题。而LSTM的提出改变了这一情况。
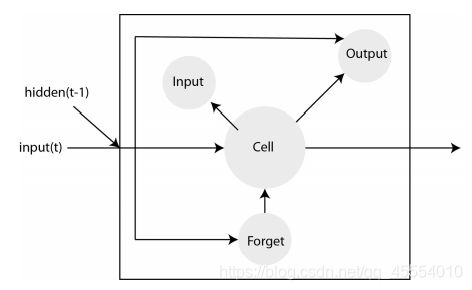
在RNN中,网络会“记住”一切,但人类的大脑却并不是这样的。LSTM引入了遗忘门,随着在输入链中不断深入,输入链开始的部分会变得不那么重要。单元最后会成为网络层的“记忆”,而输入门、输出门和遗忘门会确定数据如何经过一个网络层。
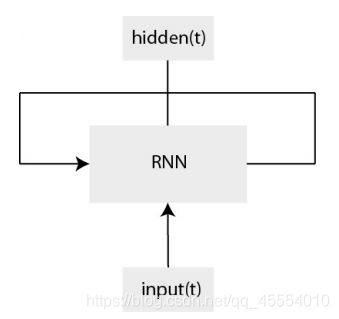
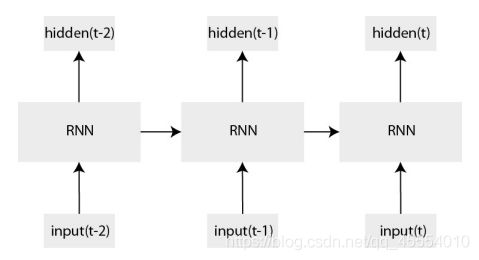
这是经典RNN的结构示意图及其结构展开示意图:
这是LSTM的结构示意图:
自然语言处理之词嵌入 (Word Embedding)
我们应该如何在一个神经网络中表示一个词?最简单的方法是使用独热编码 (one-hot encoding) 。独热编码会根据词的规模创建一个张量,对其中的每个词分配一个向量,每个向量中有一个元素会被设置为1,其余元素会被设置为0。比如我们有这样一个句子:I like eating apple.,则我们可以得到一个单词表["I", "like", "eating", "apple"],每个词的向量为:
I -> [1 0 0 0]
like -> [0 1 0 0]
eating -> [0 0 1 0]
apple -> [0 0 0 1]
独热编码虽然简单,但也有很多限制与不足。比如我们要向单词表中再增加一个词,由于编码机制就要修改所有的词向量。再如,有些词语之间是有一定联系的(比如puppy和dog),显然,独热编码不能表示词与词之间的关系。此外,独热编码的绝大部分元素都是0,只有一个元素会被设置为1,这也造成了内存的浪费。
嵌入矩阵解决了独热编码的这些缺陷。其实独热编码本质上也是一个嵌入矩阵,但它不包含词与词之间关系的信息。嵌入矩阵的思想是压缩向量空间的维度,从而充分利用这个空间。在向量空间中,类似的词会被聚集在一起,这样就可以通过词与词之间的“距离”来度量其接近程度。嵌入层和神经网络的其他层的训练过程没有什么区别,即随机初始化向量空间,在训练过程中更新参数,使得类似的词的距离更加接近。
在PyTorch中使用嵌入层非常简单:
import torch.nn as nn
# 使用嵌入层
embed = nn.Embedding(vocab_size, dimension_size)
嵌入层包含一个随机初始化的vocab_size * dimension_size的张量,单词表中的每个词会索引到这个张量中的一个元素,每个元素是一个大小为dimension_size的向量。
get_data.py - 数据预处理
数据集来自于GitHub上中文爱好者收集的5万多首唐诗,经过数据处理后打包成为一个NumPy压缩包tang.npz,加载后是一个57580 * 125的NumPy数组。
GitHub链接
tang.npz下载链接(提取码:a5gg)
import os
import numpy as np
def get_data(data_path):
if os.path.exists(data_path):
datas = np.load(data_path, allow_pickle=True)
data = datas['data']
word2ix = datas['word2ix'].item()
ix2word = datas['ix2word'].item()
print('The data is loaded successfully.')
