【人工智能】鸢尾花数据集KMeans的C++实现

小王今天也要努力啊~
报告内容
一.问题描述
鸢尾花数据集是一个经典数据集,有四个维度,即花卉的四项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,数据集同时对应给出了鸢尾花的种类(标签),共150条数据。已知三种不用的鸢尾花种类:Iris-setosa,Iris-versicolor,Iris-virginica(刚毛,变色,弗吉尼亚)。本项目需要在没有先验知识的情况下,只通过这四项特征判断鸢尾花的品种,实现无监督聚类。
本文将使用K-Means对Iris进行聚类分析,基于C++实现。
二.算法内容
K-Means算法是一种聚类算法,根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。
K代表类簇个数,Means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述)K-Means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,包括欧氏距离、曼哈顿距离、余弦距离、马氏距离等,K-Means中常用欧氏距离。
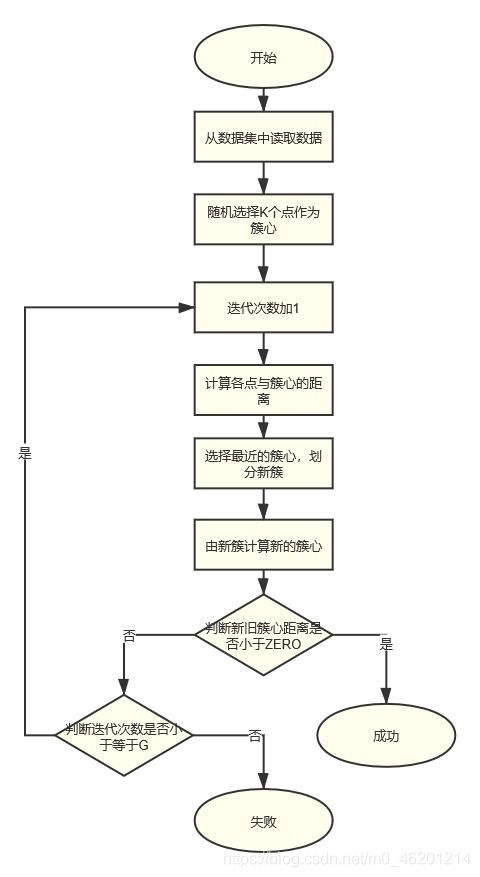
(一)算法描述
- 随机选择K个点(由数据集得出K=3)作为簇心;
- 计算数据集中各点与簇心的距离,选择距离最小的簇心,则该点属于这个簇心;
- 对各个簇通过求各点均值(Means)的方法重新求簇心
- 比较新簇心与旧簇心的距离,如果相差小于ZERO,则完成算法;否则,迭代次数加1,若迭代次数小于等于G,则返回2,若迭代次数大于G,则失败
算法流程图如下图所示:
(二)核心算法模块描述:(全部代码可见附录)
获得新的聚类中心
获得新簇中心有两种情况,第一种情况是当刚开始操作时,将随机选择三个数据点作为聚类中心,用时间随机种子和取余运算来确保选点的随机性。
srand((int)time(NULL));
x = rand()%length;
y = rand()%length;
z = rand()%length;
将各聚类中心的值分别放在center中保存:
for(i=0;i<CASE;i++){
center[0][i]=table[x].feature[i];
}
第二种情况时已有各簇并需要更新簇时,此时将计算被分得同一种类的各簇的四个属性值的平均值作为新簇的中心,流程图如下:
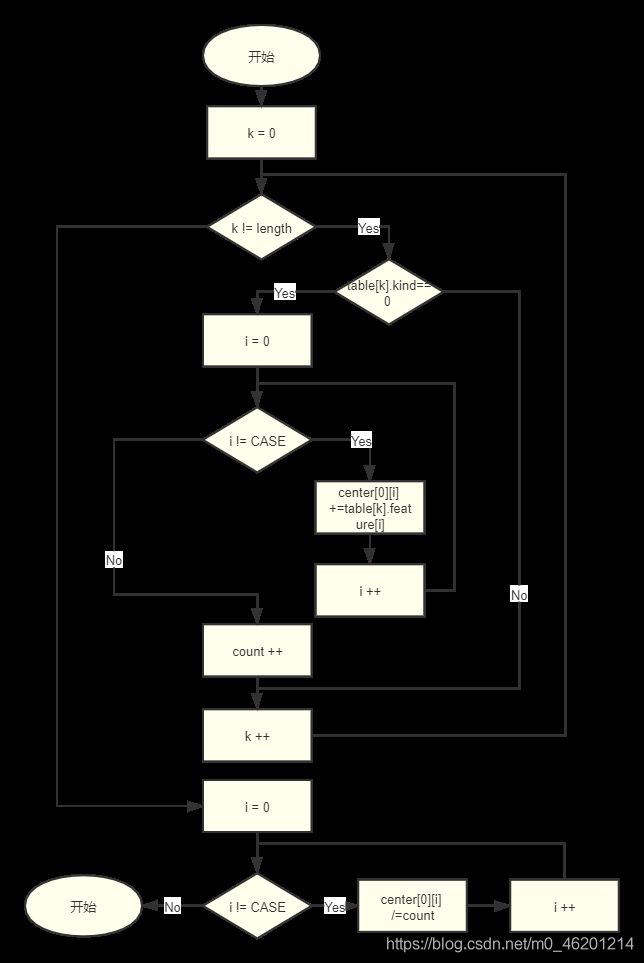
代码如下(由于本段代码有较多重复,完整代码详见附录)
for(k=0; k!=length; k++){
if(table[k].kind == 0){
count1++;
for(i=0; i<CASE; i++){
centers[0][i]+=table[k].feature[i];
}
}
}
for(i=0 ; i <CASE; i++){
centers[0][i]/=count1;
}
在此模块中可以加上算法结束的一个终止条件,即聚类中心点不发生变化,但考虑到这个条件较为苛刻,本项目引入了参数ZERO表示一个接近于0的值(经实验后设为0.01,实验过程见下文),具体代码如下:
for(i=0;i<K;i++){
for(j=0;j<CASE;j++){
difference = abs( centers[i][j]-center[i][j]);
center[i][j]=centers[i][j];
}
}
if(difference<ZERO) return SUCCESS; //曾经的终止条件
else return CONTINUE;
更新簇
