基于spark ALS协同过滤推荐系统代码实现
基于spark ALS协同过滤推荐系统代码实现
本文是基于spark的Mlib包的ALS搭建的协同过滤推荐系统,调用ALS,封装了特征向量提取过程。本系统纯后台,不涉及前端页面数据展示
推荐系统简介
推荐系统主要分为收数据收集,ETL,构建特征,构建模型,推荐结果
数据收集
数据收集
构建特征
数据源1
原始数据
数据源2
特征
构建模型
模 型
结果
- 数据收集: 数据来源主要分为;数据库,用户行为日志,服务端日志
- ETL
:E(Extract)数据库表中的数据可以通过数据库快照处理,对于实施性要求比较高的数据可以通过消息队列抽取;用户行为数据和服务端日志可以通过在客户端埋点的方式获取日志,日志信息可以通过flume等中间件读取,后面的数据根据业务需求分为离线数据和实时数据,离线数据进入数仓,实时数据通过kafka等消息队列供后面实时程序(spark streaming))处理;
:T(Tranform)将提取到的数据进行数据清洗,格式转化,缺失值填补,数据校验等方式得到能被系统处理的数据
:L(load)加载数据,离线数据加载到数仓(hive等),属性等数据存放结构化数据库 - 构建特征 特征可以简单理解为一个对象属性。特征工程分为特征选择,特征表达,特征评估几个阶段。特征构建在推荐系统中占有很重要的位置,一个好的推荐系统必然是基于优秀的特征工程。特征可分为离散特征,连续特征,时空特征,文本特征等。相应的特征构建方式有离散特征构建,连续特征构建,时空特征构建等。
- 构建模型 用户模型构建主要分为召回和排序两个阶段。召回是将用户可能感兴趣的物品,电影,视频等从全量标的中提取,召回分为以下几种:1.基于属性的标签召回,2协同过滤召回(这是目前主流的召回方式,本文代码实现也是基于这种模型实现);3.热门召回(微博和百度热搜都基于此),这是最容易实现的方式。在系统搭建冷启动初期,主要采用属性召回和热门召回
- 推荐结果 将推荐结果通过客户端返回给用户
推荐算法
不同模型构建方式对应不同的推荐算法,在产品不同阶段,构建模型方式不同,推荐算法也会相应的迭代升级,在项目初期阶段,数据量有限,构建模型的方式有热门召回和标签召回,采用的算法也主要是通过热门榜单和基于用户注册的属性提供相应的内容。随着系统积累的数据量足够,会采用协同过滤(比如淘宝)和社交关系(微信)做推荐
特征工程简介
特征选择: 特征选择可以分为基于统计量选择和基于模型选择
特征表达: 特征表达的任务就是要将一个个的样本抽象成数值向量,供机器学习模型使用例如:我是码农和我是高级码农,通过分词可以分为:我,是,码农,高级。将上面数字抽象成0和1,存在为1,不存在未0,那么这两句话可以分别抽象为(1,1,1,0),(1,1,1,1)
**特征评估:**对已经生成的特征的整体评估,发生在特征选择和特征编码之后
协同过滤
协同过滤原理网上 可以找到很多文章,这里不再赘述,本文下面主要展示代码实现,可参考文章《协同过滤推荐算法》
基于协同过滤算法推荐系统搭建
架构图
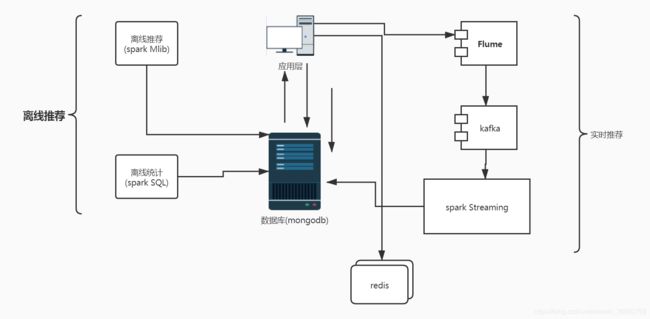
系统环境
- 虚拟机环境:CentOS-7-x86_64-DVD-1511.iso

- 后台安装包
相关工具包的安装和使用本文不做赘述

- 开发工具idea
代码
前端部分代码和调度不做展示,数据源来源于随机生产,不对数据的实用性做校验,只是通过代码搭建简单的推荐系统,仅供参考学习
离线统计
代码片.
package com.geyuegui
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* Created by root on 2019/9/19.
