HOT100刷题,各类题型记录
文章目录
- 双指针(三指针、快慢指针)
-
- 11. 盛最多水的容器
- 15. 三数之和
- 19. 删除链表的倒数第 N 个结点
- 回溯
-
- 17. 电话号码的字母组合
-
- 回溯(用StringBuilder,最后需要撤销,即回溯)
- DFS(用String,最后不需要撤销,即DFS)
- 22. 括号生成
- 栈
-
- 20. 有效的括号
- 递归
-
- 21. 合并两个有序链表
- 看规律、归纳
-
- 31. 下一个排列
双指针(三指针、快慢指针)
11. 盛最多水的容器
参考
15. 三数之和
参考
19. 删除链表的倒数第 N 个结点
参考
回溯
- 回溯讲解及练习例题
17. 电话号码的字母组合
参考
模式识别
- 关键字:
所有组合
首先想到穷举,需要搜索算法-----回溯


- 向上的箭头代表回溯
回溯(用StringBuilder,最后需要撤销,即回溯)
class Solution {
ArrayList<String> res;
HashMap<Character , String> map;
public List<String> letterCombinations(String digits) {
res = new ArrayList<>();
if(digits.length() == 0) return res;
map = new HashMap<>();
map.put('2' , "abc");
map.put('3' , "def");
map.put('4' , "ghi");
map.put('5' , "jkl");
map.put('6' , "mno");
map.put('7' , "pqrs");
map.put('8' , "tuv");
map.put('9' , "wxyz");
StringBuffer tempCombination = new StringBuffer();
dfs(digits , 0 , tempCombination);
return res;
}
void dfs(String digits , int index , StringBuffer tempCombination){
if(index == digits.length()) res.add(tempCombination.toString());
else{
char letter = digits.charAt(index);
String s = map.get(letter);
for(int i = 0 ; i < s.length() ; i++){
dfs(digits , index + 1 , tempCombination.append(s.charAt(i)));
tempCombination.deleteCharAt(index);
}
}
}
}
DFS(用String,最后不需要撤销,即DFS)
class Solution {
ArrayList<String> res;
HashMap<Character , String> map;
public List<String> letterCombinations(String digits) {
res = new ArrayList<>();
if(digits.length() == 0) return res;
map = new HashMap<>();
map.put('2' , "abc");
map.put('3' , "def");
map.put('4' , "ghi");
map.put('5' , "jkl");
map.put('6' , "mno");
map.put('7' , "pqrs");
map.put('8' , "tuv");
map.put('9' , "wxyz");
//StringBuffer tempCombination = new StringBuffer();
String tempCombination = "";
dfs(digits , 0 , tempCombination);
return res;
}
void dfs(String digits , int index , String tempCombination){
if(index == digits.length()) res.add(tempCombination);
else{
char letter = digits.charAt(index);
String s = map.get(letter);
for(int i = 0 ; i < s.length() ; i++){