更新簇的操作实际上是把每朵鸢尾花的种类重新分配。根据数据点到聚类中心的距离,比较发现离本数据点最近的聚类中心,则该数据点将被划分为此聚类中心代表的簇中。具体代码如下:
for(k=0;k!=length;k++){
//计算每个点距离各簇中心的距离(欧氏距离)
for(i=0;i!=K;i++){
for(j=0;j<CASE;j++){
//欧式距离
table[k].distance[i] += sqrt(
(center[i][j]-table[k].feature[j])
*(center[i][j]-table[k].feature[j]));
//曼哈顿距离
/* table[k].distance[i] += abs(center[i][j]-table[k].feature[j]); */
}
}
//寻找最小距离
float shortest = (table[k].distance[0] < table[k].distance[1])
? table[k].distance[0]:table[k].distance[1];
shortest = (shortest < table[k].distance[2])
? shortest:table[k].distance[2];
for(i=0;i<K;i++){
if(table[k].distance[i]==shortest){
if(table[k].kind==i) count++;
else table[k].kind=i;
}
}
}
其中count记录了前后两次分簇相同的数据点的个数。在此部分中,可以加入算法结束的另一个终止条件:当各个数据点前后两次分簇情况都不发生变化。代码如下:
if(length == count ) return SUCCESS;
else return CONTINUE;
(三)算法参数
K:由分析鸢尾花数据集已知,共有三种类别,所以K=3
CASE:已知四种不同属性,设置CASE=4
ZERO:根据几次调试将ZERO设为0.01。在调试过程中,发现:当ZERO小于0.01时(0.001、0.00001),迭代次数出现了缓慢增长,但输出正确率并没有发生很大改变;当ZERO大于0.01时(0.1),迭代次数没有较大变化,成功率的均值也较好,但出现了较大的振荡。
G:由测试得出,数据集往往在10代以内迭代完成,将G稍微放宽一点,设为20
三.运行结果及分析
输出数据从左向右依次为鸢尾花的四个特征(feature)、真实种类(truth_value)和聚类后所属种类(kind)。真实种类代表的数字和分类后所打标签数字可能不同(即可能1对映2,2对映0等),是初始随机分簇时的不同顺序造成的,并不影响最终效果。末尾三行输出是否成功,经历迭代次数和聚类正确率。部分运行结果截图如下:
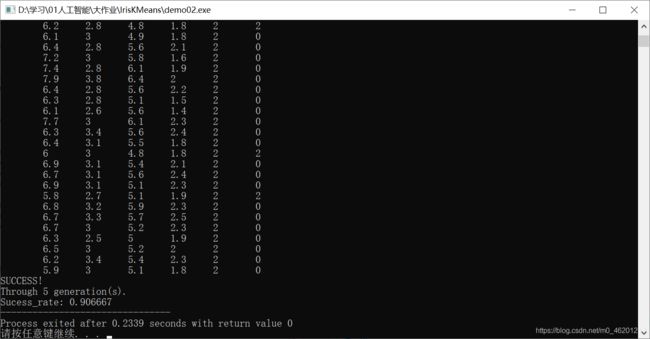
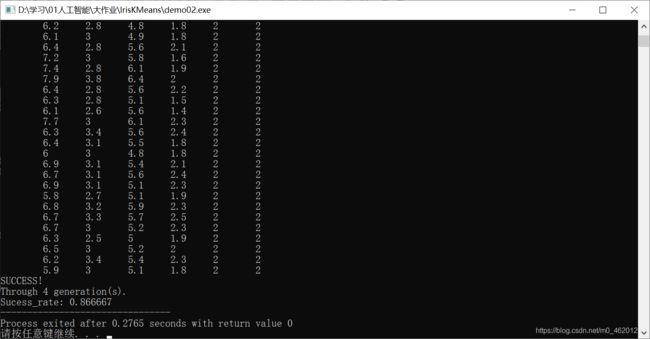
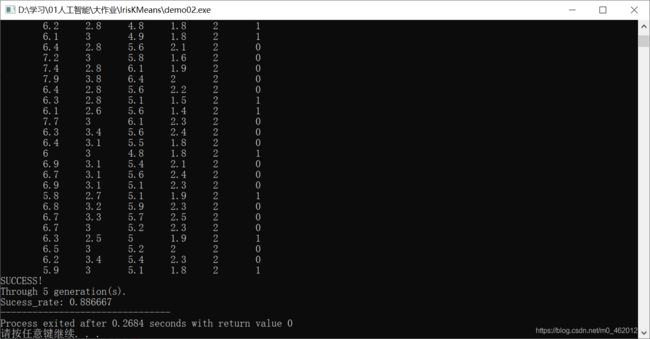
由运行结果可得,绝大多数都聚类成功(测试并未出现聚类失败情况),在10代以内可以完成聚类,聚类成功率在80%以上。通过图片的联合分析,鸢尾花的三类中,处于左下角的一类(Iris-setosa,在代码中truth_value表示为0)聚类效果非常好,但右上角的两类(Iris-versicolor,在代码中truth_value表示为1;Iris-virginica,在代码中truth_value表示为2)由于距离较近,聚类效果欠佳。
1.距离:
对比欧式距离和曼哈顿距离,欧式距离效果更好:迭代次数起伏较大,从2代到大于50代不等;且正确率不稳定,从0.78到0.92不等。 最终仍采用欧氏距离。
2.算法终止条件:
原算法:当新旧两个簇中心之间距离小于ZERO时,结束算法;限制改为当各点前后两次分簇相同时,结束算法。
