大数据技术之 Kafka (第 3 章 Kafka 架构深入 ) Kafka 消费者
3.3.1 消费方式
consumer 采用 pull(拉)模式从 broker 中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。
它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout
3.3.2 分区分配策略
一个 consumer group 中有多个 consumer,一个 topic 有多个 partition,所以必然会涉及到 partition 的分配问题,即确定那个 partition 由哪个 consumer 来消费。
Kafka 有两种分配策略,一是 RoundRobin,一是 Range。
1)RoundRobin (轮询)按照组来消费
分区分配策略之RoundRobin


使用轮询的策略优点:就是一个消费者组多个消费者直接消费消息最多相差1个
缺点:使用轮询的策略有一个问题,当一个消费者组订阅的是多个topic主题,假设有一个消费者组consumergroup(consumerA订阅了主题topic1和consumerB主题topic2)consumerA消费topic1,consumerB消费topic2 ,这看起来似乎没有问题,使用轮询的策略会将消费者组订阅的主题当成一个整体。但是topic1和topic2各有三个partition分区,在kafka内部有一个TopicAndPartition这个类会将topic1和topic2的partition进行排序,假设两个经过排序之后顺序{topic1partition0,topic2partition0,topic2partition1,topic1partition2,topic1partition1,topic2partition2} 然后consumerA和consumerB轮询的拉去消息,这样consumerA就会将topic2的消息给拉取消费了这样是不是有问题?
所以使用轮询策略条件的前提:就是一个消费者组里消费者订阅的主题是一样的,只有consumerA和consumerB都订阅了topic1和topic2,这样使用轮询的方式才不会有问题
2)Range (范围)默认的消费方式 按主题的方式给消费者(谁订阅了我就给谁消费)
分区分配策略之Range


范围range是按照范主题划分的,一个主题7个分区 3个消费者 7除以3除不尽就会分布不均,消费者1消费前topic1的前三个分区,后面两个消费者消费topic1的4和5分区 6和7分区就给消费者3消费,这种情况看起来也没有什么问题?
缺点:假设消费者他们订阅了2个主题topic1和topic2 都是7个分区 ,由于是按主题划分的所以,消费者1就分到了topic1和topic2的1、2、3分区这样消费者1就被分到了6个分区,消费者2和消费者3只分到了4个分区,随着订阅的主题越来越多,这样消费者1和其他消费者相差越来越大,就不均衡了
思考一个问题:消费者消费消息什么时候重新分配?
当消费者个数发生变的时候,
1,假设topic1有6个分区 三个消费者A、B、C,不管用什么策略分配,假设C负责消费partition4和partition5,突然C挂掉了,这个时候partition4和partition5需不需要消费,答案当然是要,那怎么消费?当然是重新分配
2,假设topic1有6个分区 三个消费者A、B、C、D,当消费者A服务起来的时候6个分区都分配给了A,当B起来的时候重新分配,当C起来时候也会重新分配,消费者A、B、C都分配到了2个partition,当第四个消费者D加进来的时候,会怎么办?还是上面那句话,消费者个数发生变化的时候,就会触发分区分配策略重新分配
总结:当消费者个数发生变的时候,消费者个数可以增多或者减少,甚至可以增多至比分区数还多的时候,照样会重新分配,只是有些消费者可能被分配不到
3.3.3 offset 的维护
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
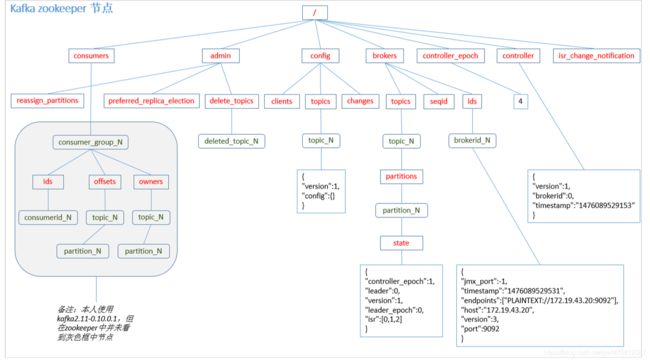
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
1)修改配置文件 consumer.properties
exclude.internal.topics=false
2)读取 offset
0.11.0.0 之前:
bin/kafka-console-consumer.sh --topic __consumer_offsets zookeeper backup01:2181 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties from-beginning
0.11.0.0 之后版本(含):
bin/kafka-console-consumer.sh --topic __consumer_offsets zookeeper backup01:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties frombeginning 但是在新版本中
[root@backup01 kafka_2.12-2.4.1]# bin/kafka-console-consumer.sh --topic __consumer_offsets zookeeper backup01:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties frombeginning
Missing required argument "[bootstrap-server]"
那我们不能用zookeeper了
[root@backup01 kafka_2.12-2.4.1]# bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server backup01:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties frombeginning