Apache Kafka: Next Generation Distributed Messaging System---reference
Introduction
Apache Kafka is a distributed publish-subscribe messaging system. It was originally developed at LinkedIn Corporation and later on became a part of Apache project. Kafka is a fast, scalable, distributed in nature by its design, partitioned and replicated commit log service.
Apache Kafka differs from traditional messaging system in:
- It is designed as a distributed system which is very easy to scale out.
- It offers high throughput for both publishing and subscribing.
- It supports multi-subscribers and automatically balances the consumers during failure.
- It persist messages on disk and thus can be used for batched consumption such as ETL, in addition to real time applications.
In this article, I will highlight the architecture points, features and characteristics of Apache Kafka that will help us to understand how Kafka is better than traditional message server.
I will compare the traditional message server RabbitMQ and Apache ActiveMQcharacteristics with Kafka and discuss certain scenarios where Kafka is a better solution than traditional message server. In the last section, we will explore a working sample application to showcase Kafka usage as message server. Complete source code of the sample application is available on GitHub. A detailed discussion around sample application is in the last section of this article.
Architecture
Firstly, I want to introduce the basic concepts of Kafka. Its architecture consists of the following components:
- A stream of messages of a particular type is defined as a topic. A Messageis defined as a payload of bytes and a Topic is a category or feed name to which messages are published.
- A Producer can be anyone who can publish messages to a Topic.
- The published messages are then stored at a set of servers called Brokers or Kafka Cluster.
- A Consumer can subscribe to one or more Topics and consume the published Messages by pulling data from the Brokers.
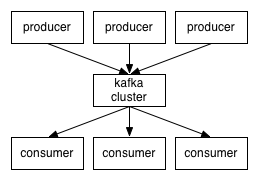
Figure 1: Kafka Producer, Consumer and Broker environment
Producer can choose their favorite serialization method to encode the message content. For efficiency, the producer can send a set of messages in a single publish request. Following code examples shows how to create a Producer to send messages.
Sample producer code:
producer = new Producer(…);
message = new Message(“test message str”.getBytes());
set = new MessageSet(message);
producer.send(“topic1”, set);
For subscribing topic, a consumer first creates one or more message streams for the topic. The messages published to that topic will be evenly distributed into these streams. Each message stream provides an iterator interface over the continual stream of messages being produced. The consumer then iterates over every message in the stream and processes the payload of the message. Unlike traditional iterators, the message stream iterator never terminates. If currently no message is there to consume, the iterator blocks until new messages are published to the topic. Kafka supports both the point-to-point delivery model in which multiple consumers jointly consume a single copy of message in a queue as well as the publish-subscribe model in which multiple consumers retrieve its own copy of the message. Following code examples shows a Consumer to consume messages.
Sample consumer code:
streams[] = Consumer.createMessageStreams(“topic1”, 1)
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
}
The overall architecture of Kafka is shown in Figure 2. Since Kafka is distributed in nature, a Kafka cluster typically consists of multiple brokers. To balance load, a topic is divided into multiple partitions and each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
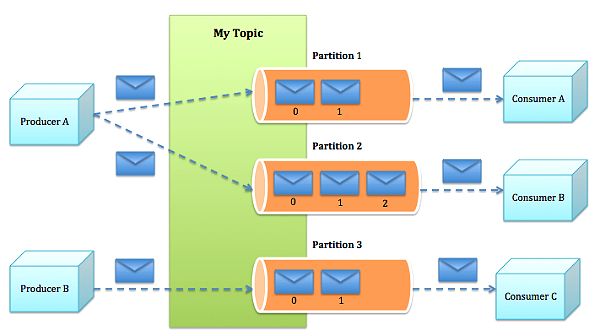
Figure 2: Kafka Architecture
Kafka Storage
Kafka has a very simple storage layout. Each partition of a topic corresponds to a logical log. Physically, a log is implemented as a set of segment files of equal sizes. Every time a producer publishes a message to a partition, the broker simply appends the message to the last segment file. Segment file is flushed to disk after configurable numbers of messages have been published or after a certain amount of time elapsed. Messages are exposed to consumer after it gets flushed.
Unlike traditional message system, a message stored in Kafka system doesn’t have explicit message ids.
Messages are exposed by the logical offset in the log. This avoids the overhead of maintaining auxiliary, seek-intensive random-access index structures that map the message ids to the actual message locations. Messages ids are incremental but not consecutive. To compute the id of next message adds a length of the current message to its logical offset.