*
* 离线统计入口程序
*
* 数据流程:
* spark 读取MongoDB中数据,离线统计后,将统计结果写入MongoDB
*
* (1)评分最多电影
*
* 获取所有评分历史数据,计算评分次数,统计每个电影评分次数 ---> RateMoreMovies
*
* (2)近期热门电影
*
* 按照月统计,这个月中评分最多的电影,我们认为是热门电影,统计每个月中每个电影的评分数量 --> RateMoreRecentlyMovie
*
* (3)电影平均分
*
* 把每个电影,所有用户评分进行平均,计算出每个电影的平均评分 --> AverageMovies
*
* (4)统计出每种类别电影Top10
*
* 将每种类别的电影中,评分最高的10个电影计算出来 --> GenresTopMovies
*
*/
object statisticApp extends App {
val RATING="Rating"
val MOVIE="Movie"
var params =Map[String,Any]()
params += "sparkCores"->"local[2]"
params +="mongo.uri"->"mongodb://ip:27017/recom"
params +="mongo.db"->"recom"
//sparkSession创建
val sparkConfig=new SparkConf().setAppName("statisticApp").setMaster(params("sparkCores").asInstanceOf[String])
val sparkSession =SparkSession.builder().config(sparkConfig).getOrCreate()
//创建mongodb对象,这个对象使用隐士的方法转化
implicit val mongoConfig =MongoConfig(params("mongo.uri").asInstanceOf[String],params("mongo.db").asInstanceOf[String])
//加载需要用到的数据
import sparkSession.implicits._
val ratingsDF=sparkSession.read
.option("uri",mongoConfig.uri)
.option("collection",RATING)
.format("com.mongodb.spark.sql")
.load()
.as[Rating].cache()
ratingsDF.createOrReplaceTempView("ratings")
val movieDF=sparkSession.read
.option("uri",mongoConfig.uri)
.option("collection",MOVIE)
.format("com.mongodb.spark.sql")
.load()
.as[Movie].cache()
//ratingsDF.createOrReplaceTempView("ratings")
//1
statisticAlgorithm.genreTopTen(sparkSession)(movieDF)
}
//另外一个包
package com.geyuegui
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.spark.sql.{
Dataset, SparkSession}
object statisticAlgorithm {
val RATINGSCORE="ratingScore"
val AVGSCORE="avgScore"
val GENRETOPTEN="GenretopTen"
val POPULARMOVIE="popularMovie"
//计算评分最多的电影
def scoreMost(sparkSession: SparkSession)(implicit mongoConfig: MongoConfig):Unit={
val ratingScoreDF =sparkSession.sql("select mid,count(1) as count from ratings group by mid order by count desc")
ratingScoreDF.write
.option("uri",mongoConfig.uri)
.option("collection",RATINGSCORE)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
//近期热门电影
def popularMovie(sparkSession: SparkSession)(implicit mongoConfig: MongoConfig):Unit={
//定义日期函数
val simpleDateFormat = new SimpleDateFormat("yyyyMM")
val changTempToDate=sparkSession.udf.register("changTempToDate",(x:Long)=>simpleDateFormat.format(new Date(x*1000L)))
val popularMovieyDFtemp=sparkSession.sql("select uid,mid,score,changTempToDate(timestamp) as ym from ratings")
popularMovieyDFtemp.createOrReplaceTempView("ratingtemp")
val popularDF =sparkSession.sql("select mid,avg(score) as avgscore,ym from ratingtemp group by mid,ym order by avgscore desc")
popularDF.write
.option("uri",mongoConfig.uri)
.option("collection",POPULARMOVIE)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
//统计每种类别中的前10的电影
def genreTopTen(sparkSession: SparkSession)(movie: Dataset[Movie])(implicit mongoConfig: MongoConfig):Unit={
//将类别转化为RDD
val geners=List("Action","Adventure","Animation","Comedy","Ccrime","Documentary","Drama","Family","Fantasy","Foreign","History","Horror","Music","Mystery"
,"Romance","Science","Tv","Thriller","War","Western")
val genersRDD =sparkSession.sparkContext.makeRDD(geners)
//电影的平均分
val averageScore =sparkSession.sql("select mid,avg(score) as averageScore from ratings group by mid").cache()
//averageScore.createOrReplaceTempView("averageScore")
//生成电影评分临时表
val movieScoreTempDF=movie.join(averageScore,Seq("mid","mid")).select("mid","averageScore","genres").cache()
import sparkSession.implicits._
//每种电影类别前十
val genresTopTENDF =genersRDD.cartesian(movieScoreTempDF.rdd).filter{
case (genres,row)=>{
row.getAs[String]("genres").toLowerCase().contains(genres.toLowerCase)
}
}.map{
case(genres,row)=>{
(genres,(row.getAs[Int]("mid"),row.getAs[Double]("averageScore")))
}
}.groupByKey()
.map {
case(genres,items)=>{
genreReommender(genres,items.toList.sortWith(_._2>_._2).take(10).map(x=>RecommenderItem(x._1,x._2)))
}
}.toDF()
averageScore.write
.option("uri",mongoConfig.uri)
.option("collection",AVGSCORE)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
genresTopTENDF.write
.option("uri",mongoConfig.uri)
.option("collection",GENRETOPTEN)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
}
离线推荐
:使用ALS构建模型,并构建用户的推荐数据模型和电影的相似数据模型(通过余弦相似计算相似性),将其保存到mongodb中
代码片.
