python selenium span内容读取_【程仁智推荐】Selenium自动化测试入门

LupuX 2017-06-18 14:24:28 ![]() 11853
11853 ![]() 收藏 41
收藏 41
分类专栏: Auto Test 文章标签: 自动化测试 selenium web测试 UI自动化
版权
一、什么是Selenium
Selenium 是一个浏览器自动化测试框架,它主要用于web应用程序的自动化测试,其主要特点如下:开源、免费;多平台、浏览器、多语言支持;对web页面有良好的支持;API简单灵活易于使用;支持分布式测试用例执行。
Selenium经历了两个版本,Selenium1.0和2.0,Selenium1.0主要由以下几部分构成:
Selenium IDE:是一个嵌入到Firefox中的插件,可以实现浏览器的录制于回放功能。
Selenium Grid:自动化测试辅助工具,可以很方便地同时在多台机器上并行运行多个测试事例。
Selenium RC:是Selenium的核心工具,支持多种不同的语言编写的测试脚本,通过Selenium RC的服务器作为代理服务器去访问应用从而达到测试的目的。主要分为以下两部分:
明白了Selenium1.0的家族关系,Selenium2.0可以简单的认为是将WebDriver加入到了Selenium RC这一部分中去。那么Selenium RC和WebDriver有什么区别呢?RC和 WebDriver 类似,都可以看做是一套操作web页面的规范。当然,他们的工作原理不一样。
Client:用来编写测试脚本来控制Selenium server的库。
Server:负责控制浏览器的行为,包含三部分:Launcher;HttpProxy;Core。
Selenium RC 在浏览器中运行 JavaScript 应用,使用浏览器内置的 JavaScript 翻译器来翻译和执行selenese 命令(Selenium 命令集合) 。
WebDriver 通过原生浏览器支持或者浏览器扩展直接控制浏览器。WebDriver 针对各个浏览器而开发,取代了嵌入到被测 Web 应用中的 JavaScript。与浏览器的紧密集成支持创建更高级的测试,避免了JavaScript 安全模型导致的限制。除了来自浏览器厂商的支持,WebDriver 还利用操作系统级的调用模拟用户输入。
以后我们基本都用Selenium2.0来进行学习和脚本编写,并且选定Python语言作为编写脚本的语言,其实各种语言编写脚本都大同小异。
二、Selenium环境搭建
1. 安装Python
这里暂时只说windows下的。访问Python官网:https://www.Python.org/选择下载Python2或者3系列,直接点击安装,注意勾选将其自动添加至系统环境变量中,并且勾选自动安装pip,便于我们直接从cmd中使用。具体步骤不再多说,网上教程很多。
2. 安装Selenium
安装好了Python环境之后,我们直接用pip install Selenium命令来安装Selenium。
3. 安装浏览器驱动
这里我们需要知道的是Firefox的驱动已经集成在了Selenium WebDriver包中了,不用我们自己安装了。下面看一个简单了例子:
#coding=utf-8
from Selenium import webdriver
#浏览器驱动
driver=webdriver.Firefox()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("Selenium2")
