GitHub
作业链接
结对博客 031602334
- 具体分工
- PSP表格
- 代码规范
- 解题思路与设计说明
- 爬虫使用
- 代码组织与内部实现设计(类图)
- 算法关键
- 实现方法
- 流程图
- 附加题
- 设计说明
- 实现思路
- 实现成果展示
- 关键代码
- 性能分析
- 单元测试
- GitHub签入记录
- 遇到的困难
- 学习进度条
- 感想
- 参考链接
具体分工
许郁杨:WordCount代码、文档编写;
温伊倩:爬虫、附加功能设计和实现、部分文档编写.
我们首先详细阅读了作业要求,明确了各部分功能、实现方式和细节,以及所需的附加功能。
确定好需求和设计细节后,我们开始准备实现各自负责的部分,学习和测试需要使用到的技术。接着便是逐步完成各个功能,进行性能分析和单元测试,并编写博客。
在WordCount部分,我主要是作为“驾驶员”(Driver),而队友主要作为“领航员”(Navigator);
在爬虫和附加功能部分,我主要是作为“领航员”(Navigator),而队友主要作为“驾驶员”(Driver)。
这样分工使得两人工作量较为均等,并且各自都能完成较为擅长的部分,保证了最后的质量。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 57 |
| · Estimate | · 估计这个任务需要多少时间 | 45 | 57 |
| Development | 开发 | 890 | 1015 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 214 |
| · Design Spec | · 生成设计文档 | 30 | 32 |
| · Design Review | · 设计复审 | 20 | 9 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 30 | 34 |
| · Coding | · 具体编码 | 400 | 518 |
| · Code Review | · 代码复审 | 50 | 41 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 150 | 162 |
| Reporting | 报告 | 70 | 47 |
| · Test Report | · 测试报告 | 20 | 12 |
| · Size Measurement | · 计算工作量 | 20 | 11 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 24 |
| 合计 | 1005 | 1119 |
代码规范
代码规范我们用的是实验室的代码规范:阿里巴巴的码出高效,并加上了一些补充。
解题思路与设计说明
- 爬虫使用
- 代码组织与内部实现设计(类图)
- 算法关键
- 实现方法
- 流程图
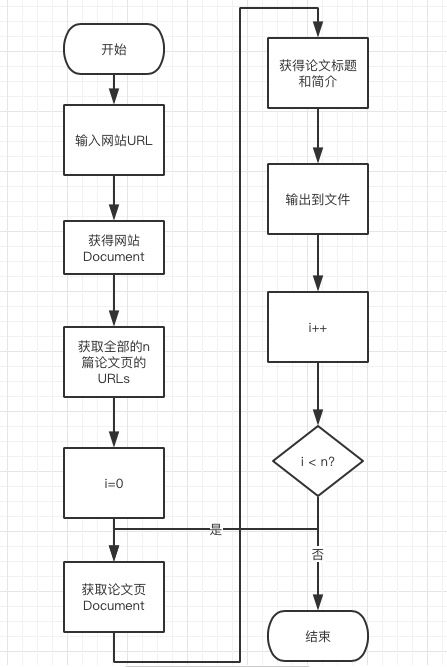
爬虫使用
- 介绍
爬虫是用java的一款HTML解析器——Jsoup来实现的。
首先用Jsoup.connect(String url)抓取url,得到网站的HTML文件文档,根据代码发现各论文页面的地址放置于ptitle类a元素的href属性中,使用Element类得到论文页面的超链接后,再循环得到各论文页面的文档,使用Element类找到papertitle和abstract,将其文本存于字符串中输出到文件中。
- 流程图
- 主要代码
//从URL加载Document
Document doc = Jsoup.connect(URL)
// 取消获取相应内容大小限制
.maxBodySize(0)
//设置超时时间
.timeout(600000)
.get();
//ptitle类
Elements paper = doc.select("[class=ptitle]");
//ptitle类中带有href属性的a元素