package com.geyuegui
import breeze.numerics.sqrt
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{
ALS, Rating}
import org.apache.spark.sql.SparkSession
import org.jblas.DoubleMatrix
object OfflineRecommender {
val RATINGS="Rating"
val MOVIES="Movie"
val USER_RECMS="UserRecms"
val MOVIE_REMS="MovieRecms"
val MOVIE_RECMS_NUM=10
def main(args: Array[String]): Unit = {
//两个对象,一个是spark对象,用来执行代码,另外一个mongodb对象,用来保存数据
val conf=Map(
"spark.core"->"local[2]",
"mongo.uri"->"mongodb://ip:27017/recom",
"mongo.db"->"recom"
)
val sparkConf=new SparkConf().setAppName("OfflineRecommender").setMaster(conf("spark.core"))
.set("spark.executor.memory","6G")
.set("spark.driver.memory","2G")
val sparkSession=SparkSession.builder().config(sparkConf).getOrCreate()
implicit val mongoConfig=MongoConfig(conf("mongo.uri"),conf("mongo.db"))
import sparkSession.implicits._
/**
* 要生成用户的推荐矩阵,需要评分数据,从评分数据中获取用户信息和评分信息,从电影collection中获取电影信息
*/
//获取评分
val ratingRDD=sparkSession.read
.option("uri",mongoConfig.uri)
.option("collection",RATINGS)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRating]
.rdd
.map(rating=>(rating.uid,rating.mid,rating.score)).cache()
//电影
val movieRDD=sparkSession.read
.option("uri",mongoConfig.uri)
.option("collection",MOVIES)
.format("com.mongodb.spark.sql")
.load()
.as[Movie]
.rdd
.map(_.mid).cache()
//生成用户,电影对象集合
val users=ratingRDD.map(_._1).distinct().cache()
val userMovies=users.cartesian(movieRDD)
/**
* 构建模型,需要的数据transdata,特征值个数,迭代次数,迭代步长
*/
val (range,itrators,lambda)=(50,5,0.01)
val transdatas= ratingRDD.map(x=>Rating(x._1,x._2,x._3))
val models =ALS.train(transdatas,range,itrators,lambda)
//推荐矩阵
val preRatings=models.predict(userMovies)
//获取用户推荐电影,并将其转化为mogodb存储模式
val userRecmsDF=preRatings.filter(_.rating>0)
.map(x=>(x.user,(x.product,x.rating)))
.groupByKey()
.map{
case (uid,recs)
=>UserRecs(uid,recs.toList.sortWith(_._2>_._2).take(MOVIE_RECMS_NUM).map(x=>RecommenderItem(x._1,x._2)))}
.toDF()
//存储到mongodb上
userRecmsDF.write
.option("uri",mongoConfig.uri)
.option("collection",USER_RECMS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
/**
* 通过模型计算电影的相似矩阵
*/
//得到电影的特征矩阵,然后通过余弦相似性计算电影之间的相似性
val movieFeatures=models.productFeatures.map{
case(mid,feature)
=>(mid,new DoubleMatrix(feature))
}
val movieRecmsDF=movieFeatures.cartesian(movieFeatures)
.filter{
case(a,b)=>a._1!=b._1
}.map{
case(a,b)=>(a._1,(b._1,this.consimScore(a._2,b._2)))//(Int,(Int,Double))
}.filter(_._2._2>0.6)
.groupByKey()
.map{
case(mid,consmids)=>
MovieRecs(mid,consmids.toList.map(x=>RecommenderItem(x._1,x._2)))
}.toDF()
movieRecmsDF.write
.option("uri",mongoConfig.uri)
.option("collection",MOVIE_REMS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
sparkSession.close()
}
def consimScore(feature1: DoubleMatrix, feature2: DoubleMatrix): Double = {
(feature1.dot(feature2))/(feature1.norm2()*feature2.norm2())
}
}
实时推荐
- 根据以下公式排序(优先级)

代码片.
