深入理解Android Handler机制(深入至native层)
文章目录
- 前言
- 前置知识
-
- ThreadLocal
-
- ThreadLocal使用
- ThreadLocal原理
-
- 源码解读
- 总结
- 多路复用IO
- handler工作原理
-
- 概述
- 工作原理
-
- 架构
- 流程
-
- Looper
- handler
-
- 构造
- 消息分发
- 发送消息
- 移除消息
- MessageQueue
-
- 创建MessageQueue
- 循环消息
-
-
- enqueueMessage
-
- native层的handler
-
- 初始化
- 阻塞
- 唤醒
- 其他
-
- handler为什么不会阻塞主线程?
- handler在Android源码中的应用
- 后记
前言
handler作为Android中最重要的内容,需要相对透彻的理解,并非只是了解Handler的使用、handler、looper、messageQueue的原理,而是需要对源码有比较清晰的认知,对重要部分的代码做到完全理解,需要理解到的内容有
- handler的工作方式
- handler为什么不会阻塞主线程?
- 同步消息与异步消息及同步屏障
- handler如何实现延迟消息
- 对阻塞epoll机制理解
- native层handler机制理解
- handler在Android源码中应用
涉及到的前置知识有
- ThreadLocal理解
- 多路复用技术(select/poll/epoll)
前置知识
ThreadLocal
ThreadLocal使用
理解Java中ThreadLocal,可以更好地理解Handler原理。
ThreadLocal是一个线程内部的数据存储类,通过它可以在指定的线程中存储数据,存储后只有在指定线程中获取到存储的数据,其他线程则无法获取到数据。当某些数据是以线程为作用域并且不同线程具有不同的数据副本时,就可以考虑使用ThreadLocal。
private ThreadLocal demoBooleanThreadLocal = new ThreadLocal();
//主线程中赋值
demoBooleanThreadLocal.set(true)
// true
Log.d("main thread"+demoBooleanThreadLocal)
//开新线程赋值打印
new Thread("Thread1"){
@override
public void run(){
demoBooleanThreadLocal.set(false)
//false
Log.d("thread 1"+demoBooleanThreadLocal)
}
}
//开新线程赋值打印
new Thread("Thread2"){
@override
public void run(){
//null
Log.d("thread 1"+demoBooleanThreadLocal)
}
}
我们可以看出,三个线程(mainThread、Thread1、Thread2)可以共享同一个TreadLocal。在主线程中设置为true,那么在主线程中get值为true,在Thread1中set为false,那么在Thread2中get便为false,在Thread2中没有set,那么获取为null。并且ThreadLocal支持泛型
ThreadLocal原理
源码解读
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的map
ThreadLocalMap map = getMap(t);
//没有map则创建,有则set值,注意key是用户刚刚创建的demoBooleanThreadLocal
//也就是说每个线程都有个map,key是threadlocal变量,value是该变量在当前线程的值
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
//getMap()返回当前线程的ThreadLocalMap
//Thread类中存在threadLocals变量
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
//Thread类中的变量定义
ThreadLocal.ThreadLocalMap threadLocals = null;
//但是我们并没有发现Thread类中封装threadLocals的操作方法,转向看ThreadLocal
//中的createMap()方法:这里直接访问并初始化了threadLocals
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
//ThreadLocalMap是ThreadLocal的内部类,来看ThreadLocalMap构造方法
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
//创建Entry数组
table = new Entry[INITIAL_CAPACITY];
//计算出firstKey在数组中位置,具体算法不细看
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//存入位置
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
//由此可见,ThreadLocalMap是一个数组实现的key-value容器
//ThreadLocalMap set方法
private void set(ThreadLocal key, Object value) {
