0.目录
- 1.优先队列ADT
- 2.几种实现
- 3.二叉堆
- 4.d-堆
- 5.左式堆
- 6.斜堆
- 7.二项队列
- 8.斐波那契堆
- 9.van Emde Boas树
- 10.配对堆(Pairing heap)
1.优先队列ADT
优先队列是允许至少下列两种操作的数据结构:
1)Insert
2)DeleteMin 找出、返回和删除优先队列中最小的元素

2.几种实现
1)使用链表
可以使用一个简单链表,在表头以O(1)执行插入操作,并遍历该链表以删除最小元,需要O(N时间)。
始终让表保持有序状态,这使得插入代价O(N),而DeleteMin为O(1)
2)使用查找树
两种操作的平均时间都是O(lgN)
但是查找树支持许多并不需要的操作。
3)使用二叉堆
不需要使用指针,以最坏情形O(lgN)支持上述两种操作。
3.二叉堆
3.1 结构性质
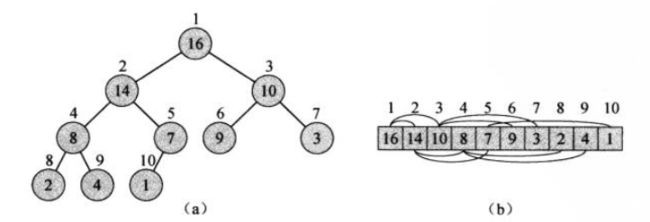
二叉堆是一个数组,可以被看成一个近似的完全二叉树。树上的每一个结点对应数组中的一个元素。除了最底层外,该树是完全充满的。而且是从左向右填充。
数组A的两个属性:
A.length给出数组元素的个数
A.heap-size表示有多少堆元素存储在该数组中
因此,A[1..A.length]可能都存有数据,但只有A[1..A.heap-size]中存放的是堆的有效元素。 0<=A.heap-size<=A.length

3.2 堆序性质
对于最大堆而言:最大元应该在根上,并且任意子树也应该是一个最大堆。
也即,除了根以外的所有节点i都要满足:
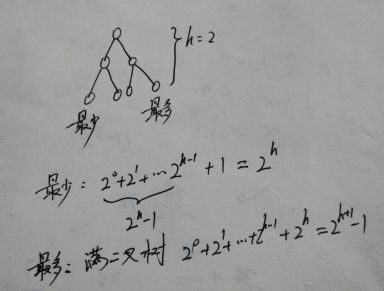
1)在高度为h的堆中,元素个数最多和最少分别是多少?
2)证明:含n个元素的堆的高度为floor(lgn)。(向下取整)
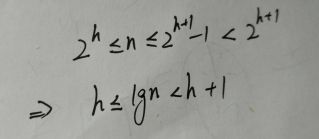
3)一个已排好序的数组是一个最小堆,但是一个最小堆不一定是拍好序的

4)证明:当用数组表示存储n个元素的堆时,叶节点下标分别是floor(n/2) +1, floor(n/2) + 2, ..., n.

3.3 基本的堆操作
3.3.1 建堆
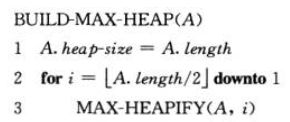
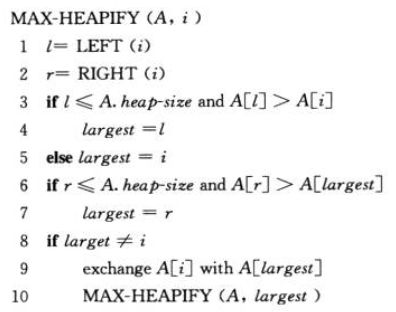

1)MAX-HEAPIFY(A, i)
在调用MAX-HEAPIFY的时候,假定根节点为LEFT(i)和RIGHT(i)都为最大堆,MAX-HEAPIFY让A[i]的值在最大堆中逐级下降,从而使得以下标为i的子树重新遵循最大堆的性质。
2)时间代价分析
a.调整最上面三个的关系Θ(1)
b.递归处理孩子结点,至多为2n/3(最坏情况:子树结点占了整个树的大部分,发生在树的最底层恰好半满的时候)
T(n) <= T(2n/3) + Θ(1)
=>得到T(n) = Θ(lgn)