package com.geyuegui
import com.mongodb.casbah.commons.MongoDBObject
import kafka.Kafka
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{
ConsumerStrategies, KafkaUtils, LocationStrategies}
import redis.clients.jedis.Jedis
import scala.collection.JavaConversions._
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
/**
* 实时推荐系统
* 1.从kafka消息队列中获取用户当前的电影评分,
* 读取电影的相似性矩阵表,并将其设置为广播变量,然后根据相似矩阵中获取与当前电影相似的电影
* 相似矩阵中的相似电影是历史的数据,作为所有电影的相似参考,但是每个用户的喜好可能不一样,需要根据用户最近的评分数据在这个基础上进一步的分配推荐优先级
* 用户最近的评分数据我们这边从redis缓存中拉去。
* 根据相似电影矩阵中获取的相似电影,用户最近的评分数据,按照公式计算每个电影的推荐优先级,将推荐的电影保存到对应用户的下
*/
object StreamingRecommender {
val MOVIE_RECMS="MovieRecms"
val RATINGMOVIE="Rating"
val STREAMRESMS="StreamRecms"
val REDISNUM=10
val RECOMNUM=10
//环境变量
def main(args: Array[String]): Unit = {
// System.gc();
val config =Map(
"spark.core"->"local[3]",
"mongo.uri"->"mongodb://ip:27017/recom",
"mongo.db"->"recom",
"kafka.topic"->"recom"
)
val sparkConf=new SparkConf().setAppName("StreamingRecommender").setMaster(config("spark.core"))
val sparkSession=SparkSession.builder().config(sparkConf).getOrCreate()
val sparkContext=sparkSession.sparkContext
implicit val mongoConfig=MongoConfig(config("mongo.uri"),config("mongo.db"))
import sparkSession.implicits._
/**
* 设置电影的相似矩阵为广播
*/
val movieRecs=sparkSession.read
.option("uri",mongoConfig.uri)
.option("collection",MOVIE_RECMS)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRecs]
.rdd
.map {
movieRecms =>
(movieRecms.mid,movieRecms.recs.map(x => (x.mid, x.score)).toMap)
}.collectAsMap()
val movieRecsBroadCoast=sparkContext.broadcast(movieRecs)
//广播变量需要使用聚合计算才能生效
val a=sparkContext.makeRDD(1 to 2)
a.map(x=>movieRecsBroadCoast.value.get(1)).count
//获取kafka中的数据
val ssc = new StreamingContext(sparkContext,Seconds(2))
val kafkaParam=Map(
"bootstrap.servers"->"ip:9092",
"key.deserializer"->classOf[StringDeserializer],
"value.deserializer"->classOf[StringDeserializer],
"group.id" -> "recomgroup"
)
val kafkaStreaming=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Array(config("kafka.topic")),kafkaParam))
//接收评分流 UID | MID | Score | TIMESTAMP
//kafka数据:1|2|5.0|1564412033
val ratingStream=kafkaStreaming.map{
case msgs=>
val msg= msgs.value().split("\\|")
println("get data from kafka --- ratingStream ")
(msg(0).toInt,msg(1).toInt,msg(2).toDouble)
}
//计算并更新用户的每次评分的推荐数据,将其保存到mongo
ratingStream.foreachRDD{
data=>
data.map{
case(uid,mid,score)=>
println("get data from kafka --- ratingStreamNext ")
//1.最近评价的电影,从redis中获取
val userRecentMovies=getUserRecentMovie(uid:Int,REDISNUM:Int,ConnerHelper.jedis:Jedis)
//获取d当前电影最相似的几个电影,同时要排除掉用户已经评价电影
val topMovieSimScore=getTopMovieSimScore(uid,mid,RECOMNUM,movieRecsBroadCoast.value)
//给最相似的电影赋优先级并
val topMovieOrder=getTopMovieOrder(topMovieSimScore,userRecentMovies,movieRecsBroadCoast.value)
//将数据保存到mongodb
saveSimMovietoMongo(uid,topMovieOrder)
}.count()
}
ssc.start()
ssc.awaitTermination()
}
/**
*
* @param uid
* @param num
* @param jedis
*/
//lpush uid:1 1129:2.0 1172:4.0 1263:2.0 1287:2.0 1293:2.0 1339:3.5 1343:2.0 1371:2.5