Elements links = paper.select("a[href]");
//论文计数
long count = 0;
for(Element link : links) {
//论文页url
String url = link.absUrl("href");
Document paperDoc = Jsoup.connect(url)
.maxBodySize(0)
.timeout(600000)
.get();
//获取论文标题
Elements paperTitle = paperDoc.select("[id=papertitle]");
String title = paperTitle.text();
//获取论文简介
Elements paperAbstract = paperDoc.select("[id=abstract]");
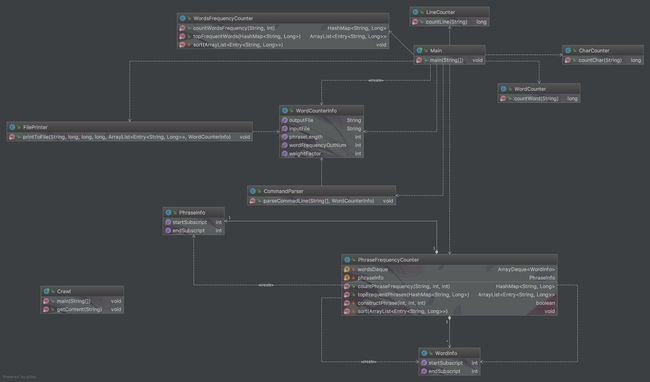
String abstracts = paperAbstract.text();代码组织与内部实现设计(类图)
算法关键
- 实现方法
- 流程图
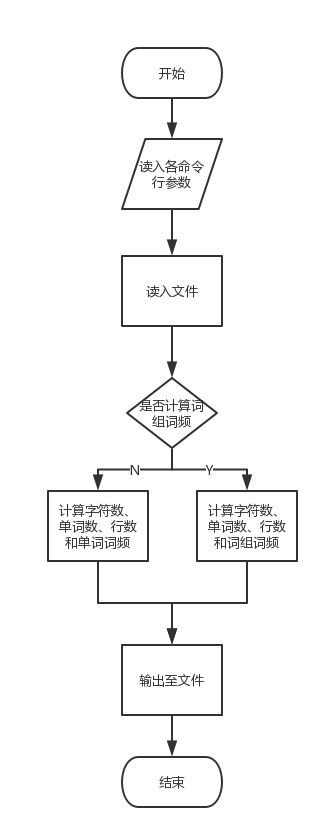
实现方法
这次基本要求里相对上次新增加的功能主要有以下几点:
- 可传入多参数;
- 可指定输入输出文件;
- 词频统计权重开关;
- 可指定词频统计输出个数;
- 可统计词组词频,并可指定词组长度;
- 可切换单词词频和词组词频;
其中实现的关键点在于多参数和词组词频统计。
对于多参数,我的实现方式是使用Apache的commons-cli包,并增设JavaBean "WordCounterInfo"。
通过commons-cli中的PosixParser解析原始命令行数据,然后把解析得到的数据存入Bean。
其中,Bean所包含的参数有:
private String inputFile = "input.txt";
private String outputFile = "output.txt";
private int weightFactor = 1;
private int phraseLength = -1;
private int wordFrequencyOutNum = 10;对于词组词频统计,我的实现方式通过自动机扫描文本,判断得到单词,并记录下该单词的首尾下标,存入队列。然后判断队列长度,每当长度满足要求时,分别取出头尾两个单词的首下标、尾下标,这样就能定位出一整个词组。同时,在自动机判断过程中,每当在单词与单词的间隔中出现不属于分隔符的字母符号时,就清空队列,避免出现不合法的词组。
流程图
附加题
- 设计说明
- 实现思路
- 实现成果展示
设计的创意独到之处
1.从网站爬取了论文作者、pdf链接的额外信息.内容txt文件
2.分析了论文列表中第一作者与第二作者之间的合作关系,并根据关系生成了关系图谱。
实现思路
1.实现方法如同爬虫使用。
2.由爬取的论文作者中提取第一作者与第二作者,用Java将之写入到Excel表格中,再使用NodeXL生成关系图表,对生成图进行筛选,可以得到合作数较多的作者。
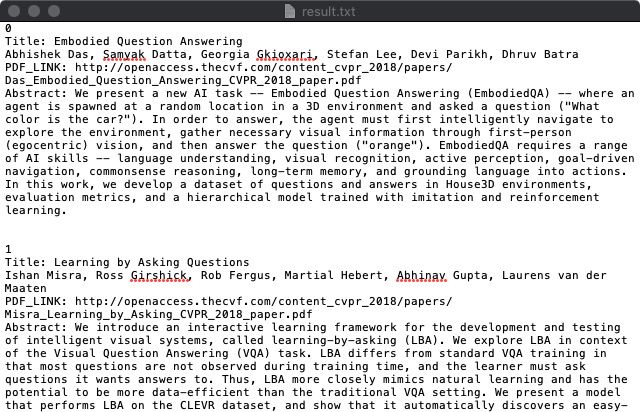
实现成果展示
1.爬取信息图
2.全部作者关系图

筛选掉近发表过一次的作者
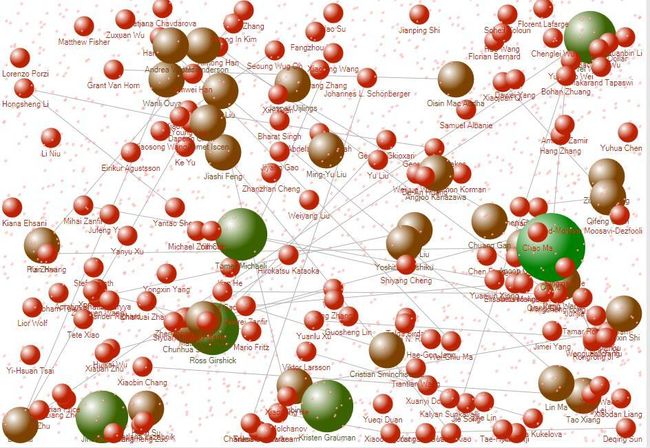
细节图(单节点说明此作者的度>=2,但队友都被滤掉了):

身为第一第二作者且和人合作次数最多的作者

关键代码
这里贴出多参数解析和词组词频统计两个关键部分的代码,并做更详尽的分析解释。
对于多参数解析,我首先添加各项参数及其对应解释,如对于参数i,其意义为"input",后跟数据——输入文件的文件名,具体描述为"input file path."。
然后创建Posix形式的解析器,并解析命令行。接着逐项处理参数,对于i、o、w三个必有参数,直接取值并存入Bean中;对于其他可选参数,逐项判断。