3)证明BUILD-MAX-HEAP的正确性
循环不变量:第2-3行中每一次for循环的开始,结点i+1, i+2, ..., n都是一个最大堆的根结点。

4)BUILD-MAX-HEAP的时间代价

3.3.2 INSERT(S, x)
每个元素都有一个健值key
把元素x插入到优先队列S中

3.3.3 MAXIMUM(S)
返回S中具有最大健值的元素

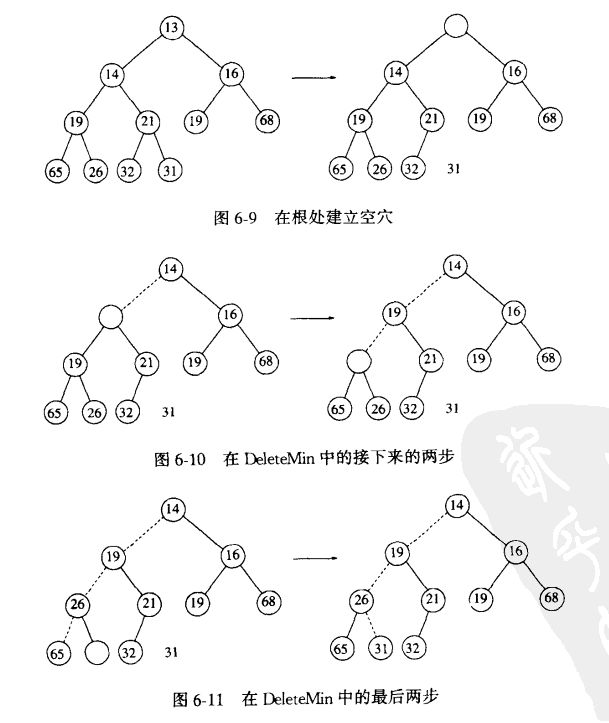
3.3.4 EXTRACT-MAX(S)
去掉并返回S中的具有最大健值的元素

一种更有效的方式(从根节点的两个儿子选取,而不是将最后一个放上去):

3.3.5 INCREASE-KEY(S, x, k)
将元素x的健值增加到k,这里假设k的值不小于x原来的健值
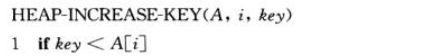

4.d-堆
d-堆时二叉堆的简单推广。

5.左式堆
5.1 左式堆性质
目的是高效的支持合并操作。
因为需要支持合并操作,因此需要指针。
左式堆也是二叉树,具有相同的堆序性质,唯一的区别是:趋于非常不平衡。
零路径长NPL(null path length):定义为从X到一个没有两个儿子的结点的最短路径的长。npl(NULL) = -1. 任一结点的零路径长比它的诸儿子结点的零路径长的最小值多1.
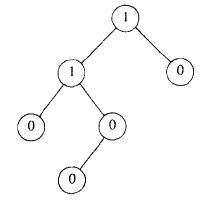
左式堆性质:对于堆中的每一个结点,左儿子的零路径长至少与右儿子的零路径长一样大。
该性质使得偏重于使树向左增加深度。便于合并操作。


5.2 左式堆的操作
左式堆的基本操作是合并。插入只是合并的特殊形式。
1)左式堆的声明

2)左式堆的合并
2-1)递归的做法


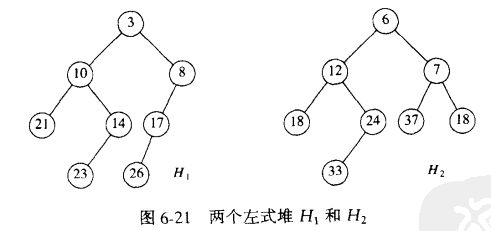
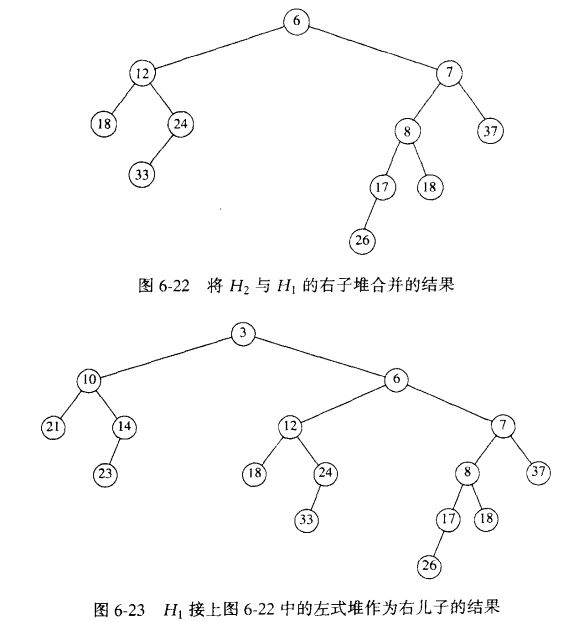