Consumer always consumes messages from a particular partition sequentially and if the consumer acknowledges particular message offset, it implies that the consumer has consumed all prior messages. Consumer issues asynchronous pull request to the broker to have a buffer of bytes ready to consume. Each asynchronous pull request contains the offset of the message to consume. Kafka exploits the sendfile API to efficiently deliver bytes in a log segment file from a broker to a consumer.
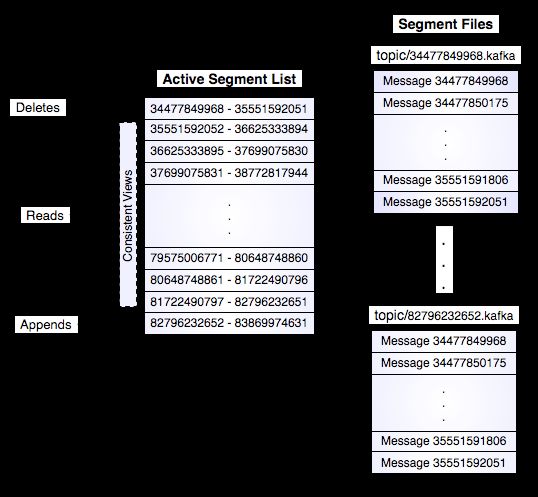
Figure 3: Kafka Storage Architecture
Kafka Broker
Unlike other message system, Kafka brokers are stateless. This means that the consumer has to maintain how much it has consumed. Consumer maintains it by itself and broker would not do anything. Such design is very tricky and innovative in itself.
- It is very tricky to delete message from the broker as broker doesn't know whether consumer consumed the message or not. Kafka innovatively solves this problem by using a simple time-based SLA for the retention policy. A message is automatically deleted if it has been retained in the broker longer than a certain period.
- This innovative design has a big benefit, as consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but proves to be an essential feature for many consumers.
Zookeeper and Kafka
Consider a distributed system with multiple servers, each of which is responsible for holding data and performing operations on that data. Some potential examples are distributed search engine, distributed build system or known system like Apache Hadoop. One common problem with all these distributed systems is how would you determine which servers are alive and operating at any given point of time? Most importantly, how would you do these things reliably in the face of the difficulties of distributed computing such as network failures, bandwidth limitations, variable latency connections, security concerns, and anything else that can go wrong in a networked environment, perhaps even across multiple data centers? These types of questions are the focus of Apache ZooKeeper, which is a fast, highly available, fault tolerant, distributed coordination service. Using ZooKeeper you can build reliable, distributed data structures for group membership, leader election, coordinated workflow, and configuration services, as well as generalized distributed data structures like locks, queues, barriers, and latches. Many well-known and successful projects already rely on ZooKeeper. Just a few of them include HBase, Hadoop 2.0, Solr Cloud, Neo4J, Apache Blur (incubating), and Accumulo.
ZooKeeper is a distributed, hierarchical file system that facilitates loose coupling between clients and provides an eventually consistent view of its znodes, which are like files and directories in a traditional file system. It provides basic operations such as creating, deleting, and checking existence of znodes. It provides an event-driven model in which clients can watch for changes to specific znodes, for example if a new child is added to an existing znode. ZooKeeper achieves high availability by running multiple ZooKeeper servers, called an ensemble, with each server holding an in-memory copy of the distributed file system to service client read requests.
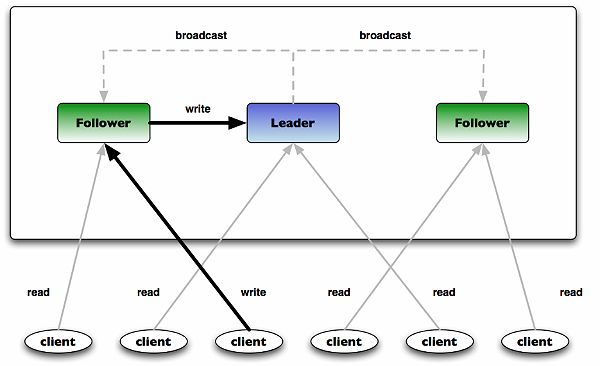
Figure 4: ZooKeeper Ensemble Architecture
Figure 4 above shows typical ZooKeeper ensemble in which one server acting as a leader while the rest are followers. On start of ensemble leader is elected first and all followers replicate their state with leader. All write requests are routed through leader and changes are broadcast to all followers. Change broadcast is termed as atomic broadcast.
Usage of Zookepper in Kafka: As for coordination and facilitation of distributed system ZooKeeper is used, for the same reason Kafka is using it. ZooKeeper is used for managing, coordinating Kafka broker. Each Kafka broker is coordinating with other Kafka brokers using ZooKeeper. Producer and consumer are notified by ZooKeeper service about the presence of new broker in Kafka system or failure of the broker in Kafka system. As per the notification received by the Zookeeper regarding presence or failure of the broker producer and consumer takes decision and start coordinating its work with some other broker. Overall Kafka system architecture is shown below in Figure 5 below.