/**
* 解析命令行
*
* @param args 命令行参数
* @param wordCounterInfo 计数器的Bean
*/
public static void parseCommadLine(String[] args, WordCounterInfo wordCounterInfo) {
Options options = new Options();
options.addOption("i", "input", true, "input file path.");
options.addOption("o", "output", true, "result file path.");
options.addOption("w", "weight", true, "set weight factor.");
options.addOption("m", "length", true, "phrase length.");
options.addOption("n", "number", true, "word frequency output number.");
options.addOption("h", "help", false, "print options' information");
CommandLineParser parser = new PosixParser();
try {
CommandLine commandLine = parser.parse(options, args);
if (commandLine.hasOption("h")) {
HelpFormatter helpFormatter = new HelpFormatter();
helpFormatter.printHelp("Options", options);
} else {
wordCounterInfo.setInputFile(commandLine.getOptionValue("i"));
wordCounterInfo.setOutputFile(commandLine.getOptionValue("o"));
wordCounterInfo.setWeightFactor(Integer.parseInt(commandLine.getOptionValue("w")));
if (commandLine.hasOption("m")) {
wordCounterInfo.setPhraseLength(Integer.parseInt(commandLine.getOptionValue("m")));
}
if (commandLine.hasOption("n")) {
wordCounterInfo.setWordFrequencyOutNum(Integer.parseInt(commandLine.getOptionValue("n")));
}
}
} catch (ParseException e) {
System.out.println("Arguments format wrong.");
e.printStackTrace();
}
}对于词组词频统计,基本逻辑与之前处理单词词频时相近。首先读入文本,然后判断是否为Title或Abstract,对这两个部分的文本区分处理。
通过自动机扫描单词,并记录下单词的首尾下标。每扫描出一个单词,就去构造词组,将新得到的单词压入队列尾部。自动机扫描过程中,如果出现一个合法单词后跟着一个非法单词的情况,就清空队列(此时那个合法单词不能在后续过程中组成合法词组)。如果队列长度满足要求,就记录下词组的首尾下标,并推出头元素。然后根据下标取出词组,存入Map。如果有权重要求,就对Title部分的词组增加权重值。最后对得到的Map排序,就得到了所需的词频排序列表。
/**
* 读取并计算Title和Abstract词组词频.