合并两个左式堆的时间界为O(lgN),与右路径的长的和(r1 + r2)成正比。
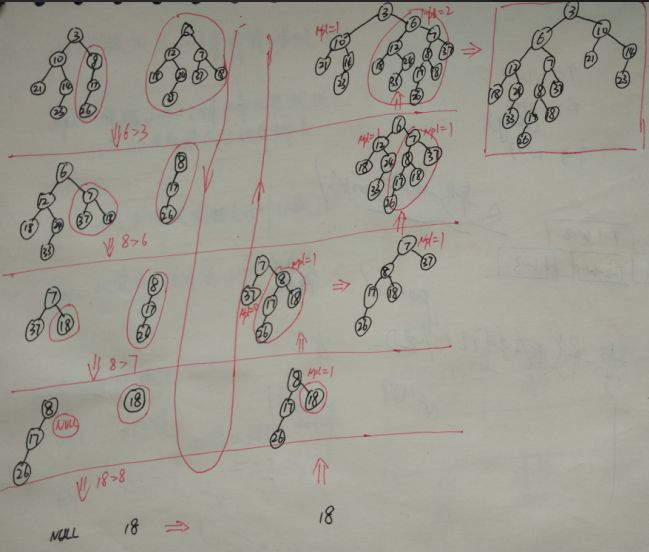
2-2)非递归的做法
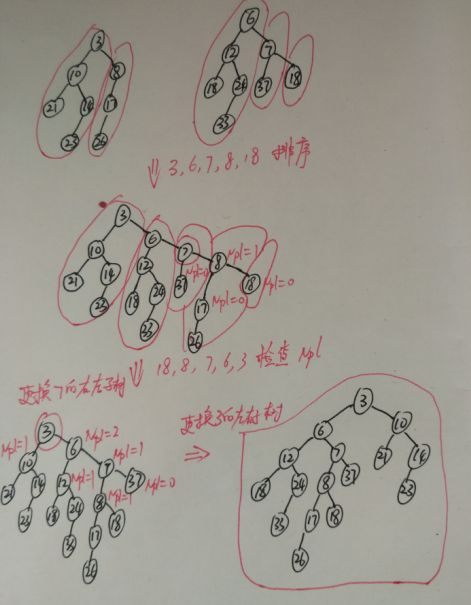
step1.通过合并两个堆的右路径建立一棵新的树。以排序的顺序的安排H1和H2右路径上的结点,并保持各自的左儿子不变。新的路径为3,6,7,8,18.
step2.恢复左式堆的性质。交换左式堆性质被破坏的结点的左右儿子。结点7,3各有一次交换工作。
2-3)递归和非递归的做法本质上是一模一样的
递归的做法,可以看出也是在右路径上将两个左式堆的右结点一一拼接起来,并且拼接的顺序是从底向上,也就是18->8->7->6->3;
递归的做法与非递归做法唯一的不同是:递归的做法在拼接好两个结点后,就判断是否符合左式堆性质,如果不符合,就交换左右子节点;而非递归做法要等到第二趟的时候才进行统一的交换。
3)左式堆的插入

4)左式堆的DeleteMin

5)左式堆DecreaseKey
二叉堆中,DecreaseKey通过降低结点的值然后将其朝着根上滤直到建成堆序来实现的。最坏情况为Θ(N)。
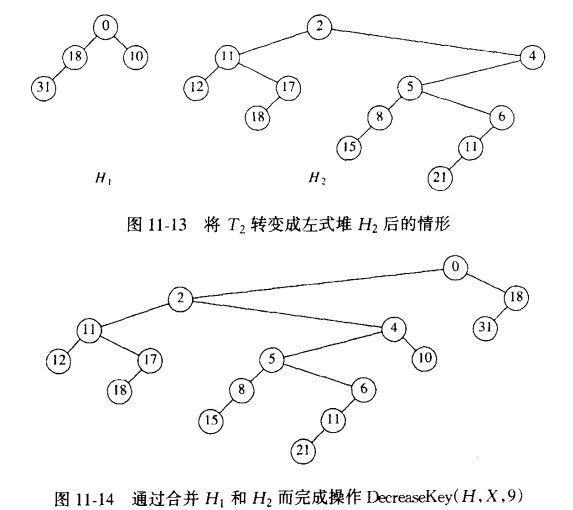
如下,将关键字9减到0:

解决办法是:把堆沿着虚线切开,如此得到两棵树,然后将两棵树合并一棵。

如果得到的两棵树都是左式堆,那么他们可以以时间O(logN)合并。
H1显然是左式堆,T2未必是左式堆。
不过容易恢复左式堆的性质:

6.斜堆
6.1 斜堆与左式堆
斜堆~左式堆 等价于 伸展树~AVL树
斜堆是具有堆序的二叉树,但是不存在对树的结构限制,斜堆的零路径长Npl不保留,因此右路径肯能很长,所有操作的最坏情形为O(N)。 而左式堆右路径长最多不超过O(lgN),所以最坏时间不超过O(lgN)。
正如同伸展树一样,可以证明任意M次连续操作,总的最坏情形运行时间是O(MlgN),因此斜堆每次操作的摊还时间为O(lgN)。
6.2 斜堆的操作
1)递归操作
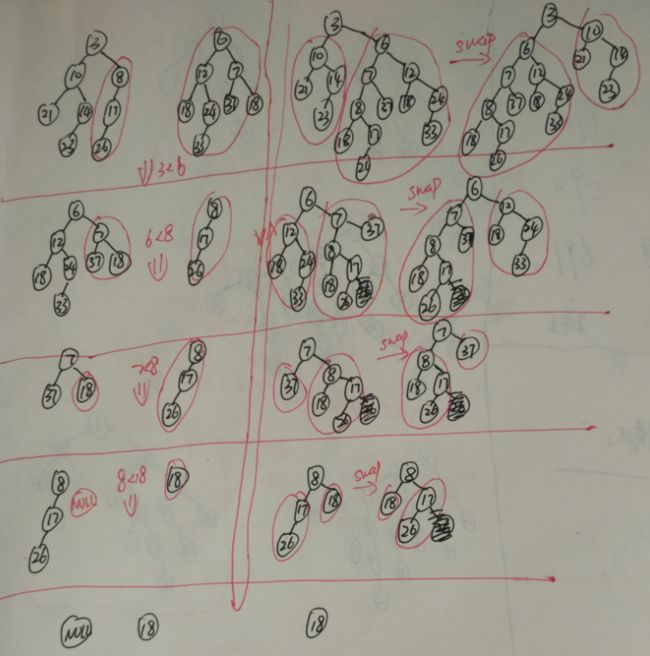
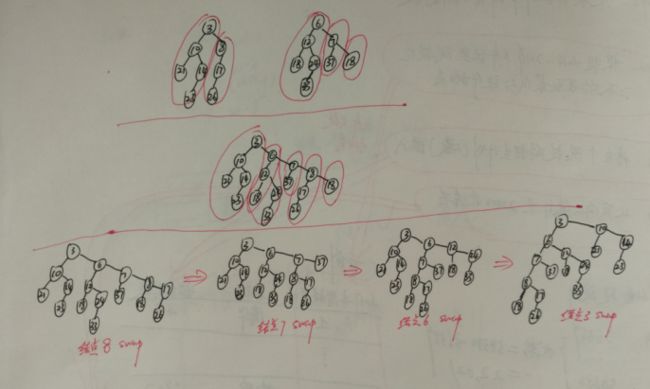
合并操作:除了右路径所有节点的最大者(最后一个节点,这个节点没有右儿子,比如例子中的18),交换左右儿子是无条件的。(而左式堆只交换不满足左式堆堆序性质的结点)
2)非递归操作
step1.按排序顺序合并右路径
step2.除最后结点外,交换右路径上每个结点的左右儿子
7.二项队列
7.1 二项队列的进一步改进
左式堆和斜堆每次操作都花费了O(lgN)时间,这有效地支持了合并、插入、DeleteMin操作。
但是还有改进的余地,二叉堆每次插入的平均时间为常数。
二项队列支持这三种操作,操作的最坏情形运行时间为O(lgN),而插入操作平均时间为常数。
7.2 二项队列的结构
二项队列不是一棵堆序的树,而是堆序树的集合,称为森林。
每一棵堆序树称为二项树,每一个高度至多存在一棵二项树。


如下图:具有六个元素的二相队列

这里的本质是:将元素个数N转换成二进制形式,二进制为1的位,表示该有以该位权重为高度的二项树。
7.3 二项队列的操作
1)最小元
最小元通过搜索所有树的根来找出。由于最多有lgN棵不同的树,因此最小元可以在O(lgN)时间内找到。也可以在所有其他操作中记住最小元并更新,则只用O(1)就能找到。
2)合并操作
合并两棵二项树花费常数时间,总共存在O(lgN)棵二项树,因此合并在最坏情形下花费时间O(lgN)。
合并本质上类似于二进制的加法。

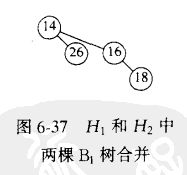

3)插入
插入式合并的特殊形式,创建一棵单节点树并执行一次合并。这种操作的最坏情形也是O(lgN)。
更准确的说,如果元素将要插入的优先队列不存在的最小的二项树是Bi,那么运行时间与Θ(i+1)。 因为类似于一个二进制数 + 1,最多进位到Bi+1.
证明:对一个初始为空的二项队列进行N次Insert将花费的最坏情形时间为O(N)。

4)DeleteMin

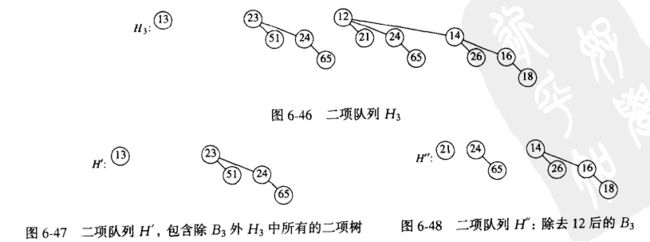

7.4 二项队列的实现
7.4.1 二项队列的实现结构
1)DeleteMin需要快速找出根的所有子树
=> 需要使用树的标准表示法,每个结点的儿子都存在一个链表中,每个结点都有一个指针指向它的第一个儿子。
2)方便地合并两棵树
=>诸儿子按照它们的子树大小排序(原因:两棵树合并时,其中一棵树作为儿子被加到另一棵树上,由于这棵新树将是最大的子树,因此,以大小递减的方式保持这些子树是有意义的)
总之:
1)二项树是二项树的数组
2)二项树的每一个结点将包含数据、第一个儿子以及右兄弟

