如何使用ClickHouse实现时序数据管理和挖掘?
ClickHouse是一个高效的开源联机分析列式数据库管理系统,由俄罗斯IT公司Yandex开发的,并于2016年6月宣布开源。本篇文章将详细解读JUST(https://just.urban-computing.cn/)是如何使用ClickHouse实现时序数据管理和挖掘的。
一、时序数据简介
时序数据全称是时间序列(TimeSeries)数据,是按照时间顺序索引的一系列数据点。最常见的是在连续的等时间间隔时间点上获取的序列,因此,它是一系列离散数据[1]。
时序数据几乎无处不在,在目前单向的时间流中,人的脉搏、空气的湿度、股票的价格等都随着时间的流逝不断变化。时序数据是数据的一种,因为它显著而有价值的特点,成为我们特别分析的对象。
将时序数据可以建模为如下部分组成:
- Metric:度量的数据集,类似于关系型数据库中的 table,是固定属性,一般不随时间而变化
- Timestamp:时间戳,表征采集到数据的时间点
- Tags:维度列,用于描述Metric,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化
- Field/Value:指标列,代表数据的测量值,可以是单值也可以是多值
一个具体的多值模型时序数据案例如表1所示:

二、时序数据管理概述
1. 时序数据管理的流程
一切数据的本质都是为价值服务的,获取价值的这个过程就是数据管理与分析。从技术上来说,任何数据从产生到灭亡都会经历如图1所示的过程。

时序数据也不例外,只是每个部分的处理不同。
(1)数据采集。同一个场景下时序数据产生的频率一般恒定,但在不同场景下采集数据的频率是变化的,每秒一千条和每秒一千万条数据使用的技术是完全不同的。所以,数据采集要考虑的主要是频率和并发。
(2)数据存储。数据存储是为了查询和分析服务的。以什么格式存储、建什么索引、存储数据量大小、存储时长是时序数据存储要考虑的,一般时序数据写多读少,数据具有时效性,所以存储时可以考虑冷热存储分离。
(3)数据查询和分析。时序数据的查询也具有显著特点,一般会按照时间范围读取,最近的数据读取频率高,并且按照不同的时间粒度做聚合查询,比如统计最近一周每天的数据量。
分析是依赖于查询的,时序数据的分析通常是多维的,比如网页点击流量、从哪个网站、来自哪个IP、点击频率等维度众多,取决于具体场景。而时序数据也非常适合数据挖掘,利用历史预测未来。
(4)数据删除。这里的删除并不是针对单条数据的,而是对特定时间范围内的批量数据进行过期处理。因为时序数据具有时效性,历史数据通常不再具有价值,不管是定时删除还是手动删除,都代表着其短暂的生命周期的结束。
2. 时序数据管理系统目标
根据时序数据的特点和场景,我们需要一个能满足以下目标的时序数据管理平台:
- 高吞吐写入:千万、上亿数据的秒级实时写入 & 持续高并发写入。
- 无更新操作:数据大多表征设备状态,写入后无需更新。
- 海量数据存储:从TB到PB级。
- 高效实时的查询:按不同维度对指标进行统计分析,存在明显的冷热数据,一般只会频繁查询近期数据
- 高可用
- 可扩展性
- 易于使用
- 易于维护
3.技术选型
说到数据库,大家第一个想到的肯定是MySQL、Oracle等传统的已经存在很多年的关系型数据库。当然关系模型依然有效且实用。对于小数据量(几百万到几千万),MySQL是可以搞定的,再大一些就需要分库分表解决了。对时序数据一般按照时间分表,但是这对外部额外设计和运维的工作提出了高要求。显然,这不能满足大数据场景,所以几乎没有人选择这种方案。
纵观db-engine上排名前十的时序数据库[2],排除商用的,剩下开源的选择并不多。接下来介绍几款比较流行的时序数据库。

(1)OpenTSDB。OpenTSDB开源快10年了,属于早期的解决方案。因为其基于Hadoop和HBase开发的索引,所以具有海量数据的存储能力,也号称每秒百万级别的写入速度。但同样因为其依赖的Hadoop生态太重, 运维成本很高,不够简洁与轻量;另一个缺点就是它基于HBase的key-value存储方式,对于聚合查询并不友好高效,HBase存在的问题也会体现出来。

(2)InfluxDB。InfluxDB可以说是时序行业的典范了,其已经发展成为一个平台,包括了时序数据应有的一切:从数据存储到界面展示。然而,InfluxDB虽然开源了其核心代码,但重要的集群功能只有企业版才提供[3], 而企业版并不是免费的。很多大公司要么直接使用,要么自己开发集群功能。