Entry[] tab = table;
int len = tab.length;
//一串代码计算key位置
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
//key位置存入entry
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
//最后再来看下ThreadLocal的get方法
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//拿到当前线程的map(ThreadLocalMap对象)
ThreadLocalMap map = getMap(t);
if (map != null) {
//从ThreadLocalMap中取出值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//如果map为空说明没有set过,返回初始值即可
return setInitialValue();
}
总结
从注释上还是可以很清晰的看出逻辑的,注意一点是,每个Thread中存在一个map,来存放当前线程的数据,key是TreadLocal对象,value是ThreadLocal对象在当前线程调用set设置的值,而这个map并不是Java自带的map,而是TreadLocalMap:ThreadLocal的内部类,一个又数组实现的key-value容器。
我们创建一个ThreadLocal对象:demoLocal,在主线程、线程1、线程2中调用demoLocal.set()方法,分别设置1,2,3.那么在主线程Thread对象的threadLocals中table数组中存在value为1的Entry对象,在线程2Tread对象的threadLocals中table数组中存在value为2的Entry对象,线程3同理。至于该Entry在数组中位置,在各个线程的threadLocals中table应该是一样的。因为都是一个算法算出来的,并且demoLocal对象也是一个。
多路复用IO
我们知道,有五种IO模型,分别为阻塞IO、非阻塞IO、多路复用IO、信号驱动IO以及异步IO。这是五种理论IO模型。多路复用IO在Linux下的实现有三种,分别是slect/poll/epoll,为什么我们要在这里提多路复用IO?因为handler的阻塞正是又epoll实现的。
I/O多路复用(multiplexing)的本质是通过一种机制(系统内核缓冲I/O数据),让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作
文件描述符是Linux中的概念,Linux中的文件、设备都可以用文件描述符来描述,可以理解为某个文件或设备的引用,通过文件描述符可以找到文件,我个人把它简单理解为文件路径
这里我们详细介绍下epoll
Linux下提供的epoll相关函数如下:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
-
epoll_create 函数创建一个epoll句柄,参数size表明内核要监听的描述符数量。调用成功时返回一个epoll句柄描述符,失败时返回-1。
-
epoll_ctl 函数注册要监听的事件类型。四个参数解释如下:
- epfd 表示epoll句柄
- op 表示fd操作类型,有如下3种
- EPOLL_CTL_ADD 注册新的fd到epfd中
- EPOLL_CTL_MOD 修改已注册的fd的监听事件
- EPOLL_CTL_DEL 从epfd中删除一个fd
- fd 是要监听的描述符
- event 表示要监听的事件,事件可以使如下如下几种宏的集合
- EPOLLIN :表示对应的文件描述符可以读
- EPOLLOUT:表示对应的文件描述符可以写
- EPOLLERR:表示对应的文件描述符发生错误;
- epoll_wait
- epfd 表示epoll句柄
- events 表示从内核得到的就绪事件集合,将该数组传入wait,wait返回时,这个数组就塞满了就绪事件
- 告诉内核events的大小,必须小于等于epoll_create时的maxevents
- timeout 表示等待的超时时间,-1则一直阻塞,直到有数据返回
我个人理解,wait返回只返回了就绪的文件描述符数量,而非文件描述符,也就是说我还是要遍历寻找,例如遍历events 看看都有哪些就绪事件,是有读的?还是写的?然后接着去真正调用IO,这个路子也和Java NIO的使用方式是相同的,即:阻塞返回了,说明有就绪事件,然后遍历events,找到自己关注的事件处理。
handler在native层使用到了epoll函数,我们在讲解native层时会用到上述知识。
handler工作原理
概述
其实这部分内容,但凡看过几篇相关文档的人都能背出来:以下描述基于对handler工作方式有一定理解:Lopper不断轮询MessageQueue中的消息,有消息就拿出来分给消息的target,也就是分给handler,handler调用dispatchMessage()处理;也是通过handler调用sendMessage()塞消息给messageQueue,说到这里,可能会有个疑问:为什么要通过Handler塞消息给MessageQueue(),同时handler重写一个handleMessage()方法,在这个方法中处理Looper轮询到的消息,折腾这一圈是干嘛呢?其实就是【基于消息驱动】:
-
在一个线程中,可以创建多个handler,都往跑在这个线程的Looper中塞消息,Looper按照顺序去轮询到消息,进行处理。