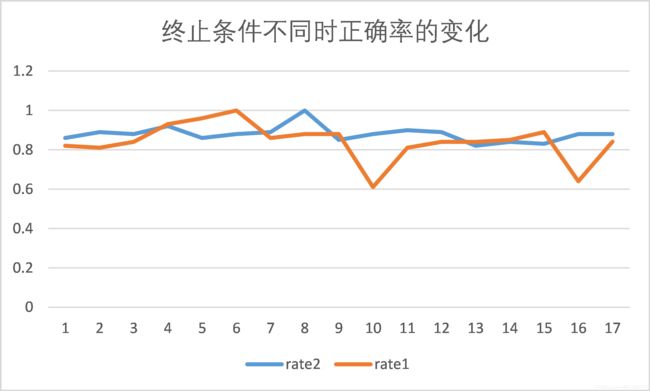
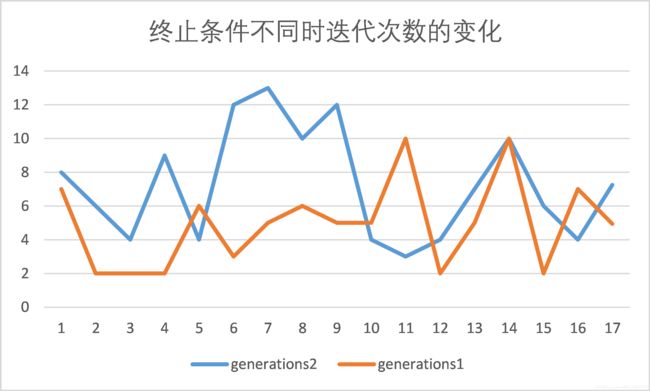
随机测试实验发现改为新的终止条件后,平均迭代次数增加,平均正确率也提高了。
四.算法改进
1.关于初始聚类中心的改进
改进缘由:发现算法中正确率与迭代次数几乎无关(corr=0.095865),但正确率上下波动很大,故猜测主要原因是KMeans对初始聚类中心的选择敏感。
通过查阅资料,本项目使用KMeans++算法进行改进。该算法的核心思想是,在选择初始簇中心时,尽量选择距离较远的数据点作为聚类中心;一开始就足够分散,则不会出现病态初始化的问题了。
主要方法是:首先随机选择第一个聚类中心,然后以概率D_i/(sum(D_i))选择第i个数据点作为下一个聚类中心,依次重复,直到找到所有聚类中心。
但实际在操作时,概率事件在程序中是可以用随机数模拟的,这里以概率p选择下一个聚类中心正是利用了用随机数模拟概率事件的思想。首先统计所有点到每一个聚类中心的最近距离,这个距离存放在数组d中,所有最近距离的和为sum,随机从0~sum间选择一个数,出现两种情况,第一种:d[i]很大,记为dmax;第二种:d[i]很小,记为dmin,则sum - dmax比sum - dmin更容易打破大于0这个条件;同时,一旦大于0的条件被打破,就可以选择对应于d[i]的点作为我们的聚类中心。这就是以概率D_i/(sum(D_i))选择第i个数据点作为下一个聚类中心的具体实现。下面是KMeans++的部分代码:
template<typename Real, int Dim>
void KMeans<Real, Dim>::kpp(vector<KmPoint> &pts, vector<KmPoint> ¢s){
Real sum = 0;
vector<Real> d;
d.resize(pts.size());
cents[0] = pts[rand() % pts.size()];
vector<KmPoint> tmpCents;
tmpCents.push_back(cents[0]);
for(int k = 1; k < (int)cents.size(); ++k){
sum = 0;
for(int i = 0; i < (int)pts.size(); ++i){
nearest(pts[i], tmpCents, d[i]);
sum += d[i];
}
sum = randf(sum);
for(int i = 0; i < (int)pts.size(); ++i){
<strong>if((sum -= d[i]) > 0) continue;</strong>
cents[k] = pts[i];
tmpCents.push_back(cents[k]);
break;
}
}
for(int i = 0; i < (int)pts.size(); ++i){
int id = nearest(pts[i], cents, *(new Real));
pts[i].setId(id);
}
}
这部分有所引用,原博见参考网址
2.关于聚类方法的改进
改进缘由:分析得到鸢尾花右下角的聚类效果较好,但相邻两簇效果始终不如意,由于KMeans只能将类似圆形的聚类在一起,故尝试基于密度的DBSCAN和层次聚类agnes。
尝试前在网上搜索学习了一些前人的工作,发现在鸢尾花数据集上,Agnes效果与kmeans相差不大,但DBSCAN的效果不尽人意。
因而在实际操作中并没有尝试Agnes和DBSCAN的方法。
这部分有所引用,原博见参考网址
五.学习与收获
