前端试题(四)
1. vue过滤器使用场景
2. v-on绑定多个方法
一个事件绑定多个函数:
点击
3. 在菜单结构不确定时,前端如何动态渲染
树形结构:深度遍历、广度遍历(递归)
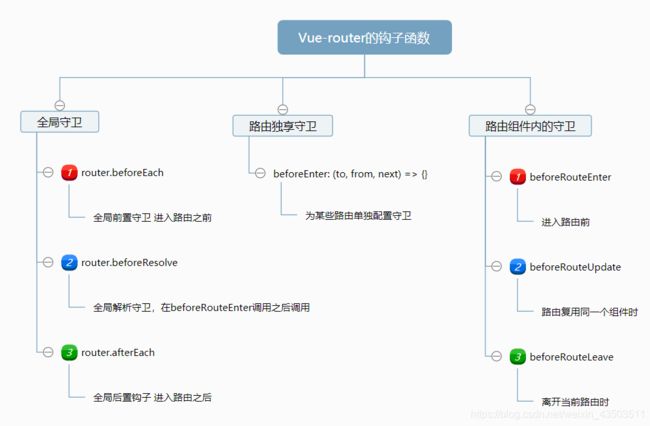
4. Vue-router的钩子函数
[Vue的钩子函数路由导航守卫、keep-alive、生命周期钩子
路由导航守卫
5. Vue-router的实现原理
更新视图但不重新请求页面,是前端路由原理的核心之一,目前在浏览器环境中这一功能的实现主要有2种方式,Hash模式和History模式。
6. Vuex的实现原理
Vuex是一个专为Vue服务,用于管理页面数据状态、提供统一数据操作的生态系统。它集中于MVC模式中的Model层,规定所有的数据操作必须通过 action - mutation - state change 的流程来进行,再结合Vue的数据视图双向绑定特性来实现页面的展示更新。统一的页面状态管理以及操作处理,可以让复杂的组件交互变得简单清晰,同时可在调试模式下进行时光机般的倒退前进操作,查看数据改变过程,使code debug更加方便。
Vuex框架原理与源码分析
7. Vue-cli的自定义指令
像vue ui那样在终端用的指令??还是vue的自定义指令
8. keep-alive的两个属性
在开发Vue项目的时候,大部分组件是没必要多次渲染的,所以Vue提供了一个内置组件keep-alive来缓存组件内部状态,避免重新渲染。
- 缓存路由组件:将所有路径匹配到的路由组件都缓存起来(某个组件切换后不进行销毁,而是保存之前的状态)
缺点:所有的路由组件都被缓存了,严重浪费性能,而且也不符合需求
- 缓存特定组件
在keep-alive上有两个属性,只有匹配的组件会被缓存。
- include 值为字符串或者正则表达式匹配的组件name会被缓存。
- exclude 值为字符串或正则表达式匹配的组件name不会被缓存。
- 路由的meta属性
除了方法二,我们还可以利用路由中的meta属性来控制
{
path: '/',
name: 'home',
meta:{
keepAlive:true
},
component: Home
}
新的问题:组件被缓存,并没有被销毁,所以组件在切换的时候也就不会被重新创建,自然也就不会调用created等生命周期函数,所以此时要使用activated与deactivated来获取当前组件是否处于活动状态。
- 在home组件里面写入了activated与deactivated生命周期函数:
activated(){
console.log("哎呀看见我了")
console.log("----------activated--------")
},
deactivated(){
console.log("讨厌!!你又走了")
console.log("----------deactivated--------")
}
9. keep-alive组件
10. Vue的核心
Vue核心思想
11. Vue的修饰符
- 修饰符
- 事件修饰符
- 按键修饰符
- 系统修饰符
vue常用的修饰符
12. ES5、ES6的区别
所有es6的新特性都要答到
JavaScript、ES5和ES6的介绍和区别
13. 单页面应用的原理和优缺点
单页面应用指只有一个主页面的应用,浏览器一开始就要加载所有必须的html,js,ss,单页面的页面跳转仅刷新局部资源,多应用于pc端,
多页面就是指一个页面中有多个页面,页面跳转时是整页刷新
单页面优点:
1.用户体验好,快,内容改变不需要重新加载整个页面;
2.没有页面之间的切换,就不会出现“白屏现象”
单页面缺点:
1.首次加载耗时比较多;
2.不利于SEO
3.不可以用导航实现前进后退效果;
4.页面复杂度高
14. 浏览器兼容
15. 前端文件上传
百度的webuploader,基于jquery封装的
原生ajax上传/axios.post上传+进度条+后端接收文件
15.1 原生
掘金:前端本地文件(图片)操作与上传,并显示在页面中