(3)TDengine。TDengine是涛思团队开发的一个高效存储、查询和分析时序大数据的平台,其创始人陶建辉年近5旬,依然开发出了这个数据库。
TDengine的定位是物联网、车联网、运维监测等时序数据,其设计也是专门针对每个设备。每个采集点一张表,比如空气监测站有1000万个,那么就建1000万个表,为了对多个采集点聚合查询,又提出了超表的概念,将同类型的采集点表通过标签区分,结构一样。这种设计确实非常有针对性,虽然限制了范围,但极大提高了效率,根据其官方的测试报告[4], 其聚合查询速度是InfluxDB的上百倍,CPU、内存和硬盘消耗却更少。

TDengine无疑是时序数据库的一朵奇葩,加上在不久前开源了其集群功能[5],受到了更多用户青睐。当我们选型时其还没有开源集群功能,后续也会纳入观察之中。
(4)ClickHouse。ClickHouse(之后简称CK)是一个开源的大数据分析数据库,也是一个完整的DBMS。CK无疑是OLAP数据库的一匹黑马,开源不到4年,GitHub上的star数已经超过12k(InfluxDB也不过19k+),而它们的fork数却相差不大。
CK是俄罗斯的搜索引擎公司yandex开源的,最初是为了分析网页点击的流量,所以叫Click,迭代速度很快,每个月一版,开发者500+,很多都是开源共享者,社区非常活跃。
CK是一个通用的分析数据库,并不是为时序数据设计的,但只要使用得当,依然能发挥出其强大的性能。
三、CK原理介绍
要利用CK的优势,首先得知道它有哪些优势,然后理解其核心原理。根据我们的测试结果,对于27个字段的表,单个实例每秒写入速度接近200MB,超过400万条数据/s。因为数据是随机生成的,对压缩并不友好。
而对于查询,在能够利用索引的情况下,不同量级下(百万、千万、亿级)都能在毫秒级返回。对于极限情况:对多个没有索引的字段做聚合查询,也就是全表扫描时,也能达到400万条/s的聚合速度。
1. CK为什么快
可以归结为选择和细节,选择决定方向,细节决定成败。
CK选择最优的算法,比如列式压缩的LZ4[6];选择着眼硬件,充分利用CPU和分级缓存;针对不同场景不同处理,比如SIMD应用于文本和数据过滤;CK的持续迭代非常快,不仅可以迅速修复bug,也能很快纳入新的优秀算法。
2. CK基础
(1)CK是一个纯列式存储的数据库,一个列就是硬盘上的一个或多个文件(多个分区有多个文件),关于列式存储这里就不展开了,总之列存对于分析来讲好处更大,因为每个列单独存储,所以每一列数据可以压缩,不仅节省了硬盘,还可以降低磁盘IO。
(2)CK是多核并行处理的,为了充分利用CPU资源,多线程和多核必不可少,同时向量化执行也会大幅提高速度。
(3)提供SQL查询接口,CK的客户端连接方式分为HTTP和TCP,TCP更加底层和高效,HTTP更容易使用和扩展,一般来说HTTP足矣,社区已经有很多各种语言的连接客户端。
(4)CK不支持事务,大数据场景下对事务的要求没这么高。
(5)不建议按行更新和删除,CK的删除操作也会转化为增加操作,粒度太低严重影响效率。
3. CK集群
生产环境中通常是使用集群部署,CK的集群与Hadoop等集群稍微有些不一样。如图5所示,CK集群共包含以下几个关键概念。
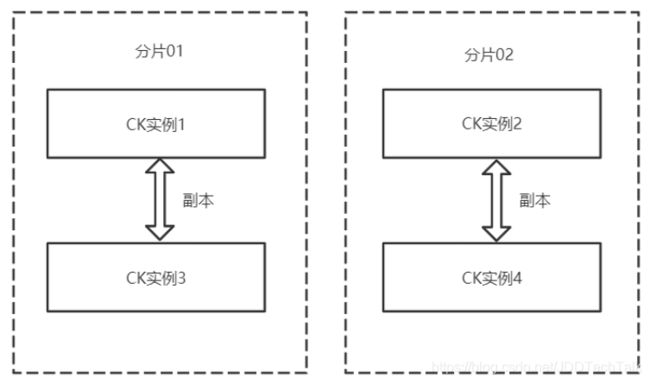
(1)CK实例。可以一台主机上起多个CK实例,端口不同即可,也可以一台主机一个CK实例。
(2)分片。数据的水平划分,例如随机划分时,图5中每个分片各有大约一半数据。
(3)副本。数据的冗余备份,同时也可作为查询节点。多个副本同时提供数据查询服务,能够加快数据的查询效率,提高并发度。图5中CK实例1和示例3存储了相同数据。
(4)多主集群模式。CK的每个实例都可以叫做副本,每个实体都可以提供查询,不区分主从,只是在写入数据时会在每个分片里临时选一个主副本,来提供数据同步服务,具体见下文中的写入过程。