通过本次项目的实践,深入理解了KMeans具体实现方方面面的细节,在编写代码的过程中发现了许多之前单单在学习KMeans基本思路时并没有发现的问题,也收获到了许多新的东西。由于之前没有仔细看过KMeans的聚类效果,在调试成功后,其迭代次数之少与正确率之高超过了我的预期,让我感受到了这简单想法背后的大智慧。然而在Agnes和DBSCAN在鸢尾花上的实现后我更深层地意识到,对于不同的问题不同的数据集,需要有不同的方法有针对性地去解决,每种方法都有自己的适用范围。
在本节课程上,对人工智能领域的基本介绍,从身边的人工智能、人工智能的背景与发展史——三次浪潮迭起,到一些搜索算法、逻辑与推理相关知识,到进化算法、群智能优化和最后的机器学习,在这个领域下林林总总方方面面的接触,不管是概念领悟,还是算法思路的理解,甚至部分算法的实践,都让我感受到了人工智能的魅力与广阔的前景。用人工的方法在机器上实现的智能,人工智能是人类显性智慧的人工实现。通过这堂课,我明白了人工智能发展的历史和所处的地位,它始终处于计算机发展的最前沿。我相信人工智能在不久的将来会得到更深一步的实现,会创造出一个全新的人工智能世界。
六.参考文献及网址
鸢尾花数据集分析
https://www.jianshu.com/p/52b86c774b0b
鸢尾花数据的三种聚类:分散聚类kmeans层次聚类agnes密度聚类dbscan
https://blog.csdn.net/weixin_42134141/article/details/80413598
kmeans++算法的C++实现
https://blog.csdn.net/zhouliyang1990/article/details/25188267
完整代码
// IrisDataSetK-Means demo02
#include
}
int Cluster::Update_NewCluster(){
int i,j,k;
int count = 0;
int length = table.size();
for(k=0;k!=length;k++){
//计算每个点距离各簇中心的距离(欧氏距离)
for(i=0;i!=K;i++){
for(j=0;j<CASE;j++){
//欧式距离
table[k].distance[i] += sqrt(
(center[i][j]-table[k].feature[j])
*(center[i][j]-table[k].feature[j]));
//曼哈顿距离
/* table[k].distance[i] += abs(center[i][j]-table[k].feature[j]);*/
}
}
//寻找最小距离
float shortest = (table[k].distance[0] < table[k].distance[1])
? table[k].distance[0]:table[k].distance[1];
shortest = (shortest < table[k].distance[2])
? shortest:table[k].distance[2];
for(i=0;i<K;i++){
if(table[k].distance[i]==shortest){
if(table[k].kind==i) count++;
else table[k].kind=i;
}
}
}
if(length == count ) return SUCCESS;
else return CONTINUE;
}
void Cluster::success_rate(){
int i,j,success=0;
int length = table.size();
int feature[K][K]={
0};
int key[K];
for(i=0;i!=length;i++){
if(table[i].truth_value == 0){
if(table[i].kind == 0) feature[0][0]++;