底层实现还是基于input输入框,然后利用onchange事件,监听文件选择的事件,然后利用formData对象装载需要上传的文件,最后通过XMLHttpRequest来进行文件的网络异步传输。
inputDom.files[0]
var fd=new FormData()
fd.append('pic',pic)
xhr.upload.onprogress
- lengthComputable
- loaded
- total
这里的处理,在于如何显示出来(读取文件)
let fileReader = new FileReader()
fileReader.onload
fileReader.readAsDataURL(this.files[0])赋值给img标签的src
15.1.1 在ipt的onchange事件里打印this对象,有files属性,是一个数组

15.1.2 打印files[0]

15.1.3 input dom对象的value值

- input标签在选择同一个文件上传时的bug处理
input在上传文件的时候,如果连续上传同一个文件的时候,会出现上传无效的bug。这个问题出现在第二次选择同一个文件的时候,input的onchange方法并不会触发执行。
解决这个问题,上网搜索了一下,找到了办法,就是需要重新设定input的type属性。每次选择完文件后,将input元素的type设置成text,然后在下一次click的时候将其设置成file,再触发onchange事件,解决这个问题。
15.2 拖拽、粘贴
15.2.1 enctype
- 编码格式是multipart/form-data,
参数和参数之间是且一个相同的字符串隔开的,比如这里是:
------WebKitFormBoundary72yvM25iSPYZ4a3F

- 编码是application/x-www-form-urlencoded
参数和参数之间使用&连接,如:
key1=value1&key2=value2
如果直接就是一个FormData了,那么直接用ajax发出去就行了,不用做任何处理。
15.2.2 拖拽
dragover事件
event.originalEvent.dataTransfer.files[0]
fileReader读url,formData,append
$(".img-container").on("dragover", function (event) {
event.preventDefault();
})
.on("drop", function(event) {
event.preventDefault();
// 数据在event的dataTransfer对象里
let file = event.originalEvent.dataTransfer.files[0];
// 然后就可以使用FileReader进行操作
fileReader.readAsDataURL(file);
// 或者是添加到一个FormData
let formData = new FormData();
formData.append("fileContent", file);
})
15.2.3 粘贴
contenteditable="true"
paste
event.originalEvent.clipboardData.files[0]
hello, paste your image here
$("#editor").on("paste", function(event) {
let file = event.originalEvent.clipboardData.files[0];
});
15.3 分片 断点续传
- 七牛云
1、修改服务端上传的限制配置;Nginx 以及 PHP 的上传文件限制 不宜过大,一般5M 左右为好;
2、大文件分片,一片一片的传到服务端,再由服务端合并。这么做的好处在于一旦上传失败只是损失一个分片而已,不用整个文件重传,而且每个分片的大小可以控制在4MB以内,服务端限制在4M即可。
3、使用七牛JavaScript SDK分片上传
博客园断点续传
