上一篇:077-preBigData-05Linux常用基本命令
一、项目起源
- Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发
- Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
• GFS ====> HDFS
• Map-Reduce ====> MR
• BigTable ====> HBase
二、Hadoop的优势
因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
- 高扩展性:
在集群间分配任务数据,可方便的扩展数以千计的节点。 - 高效性:
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。 - 高容错性:
自动保存多份副本数据,并且能够自动将失败的任务重新分配。
三、Hadoop组成
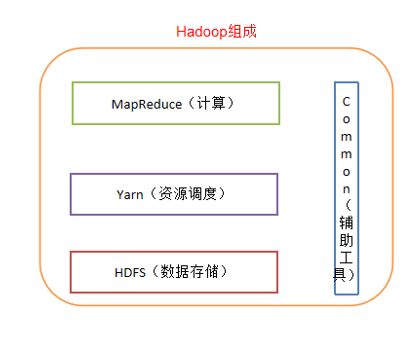
四个部分:
Hadoop HDFS:
一个高可靠、高吞吐量的分布式文件系统。
Hadoop MapReduce:
一个分布式的离线并行计算框架。
Hadoop YARN:
作业调度与集群资源管理的框架。
Hadoop Common:
支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
1、HDFS架构概述
• Namenode:存储元数据
• Datanode:存储数据的节点,会对数据块进行校验
• Secondarynamenode:监控namenode 的元数据,每隔一定的时间进行元数据的合并
2、YARN架构概述
- ResourceManager(rm):
处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度 - NodeManager(nm):
单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令 - ApplicationMaster:
数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错 - Container:
对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息
3、MapReduce架构概述
- MapReduce将计算过程分为两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
4、common通用、辅助
四、环境搭建
依赖jdk,需要Linux版本的jdk。
Linux版本的jdk下载地址
提取码:gxjl
hadoop2.8.4下载地址
提取码:rha6
下载好之后,传输到Linux上。
环境配置
1、关闭防火墙
关闭防火墙:
systemctl stop firewalld.service
禁用防火墙:
systemctl disable firewalld.service
查看防火墙:
systemctl status firewalld.service
2、关闭Selinux
安全增强型 Linux(Security-Enhanced Linux)简称 SELinux,它是一个 Linux 内核模块,也是 Linux 的一个安全子系统。
SELinux 主要由美国国家安全局开发。2.6 及以上版本的 Linux 内核都已经集成了 SELinux 模块。
SELinux 的结构及配置非常复杂,而且有大量概念性的东西,要学精难度较大。很多 Linux 系统管理员嫌麻烦都把 SELinux 关闭了。
SELinux 主要作用就是最大限度地减小系统中服务进程可访问的资源(最小权限原则)。
也就是说,会导致很多访问权限问题。新手很容易遇到设置不生效,没权限问题。所以直接关掉。
vi /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
3、修改IP
用tab补全:
vi /etc/sysconfig/network-scripts/ifcfg-ens
• BOOTPROTO=static
• ONBOOT=yes
• IPADDR=192.168.X.131
• GATEWAY=192.168.X.2
• DNS1=8.8.8.8
• DNS2=8.8.4.4
• NETMASK=255.255.255.0
上面是有线网络。
如果是无线网络,DNS1填网关192.168.X.2并且不要DNS2了。
4、修改resolv.conf
vi /etc/resolv.conf
有线网络如下设置
nameserver 8.8.8.8
nameserver 8.8.4.4
无线网络填网关
nameserver 192.168.X.2
5、修改了网络,一定要重启!!(真垃圾的设计,强行多一步)
重启网卡:
servie network restart
附赠打开和关闭网卡:
service network start
service network stop
6、修改主机名~ 取一个名字吧 ~
hostnamectl set-hostname 主机名
或者
vi /etc/hostname
然后直接填写主机名字
7、修改IP和主机名之间的映射关系
vi /etc/hosts
准备搭三台,提前设定好所有关系。
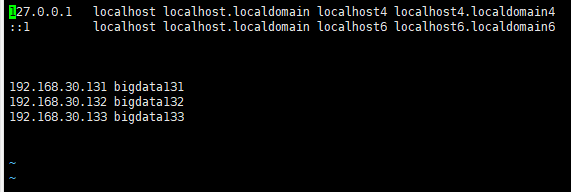
8、在windows的C:\Windows\System32\drivers\etc路径下找到hosts并添加同样内容
192.168.30.131 bigdata131
192.168.30.132 bigdata132
192.168.30.133 bigdata133
9、Xshell连接Linux,输入IP及账号密码
10、设置普通用户权限(可选)
• vi /etc/sudoers 92行 找到root ALL=(ALL) ALL
• 复制一行:AncientMing ALL=(ALL) ALL
11、安装jdk
打开Winscp传输
使用其他方式传输也行。
把上面下载好的jdk和hadoop软件传给Linux。
放在/opt/soft下面
tar zxvf /opt/soft/jdk-8u144-linux-x64.tar.gz
执行解压操作。
配置JAVA_HOME的环境变量
vi /etc/profile

同步配置:
source /etc/profile
完成后,测试好没好:
java -version

再试试javac
javac

这样jdk就好啦。
12、安装hadoop
同上,传输后,解压,然后配置环境变量

同步配置:
source /etc/profile
好了后测试好没好。
hadoop不需要杆:
hadoop version

13、跑一段试试
切换到示例的目录:
cd /opt/soft/hadoop-2.8.4/share/hadoop/mapreduce/

跑一个例子:
hadoop jar hadoop-mapreduce-examples-2.8.4.jar wordcount /opt/soft/test /opt/soft/out

下一篇:079-BigData-07hadoop伪分布式和分布式