java 分布式任务队列_分布式任务队列Celery
分布式任务队列Celery
Celery (芹菜)是基于Python开发的分布式任务队列。它支持使用任务队列的方式在分布的机器/进程/线程上执行任务调度。
结构
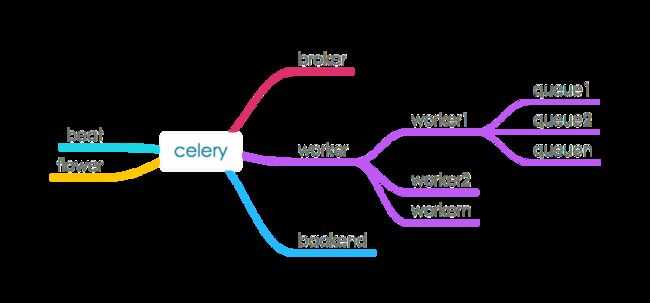
核心部件
broker
消息队列,由第三方消息中间件完成
常见有RabbitMQ, Redis, MongoDB等
worker
任务执行器
可以有多个worker进程
worker又可以起多个queue来并行消费消息
backend
后端存储,用于持久化任务执行结果
功能部件
beat
定时器,用于周期性调起任务
flower
web管理界面
任务
基本用法是在程序里引用celery,并将函数方法绑定到task
from celery import Celery
app = Celery('tasks', backend='amqp', broker='amqp://guest@localhost//')
app.conf.CELERY_RESULT_BACKEND = 'db+sqlite:///results.sqlite'
@app.task
def add(x, y):
return x + y
然后调用相应方法即可(delay与apply_async都是异步调用)
from tasks import add
import time
result = add.delay(4,4)
while not result.ready():
print "not ready yet"
time.sleep(5)
print result.get()
由于是采用消息队列,因此任务提交之后,程序立刻返回一个任务ID。
之后可以通过该ID查询该任务的执行状态和结果。
关联任务
执行1个任务,完成后再执行第2个,第一个任务的结果做第二个任务的入参
add.apply_async((2, 2), link=add.s(16))
结果:2+2+16=20
还可以做错误处理
@app.task(bind=True)
def error_handler(self, uuid):
result = self.app.AsyncResult(uuid)
print('Task {0} raised exception: {1!r}\n{2!r}'.format(
uuid, result.result, result.traceback))
add.apply_async((2, 2), link_error=error_handler.s())
定时任务
让任务在指定的时间执行,与下文叙述的周期性任务是不同的。
ETA, 指定任务执行时间,注意时区
countdown, 倒计时,单位秒
from datetime import datetime, timedelta
tomorrow = datetime.utcnow() + timedelta(seconds=3)
add.apply_async((2, 2), eta=tomorrow)
result = add.apply_async((2, 2), countdown=3)
tip
任务的信息是保存在broker中的,因此关闭worker并不会丢失任务信息
回收任务(revoke)并非是将队列中的任务删除,而是在worker的内存中保存回收的任务task-id,不同worker之间会自动同步上述revoked task-id。
由于信息是保存在内存当中的,因此如果将所有worker都关闭了,revoked task-id信息就丢失了,回收过的任务就又可以执行了。要防治这点,需要在启动worker时指定一个文件用于保存信息
celery -A app.celery worker --loglevel=info &> celery_worker.log --statedb=/var/tmp/celery_worker.state
过期时间
expires单位秒,超过过期时间还未开始执行的任务会被回收
add.apply_async((10, 10), expires=60)
重试
max_retries:最大重试次数
interval_start:重试等待时间
interval_step:每次重试叠加时长,假设第一重试等待1s,第二次等待1+n秒
interval_max:最大等待时间
add.apply_async((2, 2), retry=True, retry_policy={
'max_retries': 3,
'interval_start': 0,
'interval_step': 0.2,
'interval_max': 0.2,
})
序列化
将任务结果按照一定格式序列化处理,支持pickle, JSON, YAML and msgpack
add.apply_async((10, 10), serializer='json')
压缩
将任务结果压缩
add.apply_async((2, 2), compression='zlib')
任务路由
使用-Q参数为队列(queue)命名,然后调用任务时可以指定相应队列
$ celery -A proj worker -l info -Q celery,priority.high
add.apply_async(queue='priority.high')
工作流
按照一定关系一次调用多个任务
group: 并行调度