dfs(digits , index + 1 , tempCombination + s.charAt(i));
//tempCombination.deleteCharAt(index);
}
}
}
}
注:由上可看出,回溯是使用DFS工具的一个算法,即回溯=DFS+撤销(剪枝);
用StringBulider是回溯;用String是DFS的原因
- 【利用String的不可变特性,不用处理,StringBulider的可变特性,得处理】
1、
StringBuilder对象是可变特性,所以元素传入的都是同一个对象,所以在递归完成之后必须撤回上一次的操作,需要删除上一次添加的字符。而String是不可变特性的,每次改变之后,元素传入的都是不同的对象。故无需撤销操作。
比如:用StringBuilder时,如果不删除,在for循环里,下一次运行时,tempCombination数据就被污染了。(ad,ae)变成(ad,ade)。
流程是:a进入StringBuilder对象,b接着进入,由于StringBuilder的可变性,下一次的e还是添加在同一个StringBuilder对象,出错;所以在完成一次搜索后要删除上一个字符,作为回溯。
用String时,可理解为递归函数返回时,自动回溯。
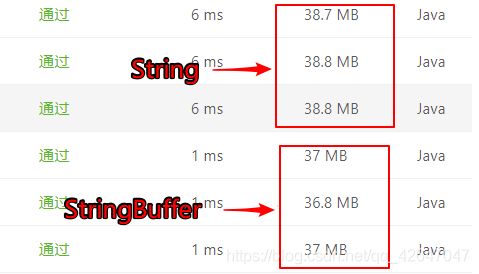
用StringBulider和String所占资源对比
由于String的不可变性,每次拼接操作会创建一个新的String对象,会占相对较多资源;而StringBulider是可变的,每次操作的是同一个StringBulider对象,不需要创建多个对象,会占相对较少资源。从下面两种方法的空间复杂度可看出:
22. 括号生成
参考
这一类问题是在一棵隐式的树上求解,可以用深度优先遍历,也可以用广度优先遍历。一般用深度优先遍历。
-
该题刻画出树
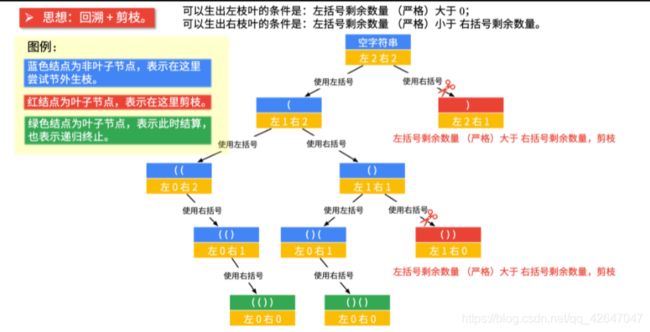
-
树出来了,由于树的DFS是树的前序遍历,所以用前序遍历即可。
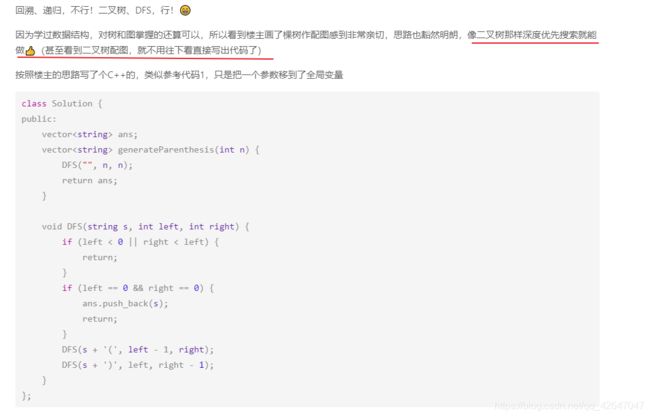
class Solution {
ArrayList<String> res;
public List<String> generateParenthesis(int n) {
res = new ArrayList<>();
if(n == 0) return res;
StringBuilder sb = new StringBuilder();
int left = n;
int right = n;
dfs(sb , left , right);
return res;
}
void dfs(StringBuilder sb , int left , int right){
if(left < 0 || left > right) return;//剪枝--回溯
if(left == 0 && right ==0){
res.add(sb.toString());
return;
}//正常到叶节点返回
dfs(sb.append('(') , left - 1 , right);
sb.deleteCharAt(sb.length() - 1);
dfs(sb.append(')') , left , right - 1);
sb.deleteCharAt(sb.length() - 1);
}
}
栈
20. 有效的括号
参考

递归
21. 合并两个有序链表
参考(有图节递归过程)
或 迭代
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
// if(l1 == null && l2 == null) return null;
// if(l1 ==null && l2 != null) return l2;
// if(l1 !=null && l2 == null) return l1;
ListNode pPre = new ListNode();
ListNode pre = pPre;
while(l1 != null && l2 != null){
if(l1.val <= l2.val){
pre.next = l1;
l1 = l1.next;
pre = pre.next;
}else{
pre.next = l2;
l2 = l2.next;
pre = pre.next;
}
}
pre.next = l1 == null ? l2 : l1;
return pPre.next;
}
}
- 本题迭代更好,因为空间复杂度是O(1)。
看规律、归纳
31. 下一个排列
参考