driver.find_element_by_id("su").click()
driver.quit()1
2
3
4
5
6
7
8
9
10
这个简单的例子做的事是:打开Firefox,访问百度首页,输入Selenium2关键字进行搜索,退出。运行它,我们可以看见以下页面:
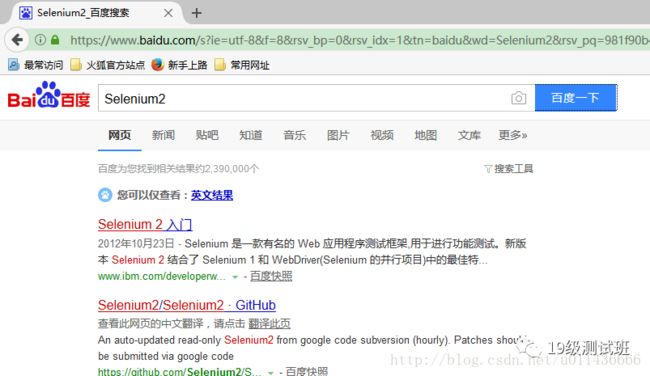
如果我们想要使用其他的浏览器呢?首先必须要下载响应浏览器的驱动,我们可以访问http://docs.Seleniumhq.org/download/来下载相关的驱动,并将其放在系统路径中。比如我们这里把Firefox改为Chrome,再运行程序可以看见:
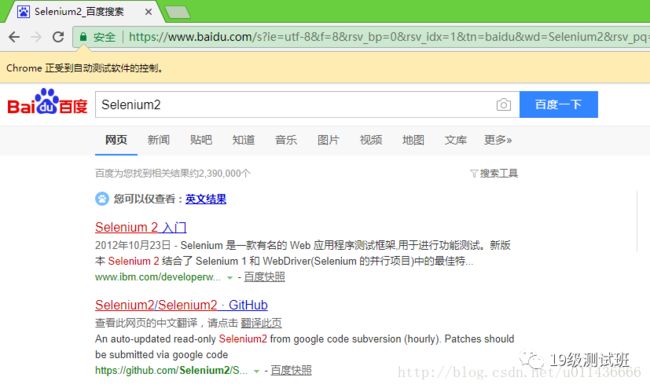
4. 其他工具安装
这里我们主要使用Firefox来进行演示,还需要安装一些插件来方便我们后面的控件抓取。可以直接访问https://addons.mozilla.org/zh-CN/firefox/来搜索和安装一些插件,比如常用的XPath和Firebug等。
环境搭建完成以后我们要做的就是开始学习编写脚本的API了。
三、WebDriver API
本节的内容是,在Python语言中,如何通过Selenium WebDriver提供的各种方法来实现web自动化测试。我们会学习一下各种操作web页面的API。这里推荐一个特别好的写示例Demo用的网站http://sahitest.com/demo/index.htm,它里面基本可以找到我们需要的所有场景。
1. 定位元素
通过firebug等工具我们可以看见页面上的各种元素,如下图:
每个元素都有不同的标签名和属性名等,Selenium可以通过这些来定位元素。在WebDriver中有以下定位元素的方法:
id
name
class name
tag name
link text
partial link text
XPath
css selector
对应的在Python中定位的方法如下:
find_element _by_id()
find_element _by_name()
…
等等八种方式(仅仅更换了关键字)。
上面这些定位方式除了最后两种外,我们只需要看它的名字就很明显可以知道,它到底是怎么定位的。但是有个问题是?我们怎么得到这些属性,可以看见即使通过firebug或查看源码去观察元素时,也是比较麻烦和不直观的。这里我们就要用到最后这两种强大的工具了。
XPath定位:
在前面我们说到了安装XPath工具,如果安装成功了之后,在一个网页的任意位置,单击右键可以看到以下页面:
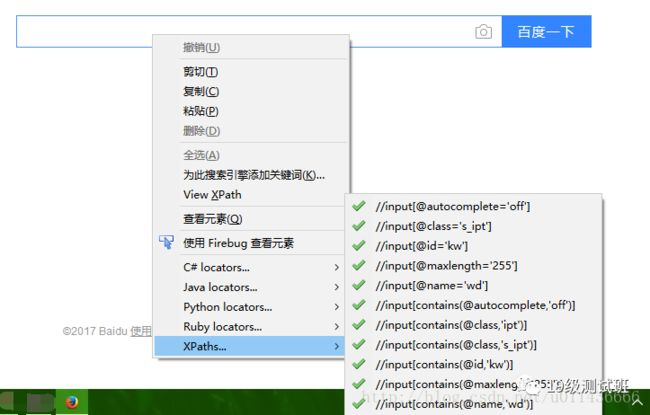
通过firebug可以看出来一些元素的属性等信息,如以下片段是搜索框和按钮的信息:
span>
1
2
3
4
5
6
7
8
图中我们是在百度搜索的搜索框中点击了右键,选中XPaths之后,可以看到显示出了很多种定位此元素的方法,从中我们也可以得到此元素的各种信息。这时在相应的方法上单击右键或左键就可以将其复制下来。
使用绝对路径定位 很显然我们要定位一个元素的话,可以从第一层一直往下找,最终一定会找到这个元素的:
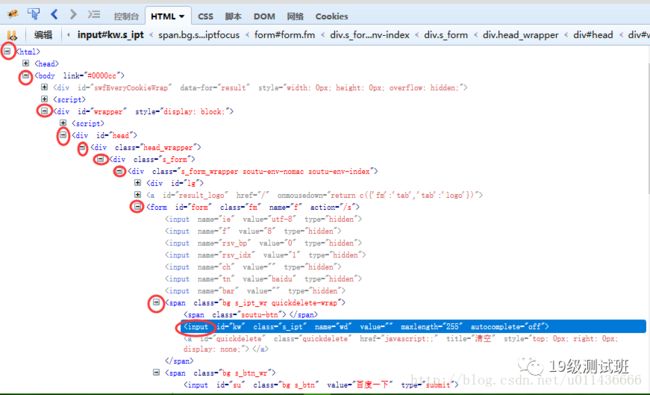
可以从上图看到,如果想定位到搜索框的话,采用绝对路径定位的话,其层级有十层之多,太烦人类了!
