Vigenère 密码
题目描述
16 世纪法国外交家 Blaise de Vigenère 设计了一种多表密码加密算法――Vigenère 密码。
Vigenère 密码的加密解密算法简单易用,且破译难度比较高,曾在美国南北战争中为南军所广泛使用。
在密码学中,我们称需要加密的信息为明文,用 M 表示;称加密后的信息为密文,用C 表示;而密钥是一种参数,是将明文转换为密文或将密文转换为明文的算法中输入的数据,记为 k。 在 Vigenère 密码中,密钥 k 是一个字母串,k=k1k2…kn。当明文 M=m1m2…mn时,得到的密文 C=c1c2…cn,其中 ci=mi®ki,运算®的规则如下表所示:

Vigenère 加密在操作时需要注意:
- ®运算忽略参与运算的字母的大小写,并保持字母在明文 M 中的大小写形式;
- 当明文 M 的长度大于密钥 k 的长度时,将密钥 k 重复使用。
例如,明文 M=Helloworld,密钥 k=abc 时,密文 C=Hfnlpyosnd。

输入输出格式
输入格式:
输入共 2 行。
第一行为一个字符串,表示密钥 k,长度不超过 100,其中仅包含大小写字母。第二行
为一个字符串,表示经加密后的密文,长度不超过 1000,其中仅包含大小写字母。
输出格式:
输出共 1 行,一个字符串,表示输入密钥和密文所对应的明文。
输入输出样例
输入样例#1:
CompleteVictory
Yvqgpxaimmklongnzfwpvxmniytm
输出样例#1:
Wherethereisawillthereisaway
思路
比较简单的暴力模拟
代码
#include
#include
#include
using namespace std;
int main()
{
int key[100];
char k[100],mw[1000],ans[1000];
int i,lk,lmw;
cin>>k>>mw;
lk=strlen(k);
lmw=strlen(mw);
for(i=0;i='a')key[i]=k[i]-'a';
else key[i]=k[i]-'A';
}
i=0;
while(i='a'))ans[i]=ans[i]+26;
cout< 国王游戏
题目描述
恰逢 H 国国庆,国王邀请 n 位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这 n 位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。
国王不希望某一个大臣获得特别多的奖赏,所以他想请你帮他重新安排一下队伍的顺序,使得获得奖赏最多的大臣,所获奖赏尽可能的少。注意,国王的位置始终在队伍的最前面。
输入输出格式
输入格式:
第一行包含一个整数 n,表示大臣的人数。
第二行包含两个整数 a和 b,之间用一个空格隔开,分别表示国王左手和右手上的整数。
接下来 n 行,每行包含两个整数 a 和 b,之间用一个空格隔开,分别表示每个大臣左手和右手上的整数。
输出格式:
输出只有一行,包含一个整数,表示重新排列后的队伍中获奖赏最多的大臣所获得的金币数。
输入输出样例
输入样例#1:
3
1 1
2 3
7 4
4 6
输出样例#1:
2
说明
【输入输出样例说明】
- 按 1、2、3 号大臣这样排列队伍,获得奖赏最多的大臣所获得金币数为 2;
- 按 1、3、2 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2;
- 按 2、1、3 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2;
- 按 2、3、1 这样排列队伍,获得奖赏最多的大臣所获得金币数为 9;
- 按 3、1、2 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2;
- 按 3、2、1 这样排列队伍,获得奖赏最多的大臣所获得金币数为 9。
因此,奖赏最多的大臣最少获得 2 个金币,答案输出 2。
【数据范围】
对于 20%的数据,有 1≤ n≤ 10,0 < a、b < 8;
对于 40%的数据,有 1≤ n≤20,0 < a、b < 8;
对于 60%的数据,有 1≤ n≤100;
对于 60%的数据,保证答案不超过 10^9;
对于 100%的数据,有 1 ≤ n ≤1,000,0 < a、b < 10000。
思路
看到这道题的使得获得奖赏最多的大臣,所获奖赏尽可能的少
可以这样思考,相邻两个的人交换对于前面的人答案没影响、,而且对于后面的人答案也没有影响。也就是说相邻两人的位置交换只会对这两个人产生影响。那么我们就先考虑这两个人。
设这两个人分别为i和i+1。左手数字为a[i]和a[i+1],右手数字为b[i]和b[i+1]。两人的金币数为w[i]和w[i+1]。
记P[i]=a[1]*a[2]*a[3]*...*a[i]
可得:
w[i]=P[i-1]/b[i];
w[i+1]=P[i]/b[i+1];
又P[i]=P[i-1]*a[i]
那么 w[i+1]=P[i-1]*a[i]/b[i+1]=w[i]*a[i]*b[i]/b[i+1]
不难看出,在这个相邻的二元组中,前面的数不受后面的影响,而后面的金币数决定于w[i],a[i],b[i]。
推广到整个排队方案,前面的金币数和a[i],b[i]都会影响后面的答案。贪心原则便出来了:按a[i]*b[i]为关键字从小到大排序,相同的顺序无所谓。最后再扫一遍,算出答案即可。