1)二项队列类型声明

2)合并同样大小的两棵二项树


7.4.2 二项队列的操作实现
1)合并

合并程序说明:
a. !!T,若二项树T存在,则!!T为1,否则为0
b. (!!T1 + !!T2 + !!Carry)这种处理方式太妙了,将所有的八种情况全部全都概括了,程序一下子变得很简洁
c. 通过j来控制循环次数,j = 2的i次方,当j大于CurrentSize的时候,则H1和H2都没有二项树了。
2)DeleteMin

DeleteMin完全按照前面的思路实现的:
step1.找出最小元素所在的树,去掉最小元素,将所有子树重新加入到一个二项队列
step2.将原二相队列去掉最小元素所在的树剩下队列,与新生成的二相队列合并
8.斐波那契堆(本质是二项队列,参见EXTRACT-MIN中对相同degree树的合并)
8.1 斐波那契堆概念
1)可合并堆
可合并堆是支持以下5种操作的一种数据结构,其中每个元素都有一个关键字:
MAKE-HEAP():创建和返回一个新的不含任何元素的堆
INSERT(H, x):将一个已填入关键的元素x插入堆H中
MINIMUM(H):返回一个指向堆H中具有最小关键字元素的指针
EXTRACT-MIN(H):从堆H中删除最小关键字的元素,并返回一个指向该元素的指针。
UNION(H1, H2):创建并返回一个包含堆H1和堆H2中所有元素的新堆。
2)斐波那契堆还支持两种操作
DECREASE-KEY(H, x, k):将堆H中元素x的关键字赋予新值k。假定新值k不大于当前的关键字
DELETE(H, x):从堆H中删除x
3)斐波那契堆是二项队列的推广
通过添加两个新的观念:
a. DECREASE-KEY的一种不同的实现方法:之前的方法是把元素朝向根节点上滤。这种方法不能实现O(1)的摊还时间界,因此需要一种新的方法。(斐波那契堆是直接剪切掉,放到根链表中)
b. 懒惰合并:只有当两个堆需要合并时才进行合并。类似于懒惰删除。对于懒惰合并,UNION是低廉的。但是因为懒惰合并并不实际把树结合在一起,所以EXTRACT-MIN操作可能会遇到很多树,从而使得这种操作的代价高昂。 特别地,一次昂贵EXTRACT-MIN必须在其前面要有大量非常低廉的UNION操作
4)理论上的斐波那契堆与实际中的斐波那契堆
a.理论上
当EXTRACT-MIN和DELETE数目相比其他操作小得多的时候,斐波那契堆尤其适用。例如:最小生成树、单元最短路径。
b.实际中
除了某些需要管理大量数据的应用外,对于大多数应用,斐波那契堆的常数因子和编程复杂性使得它比起普通二叉堆(d-堆)并不那么适用。
二叉堆和斐波那契堆对于SEARCH操作支持比较低效。因此,涉及给定元素的操作(DECREASE-KEY和DELETE)均需要一个指针指向这个元素。
8.2 斐波那契堆结构
一个斐波那契堆时一系列具有最小堆序的有根树的集合。
每棵树遵循最小堆性质:每个结点的关键大于或等于它的父节点关键字。
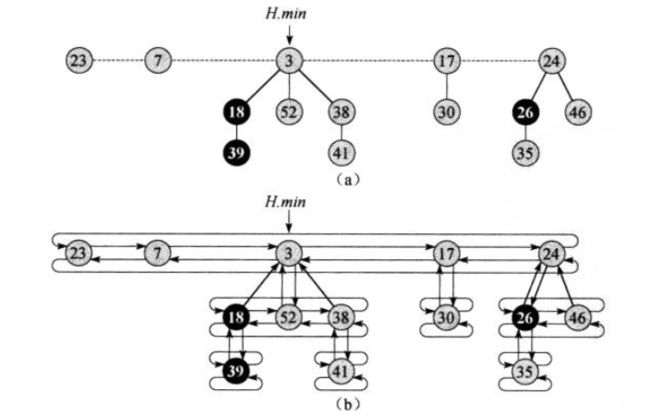
使用环形双向链表:
1)可以在O(1)内从一个环形双向链表的任何位置插入一个结点或删除一个结点
2)给定两个这种链表,可以用O(1)时间把它们链接成一个环形双向链表
每个结点的属性:
x.p 父指针
x.child 某一个孩子指针
x.left
x.right 左右兄弟
x.degree 结点x的孩子链表中的孩子数目
x.mark 指示结点x自从上一次成为另一个结点的孩子后,是否失去过孩子(这个属性有什么作用?)
H.min 通过该指针访问一个给定的斐波那契堆H,该指针指向具有最小关键字的树的根节点。(最小节点)
H.n 表示H中当前的结点数目
根链表:所有树的根形成一个环形的双链表
step1.斐波那契堆势函数的定义
对于一个给定的斐波那契堆H,用t(H)来表示H中跟链表中数的数目,用m(H)表示H中已标记的结点数目。定义H的势函数:Φ(H) = t(H) + 2m(H)
例如上图中斐波那契堆的势为5+2x3=11.(有5棵根数,3个被标记的结点)
势初始值为0,势在随后的任何时间内都不为负,对于某一操作序列来说,总的摊还代价的上界就是其总的实际代价的上界。
8.3 斐波那契堆的操作
1)MAKE-FIB-HEAP
创建一个空的斐波那契堆,其中H.n = 0和H.min = NIL
step2.斐波那契堆各操作的摊还代价——建堆
空堆斐波那契堆的势为Φ(H) = 0,因此建堆的摊还代价等于它的实际代价O(1)。
2)FIB-HEAP-INSERT(H, x)
假定结点x已经被分配,x.key已经被赋值