15.4 如何限制值只能上传png格式
文件头信息
hexdump
15.5 如何判断文件唯一性
- 算hash值,比如md5
- 文件过大,怎么算md5不卡顿:
- web-worker
- 时间切片(react fiber架构 requestldleCallback)
- 抽样
15.6 文件切片数量过多,上传请求过多,导致卡顿,怎么处理
- 控制异步任务并发数量(如果有报错怎么重试,报错三次怎么统一终止所有切片)
15.7 移动端/pc端,每个切片大小如何控制
根据网速来动态调整包的大小
15.8 并发数+包控制如何实现
五月分割线
16. 浏览器缓存
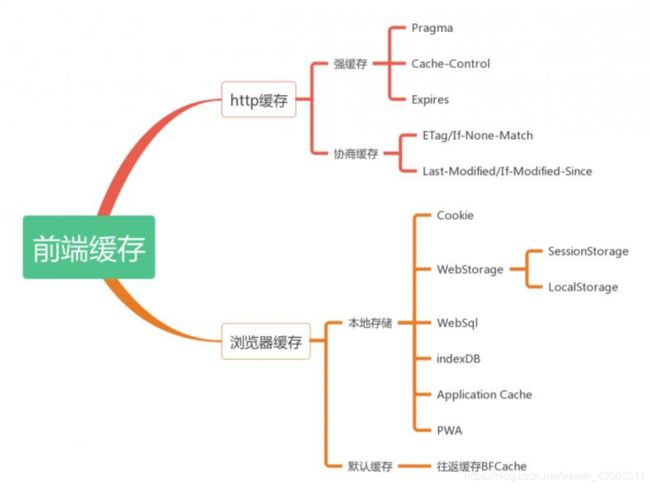
1. DNS缓存
有dns的地方,就有缓存。浏览器、操作系统、Local DNS、根域名服务器,它们都会对DNS结果做一定程度的缓存。
DNS查询过程如下:
- 首先搜索浏览器自身的DNS缓存,如果存在,则域名解析到此完成。
- 如果浏览器自身的缓存里面没有找到对应的条目,那么会尝试读取操作系统的hosts文件看是否存在对应的映射关系,如果存在,则域名解析到此完成。
- 如果本地hosts文件不存在映射关系,则查找本地DNS服务器(ISP服务器,或者自己手动设置的DNS服务器),如果存在,域名到此解析完成。
- 如果本地DNS服务器还没找到的话,它就会向根服务器发出请求,进行递归查询。
2. CDN缓存
当浏览器向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向服务器发出回源请求,从服务器拉取最新数据,更新本地缓存,并将最新数据返回给客户端。 CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。
打个比方:
10年前,还没有火车票代售点一说,12306.cn更是无从说起。那时候火车票还只能在火车站的售票大厅购买,而我所在的小县城并不通火车,火车票都要去市里的火车站购买,而从我家到县城再到市里,来回就是4个小时车程,简直就是浪费生命。后来就好了,小县城里出现了火车票代售点,甚至乡镇上也有了代售点,可以直接在代售点购买火车票,方便了不少,全市人民再也不用在一个点苦逼的排队买票了。
简单的理解CDN就是这些代售点(缓存服务器)的承包商,他为买票者提供了便利,帮助他们在最近的地方(最近的CDN节点)用最短的时间(最短的请求时间)买到票(拿到资源),这样去火车站售票大厅排队的人也就少了。也就减轻了售票大厅的压力(起到分流作用,减轻服务器负载压力)。
用户在浏览网站的时候,CDN会选择一个离用户最近的CDN边缘节点来响应用户的请求,这样海南移动用户的请求就不会千里迢迢跑到北京电信机房的服务器(假设源站部署在北京电信机房)上了。
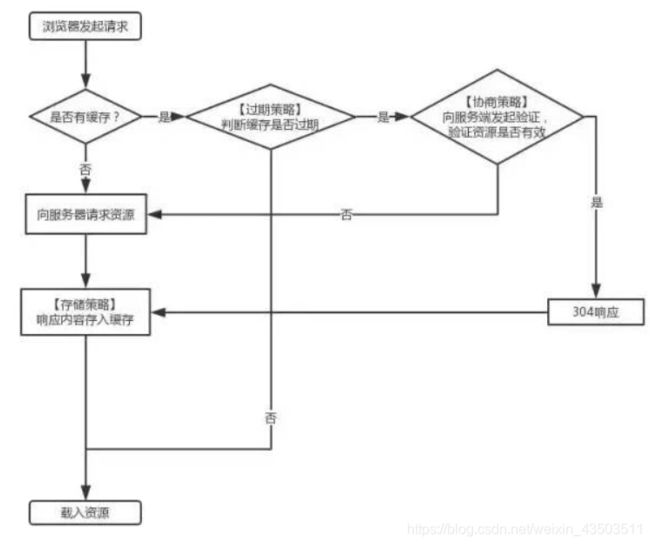
3. http缓存
简书http缓存
实践这一次,彻底搞懂浏览器缓存机制

- 只缓存get请求相应的资源
- 缓存是从第二次请求开始
- 第一次请求资源时,服务器返回资源,并在响应头中回传资源的缓存参数
- 第二次请求时,浏览器判断这些请求参数
Cache-Control': 'max-age=300'在服务端设置- js设置
里的标签 - Cache-Control的默认值就是no-cache(需要进行协商缓存)
- HTTP中并没有指定如何生成ETag,哈希是比较理想的选择。(在服务器端实现中,很多情况下并不会用哈希来计算ETag,这会严重浪费服务器端资源,很多网站默认是禁用ETag的)
- 思考:多服务器时,INode不一样,所以不同的服务器生成的ETag不一样,所以用户有可能重复下载(这时ETag就会不准),明白了上面的原理和设置后,解决方法也很容易,让ETag后面 二个参数,MTime和Size就好了。只要ETag的计算没有INode参于计算,就会很准了。
- 关于ETAG的工作原理
- 使用 Last-Modified 的问题在于它的精度在秒(s)的级别,比较适合不太敏感的静态资源。
- 思考,这几个参数怎么配合使用 ?