*
* @param fileName 文件名
* @param weightFactor 权重参数
* @param phraseLength 词组长度
* @return 各词组词频
*/
public static HashMap countPhraseFrequency(String fileName, int weightFactor, int phraseLength) {
InputStreamReader inputStreamReader = null;
BufferedReader bufferedReader = null;
String in = "";
char temp;
int state = 0;
int startSubscript = 0;
int endSubscript = 0;
HashMap phraseMap = new HashMap(100 * 1024 * 1024);
//读入文件
try {
inputStreamReader = new InputStreamReader(new FileInputStream(fileName));
} catch (FileNotFoundException e) {
System.out.println("PhraseFrequencyCounter找不到此文件");
e.printStackTrace();
}
if (inputStreamReader != null) {
bufferedReader = new BufferedReader(inputStreamReader);
}
//计算单词词频
try {
while ((in = bufferedReader.readLine()) != null) {
if (in.contains("Title: ")) {
wordsDeque.clear();
int length = in.length();
state = 0;
for (int i = 7; i < length; i++) {
temp = in.charAt(i);
//大写字母转为小写字母
if ((temp >= 65) && (temp <= 90)) {
temp += 32;
}
//自动机状态转移
switch (state) {
case 0: {
if ((temp >= 97) && (temp <= 122)) {
startSubscript = i;
state = 1;
}
break;
}
case 1: {
if ((temp >= 97) && (temp <= 122)) {
state = 2;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 2: {
if ((temp >= 97) && (temp <= 122)) {
state = 3;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 3: {
if ((temp >= 97) && (temp <= 122)) {
endSubscript = i;
state = 4;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 4: {
if (((temp >= 97) && (temp <= 122)) || ((temp >= '0') && (temp <= '9'))) {
endSubscript = i;
} else {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (weightFactor == 1) {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 10L);
} else {
phraseMap.put(phrase.toString(), 10L);
}
} else {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
}
state = 0;
}
break;
}
}
}
if (state == 4) {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (weightFactor == 1) {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 10L);
} else {
phraseMap.put(phrase.toString(), 10L);
}