-
在线程A中,可以使用线程B中handler,发送消息到线程B,线程B的handler意思是其Looper是在线程B中轮询的。这个handler就像是线程B放出去的口子,谁向往线程B发消息,就通过我来塞。
个人认为这是handler的重要使命:线程间通信
延伸:线程间通信的其他方法
工作原理
架构
Tips:以上论述比较口头话,是基于对handler工作方式有一定理解来论述的,下面我们讲一下工作方式
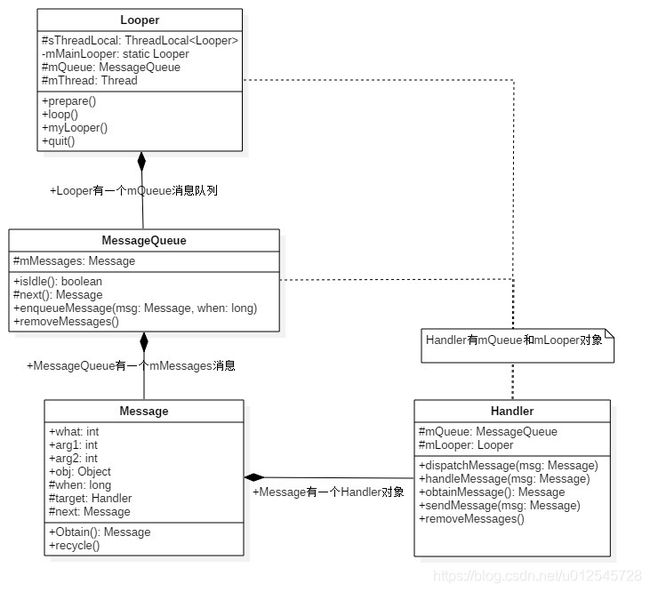
从架构图中看出重要角色间的持有关系
- Handler持有队列mQueue和Looper对象
- Looper中持有队列mQueue
- message中持有handler和next message
- MessageQueue中持有当前message
流程
这里我们讲一下handler工作的流程,首先的角色是Looper,Looper的作用是不断轮询消息队列MessageQueue。Looper是和线程强关联的,Loop先在某个线程中跑起来。
我们以这样一个例子,来讲解handler代码
class LooperThread extends Thread {
public Handler mHandler;
public void run() {
Looper.prepare();
mHandler = new Handler() {
public void handleMessage(Message msg) {
//TODO 定义消息处理
}
};
Looper.loop();
}
}
解释
-
在LooperThread线程中创建Looper,并开启循环,我们知道线程执行完run()方法中的逻辑就结束了,但是在该例子中,开启Looper.loop()后会不断轮询,即使轮询不到消息会阻塞线程,就会将线程挂起,不会执行结束
-
外部可以通过mHandler向该线程抛消息,那抛过来的消息最终会通过handleMessage处理,那么执行内容就跑在了LooperThread中
重点:一个线程有且只能有一个Looper
Looper
创建Looper
//门面方法创建
Looper.prepare();
//创建逻辑核心
private static void prepare(boolean quitAllowed) {
//每个线程只允许执行一次该方法,第二次执行时线程的TLS已有数据,则会抛出异常。
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
//创建Looper对象,并保存到当前线程的TLS区域
sThreadLocal.set(new Looper(quitAllowed));
}
//Looper构造方法
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed); //创建MessageQueue对象. 【见4.1】
mThread = Thread.currentThread(); //记录当前线程.
}
//关键方法Loop
public static void loop() {
final Looper me = myLooper(); //获取TLS存储的Looper对象 【见2.4】
final MessageQueue queue = me.mQueue; //获取Looper对象中的消息队列
Binder.clearCallingIdentity();
//确保在权限检查时基于本地进程,而不是调用进程。
final long ident = Binder.clearCallingIdentity();
for (;;) { //进入loop的主循环方法
Message msg = queue.next(); //可能会阻塞
if (msg == null) { //没有消息,则退出循环
return;
}
//默认为null,可通过setMessageLogging()方法来指定输出,用于debug功能
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg); //用于分发Message,将分发的逻辑转嫁到handler.dispatchMessage
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
//恢复调用者信息
final long newIdent = Binder.clearCallingIdentity();
msg.recycleUnchecked(); //将Message放入消息池回收,减少消息的创建
}
}
关于ThreadLocal不再赘述:保存当前线程的信息
loop方法中,是个死循环,不断从MessageQueue()中读取next()消息,可能会阻塞,阻塞的原理,在【MessqgeQueue.next()】中,下面讲。总体来看loop()的逻辑还是还简单:
- next()取消息,取不到阻塞
- 取到了将分发逻辑转嫁到message.target(handler上)
- 取出来是空,结束轮询
handler
构造
创建handler,一定要有looper,并且该Looper已经执行过prepare()了,这样才可以从looper中获取MessageQueue。没有指定Looper会直接那当前线程的Looper。
public Handler() {
this(null, false);
}
public Handler(Callback callback, boolean async) {
......
