Sqoop基础命令
获取帮助:
$ sqoop help显示MySQL数据库loudacre数据库中的表:
$ sqoop list-tables --connect \
jdbc:mysql://localhost/loudacre --username training --password training查看sqoop import的功能
$ sqoop import -help使用sqoop导入MySQL数据库中loudacre数据库中的表accounts,并存储到HDFS的/loudacre目录下:
$ sqoop import \
--connect jdbc:mysql://localhost/loudacre \
--username training --password training \
--table accounts \
--target-dir /loudacre/accounts \
--null-non-string '\\N'
--null-non-string功能告诉Sqoop将空值表示为\ N,这使得导入的数据与Hive和Impala兼容。在HDFS的表中数据后面追加字段 acct_num 大于129761的数据
$ sqoop import \
--connect jdbc:mysql://localhost/loudacre \
--username training --password training \
--incremental append \
--null-non-string '\\N' \
--table accounts \
--target-dir /loudacre/accounts \
--check-column acct_num \
--last-value 129761查询MySQL数据库中loudacre数据库的表webpage的前十条数据:
$ sqoop eval \
--query "SElECT * FROM webpage LIMIT 10" \
--connect jdbc:mysql://localhost/loudacre \
--username training -password training导入MySQL数据库中loudacre数据库中表webpage的数据到HDFS,使用 \t 作为字段分隔符
$ sqoop import \
--connect jdbc:mysql://localhost/loudacre \
--username training --password training \
--table webpage \
--target-dir /loudacre/webpage \
--fields-terminated-by "\t"导入MySQL数据库中loudacre数据库中的表accounts表,要求字段state为ca,acct_close_dt is null:
$ sqoop import \
--connect jdbc:mysql://localhost/loudacre \
--username training --password training \
--table accounts \
--target-dir /loudacre/accounts \
--null-non-string "\\N"
--where "state='CA' and acct_close_dt is null"直接将MySQL中数据导入Hive(Impala):
$ sqoop import \
--connect jdbc:mysql://localhost/loudacre \
--username training --password training \
--fields-terminated-by '\t' \
--table device \
--hive-import
导入完成后需要执行以下命令更新Impala metadata缓存:
impala-shell> INVALIDATE METADATA;使用avro格式导入MySQL中loudacre数据库中表accounts的数据:(使用这一句代码会自动在当前目录生成几个文件,包括表结构文件)
先创建并进入目录:
$ mkdir -p /files/sqoop_avro
$ cd /files/sqoop_avro执行以avro格式导入:
$ sqoop import \
--connect jdbc:mysql://localhost/loudacre \
--username training --password training \
--table accounts \
--target-dir /loudacre/accounts_avro \
--null-non-string '\\N' \
--as-avrodatafile生成的文件(需要保证生成的文件后缀为.avsc才能在后面建表命令中使用):
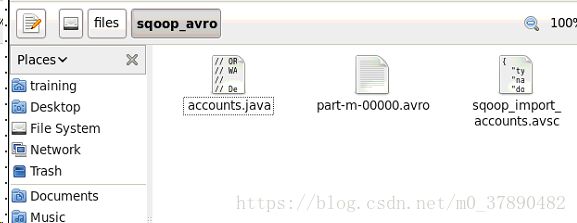
将HDFS /loudacre/accounts_avro/part-m-00000.avro中的文件下载到本地目录:
$ hdfs dfs -get /loudacre/accounts_avro/part-m-00000.avro将avro文件转化为json并在控制台输出(一般来说不需要后面的more,用more是为了查看方便),而且这里只能控制台输出,还没找到能够输出到文件的方法。
$ avro-tools tojson part-m-00000.avro | more将之前用avro格式导入HDFS的同时生成自动生成的schema文件(sqoop_import_accounts_avsc)放到HDFS中:
$ hdfs dfs -put sqoop_import_accounts.avsc /loudacre/在Impala或者Hive中使用之前生成的、已放入HDFS的文件来创建AVRO表:
CREATE EXTERNAL TABLE accounts_avro
STORED AS AVRO
LOCATION '/loudacre/accounts_avro'
TBLPROPERTIES ('avro.schema.url'=
'hdfs:/loudacre/sqoop_import_accounts.avsc ')根据已有的accounts_avro创建parquet格式表(hive中加external会报错,使用时可以去掉external):
create external table accounts_parquet stored as parquet
location '/loudacre/accounts_parquet/' as select * from accounts_avro;