} else {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
}
}
} else {
if (in.contains("Abstract: ")) {
wordsDeque.clear();
int length = in.length();
state = 0;
for (int i = 10; i < length; i++) {
temp = in.charAt(i);
//大写字母转为小写字母
if ((temp >= 65) && (temp <= 90)) {
temp += 32;
}
//自动机状态转移
switch (state) {
case 0: {
if ((temp >= 97) && (temp <= 122)) {
startSubscript = i;
state = 1;
}
break;
}
case 1: {
if ((temp >= 97) && (temp <= 122)) {
state = 2;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 2: {
if ((temp >= 97) && (temp <= 122)) {
state = 3;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 3: {
if ((temp >= 97) && (temp <= 122)) {
endSubscript = i;
state = 4;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 4: {
if (((temp >= 97) && (temp <= 122)) || ((temp >= '0') && (temp <= '9'))) {
endSubscript = i;
} else {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
state = 0;
}
break;
}
}
}
if (state == 4) {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return phraseMap;
}
/**
* 构造词组
*
* @param startSubscript 单词首下标
* @param endSubscript 单词尾下标
* @param phraseLength 词组长度
* @return 当前是否构造出合法词组
*/
private static boolean constructPhrase(int startSubscript, int endSubscript, int phraseLength) {
WordInfo wordInfo = new WordInfo();
wordInfo.setStartSubscript(startSubscript);
wordInfo.setEndSubscript(endSubscript);
wordsDeque.addLast(wordInfo);
if (wordsDeque.size() == phraseLength) {
phraseInfo.setStartSubscript(wordsDeque.getFirst().getStartSubscript());
phraseInfo.setEndSubscript(wordsDeque.getLast().getEndSubscript());
wordsDeque.removeFirst();
return true;
}
return false;
} 性能分析
下面是命令行参数为"-i result.txt -o output.txt -w 1 -n 20"的性能分析情况。


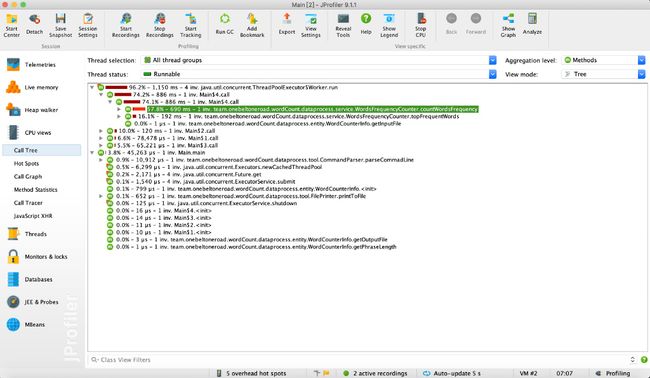
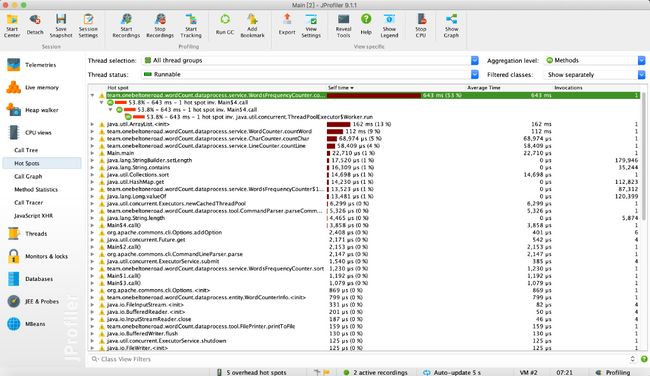
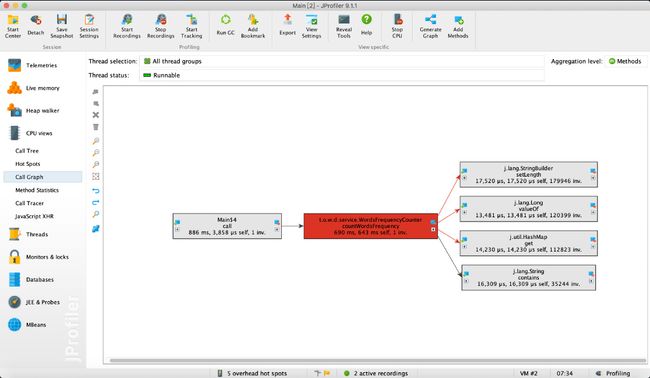
下面是命令行参数为"-i result.txt -o output.txt -w 1 -n 20 -m 3"的性能分析情况。

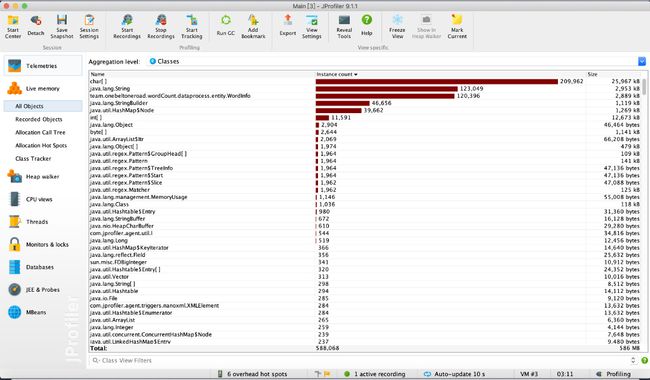

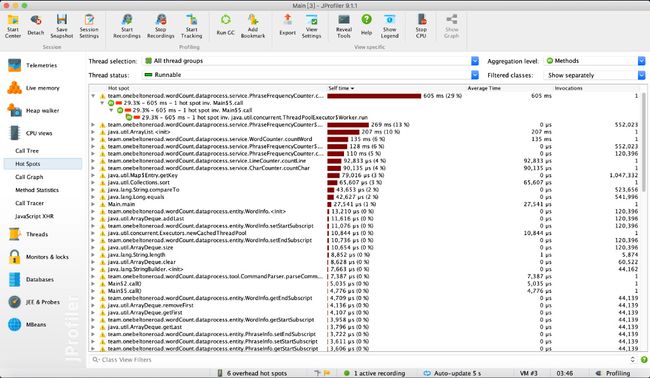
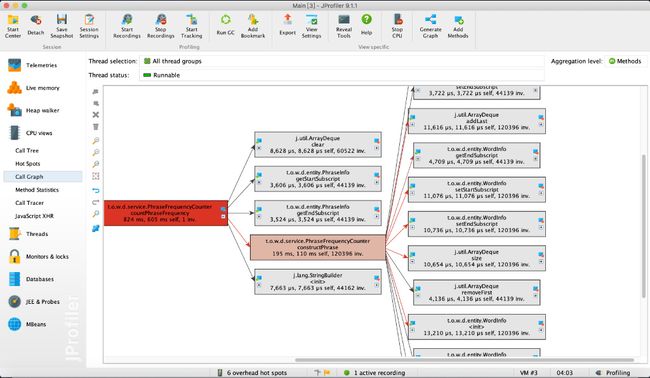
可以看出消耗最高的为单词和词组的词频统计部分。
/**
* 读取并计算Title和Abstract词频.