注意一点:乘除法都要写高精度,答案有10000多位。
代码
#include
#include
#include
#include
#include
#include
#include
using namespace std;
int N;
int a[1005],b[1005],ka,kb;
int ans[20000],t[20000],lena,lent,tt[20000],t2[20000],len;
void _qst_ab(int l,int r)
{
int i=l,j=r,ma=a[(i+j)>>1],mb=b[(i+j)>>1];
while(i<=j)
{
while(a[i]*b[i]ma*mb) j--;
if(i<=j)
{
swap(a[i],a[j]);
swap(b[i],b[j]);
i++;j--;
}
}
if(l=10)
{
tt[lent+1]=tt[lent]/10;
tt[lent]%=10;
lent++;
}
while(lent>1&&tt[lent]==0) lent--;
len=lent;
memcpy(t,tt,sizeof(tt));
memset(tt,0,sizeof(tt));
for(int i=1,j=len;i<=len;i++,j--)
t2[i]=t[j];
int x=0,y=0;
for(int i=1;i<=len;i++)
{
y=x*10+t2[i];
tt[i]=y/Right;
x=y%Right;
}
x=1;
while(xlena) return true;
if(lentt[i]) return false;
}
return false;
}
void _solve()
{
_qst_ab(1,N);
t[1]=1;lent=1;
for(int i=1;i<=N;i++)
{
memset(tt,0,sizeof(tt));
len=0;
_get_t(a[i-1],b[i]);
if(_cmp())
{
memcpy(ans,tt,sizeof(tt));
lena=len;
}
}
for(int i=1;i<=lena;i++)
printf("%d",ans[i]);
printf("\n");
}
int main()
{
_init();
_solve();
return 0;
}
借教室
题目描述
在大学期间,经常需要租借教室。大到院系举办活动,小到学习小组自习讨论,都需要向学校申请借教室。教室的大小功能不同,借教室人的身份不同,借教室的手续也不一样。
面对海量租借教室的信息,我们自然希望编程解决这个问题。
我们需要处理接下来n天的借教室信息,其中第i天学校有ri个教室可供租借。共有m份订单,每份订单用三个正整数描述,分别为dj,sj,tj,表示某租借者需要从第sj天到第tj天租借教室(包括第sj天和第tj天),每天需要租借dj个教室。
我们假定,租借者对教室的大小、地点没有要求。即对于每份订单,我们只需要每天提
供dj个教室,而它们具体是哪些教室,每天是否是相同的教室则不用考虑。
借教室的原则是先到先得,也就是说我们要按照订单的先后顺序依次为每份订单分配教室。如果在分配的过程中遇到一份订单无法完全满足,则需要停止教室的分配,通知当前申请人修改订单。这里的无法满足指从第sj天到第tj天中有至少一天剩余的教室数量不足dj个。
现在我们需要知道,是否会有订单无法完全满足。如果有,需要通知哪一个申请人修改订单。
输入输出格式
输入格式:
第一行包含两个正整数n,m,表示天数和订单的数量。
第二行包含n个正整数,其中第i个数为ri,表示第i天可用于租借的教室数量。
接下来有m行,每行包含三个正整数dj,sj,tj,表示租借的数量,租借开始、结束分别在第几天。
每行相邻的两个数之间均用一个空格隔开。天数与订单均用从1开始的整数编号。
输出格式:
如果所有订单均可满足,则输出只有一行,包含一个整数 0。否则(订单无法完全满足)
输出两行,第一行输出一个负整数-1,第二行输出需要修改订单的申请人编号。
输入输出样例
输入样例#1:
4 3
2 5 4 3
2 1 3
3 2 4
4 2 4
输出样例#1:
-1
2
说明
【输入输出样例说明】
第 1 份订单满足后,4 天剩余的教室数分别为 0,3,2,3。第 2 份订单要求第 2 天到第 4 天每天提供 3 个教室,而第 3 天剩余的教室数为 2,因此无法满足。分配停止,通知第2 个申请人修改订单。
【数据范围】
对于10%的数据,有1≤ n,m≤ 10;
对于30%的数据,有1≤ n,m≤1000;
对于 70%的数据,有1 ≤ n,m ≤ 10^5;
对于 100%的数据,有1 ≤ n,m ≤ 10^6,0 ≤ ri,dj≤ 10^9,1 ≤ sj≤ tj≤ n。
思路
看数据范围,应该是一个log的算法,发现是每一次都维护一个范围的数,果断线段树……
维护一个区间的所有值的线段树需要加lazy优化,要不然绝对T掉。
所以总结一句:本题为裸线段树+lazy优化
代码
#include
#define MAXN 1100010
using namespace std;
struct rec
{
int sum;
int inc;//lazy
};
int m,n;
rec tree[2*MAXN];
int i;
int u,v,w;
bool finish=false;
inline void read(int &x) //读入优化,据说不加会T?