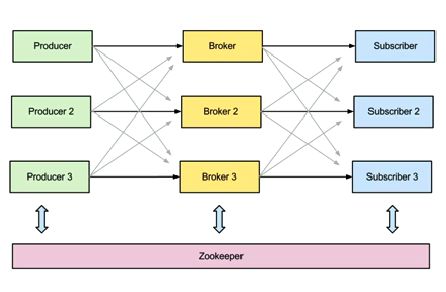
Figure 5: Overall Kafka architecture as distributed system
Apache Kafka v. other message servers
We’ll look at two different projects using Apache Kafka to differentiate from other message servers. These projects are LinkedIn and mine project is as follows:
LinkedIn Study
LinkedIn team conducted an experimental study, comparing the performance of Kafka with Apache ActiveMQ version 5,4 and RabbitMQ version 2.4. They used ActiveMQ’s default persistent message store kahadb. LinkedIn ran their experiments on two Linux machines, each with 8 2GHz cores, 16GB of memory, 6 disks with RAID 10. Two machines are connected with a 1GB network link. One of the machines was used as the Broker and the other machine was used as the Producer or the Consumer.
Producer Test
LinkedIn configured the broker in all systems to asynchronously flush messages to its persistence store. For each system, they ran a single Producer to publish a total of 10 million messages, each of 200 bytes. Kafka producer send messages in batches of size 1 and 50. ActiveMQ and RabbitMQ don’t seem to have an easy way to batch messages and LinkedIn assumes that it used a batch size of 1. Result graph is shown in Figure 6 below:
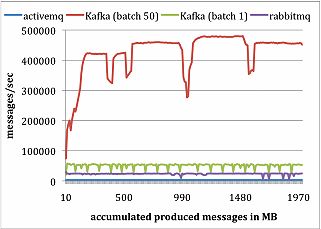
Figure 6: Producer performance result of LinkedIn experiment
Few reasons why Kafka output is much better are as follows:
- Kafka producer doesn’t wait for acknowledgements from the broker and sends messages as faster as the broker can handle.
- Kafka has a more efficient storage format. On average, each message had an overhead of 9 bytes in Kafka, versus 144 bytes in ActiveMQ. This is because of overhead of heavy message header, required by JMS and overhead of maintaining various indexing structures. LinkedIn observed that one of the busiest threads in ActiveMQ spent most of its time accessing a B-Tree to maintain message metadata and state.
Consumer Test
For consumer test LinkedIn used a single consumer to retrieve a total of 10 million messages. LinkedIn configured all systems so that each pull request should prefetch approximately the same amount data---up to 1,000 messages or about 200KB. For both ActiveMQ and RabbitMQ, LinkedIn set the consumer acknowledgement mode to be automatic. The results are presented in Figure 7.
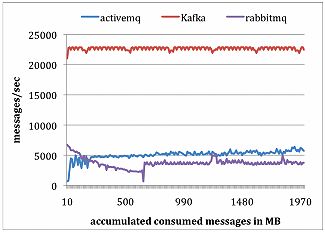
Figure 7: Consumer performance result of LinkedIn experiment
Few reasons why Kafka output is much better are as follows:
- Kafka has a more efficient storage format; fewer bytes were transferred from the broker to the consumer in Kafka.
- The broker in both ActiveMQ and RabbitMQ containers had to maintain the delivery state of every message. LinkedIn team observed that one of the ActiveMQ threads was busy writing KahaDB pages to disks during this test. In contrast, there were no disk write activities on the Kafka broker. Finally, by using the sendfile API, Kafka reduces the transmission overhead
Currently I am working in a project which provides real-time service that quickly and accurately extracts OTC(over the counter) pricing content from messages. Project is very critical in nature as it deals with financial information of nearly 25 asset classes including Bonds, Loans and ABS(Asset Backed Securities). Project raw information sources cover major financial market areas of Europe, North America, Canada and Latin America. Below are some stats about the project which show how important it is to have an efficient distributed message server as part of the solution:
- 1,300,000+ messages daily
- 12,000,000+OTC prices parsed daily
- 25+ supported asset classes
- 70,000+ unique instruments parsed daily.
Messages contain PDF, Word documents, Excel files and certain other formats. OTC prices are also extracted from the attachments.