3.1 三级缓存原理 (访问缓存优先级)
- 先在内存中查找,如果有,直接加载。
- 如果内存中不存在,则在硬盘中查找,如果有直接加载。
- 如果硬盘中也没有,那么就进行网络请求。
- 请求获取的资源缓存到硬盘和内存。
3.2 强缓存(有没有过期)
- Expires:这个时间代表着这个资源的失效时间,在此时间之前,即命中缓存。这种方式有一个明显的缺点,由于失效时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。
- Cache-Control:它是一个相对时间,例如 Cache-Control:max-age=3600,代表着资源的有效期是 3600 秒。
- no-cache:需要进行协商缓存,发送请求到服务器确认是否使用缓存。
- no-store:禁止使用缓存,每一次都要重新请求数据。
- public:可以被所有的用户缓存,包括终端用户和 CDN 等中间代理服务器。
- private:只能被终端用户的浏览器缓存,不允许 CDN 等中继缓存服务器对其缓存。
Cache-Control 与 Expires 可以在服务端配置同时启用,同时启用的时候 Cache-Control 优先级高。
3.3 协商缓存(有没有变化)
- Last-Modify(服务器)/If-Modify-Since(浏览器)
- 浏览器第一次请求一个资源的时候,服务器返回的 header 中会加上 Last-Modify,Last-modify 是一个时间标识该资源的最后修改时间。
- 当浏览器再次请求该资源时,request 的请求头中会包含 If-Modify-Since,该值为缓存之前返回的 Last-Modify。服务器收到 If-Modify-Since 后,根据资源的最后修改时间判断是否命中缓存。
- ETag/If-None-Match:ETag 可以保证每一个资源是唯一的,资源变化都会导致 ETag 变化。
4 localStorage、sessionStorage、cookie的区别,应用场景
17. 浏览器输入网址
- 对url地址进行域名解析,解析为ip地址
- 本机hosts文件 - 浏览器本身DNS缓存 - 本机配置的首选DNS服务器(ip地址)
- 浏览器向服务器发起tcp连接,三次握手
- 浏览器发送请求报文(请求行、请求头、空行、请求体)
- 服务器响应数据
- 渲染页面
html解析->外部样式、脚本加载->外部样式执行(CSSOM树)->外部脚本执行->html继续解析->DOM树构建完成->CSSOM + DOM绘制Render Tree-> 页面的重排、重绘 ->加载图片->页面加载完成。
若在HTML头部加载JS文件,由于JS阻塞,会推迟页面的首绘。为了加快页面渲染,一般将JS文件放到HTML底部进行加载,或是对JS文件执行async或defer加载。
拓展5:
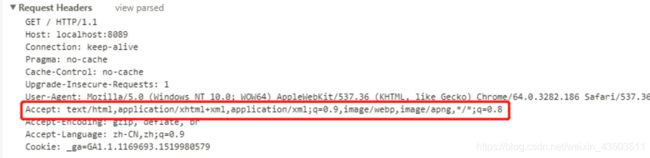
请求报文头中,accept代表客户端希望接受的数据类型,这是浏览器自动封装的请求头。如果服务器返回的content-type是accept中的任何一个(比如text/html ),浏览器都能解析,并直接展示在网页上。如果服务器返回的content-type是其他类型,此时浏览器有三种处理状态:
8. 正常显示。例如返回类型为text/javascript,浏览器能直接处理并展示。
9. 下载。例如返回类型为application/octet-stream(二进制流,不知道下载文件类型),这种浏览器不能直接处理的,会被下载。
10. 报错。当我们返回一个字符串hello world,却使用text/xml,格式时,浏览器不能正确解析,就会报错,并把报错信息呈现在网页中。
浏览器能直接处理很多种格式,并直接呈现在网页中,并不限于accept中规定的字段,具体有哪些,就需要自己亲自动手试试了。
18. data为什么要作为方法返回
data的值是一个对象, 是引用数据类型,如果不用函数return ,每个组件的data 都是同一个对象,一个数据改变了其他也改变了;
所以为了不让多处的组件共享同一data对象,只能返回函数。这都是因为js本身的特性带来的,跟vue本身设计无关。
19. nginx(轻量级占用更少内存,支持更多的并发连接)、 apache区别
Apache和Nginx在应用中如何选择?