使用元素属性定位 我们来分析一下这种格式,比如//input[@id='kw'],如果要在脚本中使用的话,应该是find_element_by_xpath("//input[@id='kw']"),这里的//表示当前页面的某个目录下,input表示定位元素的标签名,[@id=’kw’]表示这个元素的id属性值为kw。同理我们还可以用其他的属性值来定位,如name、class,元素的任意属性值都可以用,只要它可以标识唯一的一个元素。
如果属性有重复的话,可以使用逻辑运算符来连接多个属性从而区别其他属性。比如:find_element_by_xpath("//input[@id='kw' and @name='wd']")。
CSS选择器定位
css选择器可以方便的选择控件的任意属性,一般情况下比XPath速度要快,但是有一定的学习成本。可以访问http://www.w3school.com.cn/cssref/css_selectors.asp来获取css选择器的所有使用方式。部分语法如下:
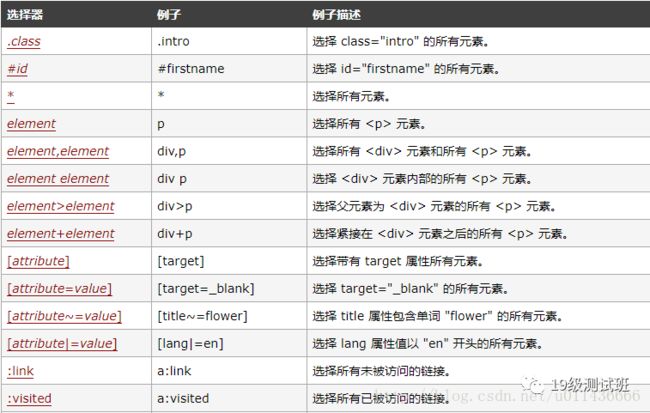
根据以上语法,我们可以使用
driver.find_element_by_css_selector("#kw")
driver.find_element_by_css_selector(".s_ipt")
driver.find_element_by_css_selector("map>area")1
2
3
等等方式来定位元素。可以使用如下方式得到CSS层级:
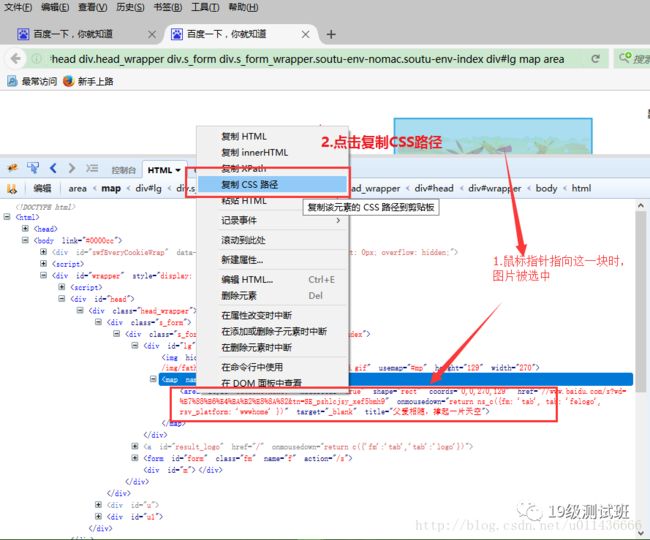
复制之后,粘贴出来可以看到如下字符串:
html body div#wrapper div#head div.head_wrapper div.s_form div.s_form_wrapper.soutu-env-nomac.soutu-env-index div#lg map area1
可以得到规律:层级之间用空格分隔,元素定位的方式会展示出来。(如,使用标签名的html、使用class的div.s_form、使用id的div#lg等等)所以我们上面可以使用map>area(父标签>子标签)来定位百度首页那张图片的位置。
关于更多CSS选择器的用法不做更多的解释了,可以查看官方文档等方式来查看使用方法!我们可以熟练的使用XPath或CSS选择器中的一种,就可以解决大部分定位的问题了。
2. 控制浏览器
控制浏览器窗口大小:
driver=webdriver.Firefox()
#设置窗口大小为x,y
driver.set_window_size(x,y)
#最大化窗口
driver.maxmize_window()1
2
3
4
5
控制浏览器前进后退:
类似于点击前进后退按钮,实现页面切换。要注意的是,我们打开的页面是不是新建了一个标签页,是不是有上级页面可以返回。
driver=webdriver.Firefox()
driver.get("https://www.baidu.com")
driver.find_element_by_css_selector("div#u1>a.mnav").click()
driver.back()
driver.forward()1
2
3
4
5
3. 元素操作
当我们获取了元素之后,还要对其进行操作,如点击按钮、输入文字、提交表单等。大多数页面交互的方法通过WebElement接口提供,常用的有:
clear() 清除文本框中的文本 send_keys(*value) 模拟按键输入 click() 单击元素
这几个方法很简单,很方便使用。
submit() 用于提交表单,例如搜索框中的提交按钮。比如我们可以用如下代码直接输入搜索的关键字后用submit()提交,而不用获取搜索按钮再点击。
driver.find_element_by_css_selector("#kw").send_keys("selenium2").submit()1