chain: 串行调度
chord: 类似group,但分header和body2个部分,header可以是一个group任务,执行完成后调用body的任务
map: 映射调度,通过输入多个入参来多次调度同一个任务
starmap: 类似map,入参类似*args
chunks:将任务按照一定数量进行分组
group
from celery import group
>>> res = group(add.s(i, i) for i in xrange(10))()
>>> res.get(timeout=1)
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
chain
>>> from celery import chain
# 2 + 2 + 4 + 8
>>> res = chain(add.s(2, 2), add.s(4), add.s(8))()
>>> res.get()
16
可以用|来表示chain
# ((4 + 16) * 2 + 4) * 8
>>> c2 = (add.s(4, 16) | mul.s(2) | (add.s(4) | mul.s(8)))
>>> res = c2()
>>> res.get()
chord
>>> from celery import chord
#1*2+2*2+...9*2
>>> res = chord((add.s(i, i) for i in xrange(10)), xsum.s())()
>>> res.get()
90
map
>>> from proj.tasks import add
>>> ~xsum.map([range(10), range(100)])
[45, 4950]
starmap
>>> ~add.starmap(zip(range(10), range(10)))
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
chunks
>>> from proj.tasks import add
>>> res = add.chunks(zip(range(100), range(100)), 10)()
>>> res.get()
[[0, 2, 4, 6, 8, 10, 12, 14, 16, 18],
[20, 22, 24, 26, 28, 30, 32, 34, 36, 38],
[40, 42, 44, 46, 48, 50, 52, 54, 56, 58],
[60, 62, 64, 66, 68, 70, 72, 74, 76, 78],
[80, 82, 84, 86, 88, 90, 92, 94, 96, 98],
[100, 102, 104, 106, 108, 110, 112, 114, 116, 118],
[120, 122, 124, 126, 128, 130, 132, 134, 136, 138],
[140, 142, 144, 146, 148, 150, 152, 154, 156, 158],
[160, 162, 164, 166, 168, 170, 172, 174, 176, 178],
[180, 182, 184, 186, 188, 190, 192, 194, 196, 198]]
周期性任务
周期性任务就是按照一定的时间检查反复执行的任务。前面描述的定时任务值的是一次性的任务。
程序中引入并配置好周期性任务后,beat进程就会定期调起相关任务
beat进程是需要单独启动的
$ celery -A proj beat
或者在worker启动时一起拉起
$ celery -A proj worker -B
注意一套celery只能启一个beat进程
时区配置
由于python中时间默认是utc时间,因此最简便的方法是celery也用utc时区
CELERY_TIMEZONE = 'UTC'
这么配置可以保证任务调度的时间是准确的,但由于服务器一般都配置时区,因此flower、以及日志中的时间可能会有偏差
另外一种方法,就是配置正确的时区
CELERY_TIMEZONE = 'Asia/Shanghai'
然后任务调起时,将时间带入时区配置
local_tz = pytz.timezone(app.config['CELERY_TIMEZONE'])
format_eta = local_tz.localize(datetime.strptime(eta.strip(), '%Y/%m/%d %H:%M:%S'))
add.apply_async((2, 2),eta=format_eta)
周期性任务配置
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': timedelta(seconds=30),
'args': (16, 16)
},
}
周期性任务配置crontab
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
# Executes every Monday morning at 7:30 A.M
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}
总结
celery功能非常强大,与django、flask等web应用配合相得益彰,推荐给大家。
本文参考官方文档