- 一般访问量网站优先使用Apache,稳定可靠。
- Apache模块非常丰富,为了用它的模块选它。
- Apache的rewrite非常强大,rewrite多就选它。
- 大访问量优先使用Nginx,支持更多的并发连接。
- 处理的都是静态资源(图片 html),首选Nginx(Nginx定位于静态资源分发,反向代理,在处理静态资源更有优势)
- 需要反向代理使用Nginx。
20. websocket(持久化、全双工通讯协议)
1. websocket使用
看完让你彻底理解 WebSocket 原理
- ajax轮询:定时,每隔一段时间问一下
- 长轮询:打电话,收到回复才挂断,并发起新的
服务器有更新时,前端不需要去轮询(消耗资源),因为浏览器可以主动推送消息。
前端代码:
url:
- 未加密:ws://
- 已加密:wss://
if (window.WebSocket) {
// wsurl服务器地址
websocket = new WebSocket(wsurl);
//连接建立
websocket.onopen = function (evevt) {
......
}
//收到消息
websocket.onmessage = function (event) {
var msg = JSON.parse(event.data); //解析收到的json消息数据
var umsg = msg.message; //消息文本
var uname = msg.name; //发送人
......(一些操作:比如显示消息在对话框)
}
//发生错误
websocket.onerror = function (event) {
......(一些操作:比如显示错误提示在对话框)
}
//连接关闭
websocket.onclose = function (event) {
......
}
function send() {
var name = $('#name').val();
var message = $('#message').val();
var msg = {
message: message,
name: name
};
try {
websocket.send(JSON.stringify(msg)); // 复杂的数据结构要先进行序列化
} catch (ex) {
console.log(ex);
}
}
}
else {
alert('该浏览器不支持web socket');
}
- var 实例 = new WebSocket(url)
- 实例.onopen = function(event){ }
- 实例.onmessage = function(event){ }
- 实例.onerror = function(event){ }
- 实例.onclose = function(event){ }
- 实例.send(data) // 向服务器发送消息
2. HTTP 1.0 1.1 2.0
2.1. HTTP 1.0 连接无法复用
浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接。(每次请求都经历三次握手和慢启动)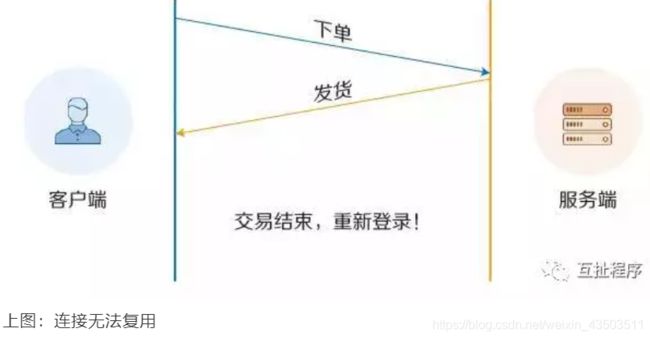
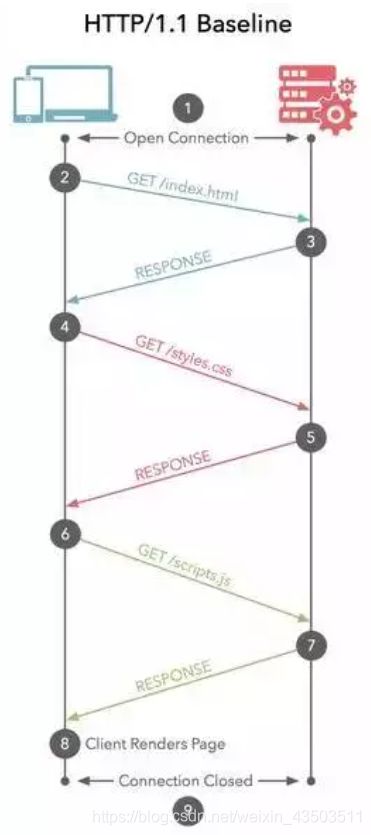
2.2. HTTP 1.1 持久连接/长连接

-
支持持久连接(HTTP/1.1的默认模式使用带流水线的持久连接),在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。