{
char ch=getchar();
while(ch<'0'||ch>'9') ch=getchar();
x=0;
while(ch<='9'&&ch>='0')
{
x=x*10+ch-'0';
ch=getchar();
}
return ;
}
int mymin(int a,int b)
{
return a>1;
Build_A_Tree(pos<<1,l,mid);
Build_A_Tree((pos<<1)+1,mid,r);
tree[pos].sum=mymin(tree[pos<<1].sum,tree[(pos<<1)+1].sum);
}
inline void update(int pos)
{
if (!tree[pos].inc) return ;
tree[pos<<1].inc+=tree[pos].inc;
tree[(pos<<1)+1].inc+=tree[pos].inc;
tree[pos<<1].sum+=tree[pos].inc;
tree[(pos<<1)+1].sum+=tree[pos].inc;
tree[pos].inc=0;
}
void modify(int pos,int l,int r,int ll,int rr,int delta)
{
if (finish) return ;
if (l>=ll&&r<=rr)
{
tree[pos].sum+=delta;
if (tree[pos].sum<0)
{
printf("-1\n%d\n",i);
finish=true;
return ;
}
tree[pos].inc+=delta;
return ;
}
update(pos);
int mid=(l+r)>>1;
if (llmid) modify((pos<<1)+1,mid,r,ll,rr,delta);
tree[pos].sum=mymin(tree[pos<<1].sum,tree[(pos<<1)+1].sum);
}
int main()
{
read(n);read(m);
Build_A_Tree(1,1,n+1);
for (i=1;i<=m;i++){
read(u);read(v);read(w);
modify(1,1,n+1,v,w+1,-u);
if (finish) return 0;
}
printf("0\n");
return 0;
}
同余方程
题目描述
求关于 x 的同余方程 ax ≡ 1 (mod b)的最小正整数解。
输入输出格式
输入格式:
输入只有一行,包含两个正整数 a, b,用一个空格隔开。
输出格式:
输出只有一行,包含一个正整数 x0,即最小正整数解。输入数据保证一定有解。
输入输出样例
输入样例#1:
3 10
输出样例#1:
7
说明
【数据范围】
对于 40%的数据,2 ≤b≤ 1,000;
对于 60%的数据,2 ≤b≤ 50,000,000;
对于 100%的数据,2 ≤a, b≤ 2,000,000,000。
思路

代码
#include
using namespace std;
int n,a,b,ans=0,x,y;
void exgcd(int a,int b){
if(b==1){y=1,x=0;return;}
exgcd(b,a%b);
int temp=x;x=y;y=temp-x*(a/b);
}
int main(){
scanf("%d%d",&a,&b);
exgcd(a,b);
printf("%d",(x%b+b)%b);
}
开车旅行
题目描述
小 A 和小 B 决定利用假期外出旅行,他们将想去的城市从 1 到 N 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 i 的海拔高度为Hi,城市 i 和城市 j 之间的距离 d[i,j]恰好是这两个城市海拔高度之差的绝对值,即d[i,j] = |Hi− Hj|。 旅行过程中,小 A 和小 B 轮流开车,第一天小 A 开车,之后每天轮换一次。他们计划选择一个城市 S 作为起点,一直向东行驶,并且最多行驶 X 公里就结束旅行。小 A 和小 B的驾驶风格不同,小 B 总是沿着前进方向选择一个最近的城市作为目的地,而小 A 总是沿着前进方向选择第二近的城市作为目的地(注意:本题中如果当前城市到两个城市的距离相同,则认为离海拔低的那个城市更近)。如果其中任何一人无法按照自己的原则选择目的城市,或者到达目的地会使行驶的总距离超出 X 公里,他们就会结束旅行。
在启程之前,小 A 想知道两个问题:
对于一个给定的 X=X0,从哪一个城市出发,小 A 开车行驶的路程总数与小 B 行驶的路程总数的比值最小(如果小 B 的行驶路程为 0,此时的比值可视为无穷大,且两个无穷大视为相等)。如果从多个城市出发,小 A 开车行驶的路程总数与小 B 行驶的路程总数的比值都最小,则输出海拔最高的那个城市。
对任意给定的 X=Xi和出发城市 Si,小 A 开车行驶的路程总数以及小 B 行驶的路程总数。
输入输出格式
输入格式:
- 第一行包含一个整数 N,表示城市的数目。
- 第二行有 N 个整数,每两个整数之间用一个空格隔开,依次表示城市 1 到城市 N 的海拔高度,即 H1,H2,……,Hn,且每个 Hi都是不同的。
- 第三行包含一个整数 X0。
- 第四行为一个整数 M,表示给定 M 组 Si和 Xi。
接下来的 M 行,每行包含 2 个整数 Si和 Xi,表示从城市 Si出发,最多行驶 Xi公里。
输出格式:
输出共 M+1 行。
第一行包含一个整数 S0,表示对于给定的 X0,从编号为 S0的城市出发,小 A 开车行驶的路程总数与小 B 行驶的路程总数的比值最小。
接下来的 M 行,每行包含 2 个整数,之间用一个空格隔开,依次表示在给定的 Si和
Xi下小 A 行驶的里程总数和小 B 行驶的里程总数。
输入输出样例
输入样例#1:
4
2 3 1 4
3
4
1 3
2 3
3 3
4 3
输出样例#1:
1
1 1
2 0
0 0
0 0
输入样例#2:
10
4 5 6 1 2 3 7 8 9 10
7
10
1 7
2 7
3 7
4 7
5 7
6 7
7 7
8 7
9 7
10 7
输出样例#2:
2
3 2
2 4
2 1
2 4
5 1
5 1
2 1
2 0
0 0
0 0
说明
【输入输出样例 1 说明】
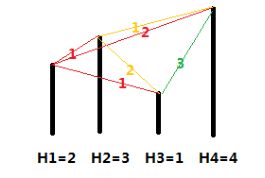
各个城市的海拔高度以及两个城市间的距离如上图所示。
- 如果从城市 1 出发,可以到达的城市为 2,3,4,这几个城市与城市 1 的距离分别为 1,1,2,但是由于城市 3 的海拔高度低于城市 2,所以我们认为城市 3 离城市 1 最近,城市 2 离城市1 第二近,所以小 A 会走到城市 2。到达城市 2 后,前面可以到达的城市为 3,4,这两个城市与城市 2 的距离分别为 2,1,所以城市 4 离城市 2 最近,因此小 B 会走到城市 4。到达城市 4 后,前面已没有可到达的城市,所以旅行结束。
- 如果从城市 2 出发,可以到达的城市为 3,4,这两个城市与城市 2 的距离分别为 2,1,由于城市 3 离城市 2 第二近,所以小 A 会走到城市 3。到达城市 3 后,前面尚未旅行的城市为4,所以城市 4 离城市 3 最近,但是如果要到达城市 4,则总路程为 2+3=5>3,所以小 B 会直接在城市 3 结束旅行。
- 如果从城市 3 出发,可以到达的城市为 4,由于没有离城市 3 第二近的城市,因此旅行还未开始就结束了。
- 如果从城市 4 出发,没有可以到达的城市,因此旅行还未开始就结束了。
【输入输出样例 2 说明】
当 X=7 时, - 如果从城市 1 出发,则路线为 1 -> 2 -> 3 -> 8 -> 9,小 A 走的距离为 1+2=3,小 B 走的距离为 1+1=2。(在城市 1 时,距离小 A 最近的城市是 2 和 6,但是城市 2 的海拔更高,视为与城市 1 第二近的城市,所以小 A 最终选择城市 2;走到 9 后,小 A 只有城市 10 可以走,没有第 2 选择可以选,所以没法做出选择,结束旅行)
- 如果从城市 2 出发,则路线为 2 -> 6 -> 7 ,小 A 和小 B 走的距离分别为 2,4。
- 如果从城市 3 出发,则路线为 3 -> 8 -> 9,小 A 和小 B 走的距离分别为 2,1。
- 如果从城市 4 出发,则路线为 4 -> 6 -> 7,小 A 和小 B 走的距离分别为 2,4。
- 如果从城市 5 出发,则路线为 5 -> 7 -> 8 ,小 A 和小 B 走的距离分别为 5,1。
- 如果从城市 6 出发,则路线为 6 -> 8 -> 9,小 A 和小 B 走的距离分别为 5,1。
- 如果从城市 7 出发,则路线为 7 -> 9 -> 10,小 A 和小 B 走的距离分别为 2,1。
- 如果从城市 8 出发,则路线为 8 -> 10,小 A 和小 B 走的距离分别为 2,0。
- 如果从城市 9 出发,则路线为 9,小 A 和小 B 走的距离分别为 0,0(旅行一开始就结束了)。
- 如果从城市 10 出发,则路线为 10,小 A 和小 B 走…
思路
用平衡树处理出每个点开始小A/小B能到达的下个点,然后加个倍增就行了
第一问枚举起点即可
代码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include