KAGGLE房价预测数据集
文章目录
- 引入
- 1 库引入
- 2 数据处理
- 完整代码
引入
KAGGLE房价预测数据集分为训练集和测试集。两个数据集都包括每栋房子的特征,如街道类型、建造年份、房价类型等特征。特征值有连续的数字、离散的标签、缺失值 (na)等。
训练集与测试集的区别在于:只有训练集包括了房子的价格,即标签。
数据集的下载地址 (需要注册):
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
原始数据以及处理好数据:
https://gitee.com/inkiinki/data20201205/blob/master/Data20201205/kaggle_house_price.rar
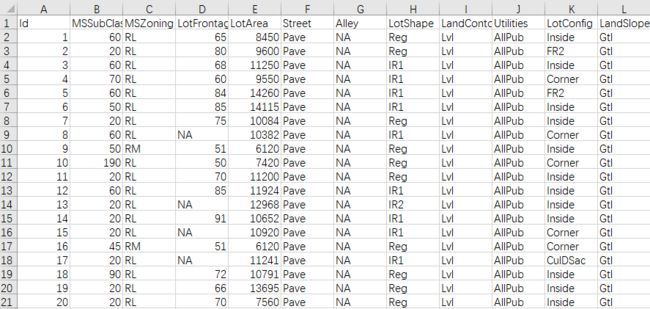
数据展示:
1 库引入
import numpy as np
import pandas as pd
2 数据处理
def load_data(para_train_path, para_test_path, is_save=False):
"""
Load datasets.
"""
temp_train_data = pd.read_csv(para_train_path)
temp_test_data = pd.read_csv(para_test_path)
# 连接训练集和测试集的所有样本
# 第一列是序号,训练集的最后一列是标签
temp_all_features = pd.concat((temp_train_data.iloc[:, 1:-1], temp_test_data.iloc[:, 1:]))
# 获取数值型数据的索引
temp_numeric_features_idx = temp_all_features.dtypes[temp_all_features.dtypes != 'object'].index
# 标准化数据
temp_all_features[temp_numeric_features_idx] = temp_all_features[temp_numeric_features_idx].apply(
lambda x: (x - x.mean()) / x.std())
# 标准化后,可以使用0来代替缺失值
temp_all_features = temp_all_features.fillna(0)
# 离散值处理:
# 例如某特征有两个不同的离散值,则该属性将被处理为二维:0 1 或者 1 0
# 三中不同的离散值时,则对于 0 0 1、 0 1 0 以及 1 0 0,以此类推
temp_all_features = pd.get_dummies(temp_all_features, dummy_na=True)
# 数据划分
temp_num_train = len(temp_train_data)
ret_train_data = np.array(temp_all_features[:temp_num_train].values, dtype=np.float)
ret_test_data = np.array(temp_all_features[temp_num_train:].values, dtype=np.float)
ret_train_label = temp_train_data.values[:, -1]
# 文件保存
if is_save:
temp_save_train_data = np.zeros((temp_num_train, len(ret_train_data[0]) + 1), dtype=float)
temp_save_train_data[:, :-1] = ret_train_data
temp_save_train_data[:, -1] = np.mat(ret_train_label)
pd.DataFrame.to_csv(pd.DataFrame(temp_save_train_data), default_path + 'house_price_train.csv',
index=False, header=False, float_format='%.6f')
pd.DataFrame.to_csv(pd.DataFrame(ret_test_data), default_path + 'house_price_test.csv',
index=False, header=False, float_format='%.6f')
return ret_train_data, ret_train_label, ret_test_data
if __name__ == '__main__':
default_path = '../Data/'
train_path = default_path + 'train.csv'
test_path = default_path + 'test.csv'
load_data(train_path, test_path, True)
完整代码
"""
@author: Inki
@contact: [email protected]
@version: Created in 2020 1209, last modified in 2020 1209.
"""
import numpy as np
import pandas as pd
def load_data(para_train_path, para_test_path, is_save=False):
"""
Load datasets.
"""
temp_train_data = pd.read_csv(para_train_path)
temp_test_data = pd.read_csv(para_test_path)
# 连接训练集和测试集的所有样本
# 第一列是序号,训练集的最后一列是标签
temp_all_features = pd.concat((temp_train_data.iloc[:, 1:-1], temp_test_data.iloc[:, 1:]))
# 获取数值型数据的索引
temp_numeric_features_idx = temp_all_features.dtypes[temp_all_features.dtypes != 'object'].index
# 标准化数据
temp_all_features[temp_numeric_features_idx] = temp_all_features[temp_numeric_features_idx].apply(
lambda x: (x - x.mean()) / x.std())
# 标准化后,可以使用0来代替缺失值
temp_all_features = temp_all_features.fillna(0)
# 离散值处理:
# 例如某特征有两个不同的离散值,则该属性将被处理为二维:0 1 或者 1 0
# 三中不同的离散值时,则对于 0 0 1、 0 1 0 以及 1 0 0,以此类推
temp_all_features = pd.get_dummies(temp_all_features, dummy_na=True)
# 数据划分
temp_num_train = len(temp_train_data)
ret_train_data = np.array(temp_all_features[:temp_num_train].values, dtype=np.float)
ret_test_data = np.array(temp_all_features[temp_num_train:].values, dtype=np.float)
ret_train_label = temp_train_data.values[:, -1]
# 文件保存
if is_save:
temp_save_train_data = np.zeros((temp_num_train, len(ret_train_data[0]) + 1), dtype=float)
temp_save_train_data[:, :-1] = ret_train_data
temp_save_train_data[:, -1] = np.mat(ret_train_label)
pd.DataFrame.to_csv(pd.DataFrame(temp_save_train_data), default_path + 'house_price_train.csv',
index=False, header=False, float_format='%.6f')
pd.DataFrame.to_csv(pd.DataFrame(ret_test_data), default_path + 'house_price_test.csv',
index=False, header=False, float_format='%.6f')
return ret_train_data, ret_train_label, ret_test_data
if __name__ == '__main__':
default_path = '../Data/'
train_path = default_path + 'train.csv'
test_path = default_path + 'test.csv'
load_data(train_path, test_path, True)