4. CK分布式引擎
要实现分片的功能,需要分布式引擎。在集群情况下,CK里的表分为本地表和分布式表,下面的两条语句能够创建一个分布式表。注意,分布式表是一个逻辑表,映射到多个本地表。
create table t_local on cluster shard2_replica2_cluster (t Datetime, id UInt64)
ENGINE=ReplicatedMergeTree(’/clickhouse/tables/{shard}/t_local’,’{replica}’)
PARTITION BY toYYYYMM(t)
ORDER BY id
create table t on cluster shard2_replica2_cluster (t Datetime, id UInt64)
ENGINE=Distributed(shard2_replica2_cluster,default,t_local,id)
这里的t_local就是本地表,t就是分布式表。ReplicatedMergeTree是实现副本同步的引擎,参数可以先忽略。Distributed引擎就是分布式引擎,参数分别为:集群名,数据库名,本地表名,分片键(可以指定为rand()随机数)。
分布式引擎在写入和查询过程中都充当着重要的角色,具体过程见下面。
5. CK写入过程
根据使用的表引擎不同,写入过程是不同的,上文的建表方式是比较常规的做法,按照上面的建表语句,需要同时开启内部复制项。
<shard2_replica2_cluster>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
…
</replica>
<replica>
…
</replica>
</shard>
写入2条数据:insert into t values(now(), 1), (now(), 2),如图6所示,写入过程分为2步:分布式写入和副本同步。
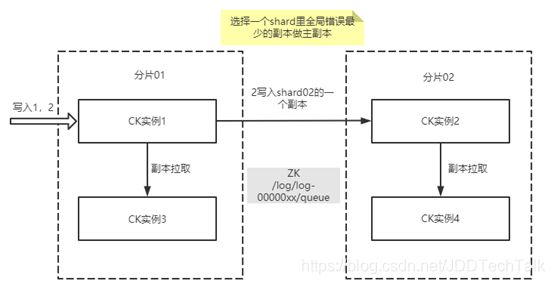
(1)分布式写入
- 客户端会选择集群里一个副本建立连接,这里是实例1。写入的所有数据先在实例1完成写入,根据分片规则,属于01分片的写入实例1本地,属于02分片的先写入一个临时目录,然后向实例2(shard02的主副本)建立连接,发送数据到实例2。
- 实例2接收到数据,写入本地分区。
- 实例1返回写入成功给客户端(每个分片写入一个副本即可返回,可以配置)。
(2)副本同步
同步的过程是需要用到ZK的,上面建表语句的ReplicatedMergeTree第一个参数就是ZK上的路径。创建表的时候会有一个副本选举过程,一般先起的会成为主副本,副本的节点信息会注册到ZK,ZK的作用只是用来维护副本和任务元数据以及分布式通信,并不传输数据。副本一旦注册成功,就开始监听/log下的日志了,当副本上线,执行插入时会经过以下过程:
- 实例1在写入本地分区数据后,会发送操作日志到ZK的/log下,带上分区名称和源主机(实例1的主机)。
- 01分区的其他副本,这里就实例3,监听到日志的变化,拉取日志,创建任务,放入ZK上的执行队列/queue(这里都是异步进行),然后再根据队列执行任务。
- 执行任务的过程为:选择一个副本(数据量最全且队列任务最少的副本),建立到该副本(实例1)的连接,拉取数据。
注意,使用副本引擎却不开启内部复制是不明智的做法,因为数据会重复写,虽然数据校验可以保证数据不重复,但增加了无畏的开销。
6. CK查询过程
查询的是分布式表,但要定位到实际的本地表,也就是副本的选择,这里有几种选择算法,默认采用随机选择。响应客户端查询请求的只会有一个副本,但是执行过程可能涉及多个副本。比如:select count(*) from t。因为数据是分布在2个分片的,只查一个副本不能得到全部结果。