//必须先执行Looper.prepare(),才能获取Looper对象,否则为null.
mLooper = Looper.myLooper(); //从当前线程的TLS中获取Looper对象【见2.1】
if (mLooper == null) {
throw new RuntimeException("");
}
mQueue = mLooper.mQueue; //消息队列,来自Looper对象
mCallback = callback; //回调方法
mAsynchronous = async; //设置消息是否为异步处理方式
}
//有参构造
public Handler(Looper looper) {
this(looper, null, false);
}
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
消息分发
在讲解looper时说道,当looper.loop()循环到消息时,会调用message.target.dispatchMessage(),也就是handler的dispatchMessage()方法
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
//当Message存在回调方法,回调msg.callback.run()方法;
//其实message.callback是个runnable
handleCallback(msg);
} else {
if (mCallback != null) {
//当Handler存在Callback成员变量时,回调方法handleMessage();
if (mCallback.handleMessage(msg)) {
return;
}
}
//Handler自身的回调方法handleMessage()
handleMessage(msg);
}
}
一般我们都会在创建handler时重写handleMessage方法。
发送消息
在使用handler时,我们可以通过调用handler的发送消息方法,向队列中抛message。
具体方法有:
sendMessage(Message e)
sendMessageDelayed(Message e)
sendEmptyMessage(int what)
obtainMessage()
obtainMessage(int what)
post(Runnable r)
推荐使用obtainMessage()方法,因为不需要外部去new Message()传进来,而是使用handler内部消息池中的消息。减少创建Message所带来的开销
无论哪个方法最终都会走到这个方法
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
我们重点讲解下这个方法
参数:
-
queue:消息队列,就是handler中持有的消息队列,也就是Looper初始化时创建的queue
-
message:消息体
-
uptimeMillis:消息触发的时间,我们可以通过sendMessageDelay()来延迟消息的触发。当前时间13:10:10,调用sendMessageDelay(message,10000),表示10秒钟后触发消息,那么uptimeMillis的值就是13:10:20所对应的毫秒值,具体的转换实现如下:系统时间+延迟时间
public final boolean sendMessageDelayed(Message msg, long delayMillis) {
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
由此可见,如何实现的延迟发送,并没有在handler中实现,而是带着延迟时间一起传递了messageQueue,由它去实现
另外还有一个逻辑,即若Handler是同步的,则设置消息是同步的,这个先不管。
移除消息
public final void removeMessages(int what) {
mQueue.removeMessages(this, what, null); 【见 4.5】
}
同样丢给了MessageQueue去处理
MessageQueue
MessageQueue不仅是逻辑的中心,并且是与native交互的类,一些比较重要的逻辑,例如阻塞与唤醒,是由native实现的
创建MessageQueue
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
//通过native方法初始化消息队列,其中mPtr是供native代码使用
mPtr = nativeInit();
}
在创建Looper()时,会创建MessageQueue,这里直接调用了native方法,返回的mPtr参数是调用其他native方法时需要的参数,这里我们先不过多讨论。在讲解native部分时讨论
循环消息
整个handler工作原理的逻辑中心就是MessagwQueue的next()方法以及enqueueMessage()方法。其实MessageQueue中维护了一份链表,元素是Message,我们从Message类的定义中可以看出定义了【Message next】;enqueueMessage()方法就是将Message插入到链表合适的位置(按,delay的顺序排序),next()方法就是从链表中取出合适的Message处理。下边我们具体看
enqueueMessage
boolean enqueueMessage(Message msg, long when) {
// 每一个普通Message必须有一个target,除了屏障消息
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
synchronized (this) {
if (mQuitting) {
//正在退出时,回收msg,加入到消息池
msg.recycle();
return false;
}
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
/**
* 1.p为null 代表链表为空,新进来的msg作为链表第一个元素
* 2.msg的触发时间是队列中最早的,则插入到p的前边,并作为mMessages
*/
if (p == null || when == 0 || when < p.when) {
