使用Antlr4和neo4j解析sql生成数据地图
使用Antlr4和neo4j解析sql生成数据地图
杂谈1:
之前学习搭建atlas平台的时候就很好奇他是如何解析sql,然后根据sql生成对应的血缘图的,在学习spark源码的过程中认识了antlr4 这样一个可以根据自定义语法规则来解析成语法树的工具
于是我就希望可以参考atlas的解析功能,将复杂的长sql解析出它的数据地图出来.
杂谈2:
那么有人会问了,这样做的意义在哪里.
如果做过数据开发之类的工作的话,应该会遇到那种情况,
维护了大量的表,但是不知道这些表究竟被谁用了,
因为迭代更新,可能需要改动表结构,但是不知道会影响到哪些表,这种情况比比皆是.
或者是某些表已经启用了,成了数据孤岛了,但是你还一直浪费资源维护它,种种情况,让我们意识到数据库表的元数据维护的重要性.
杂谈3:
实现这个功能主要是通过用antlr4定义了sql的语法规则,生成对应的接口代码,让我们可以遍历sql的语法树
然后就算监听节点,解析sql,然后构建成neo4j能够识别的语言进行导入和展示
更多情况下我们省去了麻烦手动维护在execl中,但是数据的准确性以及实时性得不到保证,所以及时进行元数据管理,可以避免发展后期形成数据沼泽.
apache Atlas 1.2.0 搭建以及hive的集成
https://blog.csdn.net/weixin_44445168/article/details/110727429
Antlr4学习笔记
https://blog.csdn.net/weixin_44445168/article/details/111060493
环境准备
antlr4
利用antlr4生成的语法树,通过它提供的监听接口,可以监听到每个节点及其子节点的内容和状态,以此来解析我们的sql
这里解析的sql选用oracle,oracle对应的plsql.g4文件在antlr4git中已经提供了
https://github.com/antlr/grammars-v4/tree/master/sql/plsql
我也已经上传到资源库了
https://download.csdn.net/download/weixin_44445168/14967225
生成对应的接口文件后(可以看上面关于antlr4 的博客关于接口文件如何生成)
关于入口节点我们选用compilation_unit
我们可以测试一下
这里提供一条测试sql
select * from tablea a
left join
tableb b on a.id=b.id
left join
tablec c on a.id=c.id
left join
(select id from tabled d left join tablee on e.id =d.id) d1
on d1.id=a.id
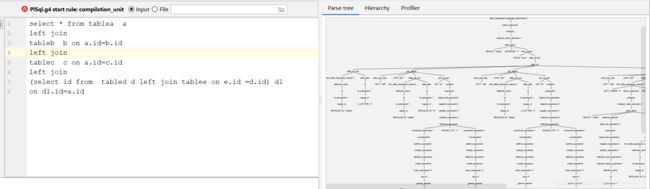
可以看到右边就是我们将sql解析后的语法树,我们可以先观察哪些节点是我们需要的,以及哪些节点需要如何处理.
NEO4J
概述
图形数据库是以图形结构的形式存储数据的数据库。 它以节点,关系和属性的形式存储应用程序的数据。 正如RDBMS以表的“行,列”的形式存储数据,GDBMS以“图形”的形式存储数据。
对于NEO4J这里不多做赘述,我也是为了借鉴atlas才拿来用的,所以如果后续感兴趣的话在进行进一步的探索图数据库
这里提供一份免费的neo4j资源当然你也可以去对应的官网下载
https://download.csdn.net/download/weixin_44445168/14965747
下载neo4j 后免安装解压后进入安装bin目录,调出cmd,执行
neo4j.bat console

可以看到对应的端口以及起来了,可以通过访问
http://localhost:7474 进入neo4j的web界面

如果是第一次的话,需要重置一下登录密码,
zh:neo4j
mm:neo4j
这里提供一份测试代码
public static void main(String[] args) {
//测试
Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "admin"));
Session session = driver.session();
session.run("CREATE (a:Person {name: {name}, title: {title}})",
parameters("name", "Arthur001", "title", "King001"));
StatementResult result = session.run("MATCH (a:Person) WHERE a.name = {name} " +
"RETURN a.name AS name, a.title AS title",
parameters("name", "Arthur001"));
while (result.hasNext()) {
Record record = result.next();
System.out.println(record.get("title").asString() + " " + record.get("name").asString());
}
session.close();
driver.close();
}
代码上传到github上了,有兴趣的可以下载玩玩
antlr4 非研发的还是建议不要去探索,我反正比较吃力
https://github.com/lxw2/Antrl4_Plsql
目前简单的展示,如果你有更好的想法欢迎一起交流
补充:
neo4j 在调试过程中比较常用的一些语句
查询某个节点的内容
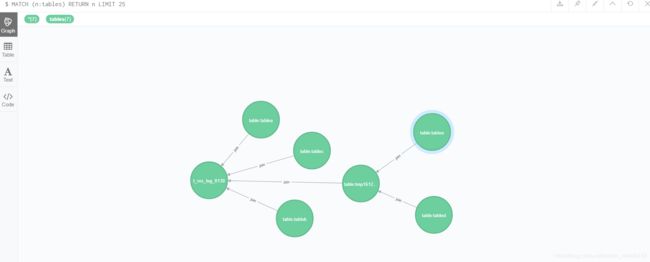
MATCH (n:tables) RETURN n LIMIT 25
删除所有的关系
MATCH (n:tables)-[r]-() DELETE n,r
删除所有的节点 (如果删除的节点中存在带有关系的,需要先删除关系)
MATCH (n:tables) delete n
创建节点标签并为之创建关联关系
CREATE (t_02:tables {comment:'table:t_02',status:'live'})
CREATE (t_01:tables {comment:'table:t_01',status:'live'})
create (t_02)-[:join]->(t_01)
对这些语句有兴趣的可以去以下网站了解,获取博客,现在已经有很多这种博客提供查阅了
https://www.w3cschool.cn/neo4j/
–仅供个人学习使用参考