ClickHouse拆解
什么是ClickHouse?
Clickhouse由俄罗斯Yandex公司开源的数据库,专为OLAP而设计。 Yandex是俄罗斯最大的搜索引擎公司,官方宣称ClickHouse 日处理记录数”十亿级”。
发布之初跑分要超过很多流行的商业MPP数据库软件,对标老东家HP的Vertica和GP 官方的性能测试显示比vertica快5倍,比GP快10倍。
毛子很任性(滑稽):
- 目前只支持Ubuntu系统
- 官方没有提供设计和架构文档,只有开源的C++源码
- 不理睬Hadoop生态,走自己的路
官网地址:https://clickhouse.yandex/
官方文档:https://clickhouse.yandex/docs/en/single/
流行的开源OLAP引擎/数据库

Impala,Presto,SparkSQL,HAWQ都是内存式引擎,本身不存储数据。GreenPlum,ClickHouse都是DBMS,有自己的数据存储机制。
Impala: 目前我们正在使用的内存引擎,CDH力推,与hive共享metadata。优点是快,缺点是容易爆内存,不支持update/delete(OLAP的通病),不支持ORC格式,UDF不支持SQL编写。不支持PLSQL(hive2后有hplsql)但默认是MR引擎,在impala中不能用。
Presto: 优点是快,跨数据源查询,支持标准SQL。
SparkSQL: 优点是稳定,适合跑批,对ORC,parquet格式有原生支持,UDF使用方便。缺点是对JVM的实际使用内存过高,且不同的spark app之间缺乏有效的共享内存机制, 之前调查过Tachyon 和ignite,都是可以实现spark的共享式RDD。
HAWQ: 全名(hadoop with query)hadoop自家出的大数据平台MPP架构的内存式分布式引擎,设计之初参考Greenplum,早期叫GOH(greenplum on hadoop),对Hive/hbase/hdfs有原生的支持,速度快,支持全语言的UDF编写(包含SQL),符合TPC-DS规格(完全兼容SQL标准),支持窗口函数和高级聚合函数,支持kerberos对表级别的权限控制。线性扩展。但现在CDH和HDP合并之后对HAWQ兼容性不能保证,因此未来不太看好。
GreenPlum: MPP架构的开源产品。
ClickHouse: MPP架构开源产品。
ClickHouse的配置要求
CPU: x86_64架构且支持SSE4.2指令集,16Core,2600MHz。
RAM: 最低4GB 。
Disk: 预留2GB安装ClickHouse,数据存储依据实际需求和压缩系数调整。
Network: 最低10G。
Environment: 官方推荐使用Ubuntu,JDK1.8。
ClickHouse的安装与使用
Guide: 安装指南
网页版查询工具TABIX:ui.tabix.io
客户端查询工具:DBeaver
Tips: 客户端和网页版查询ClickHouse时,需要开启远程登录。在安装guide有具体步骤。clickhouse的jdbc connector包需要编译,比较麻烦,建议使用dbeaver,第一次连接的时候会自动编译最新的jar包。
ClickHouse的特性
1. 列式存储,数据压缩
压缩系数<50%
2. 支持SQL
支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。 不支持窗口函数和相关子查询。
3. 多核心并行处理,多服务器分布式处理
大型查询可以以很自然的方式在ClickHouse中进行并行化处理,以此来使用当前服务器上可用的所有资源。
ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行的在所有shard上进行处理,这些对用户来说是透明的。
4. 向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理。向量化查询执行更容易利用CPU的SIMD能力。
5. 高可用
支持数据复制和数据完整性 (当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。)
6. 磁盘存储
7. 实时数据更新
ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。
8. 索引
缺陷:
1. 不支持实时的删除/更新操作,不支持事务(与Spark和大部分大数据系统一样)
2. 不支持二级索引(与Spark和大部分大数据系统一样)
3. 不支持窗口函数
ClickHouse适用场景
1. Web和App数据分析
2. 广告网络和RTB
3. 电信
4. 电子商务和金融
5. 信息安全
6. 监测和遥测
7. 时序数据
8. 商业智能
9. 在线游戏
10. 物联网
ClickHouse不适用场景
1. 事物性工作(OLTP)
2. 高并发的键值访问
3. Blob或者文档存储
4. 超标准化的数据
ClickHouse架构

ClickHouse引擎[核心]
不同的引擎用各种不同的技术存储在文件(或者内存)中。
这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平。
1. TinyLog
最简单的一种引擎,每一列保存为一个文件,里面的内容是压缩过的,不支持索引,没有并发控制。所以,当你需要在读,又在写时,读会出错。并发写,内容都会坏掉。 应用场景基本上就是那种只写一次,然后就是只读的场景。同时,它也不适用于处理量大的数据,官方推荐,使用这种引擎的表最多 100 万行的数据。 因为这种引擎的实现非常简单,所以当你有很多很多的小表数据要处理时,使用它是比较合适的,最基本的,它在磁盘上的文件量很少,读一列数据只需要打开一个文件就好了。
2. Log
TinyLog 基本一致,它的改进点,是加了一个 __marks.mrk 文件,里面记录了每个数据块的偏移,这种做的一个用处,就是可以准确地切分读的范围,从而使用并发读取成为可能。 但是,它是不能支持并发写的,一个写操作会阻塞其它读写操作。3. Merge
工具引擎,本身不保存数据,类似视图,只用于把指定库中的指定多个表链在一起。这样,读取操作可以并发执行,同时也可以利用原表的索引,但是,此引擎不支持写操作。 指定引擎的同时,需要指定要链接的库及表,库名可以使用一个表达式,表名可以使用正则表达式指定。 _table 这个列,是因为使用了 Merge 多出来的一个的一个 虚拟列 ,它表示原始数据的来源表,它不会出现在 show table 的结果当中,同时, select * 不会包含它。
4. Distributed
Merge 可以看成是单机版的 Distributed ,而真正的 Distributed 具备跨服务器能力,当然,机器地址的配置依赖配置文件中的信息。
5. Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,不支持索引,简单查询下有非常非常高的性能表现,一般用来测试 Buffer:像是 Memory 存储的一个上层应用似的(磁盘上也是没有相应目录的)。它的行为是一个缓冲区,写入的数据先被放在缓冲区,达到一个阈值后,这些数据会自动被写到指定的另一个表中。没有索引。可以设置阈值,若一次性数据量大于阈值,则直接写入表。“友好重启”时, Buffer 数据会先落到源表,“暴力重启”, Buffer 表中的数据会丢失。
6. Null
