哈夫曼码编码器的软件实现(Matlab编程)
文章目录
- 一、背景介绍
-
- 1.哈夫曼树的定义与特点
- 2.哈夫曼树的创建构造
- 二、设计思路
- 三、软件流程图
- 四、核心代码
-
- 1.sort排序函数
- 2.建立各概率符号的位置索引矩阵Index
- 3.初始化存放矩阵
- 4.回溯过程的代码实现
- 五、运行效果截图及相关说明
这里附上Matlab源码的下载链接,里面还有运行结果asv文件和软件程序流程图png文件
https://download.csdn.net/download/h568630659/18523188?spm=1001.2014.3001.5501
一、背景介绍
1.哈夫曼树的定义与特点
哈夫曼(Huffman)编码是一种编码方式, 属于一种程序算法。是满足前缀条件的平均二进制码长最短的编-源输出符号,而将较短的编码码字分配给较大概率的信源输出。算法是:在信源符号集合中,首先将两个最小概率的信源输出合并为新的输出,其概率是两个相应输出符号概率之和。这一过程重复下去,直到只剩下一个合并输出为止,这个最后的合并输出符号的概率为1。这样就得到了一张树图,从树根开始,将编码符号1和0分配在同一节点的任意两分支上,这一分配过程重复直到树叶。从树根到树叶途经支路上的编码最后就构成了一组异前置码,就是哈夫曼编码输出。
设二叉树具有n个带权值的叶子结点,从根结点到各个叶子结点的路径长度与相应叶子结点权值的乘积之和记为:
![]() ,其中wk表示第k个叶子的权值,lk表示从根节点到第k个叶子的路径长度。
,其中wk表示第k个叶子的权值,lk表示从根节点到第k个叶子的路径长度。
那么给定n个叶子结点与权值,便可以构造出形状不同的二叉树,而哈夫曼树就是给定一组具有确定权值的叶子结点,带权路径长度最小的二叉树,亦称最优二叉树。
哈夫曼树的特点:
·权值越大的叶子结点越靠近根结点,而权值越小的叶子结点越远离根结点。(构造哈夫曼树的核心思想)
·只有度为0(叶子结点)和度为2(分支结点)的结点,不存在度为1的结点。
·n个叶结点的哈夫曼树的结点总数为2n-1个。
·哈夫曼树不唯一,但WPL唯一。
2.哈夫曼树的创建构造
构成哈夫曼树的步骤:
(1)从小到大进行排序, 将每一个数据,每个数据都是一个节点,每个节点可以看成是一颗最简单的二叉树。
(2)取出根节点权值最小的两颗二叉树。
(3)组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和。
(4)再将这颗新的二叉树,以根节点的权值大小再次排序,不断重复1-2-3-4的步骤,直到数列中所有的数据都被处理,就得到一颗哈夫曼树。
二、设计思路
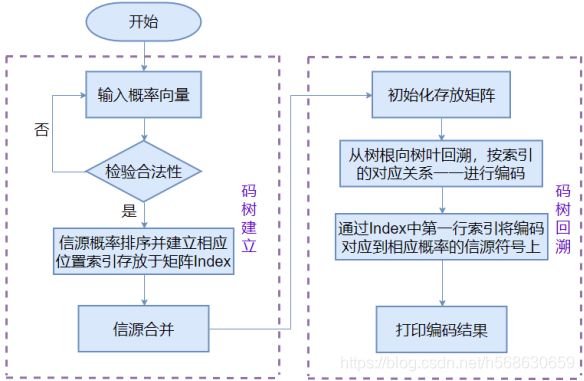
分为两步,首先是码树形成过程:对信源概率进行合并形成编码码树。然后是码树回溯过程:在码树上分配编码码字并最终得到哈夫曼编码。
1、码树形成过程:将信源概率按照从小到大顺序排序并建立相应的位置索引。然后按上述规则进行信源合并,再对信源进行排序并建立新的位置索引,直到合并结束。在这一过程中每- -次都把排序后的信源概率存入矩阵G中,位置索引存入矩阵Index中。这样,由排序之后的概率矩阵G以及索引矩阵Index就可以恢复原概率矩阵P了,从而保证了回溯过程能够进行下去。
2、码树回溯过程:在码树上分配编码码字并最终得到Huffman编码。从索引矩阵M的末行开始回溯。
(1)在Index 的末行2元素位置填入0和1。
(2)根据该行索引1位置指示,将索引1位置的编码(‘1’)填入上一行的第一、第二元素位置,并在它们之后分别添加‘0’ 和‘1’。
(3)将索引不为‘1’的位置的编码值(‘0’)填入上一行的相应位置(第3列)。
(4)以Index的倒数第二行开始向上,重复步骤(1) ~ (3), 直到计算至Index的首行为止。
也即通过从哈夫曼树根结点开始,对左子树分配代码“0”,右子树分配代码“1”,一直到达叶子结点为止,然后将从树根沿每条路径到达叶子结点的代码排列起来,便得到了哈夫曼编码。因为形成哈夫曼树的每一次合并操作都将对应一次代码分配,因此n个叶子结点的最大编码长度不会超过n-1,所以可为每个叶子结点分配一个长度为n的编码数组。
基本思想是:从叶子tree[i]出发,利用双亲地址找到双亲结点tree[p],再利用tree[p]的左孩子lchild和右孩子rchild指针域判断tree[i]是tree[p]的左孩子还是右孩子,然后决定分配代码是“0”还是“1”, 然后以tree[p]为出发点继续向上回溯,直到根结点为止。
三、软件流程图
四、核心代码
1.sort排序函数
Matlab中给一维向量排序使用sort函数:sort(A),排序按升序进行,其中A为待排序的向量;若想保留排列前的索引,则可以用[sA,index]=sort(A),排序后,sA为排序好的向量,index是向量sA中对A的索引。索引使排序逆运算成为可能。
在代码中通过p=sort( p )将输入的信源概率按从小到大的顺序排序,为后续建立位置索引做准备。
2.建立各概率符号的位置索引矩阵Index
建立此矩阵,利于编码后从树根进行回溯,从而得出对应编码。