如下例子插入了一个具有关键字21的结点:
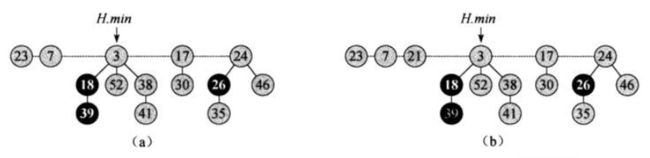
step2.斐波那契堆各操作的摊还代价——插入
假设H是输入的斐波那契堆,H'是结果斐波那契堆。那么
t(H') = t(H) +1
m(H') = m(H)
势的增量为:((t(H) + 1) + 2m(H)) - (t(H) + 2m(H)) = 1
实际代价为O(1)
因此摊还代价为O(1) + 1 = O(1)
3)FIB-HEAP-MINIMUM(H)
通过H.min得到
step2.斐波那契堆各操作的摊还代价——最小值
势无变化,因此摊还代价等于实际代价O(1)
4)FIB-HEAP-UNION(H1, H2)
仅仅将H1和H2的根链表链接,然后确定新的最小结点。

step2.斐波那契堆各操作的摊还代价——合并
由于两个链表合并,势无变化(根节点数为两个之和,标记结点为两个之和,都无变化),因此摊还代价为实际代价O(1)
5)FIB-HEAP-EXTRACT-MIN(H)
假定当一个结点从链表中移除后,留在链表中的指针要被更新,但是抽取出的结点中的指针并不改变。


FIB-HEAP-EXTRACT-MIN代码说明:
step1.将最小结点的每个孩子变为根节点,并从根链表中删除该最小结点
step2.通过把具有相同度数的根节点合并的方法来链接成根链表,直到每个度数至多只有一个根在根链表中。重复以下步骤:
2-1.在根链表中找到两个具有相同度数的根x和y,不失一般性,假定x.key <= y.key
2-2.把y链接到x:从根链表中移除y,调用FIB-HEAP-LINK过程,使y成为x的孩子。该过程将x.degree属性增1,并清除y上的标记。
几种情况:
a. 空堆
b. 只有一个结点(H.min,且没有孩子结点)
c. 其余情况
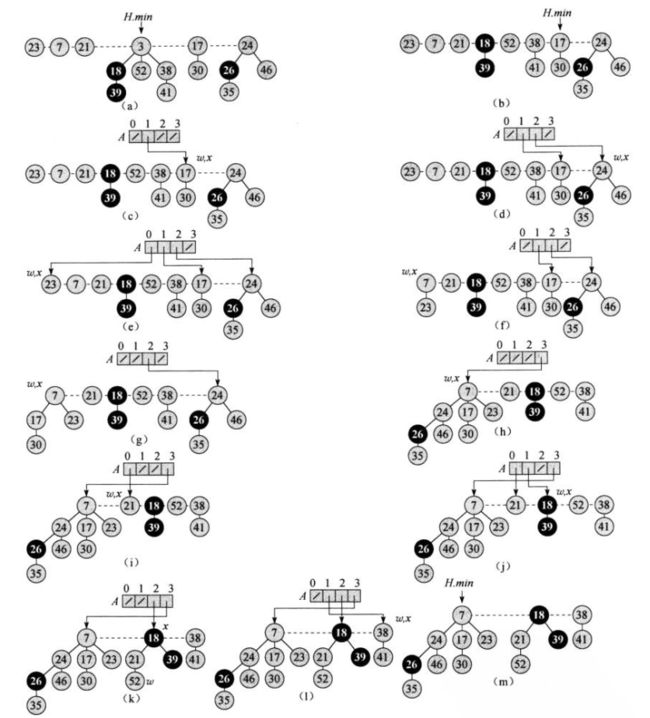
图示说明:
a-b说明的是step1
c-m说明的是step2
其中l-m步骤是将其还原成根链表的形式
从这个操作可以看出,斐波那契堆本质上跟二项队列是一致,其中x.degree表示的2的多少次方。
step2.斐波那契堆各操作的摊还代价——删除并返回关键字