Because of the performance limitations of traditional message servers, as message queue becomes large while processing large attachment files, our project was facing serious problems and JMSqueue needed to be started two to three times in a day. Restarting a JMS Queue potentially loses the entire messages in the queue. Project needed a framework which can hold messages irrespective of the parser (consumer) behavior. Kafka features are well suited for the requirements in our project.
Features of the project in current setup:
- Fetchmail utility is used for remote-mail retrieval of messages which are further processed by the usage of Procmail utility filters like separate distribution of attachment based messages.
- Each message is retrieved in a separate file which is processed (read & delete) for insertion as a message in message server.
- Message content is retrieved from message server queue for parsing and information extraction.
Sample Application
Sample application is modified version of the original application which I am using in my project. I have tried to make artifacts of sample application simple by removing the usage of logging and multi-threading features. Intent of sample application is to show how to use Kafka producer and consumer API. Application contains a sample producer (simple producer code to demonstrate Kafka producer API usage and publish messages on a particular topic), sample consumer(simple consumer code to demonstrate Kafka consumer API usage) and message content generation (API to generate message content in a file at a particular file path)API. Below Figure shows the components and their relation with other components in the system.
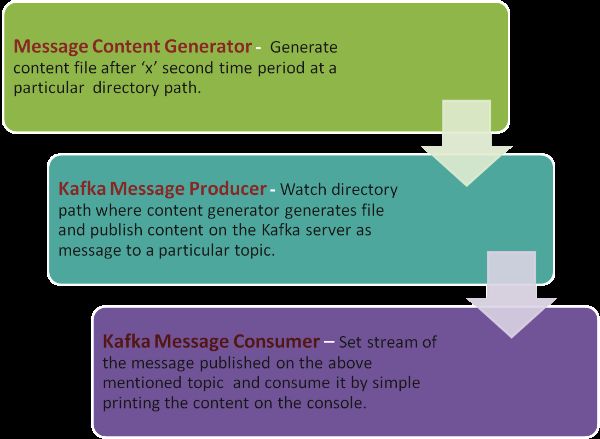
Figure 8: Sample application architecture components
Sample application has a similar structure of the example application presented in Kafka source code. Source code of the application contains the ‘src’ java source folder and ‘config’ folder containing several configuration files and shell scripts for the execution of the sample application. For executing sample application, please follow the instructions mentioned in ReadMe.md file orWiki page on Github website.
Application code is Apache Maven enabled and is very easy to setup for customization. Several Kafka build scripts are also modified for re-building the sample application code if anyone wants to modify or customize the sample application code. Detailed description about how to customize the sample application is documented in project’s Wiki page on GitHub.
Now let’s have a look on the core artifacts of the sample application.
/**
* Instantiates a new Kafka producer.
*
* @param topic the topic
* @param directoryPath the directory path
*/
public KafkaMailProducer(String topic, String directoryPath) {
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "localhost:9092");
producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));
this.topic = topic;
this.directoryPath = directoryPath;
}
public void run() {
Path dir = Paths.get(directoryPath);
try {
new WatchDir(dir).start();
new ReadDir(dir).start();
} catch (IOException e) {
e.printStackTrace();
}
}
Above code snippet has basic Kafka producer API usage like setting up property of the producer i.e. on which topic messages are going to publish, which serializer class we can use and information regarding broker. Basic functionality of the class is to read the email message file from email directory and publish it as a message on Kafka broker. Directory is watched using java.nio.WatchService class and as soon as email message is dumped in to the directory it will be read up and published on Kafka broker as a message.
public KafkaMailConsumer(String topic) {
consumer =
Kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig());
this.topic = topic;
}
/**
* Creates the consumer config.
*
* @return the consumer config
*/
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("zookeeper.connect", KafkaMailProperties.zkConnect);
props.put("group.id", KafkaMailProperties.groupId);
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext())
System.out.println(new String(it.next().message()));
}
Above code shows basic consumer API. As mentioned above consumer needs to set stream of messages for consumption. In run method this is what we are doing and then printing a consumed message on the console. In my project we are using to feed into the parser system to extract OTC prices.
We using Kafka as the message server currently in our QA system as Proof of Concept (POC) project and the overall performance looks better than JMS message server. One positive feature we are excited about is the re-consumption of messages which enables our parsing system to re-parse certain messages as per the business needs. Based on the positive response of Kafka we are now planning to use it as a log aggregator and analyze logs instead of using Nagios system.
Conclusion
Kafka is a novel system for processing of large chunks of data. Pull-based consumption model of Kafka allows a consumer to consume messages at its own speed. If some exception occurs while consuming the messages, the consumer has always a choice to re-consume the message.
reference from:http://www.infoq.com/articles/apache-kafka