图4.1 建立位置索引矩阵代码
3.初始化存放矩阵
Char(N-1,N²)(这个向量用来放编码,一行即为一次排序,输入的P长度为N,每一个概率最长码长为N,所以每一列的长度为N×N,没编码的地方为定义为空。从N-1行开始编,知道第一层,第一层即为哈夫曼编码。)

图4.2 初始化存放矩阵代码
4.回溯过程的代码实现
给第Char的N-1行赋值:给index的最后一行的两个数分别编码为0和1,存入Char的N-1行的第N列和第2N列。

从N-2行到第一行,找出index中为1的数,给那两个最小数的编码的最后一位分别编为0和1(Chars的第N列赋值为0,Chars的第N2列赋值为1)。然后将其编码加在这两个数的编码前面。

将其余空缺的编码按顺序补上。

至此,哈夫曼编码已经完成,即Chars向量的第一行,现在要把他们分离出来。

五、运行效果截图及相关说明
输入信源概率矩阵[0.4 0.2 0.1 0.1 0.08 0.02],在Matlab窗口中执行如下命令得到结果:
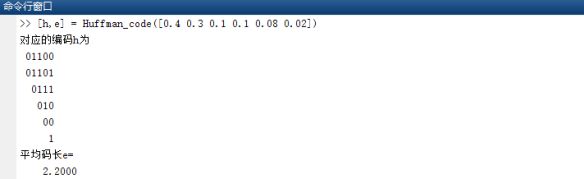
其中,h表示对应的编码,e代表平均码长。值得一提的是,哈夫曼编码的结果不唯一,它与左节点和右节点设置0和1的方式有关。
参考博文链接
这里附上Matlab源码的下载链接,里面还有运行结果asv文件和软件程序流程图png文件
https://download.csdn.net/download/h568630659/18523188?spm=1001.2014.3001.5501