【Puppeteer】豆瓣爬虫示例
Puppeteer 豆瓣爬虫
Puppeteer是谷歌在Chrome Headless的基础之上,开发出来的无界面操作与js接口套装,详细的介绍可以看官网。
官网上有给出一些demo,比如打开网页并截取长图,模拟使用iPhone打开网页等等。不过利用Puppeteer实际上就是模拟用户与Chrome交互的特点,用来写爬虫是很方便的。下面我以豆瓣为例,写一个例子。
1、模块引用
虽说Puppeteer是谷歌针对Chrome设计的,但实际上Chromium核心的浏览器都可以使用,只需要指定启动位置即可,例如我使用新版Edge:
const fs = require('fs')
const cheerio = require('cheerio')
const puppeteer = require('puppeteer-core');
(async () => {
// 初始化puppeteer
const browser = await puppeteer.launch({
executablePath: 'C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe',
headless: true //headless默认为true表示不启动GUI
});
})()
注意这里引用的puppeteer-core,这个版本的module是不会自动下载Chrome的,比较适合不想使用Chrome开发的人,否则下载速度感人-_-
2、设置Header
这一步实际上就是做最基本的伪装,一般如果一个网站真的反爬虫,仅靠一个Header是不够的(通过短时间相同浏览器频繁访问可以识别为爬虫),不过豆瓣好像基本就没有相关措施,而且我们只是举个例子,就简单设置一下吧:
// 获取page实例
const page = await browser.newPage();
// 将webdriver字段删除,防止反爬虫
await page.evaluateOnNewDocument(() => {
const newProto = navigator.__proto__;
delete newProto.webdriver;
navigator.__proto__ = newProto;
})
// 设置useragent,如果headless设置为true,则必做
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.41');
3、分析页面
本次示例我们爬取的网站是豆瓣电影分类排行榜 ,网页的布局如下:

我们的目标是获取页面内的每部电影的:电影名、演员名单、基本信息、评分信息。下面阅读网页源代码,找到HTML的结构信息
3.1 HTML结构
F12打开调式工具,然后选中一个影片定位到它的HTML元素位置:

顺着div块一层层往上缕,可以看到一个明晰的主线:.article —> .movie-list-panel pictext' —> .movie-info>,这是一部电影的结构顺序,实际上我们没必要写的太清晰,可以直接使用
let list = document.querySelectorAll('.article .movie-info')
就可以拿到全部电影的movie-info了。
3.2 筛选信息
上一步我们只是拿到了包含每部电影信息的“粗筛”,下面我们还要针对目标进行细筛。
使用js做爬虫的一个优点就是你可以直接看到每一步的返回结果,只需要使用浏览器自己的终端即可,比如我们看看上一步是不是确实拿到了每部电影的信息:

嗯,进一步看看列表中每个元素包含了什么:

不难发现,我们要的信息刚好对应四个子节点(不得不说豆瓣的结构那是相当的规范),那分离出来就很容易了:
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
movie_name: list[i].querySelector('.movie-name-text').textContent,
movie_crew: list[i].querySelector('.movie-crew').textContent,
movie_misc: list[i].querySelector('.movie-misc').textContent,
movie_rating: list[i].querySelector('.rating_num').textContent
})
}
在验证一下,确实拿到了哈:

3.3 动态页面
看到这按理说已经结束了,不过你要是这么爬可能结果只有20个左右,为什么呢?因为豆瓣它只有你向下滑动了才会加载更多影片啊!那么这里就需要我们模拟浏览器向下滑动的操作了,交给Puppteer,一切都简单:
var content, $
async function scrollPage() {
content = await page.content()
$ = cheerio.load(content)
// 执行js代码(滚动)
await page.evaluate(() => {
// 渐进滚动,直接跳转可能不刷新内容
window.scrollTo({
behavior: "smooth", top: document.body.scrollHeight });
})
}
这个函数可以将页面向下滚动一个屏宽,然后加载。你可以循环调用这个函数,就可以不断地往下滑了(当然你需要自己设置一个出口),或者修改滑动的宽度,一次性滑到足够的长度。
4、完整代码
const fs = require('fs')
const cheerio = require('cheerio')
const puppeteer = require('puppeteer-core');
(async () => {
// 初始化puppeteer
const browser = await puppeteer.launch({
executablePath: 'C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe',
headless: true //headless默认为true表示不启动GUI
});
// 获取page实例
const page = await browser.newPage();
// 将webdriver字段删除,防止反爬虫
await page.evaluateOnNewDocument(() => {
const newProto = navigator.__proto__;
delete newProto.webdriver;
navigator.__proto__ = newProto;
})
// 设置useragent,如果headless设置为true,则必做
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.41');
// 在新标签中打开要爬取的网页
url = 'https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action='
await page.goto(url, {
waitUntil: 'networkidle2' })
// 使用evaluate方法在浏览器中执行传入函数(完全的浏览器环境,所以函数内可以直接使用window、document等所有对象和方法)
var content, $
async function scrollPage() {
content = await page.content()
$ = cheerio.load(content)
// 执行js代码(滚动)
await page.evaluate(() => {
// 渐进滚动,直接跳转可能不刷新内容
window.scrollTo({
behavior: "smooth", top: document.body.scrollHeight * 3 });
})
let res = await page.evaluate(() => {
list = document.querySelectorAll('.article .movie-info')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
movie_name: list[i].querySelector('.movie-name-text').textContent,
movie_crew: list[i].querySelector('.movie-crew').textContent,
movie_misc: list[i].querySelector('.movie-misc').textContent,
movie_rating: list[i].querySelector('.rating_num').textContent
})
}
return res
})
return res
}
let list = await scrollPage()
list = JSON.stringify(list)
fs.writeFileSync('movie-info.json', list);
await browser.close()
})()
最后爬取到的结果也很规范:
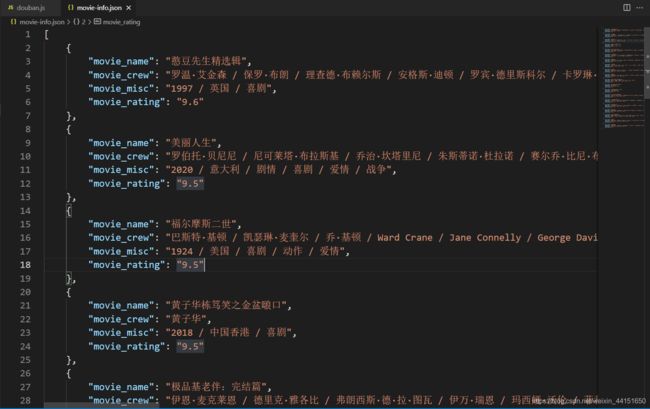
5、结语
这只是简单使用了一下Puppeteer写了一个示例,实际上如果你熟练使用Scrapy、selenium这些python方法同样可以高效的写出爬虫(甚至更加方便自动化与管理)。但是Puppeteer对于初学者学习如何分析网页,了解JavaScript与HTML的关系很有帮助,另外写一些个人项目使用起来也很简单,不需要想太多。