//p为null(代表MessageQueue没有消息)
msg.next = p;
mMessages = msg;
//如果当前是阻塞的,那么有消息插入进来了,要唤醒线程处理这个消息
needWake = mBlocked; //当阻塞时需要唤醒
} else {
//将消息按时间顺序插入到MessageQueue。一般不需要唤醒事件队列因为插入的并不是需要立马执行的消息,除非这个消息是同步屏障消息
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
//这个for找到比msg.when大的元素,
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
//如果是同步屏障消息,则不唤醒,等着,等异步消息插进来
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
//将msg插入到p的前边
msg.next = p;
prev.next = msg;
}
//消息没有退出,我们认为此时mPtr != 0
//如果需要唤醒则唤醒
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
总结:
- 逻辑是将Message插入到链表中合适的位置,并判断是否需要唤起。熟悉链表操作
就可以很容易明白插入的逻辑 - nativeWake(mPtr)从名字上也可以看出是通过native方法将该线程唤醒
Message next() {
final long ptr = mPtr;
if (ptr == 0) {
//ptr是调用native方法进行阻塞或唤起的关键参数,退出时会清空。当消息循环已经退出,则直接返回,
return null;
}
int pendingIdleHandlerCount = -1; // 循环迭代的首次为-1
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
//阻塞操作,当等待nextPollTimeoutMillis时长,或者消息队列被唤醒,都会返【见解释1】
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
//取当前消息
Message msg = mMessages;
//当前消息是同步屏障消息,则查询异步消息【见解释2】,我们平时塞入的全部是同步消息(有delay的也是同步消息!),一定有target的
if (msg != null && msg.target == null) {
//当查询到异步消息,则立刻退出循环,查询链表
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
//msg是正常消息或者经过上边的while循环赋值成异步消息了
//则进行执行逻辑
if (msg != null) {
if (now < msg.when) {
//当异步消息触发时间大于当前时间,说明还没到,继续计算下一次需要阻塞的时间
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
//链表操作:将该消息从链表中删除
mBlocked = false;
if (prevMsg != null) {
//从链表中删除
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
//设置消息的使用状态,即flags |= FLAG_IN_USE
msg.markInUse();
return msg; //成功地获取MessageQueue中的下一条即将要执行的消息,交给Looper处理
}
} else {
/**
* 没有消息,有两种情况
* 1.mMessage本来就是null
* 2.mMessage是同步屏障消息,但是遍历整个链表没有找到异步消息,则无限期阻塞,直到有地方唤醒
*/
nextPollTimeoutMillis = -1;
}
//正在退出,返回null
if (mQuitting) {
dispose();
return null;
}
//当消息队列为空,或者是消息队列的第一个消息时
if (pendingIdleHandlerCount < 0 && (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
//没有idle handlers 需要运行,则循环并等待。
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
//只有第一次循环时,会运行idle handlers,执行完成后,重置pendingIdleHandlerCount为0.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; //去掉handler的引用
boolean keep = false;
try {
keep = idler.queueIdle(); //idle时执行的方法
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
//重置idle handler个数为0,以保证不会再次重复运行
pendingIdleHandlerCount = 0;
//当调用一个空闲handler时,一个新message能够被分发,因此无需等待可以直接查询pending message.
nextPollTimeoutMillis = 0;
}
}
总结:
这里需要有三个地方需要解释
-
nativePollOnce()可以通过native层的逻辑将线程阻塞,原理是【epoll】,这里我们不先不理解他,认为他是X。只要知道他可以将线程阻塞即可。
-
同步屏障,这是Handler的一种机制,可以立即执行刚刚塞进队列的消息,而不是让该消息进去排队,直接加塞到第一。并且开启同步屏障后,不塞这个立即执行的消息,整个阻塞,不执行链表中的消息,等着你,像不像极品的走后门?具体原理参考这篇文章:
Android handler同步屏障机制
- idleHandler
还没学习,先跨过
阅读至此,应该理解了handler的工作原理,有些细节不懂,多看几次就明白了,无非就是when计算、链表操作、同步屏障的逻辑。还有一个巨大的疑问,那就是nativePollOnce()阻塞线程,原理是什么?nativeWake()唤醒线程,原理是什么?