7. CK中重要的索引引擎
CK核心的引擎就是MergeTree,在此之上产生了很多附加引擎,下面介绍几种比较常用的。
(1)ReplacingMergeTree。为了解决MergeTree主键可以重复的特点,可以使用ReplacingMergeTree,但也只是一定程度上不重复:仅仅在一个分区内不重复。使用方式参考:https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replacingmergetree/
(2)SummingMergeTree。对于确定的group by + sum查询,若比较耗时,那么可以建SummingMergeTree, 按照order by的字段进行聚合或自定义聚合字段,其余字段求和。
(3)AggregatingMergeTree。聚合显然是分析查询的重点,一般使用聚合MergeTree都会结合物化视图,在插入数据时自动同步到物化视图里,这样直接查询物化视图中聚合的结果即可。
(4)ReplicatedXXXMergeTree。在所有引擎前加一个Replicated前缀,将引擎升级为支持副本功能。
(5)物化视图。物化视图就是将视图SQL查询的结果存在一张表里,CK里特殊的一点是:只有insert的数据才能进入触发视图查询,进入视图表,分布式情况下同步过去的数据是不会被触发的,为了在分布式下使用物化视图,可以将物化视图所依赖的表指定为分布式表。
四、CK与时序的结合
在了解了CK的基本原理后,我们看看其在时序数据方面的处理能力。
(1)时间:时间是必不可少的,按照时间分区能够大幅降低数据扫描范围;
(2)过滤:对条件的过滤一般基于某些列,对于列式存储来说优势明显;
(3)降采样:对于时序来说非常重要的功能,可以通过聚合实现,CK自带时间各个粒度的时间转换函数以及强大的聚合能力,可以满足要求;
(4)分析挖掘:可以开发扩展的函数来支持。
另外CK作为一个大数据系统,也满足以下基础要求:
(1)高吞吐写入;
(2)海量数据存储:冷热备份,TTL;
(3)高效实时的查询;
(4)高可用;
(5)可扩展性:可以实现自定义开发;
(6)易于使用:提供了JDBC和HTTP接口;
(7)易于维护:数据迁移方便,恢复容易,后续可能会将依赖的ZK去掉,内置分布式功能。
因此,CK可以很方便的实现一个高性能、高可用的时序数据管理和分析系统。下面是关键点的详细介绍。
1. 时序索引与分区
时序查询场景会有很多聚合查询,对于特定场景,如果使用的非常频繁且数据量非常大,我们可以采用物化视图进行预聚合,然后查询物化视图。但是,对于一个通用的分析平台,查询条件可以随意改变的情况下,使用物化视图的开销就太大了,因此我们目前并没有采用物化视图的方式,而是采用原始的表。物化视图的方案后续将会进一步验证。
下面给出的是JUST建时序表的语法格式:第一个括号为TAG字段,第二个括号为VALUE字段(必须是数值型),大括号是对底层存储的特殊配置,这里主要是CK的索引和参数。除了用户指定的字段外,还有一个隐含的time字段,专为时序保留。
create table my_ts_table as ts (
tag1 string,
tag2 String [:primary key][:comment=’描述’]
)
(
value1 double,
value2 double
)
在JUST底层,对应了CK的2张表(一张本地表,一张分布式表),默认会根据time分区和排序,如下面的一个例子:
create table airquality as ts (
name string,
city String
)
(
PM10 double,
PM25 double
)
实际对应的CK建表语句为:
CREATE TABLE just.username_dbname_airquality_local
(
`id` Int32,
`oid` Int32,
`name` String,
`city` String,
`time` DateTime,
`PM10` Float64,
`PM25` Float64
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/24518511-2939-489b-94a8-0567384d927d', '{replica}')
ORDER BY (time)
SETTINGS index_granularity = 8192
PARTITION BY toYYYYMM(time)
CREATE TABLE just.wangpeng417_test_airquality
(
`id` Int32,
`oid` Int32,
`name` String,
`city` String,
`time` DateTime,
`PM10` Float64,
`PM25` Float64
)
ENGINE = Distributed('just_default', 'just', ' username_dbname _airquality_local',rand())
这样保证在使用时间范围查询时可以利用到索引,假如还有其他按照TAG的查询条件,还可以自定义索引和排序字段[LL1] (CK规定索引字段一定是排序字段的前缀)。
在不同场景下,还是需要根据数据量和数据特点来选择索引分区和索引粒度。根据实验测试,假如在我们环境里CK每秒可以扫描1GB数据量,再乘以1-10倍的压缩比,那么一个分区的数据量应该大于千万到亿级别可以保证较优的速度,CK本身是多线程查询的,可以保证同时对每个分区查询的隔离性。但是根据查询的场景,比如最多查到一个月,但大部分情况都是查一周,那么分区精确到周可能更好,这是个综合权衡的过程。
2.部署与高可用
在JUST中,高可扩展性和高可用性是我们的追求。为实现高可扩展性,我们对数据进行水平分片;为了实现高可用性,我们对每个分片存储至少两个副本。
关于集群部署,最小化的情况是2台机器,这会产生2种情况1)交叉副本;2)一主一备;如图9所示:

这2种方案对查询和写入影响的实验结果如图10所示。

实验结果表明:写入速度(横坐标为写入示例数,纵坐标为速度MB/s)在达到极限时是差不多的,而查询性能(横坐标为SQL编号,SQL语句见附录1,纵坐标为耗时,单位为秒)对于简单查询差别不大,但是对于占用大量资源的复杂查询,一主一备更加高效。因为CK的强悍性能是建立在充分利用CPU的基础上,在我们的测试中,裸机情况下CPU达到90%以上非常频繁,如果有单独的机器部署CK,那么无可厚非能够充分利用机器资源。但在我们的环境中,与其他大数据平台共有机器,就需要避免CK占用过多资源,从而影响其他服务,于是我们选择docker部署。docker容器部署也有开源的基于k8s的实现:clickhouse-operator,对于小型环境,可以选择手动配置,通过简单的脚本即可实现自动化部署。
基于以上测试结论,为了保证服务高可用,CK集群和数据冗余是必不可少的,我们的方案是保证至少2个副本的情况下,分片数尽量多,充分利用机器,且每个机器有且仅有一个CK实例。于是就有了以下分片数与副本数的公式:

其中f(n)代表当有n台机器时,部署的分布情况,n>=2。f(2) = (1, 2)表示2台机器采用1个分片2个副本部署的策略,f(3)=(1, 3)表示3台机器时1个分片3个副本部署策略,f(4)=(2, 2)表示4台机器使用2个分片,每个分片2个副本,以此类推。
3.动态扩容
随着数据量增加,需要扩展节点时,可以在不停机的情况下动态扩容,主要利用的是分片之间的权重关系。
这里扩容分为2种情况:
(1)增加副本:只需要修改配置文件,增加副本实例,数据会自动同步,因为CK的多主特性,副本也可以当作查询节点,所以可以分担查询压力;
(2)增加分片:增加分片要麻烦点,需要根据当前数据量、增加数据量计算出权重,然后在数据量达到均衡时将权重修改回去
假如开始时我们只有1个分片,已经有100条数据了。
1
true
10.220.48.106
9000
10.220.48.105
9000
现在要再加入一个分片,那么权重的计算过程如下(为了简化忽略这个期间插入的数据):
假如我们打算再插n条数据时,集群数据能够均衡,那么每个shard有(n+100)/2 条,现在shard01有100条,设权重为 w1、w2,那满足公式:n * (w2/(w1+w2)) = (n+100)/2 ,其中n>100, 所以,假如 w1=1,n=200,那么 w2=3。
所以,将配置修改如下:
1
true
10.220.48.106
9000
10.220.48.105
9000
3
true
10.220.48.103
9000
等到数据同步均匀后再改回1:1。
4.系统介绍与不足
JUST时序分析底层使用了CK作为存储查询引擎,并开发了可复用的可视化分析界面,欢迎访问https://just.urban-computing.cn/进行体验。

用户可以使用统一的查询界面建立时序表,然后导入数据,切换到时序分析模块进行可视化查询。


目前提供的查询功能主要有:按时间查询、按TAG过滤,在数据量很多的情况下,可以按照大一些的时间粒度进行降采样,查看整个数据的趋势,同时提供了线性、拉格朗日等缺失值填补功能。
分析挖掘部分主要是按找特定值和百分比过滤,以及一些简单的函数转换。
目前时序模块的功能还比较简陋,对于时序数据的SQL查询支持还不够完备。未来还有集成以下功能:
(1)接入实时数据;
(2)针对复杂查询,面板功能可以采用聚合引擎预先聚合;
(3)更完善的分析和挖掘功能;
(4)对数据的容错与校验处理;
(5)与JUST一致的SQL查询支持。
参考链接:
[1] https://en.wikipedia.org/wiki/Time_series.
[2] https://db-engines.com/en/ranking/time+series+dbms.
[3] https://www.influxdata.com/blog/influxdb-clustering/.
[4] https://www.taosdata.com/downloads/TDengine_Testing_Report_cn.pdf.
[5] https://www.taosdata.com/blog/2020/08/03/1703.html.
[6] lz4.LZ4[EB/OL].https://lz4.github.io/lz4/,2014-08-10..
[7] https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/.
作者:JUST团队-王棚&李瑞远
文章来源:“京东数科技术说”微信公众号
原文链接:https://mp.weixin.qq.com/s/cJXm7jocG90Gw85d5CGA2g.
更多技术干货欢迎关注“京东数科技术说”微信公众号,我们只凭技术说话!