def getUserRecentMovie(uid: Int, num: Int, jedis: Jedis) = {
jedis.lrange("uid:"+uid,0,num).map{
case item =>
val datas=item.split("\\:")
(datas(0).trim.toInt,datas(1).trim.toDouble)
}.toArray
}
def log(num: Int):Double={
math.log(num)/math.log(2)
}
/**
* 获取电影mid最相似的电影,并且去掉用户已经观看的电影
* @param uid
* @param mid
* @param RECOMNUM
* @param simMovieCollections
*/
def getTopMovieSimScore(uid: Int, mid: Int, RECOMNUM: Int, simMovieCollections: collection.Map[Int, Map[Int, Double]])(implicit mongoConfig: MongoConfig) = {
//用户已经观看的电影
val userRatingExist=ConnerHelper.mongoClient(mongoConfig.db)(RATINGMOVIE).find(MongoDBObject("uid"->uid)).toArray.map{
item=>
item.get("mid").toString.toInt
}
userRatingExist
//电影mid所有相似的电影
val allSimMovie=simMovieCollections.get(mid).get.toArray
//过滤掉用户已经观看的电影,对相似电影排序,取RECOMNUM个电影
allSimMovie.filter(x=> !userRatingExist.contains(x._1)).sortWith(_._2>_._2).take(RECOMNUM).map(x=>x._1)
}
/**
*
* @param topMovieSimScores
* @param userRecentMovies
* @param simMovies
* @return
*/
def getTopMovieOrder(topMovieSimScores: Array[Int], userRecentMovies: Array[(Int, Double)], simMovies: collection.Map[Int, Map[Int, Double]]) = {
//存放每个待选电影的权重评分
//这里用Array是便于使用groupBy集合计算
val scores=ArrayBuffer[(Int,Double)]()
//每一个待选电影的增强因子
val incre=mutable.HashMap[Int,Int]()
//每一个待选电影的减弱因子
val decre=mutable.HashMap[Int,Int]()
for (topMovieSimScore<-topMovieSimScores;userRecentMovie<-userRecentMovies){
//相似值
val simScore=getMoviesSimScore(simMovies,userRecentMovie._1,topMovieSimScore)
if (simScore>0.6){
scores +=((topMovieSimScore,simScore*userRecentMovie._2))
if (userRecentMovie._2>3){
incre(topMovieSimScore)=incre.getOrDefault(topMovieSimScore,0)+1
}else{
decre(topMovieSimScore)=decre.getOrDefault(topMovieSimScore,0)+1
}
}
}
scores.groupBy(_._1).map{
case(mid,sim)=>
(mid,sim.map(_._2).sum/sim.length+log(incre(mid))-log(decre(mid)))
}.toArray
}
/**
* 获取电影之间的相似度
* @param simMovies
* @param userRatingMovie
* @param topSimMovie
*/
def getMoviesSimScore(simMovies: collection.Map[Int, Map[Int, Double]],
userRatingMovie: Int,
topSimMovie: Int) = {
simMovies.get(topSimMovie) match {
case Some(sim) => sim.get(userRatingMovie) match {
case Some(score) => score
case None => 0.0
}
case None => 0.0
}
}
/**
*
* @param uid
* @param topMovieOrder
* @param mongoConfig
*/
def saveSimMovietoMongo(uid: Int, topMovieOrder: Array[(Int, Double)])(implicit mongoConfig: MongoConfig): Unit= {
val StreamCollection=ConnerHelper.mongoClient(mongoConfig.db)(STREAMRESMS)
StreamCollection.findAndRemove(MongoDBObject("uid"->uid))
//(Int, Double)(Int, Double)(Int, Double)(Int, Double)(Int, Double)
//Int:Double|Int:Double|Int:Double|Int:Double|Int:Double|Int:Double
StreamCollection.insert(MongoDBObject("uid"->uid,"recms"->topMovieOrder.map(x=>x._1+":"+x._2).mkString("|")))
println("save to momgo success")
}
}
数据说明
- redis获取近期用户评分数据,其中预存测试数据为:uid:1 1129:2.0 1172:4.0 1263:2.0 1287:2.0 1293:2.0 1339:3.5 1343:2.0 1371:2.5
- kafka获取用户实时评分数据,预存数据为:1|2|5.0|1564412033
- 后台系统存储原始数据机构如图
:movie数据展示

:Rating评分数据展示

4.推荐结果