空引擎,写入的任何数据都会被忽略,读取的结果一定是空。
7. Set
只用在 IN 操作符右侧,你不能对它 select。语法比较复杂,是全内存运行的,但是相关数据会落到磁盘上保存,启动时会加载到内存中
8. Join
跟 Set 类似 只用在join右侧
9. MergeTree
支持一个日期和一组主键的两层式索引,可以实时更新数据,支持直接采样功能。tree /var/lib/clickhouse/data/default/ 文件在/var/lib/clickhouse/data/default(schema)/(tablename)/.bin(列文件) .mrk(块偏移量) primary.idx主键索引 。
10. ReplacingMergeTree
在 MergeTree 的基础上,添加了“处理重复数据”的功能,在最后加一个“版本列”,它跟时间列配合一起,用以区分哪条数据是“新的”,并把旧的丢掉(这个过程是在 merge 时处理,不是数据写入时就处理了的,平时重复的数据还是保存着的,并且查也是跟平常一样会查出来的,所以在 SQL 上排序过滤 Limit 什么的该写还是要写的)。同时,主键列组用于区分重复的行。“版本列”允许的类型是, UInt 一族的整数,或 Date 或 DateTime。
11. SummingMergeTree
就是在 merge 阶段把数据加起来了,当然,哪些列要加(一般是针对可加的指标)可以配置,不可加的列,会取一个最先出现的值。可加列不能是主键中的列,并且如果某行数据可加列都是 null ,则这行会被删除。
12. AggregatingMergeTree
聚合数据的预计算,聚合数据的增量计算的情况。对于 AggregatingMergeTree 引擎的表,不能使用普通的 INSERT 去添加数据,那怎么办?一方面可以用 INSERT SELECT 来插入数据,更常用的,是可以创建一个物化视图。
13. CollapsingMergeTree
ClickHouse稀疏索引
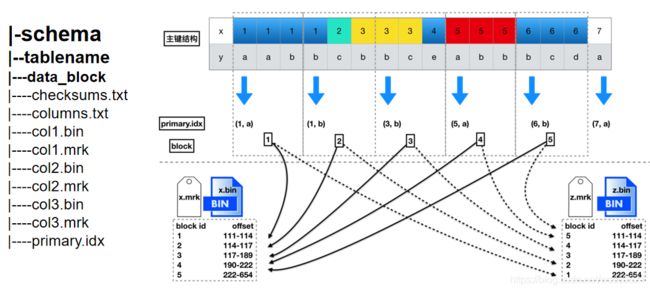
tree /var/lib/clickhouse/data/default/
图上左边的结构图为/var/lib/clickhouse/data/default(schema)/(tablename)/.bin(列文件) .mrk(块偏移量) primary.idx主键索引
主键是有序数据的稀疏索引。我们用图的方式看一部分的数据(原则上,图中应该保持标记的平均长度,但是用ASCI码的方式不太方便)。 mark文件,就像一把尺子一样。主键对于范围查询的过滤效率非常高。对于查询操作,CK会读取一组可能包含目标数据的mark文件。
MergeTree引擎中,默认的index_granularity(索引粒度)设置是8192;
在CH里,主键索引用的并不是B树,而是稀疏索引。
每隔8192行数据,是1个block 主键会每隔8192,取一行主键列的数据,同时记录这是第几个block 查询的时候,如果有索引,就通过索引定位到是哪个block,然后找到这个block对应的mrk文件 mrk文件里记录的是某个block的数据集,在整列bin文件的哪个物理偏移位置 加载数据到内存,之后并行化过滤 索引长度越低,索引在内存中占的长度越小,排序越快,然而区分度就越低。这样不利于查找。 索引长度越长,区分度就高,虽然利于查找了,但是索引在内存中占得空间就多了。
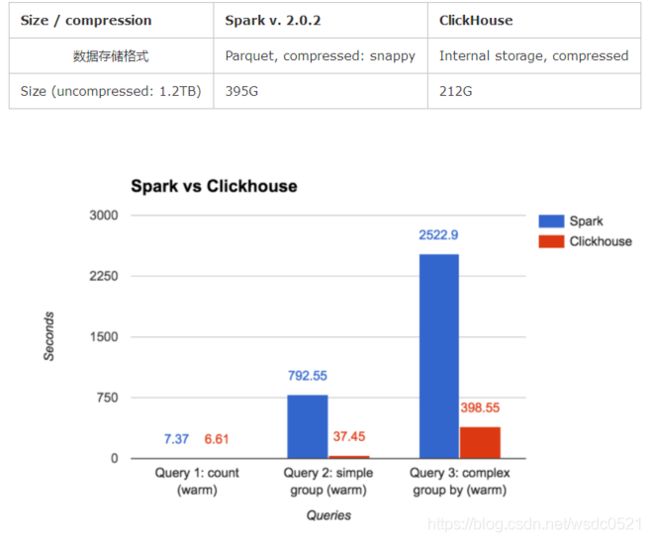
性能对比 [来自官方]
ClickHouse vs Spark
TPC-DS测试

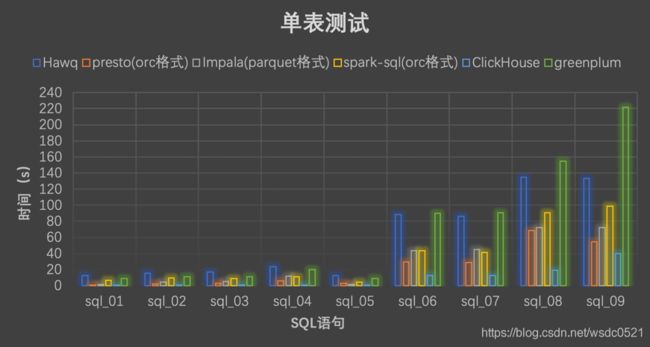
单表测试
ClickHouse为啥快?