return data, word2ix, ix2word
else:
print('[ERROR]No such file was found or the specified path name doesn\'t exist.')
exit(-1)
model.py - 定义神经网络模型
import torch
import torch.nn as nn
from torch.autograd import Variable
class LSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(LSTM, self).__init__()
self.hidden_dim = hidden_dim
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2, batch_first=False)
self.linear = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input_, hidden=None):
seq_len, batch_size = input_.size()
if hidden is None:
h_0 = input_.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input_.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
h_0, c_0 = Variable(h_0), Variable(c_0)
else:
h_0, c_0 = hidden
embed = self.embedding(input_)
output, hidden = self.lstm(embed, (h_0, c_0))
output = self.linear(output.reshape(seq_len * batch_size, -1))
return output, hidden
train.py - 训练神经网络
import os
import tqdm
from sklearn.model_selection import train_test_split
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from get_data import get_data
from model import LSTM
if not os.path.exists('./model/'):
os.mkdir('./model/')
DATA_PATH = './data/tang.npz'
BATCH_SIZE = 64
LEARNING_RATE = 1e-3
EMBEDDING_DIM = 128
HIDDEN_DIM = 256
EPOCH = 50
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('[LSTM model is being trained using the {}]'.format('GPU' if torch.cuda.is_available() else 'CPU'))
data, word2ix, ix2word = get_data(DATA_PATH)
_, data_eval = train_test_split(data, train_size=0.8, random_state=1)
data_train, data_eval = torch.from_numpy(data), torch.from_numpy(data_eval)
data_loader_train = DataLoader(data_train, batch_size=BATCH_SIZE, shuffle=True)
data_loader_eval = DataLoader(data_eval, batch_size=BATCH_SIZE, shuffle=True)
model = LSTM(len(word2ix), EMBEDDING_DIM, HIDDEN_DIM).to(device)
# model.load_state_dict(torch.load('./model/LSTM.pth', map_location=device))
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, betas=(0.9, 0.999), eps=1e-8)
criterion = nn.CrossEntropyLoss()
for epoch in range(1, EPOCH + 1):
train_loss = 0
train_step = 0
model.train()
for i, data in tqdm.tqdm(enumerate(data_loader_train)):
data = data.long().transpose(0, 1).contiguous().to(device)
optimizer.zero_grad()
input_, target = Variable(data[:-1, :]), Variable(data[1:, :])
output, _ = model(input_)
loss = criterion(output, target.view(-1))
loss.backward()
optimizer.step()
train_loss += loss.item()
train_step += 1
eval_loss = 0
eval_step = 0
model.eval()
for i, data in tqdm.tqdm(enumerate(data_loader_eval)):
data = data.long().transpose(0, 1).contiguous().to(device)
input_, target = Variable(data[:-1, :]), Variable(data[1:, :])
output, _ = model(input_)
loss = criterion(output, target.view(-1))
eval_loss += loss.item()
eval_step += 1
print('[{:2d}/{:2d}] Train Loss: {:6.4f} | Eval Loss: {:6.4f}'.format(epoch, EPOCH, train_loss / train_step,
eval_loss / eval_step))
torch.save(model.state_dict(), './model/LSTM_epoch{}.pth'.format(epoch))
print('Training completed.')
上面代码中的第18-23行是网络训练的一些参数,可以根据自己的实际情况手动调节。我在训练中采取的策略是每次将EPOCH设置为一个较小的数字(比如20或50),选定一个合适的LEARNING_RATE进行训练,并且保存每轮训练后的模型参数。一次训练结束后,可以考虑在下一次训练中加载预训练的LSTM.pth参数并且调整LEARNING_RATE进行训练。
一些比较好的AI生成诗句
- 里巷风尘起,南山杨柳深。
- 不堪捎落叶,空想抱秋心。
- 十日花落尽,一朝春景浓。
- 远期千里别,明日一时愁。
- 如闻北斗月,又见南山泉。
- 心事不可得,无心亦无疑。
- 永日无人见,春风不自由。
- 远山开旧岭,清净入深州。