6)FIB-HEAP-DECREASE-KEY(H, x, k)
同样假定,从一个链表中移除一个结点不改变被移除结点的任何结构属性。

代码说明:
a. 没有违反堆序性质,即x是根节点或者x.key >= y.key
b. 违反了最小堆序,需要很多改变
b-1. 如果违反了最小堆序,需要进行切断,切断过程与父节点的关系,并让该结点成为根节点
b-2.mark的作用:记录了每个结点一小段历史
假定下面的步骤已经发生在结点x上:
- 在某个时刻,x是根
- 然后x被链接到另一个结点(成为孩子结点)
- 然后x的两个孩子被切断操作移除
一旦失掉第二个孩子,就切断x与父节点的链接,使它成为一个新的根。如果发生了第1步和第2步且x的一个孩子被切掉,那么x.mark为TRUE。
CUT执行了第一步,因此清除x.mark。
前面FIB-HEAP-LINK中也清除了y.mark,因为y被链接到另一个结点上(第二步)。
其中CASCADING-CUT(H, y)为什么当z不为空时,y.mark标记一定有,因为所有有父节点的结点,都是通过FIB-HEAP-EXTRACT-MIN中的CONSOLIDATE得到的(合并只是将结点加入到根链表,而这个动作会进行合并),而CONSOLIDATE中的FIB-HEAP-LINK将一个结点加入到另一个结点下面时,会将子节点mark置为false。
此时,x的父节点y,可能是y的父节点z被切掉的第二个孩子,因此要尝试进行一次级联切断。一直递归向上,直到遇到根节点或者一个未被标记(false)的结点。
问题:为什么要这样设计mark?有什么作用?
这里斐波那契堆设计的关键点:一个结点最多失去一个孩子,如果失去两个孩子,就要被从父节点中剪切掉。
根据引理19.1到19.4,才能保证具有斐波那契数列性质。
关键字为46的结点将关键字减小到15:

关键位35的结点将关键字减小到5:

step2.斐波那契堆各操作的摊还代价——减小关键字

标记结点前面有2的原因:
一个标记结点y被一个级联切断操作切断的时候,它的标记位情况,使得势减小了2。一个单位的势支付切断和标记位的清除,另一个单位补偿了因为结点y变成根而增加的势。
这个地方标记为2:一方面支付上面说的实际代价O(c),也即级联切断变成根的代价O(c);一方面支付因为变成根而增加的势(t(H)+c)中的c。
7)FIB-HEAP-DELETE(H, x)
假定在斐波那契堆中任何关键字的当前值均不为负无穷。

step2.斐波那契堆各操作的摊还代价——删除结点
是两者之和,即O(D(n))
8.4 斐波那契堆的分析
size(x):以x为根的子树中包括x本身在内的结点个数。将证明size(x)是x.degree的幂。






9.van Emde Boas树
9.1 van Emde Boas树相对其他优先队列数据结构的优势
9.1.1 基于关键字比较的优先队列数据结构
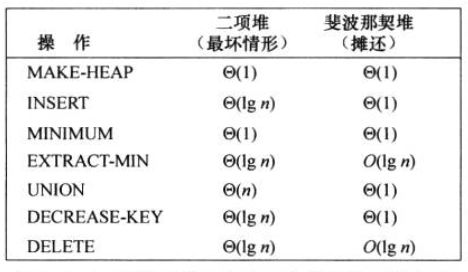
二叉堆、红黑树、斐波那契堆,不论是最坏或摊还情况,至少有一项重要操作需O(lgn)时间。
原因是这些数据结构都是基于关键字比较来做决定的。基于比较的排序算法的下界是Ω(nlgn)说明至少有一个操作必须Ω(lgn)。因为如果INSERT和EXTRACT-MIN操作均需要O(lgn),那么可以通过先执行n次INSERT操作,接着再执行n次EXTRACT-MIN操作来实现O(nlgn)时间内对n个关键字的排序。
9.1.2 特定条件下的van Emde Boas可以突破比较类型堆的时间限制
当关键字是有界范围内的整数是,可以突破排序下界限制。
同理,van Emde Boas树支持优先队列操作以及一些其他操作(SEARCH、INSERT、DELETE、MINIMUM、MAXIMUM、SUCESSOR、PREDECESSOR),每个操作最坏情况运行时间为O(lglgn)。这种数据结构限制关键字为0~n-1的整数且无重复。
n表示集合中当前元素的个数
u表示元素的可能取值范围,假定u恰为2的幂
9.2 一些简单方法
1)直接寻址
维护一个u位的数组A[0..u-1],以存储一个值来自全域{0, 1, 2, ..., u-1}的动态集合。若值x属于动态集合,则A[x]位1;否则为0.
可使INSERT、DELETE、MEMBER操作的运行时间为O(1),其余操作(MINIMUM、MAXIMUM、SUCCESSOR、PREDECESSOR)在最坏情况下仍需Θ(u)。
2)叠加二叉树结构
在位向量上叠加一棵二叉树,来缩短位向量的扫描。
内部节点存储的位是其两个孩子的逻辑或。
最坏运行时间为Θ(lgu)的操作:
MINIMUM(从树根开始,总是走最左边包含1的结点)
MAXMUM(总是走最右边包含1的结点)
SUCCESSOR(向上走,直到从左侧进入一个结点,该节点的右孩子为1)
PREDECESSOR(向上走,直到从右侧进入一个结点,该节点的左孩子为1)