一句话:利用Linux的多路复用机制epoll实现阻塞与唤醒,在前置知识中我们介绍了epoll相关知识,那么我们下面就看看native层时如何使用的
native层的handler
我们接着MessageQueue创建时调用native层方法来接着看,就可以看到epoll函数的影子
首先说明,native层也有一套Handler工作方式,和Java层是类似的,都有messagequeue/looper/handler,但是我们先重点介绍和Java层有交互的部分,也就是阻塞/唤起相关,再直白一点,寻找调用epoll相关函数的影子
关于native层handler原理,可以参考这篇文章:
native handler
初始化
我们从Java层MessageQueue的初始化作为起点开始看
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit(); //mPtr记录native消息队列的信息
}
nativeInit对应native层方法
static jlong android_os_MessageQueue_nativeInit(JNIEnv* env, jclass clazz) {
//初始化native层的消息队列
NativeMessageQueue* nativeMessageQueue = new NativeMessageQueue();
nativeMessageQueue->incStrong(env); //增加引用计数
return reinterpret_cast<jlong>(nativeMessageQueue);
}
接下来NativeMessageQueue的构造方法
NativeMessageQueue::NativeMessageQueue()
: mPollEnv(NULL), mPollObj(NULL), mExceptionObj(NULL) {
mLooper = Looper::getForThread(); //获取TLS中的Looper对象
if (mLooper == NULL) {
mLooper = new Looper(false); //创建native层的Looper 【4】
Looper::setForThread(mLooper); //保存native层的Looper到TLS
}
}
可以看到里边创建了looper,并保存在线程数据中,setForThread类比Java中的ThreadLocal,这一点是比较相似的,还有一点是和Java层相反的,Java层时创建Looper时创建MessageQueue,而native层时先创建MessageQueue中创建Looper
Looper的构造方法
Looper::Looper(bool allowNonCallbacks) :
mAllowNonCallbacks(allowNonCallbacks), mSendingMessage(false),
mPolling(false), mEpollFd(-1), mEpollRebuildRequired(false),
mNextRequestSeq(0), mResponseIndex(0), mNextMessageUptime(LLONG_MAX) {
mWakeEventFd = eventfd(0, EFD_NONBLOCK); //构造唤醒事件的fd
AutoMutex _l(mLock);
rebuildEpollLocked(); //重建Epoll事件【5】
}
重点来了,rebuildEpollLocker()方法中会初始化epoll,这里就用到了前置知识中的epoll
void Looper::rebuildEpollLocked() {
if (mEpollFd >= 0) {
close(mEpollFd); //关闭旧的epoll实例
}
mEpollFd = epoll_create(EPOLL_SIZE_HINT); //创建新的epoll实例,并注册wake管道
struct epoll_event eventItem;
memset(& eventItem, 0, sizeof(epoll_event)); //把未使用的数据区域进行置0操作
eventItem.events = EPOLLIN; //可读事件
eventItem.data.fd = mWakeEventFd;
//将唤醒事件(mWakeEventFd)添加到epoll实例(mEpollFd)
//并且关注的是可读事件,那么调用epoll_wait阻塞后,一旦向该文件操作符所代表的文件中写入数据,那么epoll_wait便会返回
int result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeEventFd, & eventItem);
//native层message的逻辑
for (size_t i = 0; i < mRequests.size(); i++) {
const Request& request = mRequests.valueAt(i);
struct epoll_event eventItem;
request.initEventItem(&eventItem);
//将request队列的事件,分别添加到epoll实例
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, request.fd, & eventItem);
}
}
Looper对象中的mWakeEventFd添加到epoll监控,以及mRequests也添加到epoll的监控范围内。
阻塞
在handler原理中我们知道,调用nativePollOnce()后便会阻塞当前线程,那么我们来看看nativePollOnce()做了什么。
pollInner代码
int Looper::pollInner(int timeoutMillis) {
...
int result = POLL_WAKE;
mResponses.clear();
mResponseIndex = 0;
mPolling = true; //即将处于idle状态
struct epoll_event eventItems[EPOLL_MAX_EVENTS]; //fd最大个数为16
//阻塞事件发生或者超时,在nativeWake()方法,向管道写端写入字符,则该方法会返回;
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
mPolling = false; //不再处于idle状态
mLock.lock(); //请求锁
if (mEpollRebuildRequired) {
mEpollRebuildRequired = false;
rebuildEpollLocked(); // epoll重建,直接跳转Done;
goto Done;
}
if (eventCount < 0) {
if (errno == EINTR) {
goto Done;
}
result = POLL_ERROR; // epoll事件个数小于0,发生错误,直接跳转Done;