还有几个常用的方法:
size() 获取元素的大小尺寸 text()获取元素的文本 is_displayed()元素是否可见
4. 鼠标、键盘事件
模拟鼠标右键、双击、悬停、拖拽等操作,会用到ActionChains类。selenium.webdriver.common.action_chains.ActionChains(driver)当调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行。
ActionChains方法列表:
click(on_element=None) ——单击鼠标左键click_and_hold(on_element=None) ——点击鼠标左键,不松开context_click(on_element=None) ——点击鼠标右键double_click(on_element=None) ——双击鼠标左键drag_and_drop(source, target) ——拖拽到某个元素然后松开drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开key_down(value, element=None) ——按下某个键盘上的键key_up(value, element=None) ——松开某个键move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标move_to_element(to_element) ——鼠标移动到某个元素move_to_element_with_offset(to_element, xoffset, yoffset) ——移到距某个元素(左上角)多少距离的位置perform() ——执行链中的所有动作release(on_element=None) ——在某个元素位置松开鼠标左键send_keys(*keys_to_send) ——发送某个键到当前焦点的元素send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这些鼠标键盘事件相对来说用的并不是很多,我们只需要熟练使用最常用的那些,剩下的都差不多。
5. 获取验证信息
我们在编写功能测试用例时,一般会有预期结果,在自动化用例执行完成之后,我们可以从页面上获取一些信息来验证用例是执行失败还是成功。最常用的几种如下:
driver.title -获取当前页的title
driver.current_url -获取当前页面URL
driver.find_element_by_...(...).text -获取当前控件的text信息1
2
3
6.设置等待时间
显示等待: - 主要使用的类和方法:WebDriverWait、uitil\until_not、Expected Conditions。
请看以下简单示例:
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver=webdriver.Firefox()
driver.get("http://www.qq.com/")
element=WebDriverWait(driver,5,0.5).until(EC.title_is(U"腾讯首页"))
print(element)1
2
3
4
5
6
7
8
9
10
11
这里调用WebDriverWait来实现,在默认的一段时间内,每隔一段时间检测一次当前的页面指定元素是存在。

WebDriverWait()
如图所示,WebDriverWait有四个参数,WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None),分别是:driver;超时时间,检测间隔;超时后的异常信息。
until()和until_not()