最坏运行时间为O(lgu)的操作:
INSERT:从该节点到根的简单路径上的每个节点都置位1
DELETE:从该叶节点出发到根,重新计算这个简单路径上每个内部节点的值
3)叠加的一棵高度恒定的树

9.3 改进——van Emde Boas结构的原型(未达到O(lglgu))
1)分析
使用递归,每次递归都以平方根缩减。
考虑如下递归式:

x的簇编号和在簇中的位置(偏移):
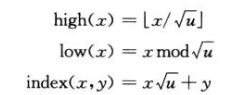
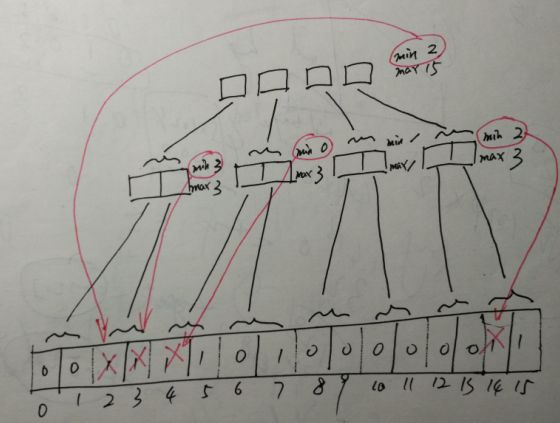
2)结构

如下实例,表示集合{2,3,4,5,7,14,15}:


3)操作
这些操作都假定 0 <= x < V.u
a. PROTO-vEB-MEMBER(V, x)

T(u) = O(lglgu)
b. PROTO-vEB-MINIMUM(V)


a = 2, b =2, f(m) = 1 = O(m)
因此T(m) = Θ(m) = Θ(lgu)
c.PROTO-vEB-SUCCESSOR(V, x)


d.PROTO-vEB-INSERT(V, x)——Θ(lgu)

e.PROTO-vEB-DELETE(V, x)
9.4 改进——van Emde Boas树
1)结构
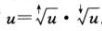
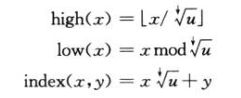
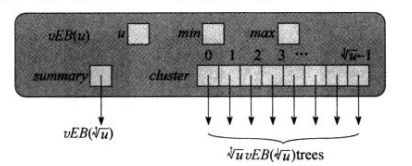
如下实例,表示集合{2,3,4,5,7,14,15}:

递归式如下:


2)操作
a. 最值

b.判断是否在集合中

c.前驱后继



d.插入一个元素


3.删除一个元素


10.配对堆(pairing heap)
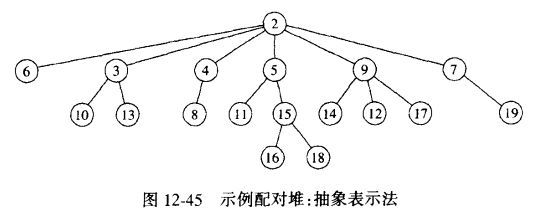
10.1 配对堆的定义
配对堆的基本操作是两个多路堆序树的合并,因此叫配对堆。
配对堆被标示成堆序树:
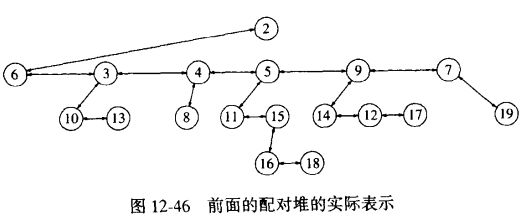
结点的构造:
- LeftChild —— 左儿子
- NextSibling —— 右兄弟
- Prev —— 作为最左儿子,该指针指向其父亲;否则该指针指向其做兄弟
10.2 配对堆的操作
10.2.1 两个多路堆序树合并
让具有较大根的子堆成为另一个子堆的最左儿子。


10.2.2 插入
插入式合并的特殊形式。

10.2.3 DecreaseKey
将调整后的结点从它的父节点切除,通过合并所得到的两个堆完成。

10.2.4 DeleteMin
将根出去,得到堆的一个集合。如果根有c个儿子,那么对合并过程进行c-1次调用将该堆重建。

10.2.5 两趟合并法
- step1.从做到有扫描,合并诸儿子对。(注意奇数情况,将最后一个儿子与最右合并的结果合并)
- step2.从右到左,将第一次扫描剩下的最右边的树和当前合并的结果合并
例如:有8个儿子:c1-c8,
第一次扫描:c1和c2,c3和c4,c5和c6,c7和c8合并,得到d1, d2, d3, d4
第二次扫描:d4和d3合并,然后与d2合并,最后与d1合并