*
* @param fileName 文件名
* @param weightFactor 权重参数
* @return 各单词词频
*/
public static HashMap countWordsFrequency(String fileName, int weightFactor) {
InputStreamReader inputStreamReader = null;
BufferedReader bufferedReader = null;
String in = "";
char temp;
int state = 0;
StringBuilder word = new StringBuilder();
HashMap wordMap = new HashMap(100 * 1024 * 1024);
//读入文件
try {
inputStreamReader = new InputStreamReader(new FileInputStream(fileName));
} catch (FileNotFoundException e) {
System.out.println("WordsFrequencyCounter找不到此文件");
e.printStackTrace();
}
if (inputStreamReader != null) {
bufferedReader = new BufferedReader(inputStreamReader);
}
//计算单词词频
try {
while ((in = bufferedReader.readLine()) != null) {
if (in.contains("Title: ")) {
word.setLength(0);
int length = in.length();
state = 0;
for (int i = 7; i < length; i++) {
temp = in.charAt(i);
//大写字母转为小写字母
if ((temp >= 65) && (temp <= 90)) {
temp += 32;
}
//自动机状态转移
switch (state) {
case 0: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 1;
}
break;
}
case 1: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 2;
} else {
word.setLength(0);
state = 0;
}
break;
}
case 2: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 3;
} else {
word.setLength(0);
state = 0;
}
break;
}
case 3: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 4;
} else {
word.setLength(0);
state = 0;
}
break;
}
case 4: {
if (((temp >= 97) && (temp <= 122)) || ((temp >= '0') && (temp <= '9'))) {
word.append(temp);
} else {
if (weightFactor == 1) {
if (wordMap.containsKey(word.toString())) {
wordMap.put(word.toString(), wordMap.get(word.toString()) + 10L);
} else {
wordMap.put(word.toString(), 10L);
}
} else {
if (wordMap.containsKey(word.toString())) {
wordMap.put(word.toString(), wordMap.get(word.toString()) + 1L);
} else {
wordMap.put(word.toString(), 1L);
}
}
word.setLength(0);
state = 0;
}
break;
}
}
}
if (state == 4) {
if (weightFactor == 1) {
if (wordMap.containsKey(word.toString())) {
wordMap.put(word.toString(), wordMap.get(word.toString()) + 10L);
} else {
wordMap.put(word.toString(), 10L);
}
} else {
if (wordMap.containsKey(word.toString())) {
wordMap.put(word.toString(), wordMap.get(word.toString()) + 1L);
} else {
wordMap.put(word.toString(), 1L);
}
}
}
} else {
if (in.contains("Abstract: ")) {
word.setLength(0);
int length = in.length();
state = 0;
for (int i = 10; i < length; i++) {
temp = in.charAt(i);
//大写字母转为小写字母
if ((temp >= 65) && (temp <= 90)) {
temp += 32;
}
//自动机状态转移
switch (state) {
case 0: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 1;
}
break;
}
case 1: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 2;
} else {
word.setLength(0);
state = 0;
}
break;
}
case 2: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 3;
} else {
word.setLength(0);
state = 0;
}
break;
}
case 3: {
if ((temp >= 97) && (temp <= 122)) {
word.append(temp);
state = 4;
} else {
word.setLength(0);
state = 0;
}
break;
}
case 4: {
if (((temp >= 97) && (temp <= 122)) || ((temp >= '0') && (temp <= '9'))) {
word.append(temp);
} else {
if (wordMap.containsKey(word.toString())) {
wordMap.put(word.toString(), wordMap.get(word.toString()) + 1L);
} else {
wordMap.put(word.toString(), 1L);
}
word.setLength(0);
state = 0;
}
break;
}
}
}
if (state == 4) {
if (wordMap.containsKey(word.toString())) {
wordMap.put(word.toString(), wordMap.get(word.toString()) + 1L);
} else {
wordMap.put(word.toString(), 1L);
}
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return wordMap;
}
/**
* 读取并计算Title和Abstract词组词频.