if(table[i].kind == 1) feature[0][1]++;
if(table[i].kind == 2) feature[0][2]++;
}
else if(table[i].truth_value == 1){
if(table[i].kind == 0) feature[1][0]++;
if(table[i].kind == 1) feature[1][1]++;
if(table[i].kind == 2) feature[1][2]++;
}
else if(table[i].truth_value == 2){
if(table[i].kind == 0) feature[2][0]++;
if(table[i].kind == 1) feature[2][1]++;
if(table[i].kind == 2) feature[2][2]++;
}
}
for(i=0;i!=K;i++){
if(feature[i][0]>feature[i][1] && feature[i][0]>feature[i][2])
key[i]=0;
else if(feature[i][1]>feature[i][0] && feature[i][1]>feature[i][2])
key[i]=1;
else if(feature[i][2]>feature[i][0] && feature[i][2]>feature[i][0])
key[i]=2;
}
for(j=0;j!=length;j++){
if(table[j].kind == key[table[j].truth_value]) success++;
}
result=(float)success/length;
}
void Cluster::show(int condition, int generation){
int length=table.size();
int i,j;
for(i=0;i!=length;i++){
for(j=0;j!=CASE;j++){
cout<<"\t"<<table[i].feature[j];
}
cout<<"\t"<<table[i].truth_value<<"\t"<<table[i].kind<<endl;
}
if(condition==SUCCESS){
cout<<"SUCCESS!"<<endl;
cout<<"Through "<<generation+1<<" generation(s)."<<endl;
cout<<"Sucess_rate: "<<result;
}
if(condition==CONTINUE){
cout<<"Not Convergence!"<<endl;
cout<<"Sucess_rate: "<<result;
}
}
int main(){
Cluster clusters;
int generation=0,condition=0;
clusters.get_Data(); //获取数据
clusters.get_FirstCenter(); //随机取簇中心
for(generation=0;generation<G;generation++){
//迭代
condition = clusters.Update_NewCluster(); //根据簇中心重新分簇
clusters.get_NewCenter(); //根据新簇获得新的簇中心
clusters.success_rate(); //计算成功分簇的百分比
if(condition==SUCCESS) break; //如果簇不再改变则跳出循环
}
clusters.show(condition,generation); //显示结果
}
- 以上内容为博主大作业
虽然辛苦,我还是会选择那种滚烫的人生(北野武)