python常用的基本内置函数
1、enumerate():自动得到下标和值
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print i, element
0 one
1 two
2 three
遍历删除
# 带条件按下标删除用pop
list_a = [1,2,3,4,2]
for i,v in enumerate(list_a):
if i == 2 or i == 3:
list_a.pop(i)
print list_a
# 带条件按值删除用remove
for i,v in enumerate(list_a):
if v == 2:
list_a.remove(v)
print list_a
# 全部删除,list_a[:]python为切片列表创建了新对象, 迭代副本
for index, item in enumerate(list_a[:]):
list_a.remove(item)
print(list_a)
2、eval():用来执行一个字符串表达式,并返回表达式的值。
print eval("9+9")
18
3、isinstance()和type():来判断一个对象是否是一个已知的类型
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
a = 2
isinstance (a,int)
True
isinstance (a,str)
False
isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
4、pow(x,y)和math.pow(x,y):返回 xy(x 的 y 次方) 的值
import math
math.pow(3,2)
9.0
pow(3,2)
9
5、sum(): 对序列进行求和计算
sum([0,1,2])
3
sum((2, 3, 4), 1) # 元组计算总和后再加 1
10
sum([0,1,2,3,4], 2) # 列表计算总和后再加 2
12
6、abs() :返回数字的绝对值。
print "abs(-45) : ", abs(-45)
print "abs(100.12) : ", abs(100.12)
print "abs(119L) : ", abs(119L)
abs(-45) : 45
abs(100.12) : 100.12
abs(119L) : 119
7、divmod() :把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)
print "abs(-45) : ", abs(-45)
print "abs(100.12) : ", abs(100.12)
print "abs(119L) : ", abs(119L)
abs(-45) : 45
abs(100.12) : 100.12
abs(119L) : 119
8、input() :它希望能够读取一个合法的 python 表达式
raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)
除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw_input() 来与用户交互
print raw_input("输入:")
print input("输入:")
输入:eval('9+9')
eval('9+9')
输入:eval('9+9')
18
9、 open() :用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
open(name, mode, buffering)
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读®。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
model输入值代表的意思
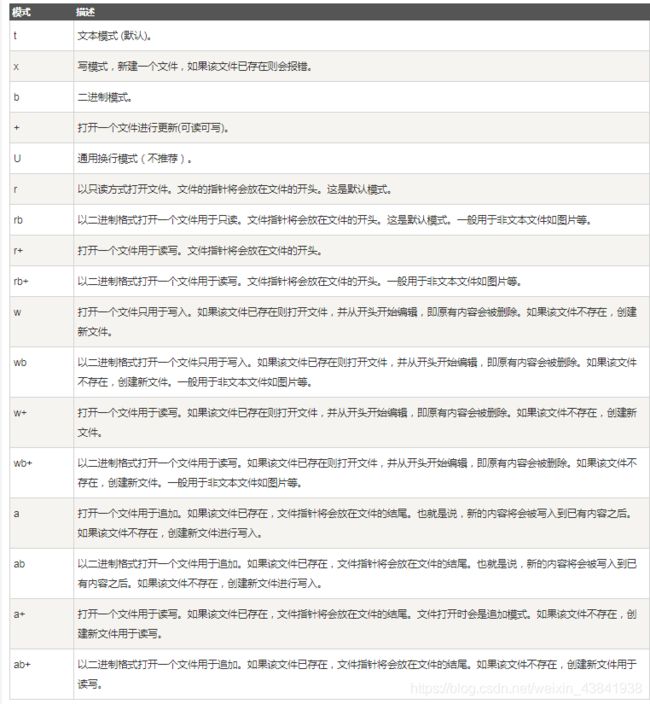
open("test.txt", "w+", "0")
10、@staticmethod: 返回函数的静态方法。
class C(object):
@staticmethod
def f():
print('runoob');
C.f(); # 静态方法无需实例化
cobj = C()
cobj.f() # 也可以实例化后调用
11、issubclass: 用于判断参数 B是否是类型参数 A的子类。
issubclass(B,A)
12、filter() :用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
def is_odd(n):
return n % 2 == 1
newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(newlist)
13、len():返回对象(字符、列表、元组等)长度或项目个数
str = "runoob"
len(str) # 字符串长度
6
l = [1,2,3,4,5]
len(l) # 列表元素个数
5
14、range() :可创建一个整数列表,一般用在 for 循环中
>>>range(10) # 从 0 开始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 从 1 开始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 30, 5) # 步长为 5
[0, 5, 10, 15, 20, 25]
>>> range(0, 10, 3) # 步长为 3
[0, 3, 6, 9]
>>> range(0, -10, -1) # 负数
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0)
[]
>>> range(1, 0)
[]
>>>x = 'runoob'