-
HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞。
-
缓存处理:在HTTP1.0中主要使用header里的If-Modified-Since,Expires(协商缓存/强缓存)来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match(协商缓存)等更多可供选择的缓存头来控制缓存策略。
-
支持断点续传
Accept-Ranges : bytes | none(图片等资源) -
HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
-
在HTTP 1.1中增加Host请求头字段。
我们可以在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
浏览器阻塞(HOL blocking/head of line blocking):
浏览器对于同一个域名,一般PC端浏览器会针对单个域名的server同时建立6~8个连接,手机端的连接数则一般控制在4~6个(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。HTTP1.0有这个问题。
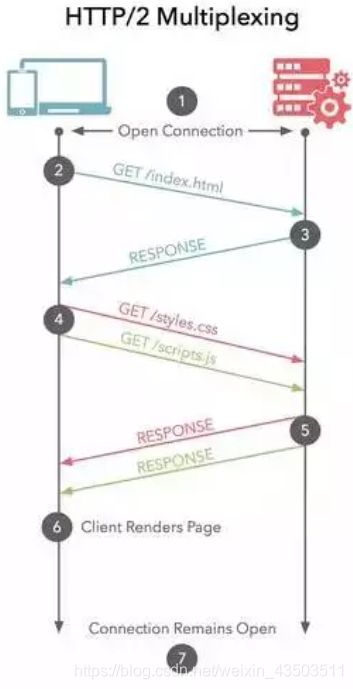
2.3. HTTP 2.0
- HTTP/2多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行
- 服务端推送
21. 软件开发流程、软件模型
需求分析-概要设计-详细设计-程序编码-程序测试-软件交付-客户验收-码农维护
增量模型:设计核心功能+逐步累加
22. js处理异步的几种方式
- 回调函数
- 事件监听
- promise
- async/await
23. vue3
24. 版本迭代时,修复bug,使用git是一个怎样的过程
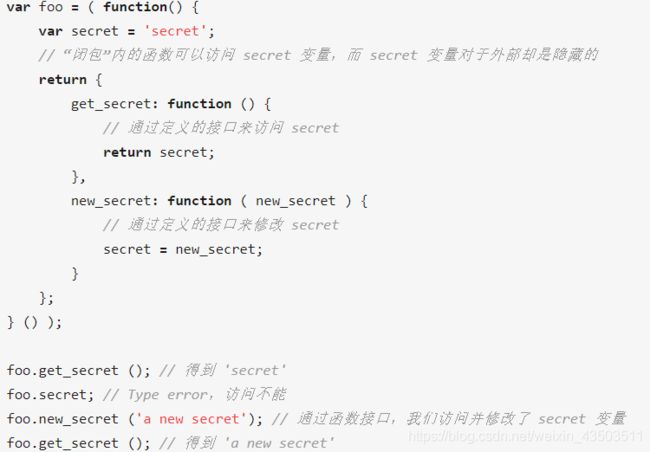
25. 闭包的实际应用,除了闭包还有什么内存泄漏的情况
- 闭包用来封装变量,收敛权限。
- 利用闭包可以给对象设置私有属性并利用特权(Privileged)方法访问私有属性。
- 如果外界想访问secret变量,只能通过我定义的函数get_secret来进行访问,用new_secret进行设置。外界能做的就只是使用我的函数,然后传几个不同的参数罢了。
26. 怎么判断一个页面加载完了
- window.onload【页面包含图片等文件在内的所有元素都加载完成】
当一个文档完全下载到浏览器中时,才会触发window.onload事件。这意味着页面上的全部元素对js而言都是可以操作的,也就是说页面上的所有元素加载完毕才会执行。这种情况对编写功能性代码非常有利,因为无需考虑加载的次序。 - jQuery的ready方法【表示文档结构已经加载完成(不包含图片等非文字媒体文件)】
会在DOM完全就绪并可以使用时调用。虽然这也意味着所有元素对脚本而言都是可以访问的,但是,并不意味着所有关联的文件都已经下载完毕。换句话说,当HMTL下载完成并解析为DOM树之后,代码就会执行。
$(document).ready(function(){
dosth//你要做的事情
})
- document.onreadystatechange
document.onreadystatechange = function() //当页面加载状态改变的时候执行function