*
* @param fileName 文件名
* @param weightFactor 权重参数
* @param phraseLength 词组长度
* @return 各词组词频
*/
public static HashMap countPhraseFrequency(String fileName, int weightFactor, int phraseLength) {
InputStreamReader inputStreamReader = null;
BufferedReader bufferedReader = null;
String in = "";
char temp;
int state = 0;
int startSubscript = 0;
int endSubscript = 0;
HashMap phraseMap = new HashMap(100 * 1024 * 1024);
//读入文件
try {
inputStreamReader = new InputStreamReader(new FileInputStream(fileName));
} catch (FileNotFoundException e) {
System.out.println("PhraseFrequencyCounter找不到此文件");
e.printStackTrace();
}
if (inputStreamReader != null) {
bufferedReader = new BufferedReader(inputStreamReader);
}
//计算单词词频
try {
while ((in = bufferedReader.readLine()) != null) {
if (in.contains("Title: ")) {
wordsDeque.clear();
int length = in.length();
state = 0;
for (int i = 7; i < length; i++) {
temp = in.charAt(i);
//大写字母转为小写字母
if ((temp >= 65) && (temp <= 90)) {
temp += 32;
}
//自动机状态转移
switch (state) {
case 0: {
if ((temp >= 97) && (temp <= 122)) {
startSubscript = i;
state = 1;
}
break;
}
case 1: {
if ((temp >= 97) && (temp <= 122)) {
state = 2;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 2: {
if ((temp >= 97) && (temp <= 122)) {
state = 3;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 3: {
if ((temp >= 97) && (temp <= 122)) {
endSubscript = i;
state = 4;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 4: {
if (((temp >= 97) && (temp <= 122)) || ((temp >= '0') && (temp <= '9'))) {
endSubscript = i;
} else {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (weightFactor == 1) {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 10L);
} else {
phraseMap.put(phrase.toString(), 10L);
}
} else {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
}
state = 0;
}
break;
}
}
}
if (state == 4) {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (weightFactor == 1) {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 10L);
} else {
phraseMap.put(phrase.toString(), 10L);
}
} else {
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
}
}
} else {
if (in.contains("Abstract: ")) {
wordsDeque.clear();
int length = in.length();
state = 0;
for (int i = 10; i < length; i++) {
temp = in.charAt(i);
//大写字母转为小写字母
if ((temp >= 65) && (temp <= 90)) {
temp += 32;
}
//自动机状态转移
switch (state) {
case 0: {
if ((temp >= 97) && (temp <= 122)) {
startSubscript = i;
state = 1;
}
break;
}
case 1: {
if ((temp >= 97) && (temp <= 122)) {
state = 2;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 2: {
if ((temp >= 97) && (temp <= 122)) {
state = 3;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 3: {
if ((temp >= 97) && (temp <= 122)) {
endSubscript = i;
state = 4;
} else {
wordsDeque.clear();
state = 0;
}
break;
}