1.MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,有多少CPU,吃多少资源,所以飞快 CH的方式,可以理解为,通过列式存储的方式,本身查询的时候就做了Map化,再对每一列做操作的时候,又使用向量化操作,等于是又增加了并发,因此,单机效率极高
2.ClickHouse不支持事务,不存在隔离级别
3.IO方面,ClickHouse是列存储
4.稀疏索引
小结
1. 作为MPP架构的开源DBMS,ClickHouse比同架构的vertica,greenplum的查询性能更快。
2. 单表测试上ClickHouse体现出了比其余组件的优势,性能比其他组件要好一大截,这得益于数据的高压缩比、稀疏索引以及对CPU资源的疯狂榨取,而在多表关联上性能相较于内存式OLAP引擎还是逊色不少。
3. 在SQL支持上ClickHouse支持类SQL,在使用合并树引擎的情况下想要发挥出CH的优势则必须用到ClickHouse的语法。
4. 因此如果做迁移时会有一定的开发成本,且ClickHouse的集群安装对机器的要求比较苛刻,更适合于在初期选型时针对真实场景作为一个选择项目。
最后附上几个测试引擎的脚本:
----------- Merge Engine-----------
create table t1 (id UInt16, name String) ENGINE=TinyLog;
create table t2 (id UInt16, name String) ENGINE=TinyLog;
create table t3 (id UInt16, name String) ENGINE=TinyLog;
insert into t1(id, name) values (1, 'first');
insert into t2(id, name) values (2, 'xxxx');
insert into t3(id, name) values (12, 'i am in t3');
drop table t_merge;
create table t_merge (id UInt16, name String) ENGINE=Merge(currentDatabase(), '^t[0-9]');
select _table,* from t_merge;
show create table t_merge;
select * from t_merge;
-------------------------------------
---------------mergetree---------------------
create table t_mergetree (gmt Date, id UInt16, name String, point UInt16) ENGINE=MergeTree(gmt, (id, name), 10);
insert into t_mergetree(gmt, id, name, point) values ('2017-04-01', 1, 'zys', 10);
insert into t_mergetree(gmt, id, name, point) values ('2017-06-01', 4, 'abc', 10);
insert into t_mergetree(gmt, id, name, point) values ('2017-04-03', 5, 'zys', 11);
-- /var/lib/clickhouse/data/
optimize table t_mergetree
------------------------------------------------
---------------ReplacingMergeTree-----------------
create table t_replacingmergetree(gmt Date, id UInt16, name String, point UInt16) ENGINE=ReplacingMergeTree(gmt, (name), 10, point);
select * from t_replacingmergetree;
insert into t_replacingmergetree (gmt, id, name, point) values ('2017-07-10', 1, 'a', 20);
insert into t_replacingmergetree (gmt, id, name, point) values ('2017-07-10', 1, 'a', 30);
insert into t_replacingmergetree (gmt, id, name, point) values ('2017-07-11', 1, 'a', 20);
insert into t_replacingmergetree (gmt, id, name, point) values ('2017-07-11', 1, 'a', 30);
insert into t_replacingmergetree (gmt, id, name, point) values ('2017-07-11', 1, 'a', 10);
truncate table t_replacingmergetree;
optimize table t_replacingmergetree;
--------------------------------------------------
---------------SummingMergeTree-----------------
create table t_summingmergetree (gmt Date, name String, a UInt16, b UInt16) ENGINE=SummingMergeTree(gmt, (gmt, name), 8192, (a));
select * from t_summingmergetree;
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-10', 'A', 1, 2);
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-10', 'B', 2, 1);
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-11', 'B', 3, 8);
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-11', 'B', 3, 7);
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-11', 'A', 3, 1);
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-11', 'C', 3, 5);
insert into t_summingmergetree (gmt, name, b) values ('2017-07-12', 'C', 3);
insert into t_summingmergetree (gmt, name, b) values ('2017-07-12', 'C', 4);
insert into t_summingmergetree (gmt, name, a, b) values ('2017-07-12', 'C', 1, 2);
truncate table t_summingmergetree;
optimize table t_summingmergetree;
--------------------------------------------------