{
if(document.readyState == "complete")
{ //当页面加载状态为完全结束时进入
init(); //你要做的操作。
}
}
27. 页面加载优化、加载图片优化
页面加载优化
-
精灵图
-
使用外部的JavaScript和CSS(浏览器就有可能缓存它们,从而在以后加载的时候能够直接使用缓存,而HTML文档的大小减小,从而提高加载速度)
-
样式表放在头部(页面内容逐步呈现,改善用户体验,防止“白屏”)、脚本放在底部(js的下载和执行会阻塞Dom树的构建)
-
压缩CSS和JavaScript【移除不必要的字符(如TAB、空格、回车、代码注释等)】
-
压缩:客户端可以通过HTTP请求中的Accept-Encoding头来表示对压缩的支持
Accept-Encoding: gzip服务器看到请求中有这个头,就会使用客户端列出来的方法中的一种来进行压缩。Web服务器通过响应中的Content-Encoding来通知 Web客户端。
Content-Encoding: gzip -
浏览器缓存
-
cdn(将整个站点的静态资源放到一个专门的域名下,以求减小网络开销)
加载图片优化
28. get/post有什么区别
| GET | POST |
|---|---|
| 回退时是无害的 | 再次提交请求 |
| 可以被收藏 | 不能被收藏 |
| 请求参数会被完整保留在浏览器历史记录里 | 不保留参数 |
| 参数是有长度限制的 | 参数无限 |
| 更不安全 暴露参数 | 更安全 |
| 参数通过URL传递 | request body |
| 参数的数据类型,GET只接受ASCII字符 | 无限制 |
| GET请求会被浏览器主动cache | POST不会,除非手动设置 |
29. 前端请求时参数错误状态码400
请求没有进入后台服务器里
原因: (1)前端提交的字段名称或者字段类型和后台的实体类不一样或者前端提交的参数跟后台需要的参数个数不一致,导致无法封装
(2)前端提交到后台的数据应该是JSON字符串类型,而前端没有将对象转化为字符串类型;
解决方法: 对照字段名称,类型保证一致
30. 同源策略具体要解决什么安全问题
31. http2.0
32.前端优化
- 从外部引入css、js,对优化有什么帮助?
- 当我们浏览网页的时候,在客户端这边都会有页面的缓存文件。在我们访问这一个页面的时候,客户端就会下载css和js文件到本地。其实区别就在这里,当我们访问完这一页面,再去访问网站其他页面,页面就会重新加载一次。如果我们将css样式和js脚本写到html网页当中,那么它将每次都得重新加载一次这些css样式和js脚本。但是,通过外部引入的方式导入css文件和js文件则不同,因为之前访问页面的时候客户端已经下载js文件和css文件到本地,所以再次访问页面的时候就会判断不会再次下载这个文件,也就是说访问页面的时候对于css,js静态文件如果未修改过页面在刷新或者其他页面引用的相同路径的文件的时候会直接用缓存,不需要再次从服务器下载。这样就减少了网页载入的速度,因为更利于网页的优化。
- 使用精灵图,如果图片很大呢?
- 博客园精灵图使用注意事项
- 请求的次数越少越好吗?如果和之前同域的情况下,没有耗费
- 精灵图,为什么能更快呢?
- 所有的js都放下面吗?如果页面依赖这个js呢?
- 304具体的交互流程,什么情况下产生的304
33. 设计模式-单例模式
34. 操作系统里进程和线程的区别
35. 死锁及发生死锁的条件
36. 32位的机器最大能承载多大的内存
37. https怎么验证ca证书,如果黑客获取证书呢?