goto Done;
}
if (eventCount == 0) { //epoll事件个数等于0,发生超时,直接跳转Done;
result = POLL_TIMEOUT;
goto Done;
}
//循环遍历,处理所有的事件
for (int i = 0; i < eventCount; i++) {
int fd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
//java层文件描述符事件
if (fd == mWakeEventFd) {
if (epollEvents & EPOLLIN) {
awoken(); //已经唤醒了,则读取并清空管道数据,个人理解下次epoll_wait还能阻塞住
}
} else {
//处理native层文件描述符事件
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex >= 0) {
int events = 0;
if (epollEvents & EPOLLIN) events |= EVENT_INPUT;
if (epollEvents & EPOLLOUT) events |= EVENT_OUTPUT;
if (epollEvents & EPOLLERR) events |= EVENT_ERROR;
if (epollEvents & EPOLLHUP) events |= EVENT_HANGUP;
//处理request,生成对应的reponse对象,push到响应数组
pushResponse(events, mRequests.valueAt(requestIndex));
}
}
}
Done: ;
//再处理Native的Message,调用相应回调方法
//与Java层无关先删掉
mLock.unlock(); //释放锁
//处理带有Callback()方法的Response事件,执行Reponse相应的回调方法:处理native层的消息
return result;
}
唤醒
调用链
MessageQueue.enqueueMessage()->
MessageQueue.nativeWake()->
JNI
android_os_MessageQueue_nativeWake() ->
nativeMessageQueue->wake() ->
Looper->wake() ->
write()
Looper::wake()
void Looper::wake() {
uint64_t inc = 1;
// 向管道mWakeEventFd写入字符1
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd, &inc, sizeof(uint64_t)));
if (nWrite != sizeof(uint64_t)) {
if (errno != EAGAIN) {
ALOGW("Could not write wake signal, errno=%d", errno);
}
}
}
其中TEMP_FAILURE_RETRY 是一个宏定义, 当执行write失败后,会不断重复执行,直到执行成功为止。我们看到向文件描述符mWakeEventFd中写入一个字符
我们再回顾一下初始化epoll时的代码
memset(& eventItem, 0, sizeof(epoll_event)); //把未使用的数据区域进行置0操作
eventItem.events = EPOLLIN; //可读事件
eventItem.data.fd = mWakeEventFd;
//将唤醒事件(mWakeEventFd)添加到epoll实例(mEpollFd)
//并且关注的是可读事件,那么调用epoll_wait阻塞后,一旦向该文件操作符所代表的文件中写入数据,那么epoll_wait便会返回
int result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeEventFd, & eventItem);
可以看到添加mWakeEventFd文字描述符到epoll句柄中,关注的event是可读事件,一切不言而喻
其他
我们这里总结一些常见的问题,其实这些问题的答案也代表着handler的核心内容
handler为什么不会阻塞主线程?
我们这样理解,一台机器的空转和机器卡死是两回事。当没有消息处理时。主线程的Looper会阻塞到MessageQueue.next()方法中,那么主线程就会被挂起,挂起不等于销毁,更不等于卡死,而是让出CPU。让其他线程运行,如果不阻塞主线程,那么主线程结束,APP也结束了。
在主线程开启Looper.loop()循环之前,已经创建了Binder线程。在有需要时,binder线程会向主线程中抛消息,唤醒主线程,但是一般情况下主线程不会没有消息处理,因为就算点一下屏幕,最终也会通过Handler处理。
再说卡死,Android中卡死就是ANR,handler阻塞是不会造成anr的,在onCreate等回调函数中才会造成ANR,不在本文讨论范围
handler在Android源码中的应用
- Android View的绘制 / Input事件处理
在必要时候,会向主线程发消息,出发主线程进行页面重绘,并且这里还使用到了同步屏障机制,我们来看ViewRootImpl源码
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
这里开启了同步屏障
private void scheduleProcessInputEvents() {
if (!mProcessInputEventsScheduled) {
mProcessInputEventsScheduled = true;
Message msg = mHandler.obtainMessage(MSG_PROCESS_INPUT_EVENTS);
msg.setAsynchronous(true);
mHandler.sendMessage(msg);
}
}
这里向handler抛入异步消息
这样能保证消息第一时间执行,看代码应该是处理Input事件的。
在学习View绘制或input事件分发时,都会看到Handler的影子
- 与binder线程的通信
我们一开始就说过handler的功能之一就是线程间通信,那么binder线程与主线程的通信就是通过Handler进行的,在梳理binder知识时会看到很多handler的影子,一开始看binder相关代码时会发现总是通过Handler处理,不明白为什么,其实就是通过handler进行线程间通信
后记
Handler作为Android最重要的内容之一,是需要深刻掌握的。理解了handler,对于理解Android其他重要内容,如Binder通信/activity管理等都有重要意义,本文着重阐述了Java层handler的工作原理以及其阻塞的方法:epoll。希望能够对大家理解handler有帮助
参考优秀博文:
gityuan native handler
gityuan java handler