WebDriverWait()一般和until()或until_not()配合使用,until(method,message=’ ‘) 调用该方法提供的驱动程序作为一个参数,直到返回值为true,同理可知道until_not(method,message=’ ‘),调用该方法提供的驱动程序作为一个参数,直到返回值应该为false。
其中的参数method,应该使用什么方法呢?这里就要用到另一个常用的类了:
expected_conditions
注意,在上面的code中我们用as将其重命名为了EC,这个类有很多种方法可以选用:
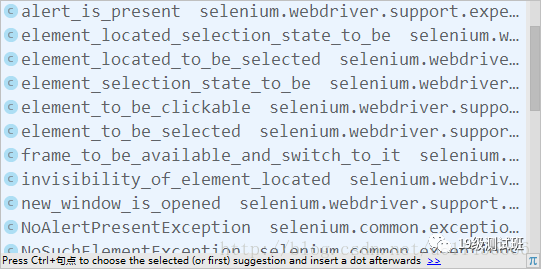
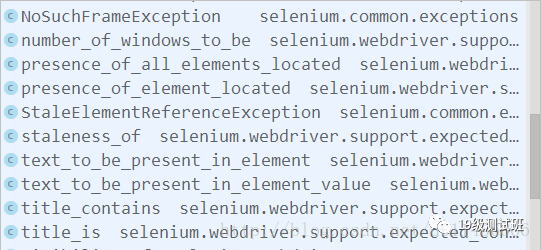
可以看到里面有很多的方法可以用来判断是否存在相应的元素。当然这里的method我们也可以用其他的方法,比如:WebDriverWait(driver,5,0.5).until(lambda driver: driver.find_element_by_xpath("//a[@bosszone='news_n']")),用这样的方式来判断是否显示出了响应的元素。
隐式等待: - implicitly_wait
隐式等待相对于显式等待就要简单多了,driver.implicitly_wait(n),n代表等待的秒数, 隐式等待相当于设置全局的等待,在定位元素时,对所有元素设置超时时间,超出了设置时间则抛出异常,默认是0。如果元素定位不到,则以轮询的方式不断定位,直到超时时间到达。
强制等待-sleep休眠方法: - Python的time模块提供,sleep(n),n为秒数。程序执行到这里的时候,强制暂停所设置的时长。
7. 定位一组元素
在前面我们说到了8种定位方法,是对单元素定位的。WebDriver还提供了与之对应的8种定位方法用于定位一组元素。区别在于element后面加了一个s,如下:
find_elements_by_id()
find_elements_by_name()
...1
2
3
一般用于以下场景:
批量操作对象:如将所有的复选框选中\取消选中
先获取一组对象,然后在这组对象中过滤出具体定位的对象
8. 多表单、多窗口切换
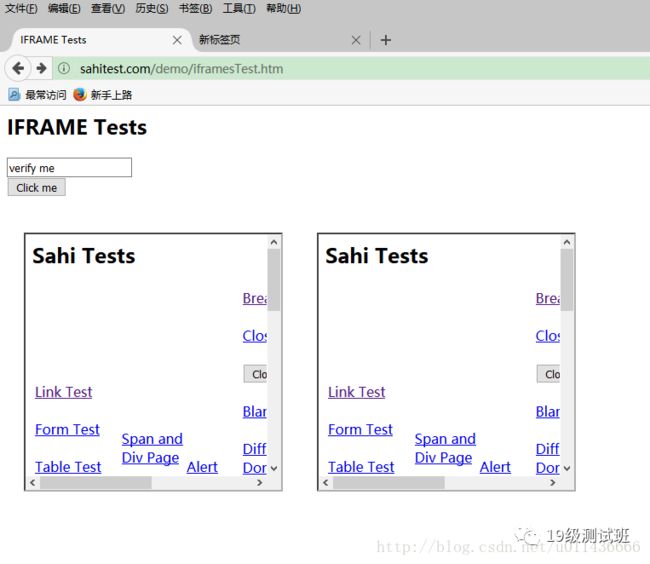
多表单页面:如图所示我们如果直接操作,去点击Link Test(frame中的元素),是不可以的,因为我们首先需要切换到这个frame里面才可以进行操作。
通过firebug工具可以得到此页面的源码,便于我们定位元素:
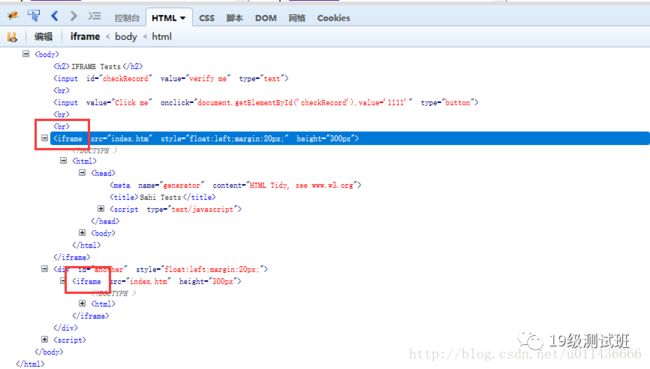
switch_to_frame(参数)方法,参数可以是iframe的id、name,如果没有的话,也可以传入locator;switch_to_default_content()方法,用来返回上一层表单,默认与据它最近的switch_to_frame方法对应。
#coding=utf-8
from selenium import webdriver
driver=webdriver.Firefox()
driver.get("http://sahitest.com/demo/iframesTest.htm")
#切换到frame里面去
driver.switch_to_frame(driver.find_element_by_xpath("/html/body/iframe"))
#进行操作
driver.find_element_by_link_text("Link Test").click()
#退出至上一层表单
driver.switch_to_default_content()1
2
3
4
5
6
7
8
9
10
11
多窗口切换:如果我们打开了多个窗口,然后想切换到其中的一个窗口呢?那就要用到switch_to_window这个方法了,请看如下代码片段:
driver=webdriver.Firefox()
driver.get("http://www.qq.com/")
#获取qq首页窗口句柄
first_windows=driver.current_window_handle
driver.find_element_by_xpath("//a[@bosszone='news_n']").click()
#当前所有打开的窗口句柄
all_handles=driver.window_handles
#进入到首页窗口
for handle in all_handles:
if handle==first_windows:
driver.switch_to_window(handle)
print("In first_windows")
#从首页打开"图片"页
driver.find_element_by_xpath("//a[@bosszone='photo_n']").click()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
9. 警告框处理
在WebDriver中处理js生成的alert、confirm、prompt是很简单的,即用switch_to_alert()方法定位到弹出框,再使用text/accept/dismiss/send_keys进行操作。看如下代码片段:
# coding=utf-8
from selenium import webdriver
import time
driver=webdriver.Firefox()
driver.get("https://www.baidu.com/")
#点击设置
driver.find_element_by_css_selector("div#u1 a.pf").click()
#点击编辑设置
driver.find_element_by_class_name("setpref").click()
time.sleep(1)
#保存设置
driver.find_element_by_css_selector("div#gxszButton>a.prefpanelgo").click()
time.sleep(1)
#接收弹窗
driver.switch_to_alert().accept()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
10. 操作滚动条&截图
操作滚动条:
可以使用js脚本,拖动到指定地方,用 driver.execute_script("arguments[0].scrollIntoView();", target),这个方法来拖动滚动条到指定的地方。其实元素没在一屏,也可以直接定位并点击的。
# coding=utf-8
from selenium import webdriver
driver=webdriver.Firefox()
driver.get("http://www.qq.com/")
#定位到“体育社区”
target = driver.find_element_by_xpath("//a[@href='http://sports.qq.com/fans/']")
#滚动到“体育社区”
driver.execute_script("arguments[0].scrollIntoView();", target)1
2
3
4
5
6
7
8
9
10
截图:
截图操作也很简单,使用driver.get_screenshot_as_file(path)即可完成截图,之后 可以借助PIL模块来进行各种处理。
11. 其他操作
还有其他一些操作如:上传下载文件、操作cookie、验证码的处理等等操作还没有用到过,这些用的场景较少并且有的还比较复杂,用到的时候再去学习就好了。
熟练使用以上的各部分,可以写出各种常用的脚本,我们算是入门Selenium了。:)