case 4: {
if (((temp >= 97) && (temp <= 122)) || ((temp >= '0') && (temp <= '9'))) {
endSubscript = i;
} else {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
state = 0;
}
break;
}
}
}
if (state == 4) {
if (constructPhrase(startSubscript, endSubscript, phraseLength)) {
StringBuilder phrase = new StringBuilder();
int start = phraseInfo.getStartSubscript();
int end = phraseInfo.getEndSubscript();
char tempc;
for (int j = start; j <= end; j++) {
tempc = in.charAt(j);
if ((tempc >= 65) && (tempc <= 90)) {
tempc += 32;
}
phrase.append(tempc);
}
if (phraseMap.containsKey(phrase.toString())) {
phraseMap.put(phrase.toString(), phraseMap.get(phrase.toString()) + 1L);
} else {
phraseMap.put(phrase.toString(), 1L);
}
}
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return phraseMap;
} 对于词组词频统计部分,我们一开始的想法是通过双重循环,对每个单词都去判断是否能以其为首组成词组。维护一个词组的字符串,当符合长度时便存入Map。这种做法虽然简单,但加上中间操作后的时间消耗比较大。所以经过试验,对其进行了改进,改为记录首尾下标,这样减少时间消耗,也能保存下单词间的分隔符。
单元测试
单元测试框架用的是JUnit4。
我总共设计了十二个单元测试,其中Main一个,三个字词计数部分各三个,单词词频计数部分一个,词组词频计数部分一个。
| 单元测试 | 测试项 | 被测试代码 |
|---|---|---|
| CharCounterTest | 分别测试普通字符、无标题无摘要和空格 | CharCounter.java |
| WordCounterTest | 分别测试普通单词、无标题无摘要和大小写单词 | WordCounter.java |
| LineCounterTest | 分别测试普通行、无标题无摘要和混合行 | LineCounter.java |
| WordFrequencyCounterTest | 测试混合单词 | WordFrequencyCounter.java |
| PhraseFrequencyCounterTest | 测试混合词组 | PhraseFrequencyCounter.java |
| MainTest | 测试空白文件 | Main.java |
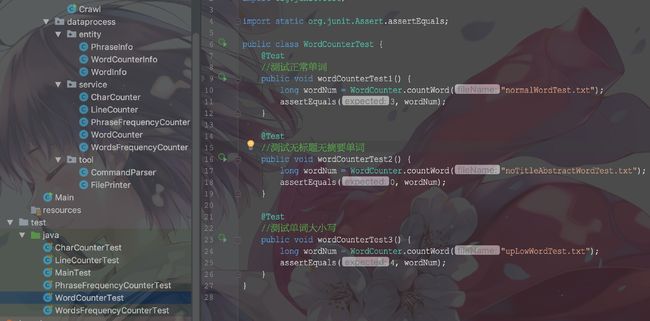
部分测试代码
import com.eventide.wordCount.dataprocess.service.WordCounter;
import org.junit.Test;
import static org.junit.Assert.assertEquals;
public class WordCounterTest {
@Test
//测试正常单词
public void wordCounterTest1() {
long wordNum = WordCounter.countWord("normalWordTest.txt");
assertEquals(3, wordNum);
}
@Test
//测试无标题无摘要单词
public void wordCounterTest2() {
long wordNum = WordCounter.countWord("noTitleAbstractWordTest.txt");
assertEquals(0, wordNum);
}
@Test
//测试单词大小写
public void wordCounterTest3() {
long wordNum = WordCounter.countWord("upLowWordTest.txt");
assertEquals(4, wordNum);
}
}
GitHub签入记录
遇到的困难
对于词组词频统计部分,我们总共尝试了三种方法。
一种是上文提到的,通过双重循环,对每个单词都去判断是否能以其为首组成词组。维护一个词组的字符串,当符合长度时便存入Map。这种做法虽然简单,但加上中间操作后的时间消耗比较大。
第二种是维护一个队列,每当有合法单词出现时就压入队列中。如果队列长度符合要求,就取出队列中保存的单词,拼接成词组,压入Map。这种方法虽然简单快捷,但在看到群里说到,不同分隔符算不同词组时就凉了。。如果要记入分隔符就需要将分隔符一起存下来。虽然可以将合法单词和其后的分隔符一起保存,但这种方法在实现上存在一些困难,在拼接成词组时还要对单词进行二次处理,因此我们觉得并不是合适的处理方式。
经过试验,我们使用了记录首尾下标的方式。创建一个JavaBean存下每个合法单词的首尾下标,通过下标组成队列,进而拼装出词组。这样做效率不错,处理过程也不复杂,因此我们认为是较为合适的方法。
我们还遇到了一个重大困难,就是国庆假期前两个人接连感冒发烧(都怪优秀的舍友),一直到现在也还没完全好。。我想解决方法,应该只有穿越时空解决掉舍友了吧。(肥宅怎么可能去锻炼身体.jpg
感想
我的优秀的队友,擅长Python,爬虫部分高效完成,并且高效改写为Java,然后还高效地搞定了附加题。学习能力强,带病工作效率还恐怖如斯,让生病了就不想干活的我惭愧不已_ (:△」∠) _。
需要改进的地方就是有时候比较粗心,比如文件丢了之类的。。虽然有时候是软件的问题吧。
不过这次真是疲倦作业呀。。。
参考链接
Java 容器源码分析之 Deque 与 ArrayDeque
commons-cli使用介绍