>>> for i in range(len(x)) :
... print(x[i])
15、len():返回对象(字符、列表、元组等)长度或项目个数
str = "runoob"
len(str) # 字符串长度
6
l = [1,2,3,4,5]
len(l) # 列表元素个数
5
16、format ():可以接受不限个参数,位置可以不按顺序
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
17、reduce() :会对参数序列中元素进行累积
def add(x,y):
return x + y
sum1 = reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5
sum2 = reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数
print(sum1)
print(sum2)
15
15
18、map() :会根据提供的函数对指定序列做映射
>>> def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
19、cmp(x,y) :用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
cmp(80, 100) : -1
cmp(180, 100) : 1
cmp(-80, 100) : -1
cmp(80, -100) : 1
20、max()和min() :返回给定参数的最大值/最小值,参数可以为序列。
max(80, 100, 1000) : 1000
max(-20, 100, 400) : 400
max(-80, -20, -10) : -10
max(0, 100, -400) : 100
min(0, 100, -400) : -400
21、reverse() :没有返回值,但是会对列表的元素进行反向排序。
aList = [123, 'xyz', 'zara', 'abc', 'xyz']
aList.reverse()
print "List : ", aList
List : ['xyz', 'abc', 'zara', 'xyz', 123]
22、zip(x) :用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
zip(*x)返回二维矩阵式
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
23、round(x,n) :返回浮点数x的四舍五入值。
x – 数值表达式。
n – 数值表达式,表示从小数点位数。从下标0开始,如果不填写n默认为0
print "round(80.25456, 0) : ", round(80.25456, 0)
print "round(80.25456, 1) : ", round(80.25456, 1)
print "round(80.25456, 2) : ", round(80.25456, 2)
round(80.25456, 0) : 80.0
round(80.25456, 1) : 80.3
round(80.25456, 3) : 80.25
24、set() :创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
x = set('runoob')
y = set('google')
print x, y
print x & y # 交集
print x | y # 并集
print x - y # 差集
set(['b', 'r', 'u', 'o', 'n']) set(['e', 'o', 'g', 'l'])
set(['o'])
set(['b', 'e', 'g', 'l', 'o', 'n', 'r', 'u'])
set(['r', 'b', 'u', 'n'])
25、dict():用于创建一个字典。(类似java中的map)
>>>dict() # 创建空字典
{}
>>> dict(a='a', b='b', t='t') # 传入关键字
{'a': 'a', 'b': 'b', 't': 't'}
>>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典
{'three': 3, 'two': 2, 'one': 1}
>>> dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典
{'three': 3, 'two': 2, 'one': 1}
26、slice():实现切片对象,主要用在切片操作函数里的参数传递。
class slice(stop)
class slice(start, stop[, step])
start – 起始位置
stop – 结束位置
step – 间距
>>> arr = range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> arr[slice(5)] # 截取 5 个元素
[0, 1, 2, 3, 4]
27、sorted() :对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
L = [('b',1),('a',2),('c',1),('d',4)]
print sorted(L, cmp=lambda x,y:cmp(x[0],y[0])) # 利用cmp函数,比较每个元组下标为0的值来进行排序
print sorted(L, key=lambda x:x[1]) # 利用key,按每个元组下表为1的值排序
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
print sorted(students, key=lambda x: x[2],reverse=True) # 按年龄排序,reverse=True降序,reverse=False升序,默认为升序