38. 组件复用
39. 闭包的应用场景,一定会用到闭包
笔试题
1. select下拉列表
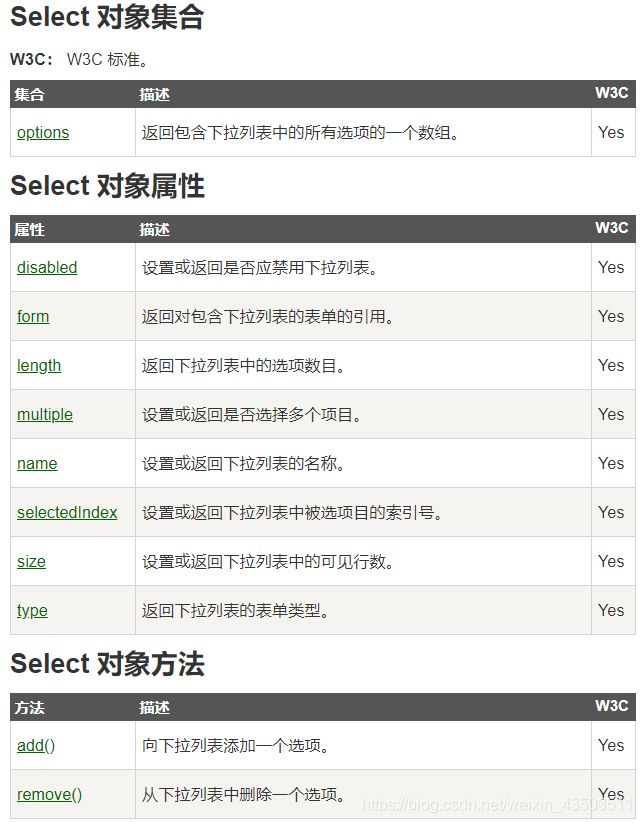

-
下拉列表属性
selected(默认选中)
autocomplete
autofocus(规定下拉列表在页面加载时自动获得焦点)
disabled
select对象
selectedIndex
option对象 -
js事件
//js事件
οnchange="fun(this.options[this.options.selectedIndex].text)"
//获取文本的值
this.options[this.options.selectedIndex].text 是文本的值
//获取value的值
this.options[this.options.selectedIndex].value 是value值
- 运用new Option(“文本”,“值”)方法添加选项option
var obj = document.getElementById("mySelect");
obj.add(new Option("4","4"));
- 删除所有选项options
var obj = document.getElementById("mySelect");
obj.options.length = 0;
- 删除选中选项option
var obj = document.getElementById("mySelect");
var index = obj.selectedIndex;
obj.options.remove(index);
- 删除select
var obj = document.getElementById("mySelect");
obj.parentNode.removeChild(obj); //移除当前对象
- 修改选中选项option
var obj = document.getElementById("mySelect");
var index = obj.selectedIndex;
obj.options[index] = new Option("three",3); //更改对应的值
obj.options[index].selected = true; //保持选中状态
2. 使图片具有”提交”按钮同样的功能
直接使用< input type=“image”>即可,此标签放置在标签内就具有提交功能,如果不在< form>标签内,则可以使用< input type=“image” onClick = “formName.submit()”>方式提交。
说明:
INPUT type=image 元素 | input type=image 对象
创建一个图像控件,该控件单击后将导致表单立即被提交。
3. javascript进行表单验证的目的是
b)检查提交的数据必须符合实际
4. class不属于javascript关键字
5. [‘1’,‘2’, ‘3’].map(parseInt)
['1','2', '3'].map(parseInt)
(3) [1, NaN, NaN]
由于map的回调函数的参数index索引值作了parseInt的基数radix,导致出现超范围的radix赋值和不合法的进制解析,才会返回NaN。
parseInt(string, radix)
| 参数 | 描述 |
|---|---|
| string | 必需。要被解析的字符串。 |
| radix | 可选。表示要解析的数字的基数。该值介于 2 ~ 36 之间。如果省略该参数或其值为 0,则数字将以 10 为基础来解析。如果它以 “0x” 或 “0X” 开头,将以 16 为基数。如果该参数小于 2 或者大于 36,则 parseInt() 将返回 NaN。 |
6. pixelTop和top
都不是Location对象的属性
| pixelTop | top |
|---|---|
| 返回以像素为单位的位置坐标的数值 | 返回带单位的位置坐标字符串 |
7. 正则
+号代表前面的字符必须至少出现一次(1次或n次)*号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)?问号代表前面的字符最多只可以出现一次(0次、或1次)$匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。- *、+ 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
| 符号 |含义 |
|–|--|
| + |1~n {1,} |
| * |0~n {0,}|
| ? |0或1 {0,1} |
|^ | 开始 |
| $ | 结尾 |
| \ |转义 |
| ( )| 子表达式|
| .| 除换行符 \n 之外的任何单字符|
||| 两项之间的一个选择 |
|{n} | 匹配确定的 n 次|
| {n,}|至少匹配n 次 |
|{n,m} | 最少匹配 n 次且最多匹配 m 次|
| \b| 匹配一个单词边界,即字与空格间的位置。|
| \B| 非单词边界匹配|
| \1 |指定第一个子匹配项 |
|g | 将该表达式应用到输入字符串中能够查找到的尽可能多的匹配|
| i| 不区分大小写|
| [xyz]|匹配所包含的任意一个字符 |
| \d| 匹配一个数字字符 |
|\D | 匹配一个非数字字符。等价于 [^0-9]|
| \s| 匹配任何空白字符,包括空格、制表符、换页符等等 |
|\S | 匹配任何非空白字符|
|\w |匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
| \W| 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
匹配